
Github: https://github.com/lern-to-write/STC
1. Motivation
最近,随着直播体育解说和增强现实眼镜等新兴应用的出现,对流式视频理解 (Streaming Video Understanding, SVU) 的需求日益迫切。在这些场景中,模型必须持续处理输入的视频帧,并以极低的延迟生成响应 。然而,现有 VideoLLM 在处理来自连续视频流的高密度视觉标记(tokens)时,计算成本极高,导致其在延迟敏感的应用中难以实时部署 。
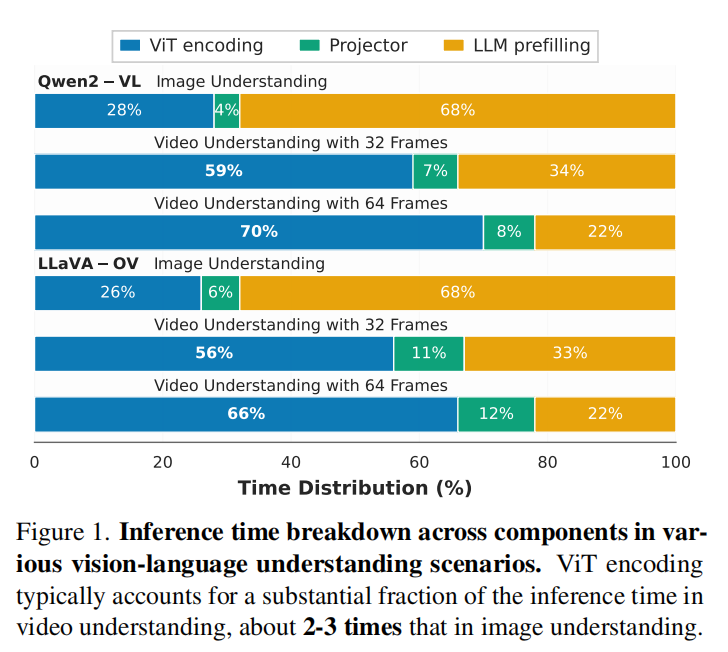
通过图 1 的推理时间分解可以发现:视频理解与图像理解存在显著差异 。在 Qwen2-VL 和 LLaVA-OV 等模型中,ViT 编码的计算成本通常比图像理解高出 2-3 倍,成为主要的延迟瓶颈 。例如,当 LLaVA-OV 处理 32 帧视频时,会有 个视觉标记输入 LLM,是普通图像任务(约 1,900 个标记)的三倍以上 。
针对流式场景,本研究通过实证分析揭示了两个关键特征:
-
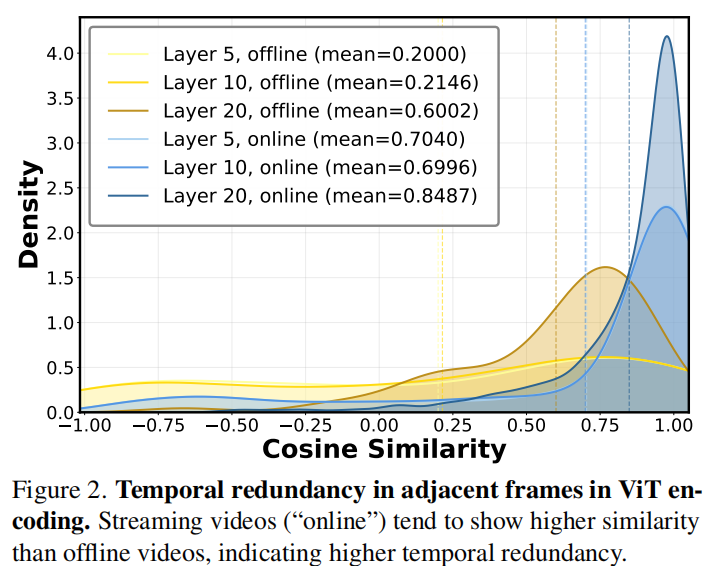
ViT 编码中的时间冗余 (Temporal Redundancy):流式视频需要更密集的帧采样,导致相邻帧之间存在大量重复内容 。实验显示,在 ViT 的深层(如 Layer 20),相邻帧特征的平均余弦相似度在流式设置下高达 0.85,而离线设置仅为 0.60 。
-
不完整的视频与未知的指令 (Incomplete Video and Unknown Instructions):流式场景下,模型无法预先获取完整视频或用户指令,这使得依赖全局视频特征或指令感知的压缩策略(如 Instruction-aware pruning)失效,因为查询通常在视频帧处理完后才到达 。
因此,迫切需要一种能够**因果式(causally)**运行、利用编码过程中的时间冗余且不依赖全局上下文的压缩方法 。
2. Contribution
基于上述分析,我们提出了 Streaming Token Compression (STC),这是一个即插即用的分层加速框架,旨在共同优化 ViT 编码和 LLM 预填充(prefilling)阶段 。其核心贡献包括:
-
流式场景的实证分析:分析了现有压缩方法在 SVU 中的局限性,强调了因果压缩的必要性,即在不依赖未来指令的情况下降低 ViT 成本 。
-
即插即用的加速框架:STC 框架可无缝集成到现有 VideoLLM 中,无需重新训练即可实现高效的流式视频理解 。
-
两个互补的标记压缩器:
-
STC-Cacher:通过缓存和重用相邻帧的特征来加速 ViT 编码 。
-
STC-Pruner:通过剪枝低显著性标记来加速 LLM 预填充阶段 。
-
-
全面的验证与结果:实验证明 STC 在性能与效率之间取得了卓越平衡。在 ReKV 框架上保留了 99% 的准确度,同时将 ViT 编码延迟降低了 24.5%,LLM 预填充延迟降低了 45.3% 。
3. Methodology
3.1. Preliminary
流式推理范式 (Streaming Inference): 连续视频流 被划分为多个长度为 的数据块(chunks) 。
$$ \mathcal{V} = {\mathcal{V}_1, \mathcal{V}2, \dots, \mathcal{V}t}, \quad \mathcal{V}t = {I{t,1}, I{t,2}, \dots, I{t,L}} $$
对于每个块,ViT 提取视觉特征标记 。
$$ \mathbf{Z}_t = \mathrm{ViT}(\mathcal{V}_t), \quad \mathbf{Z}_t \in \mathbb{R}^{N \times d} $$
为了在因果约束下保持时间一致性,每个块生成的 Key-Value (KV) 状态被缓存在存储库 中,作为未来处理的上下文 。
$$ \mathcal{M}t = \mathcal{M}{t-1} \cup {(\mathbf{K}_t, \mathbf{V}_t)} $$
冗余瓶颈 (Redundancy Bottleneck):
-
ViT 编码中的时间冗余:相邻帧共享大量静态背景,导致重复计算 。
-
LLM 预填充中的长上下文冗余:随着视频推进,标记序列中积累了持久的时间特征和低信息区域,加重了 LLM 自注意力机制的 计算负担和 KV 缓存的存储压力 。
3.2. Streaming Token Compression
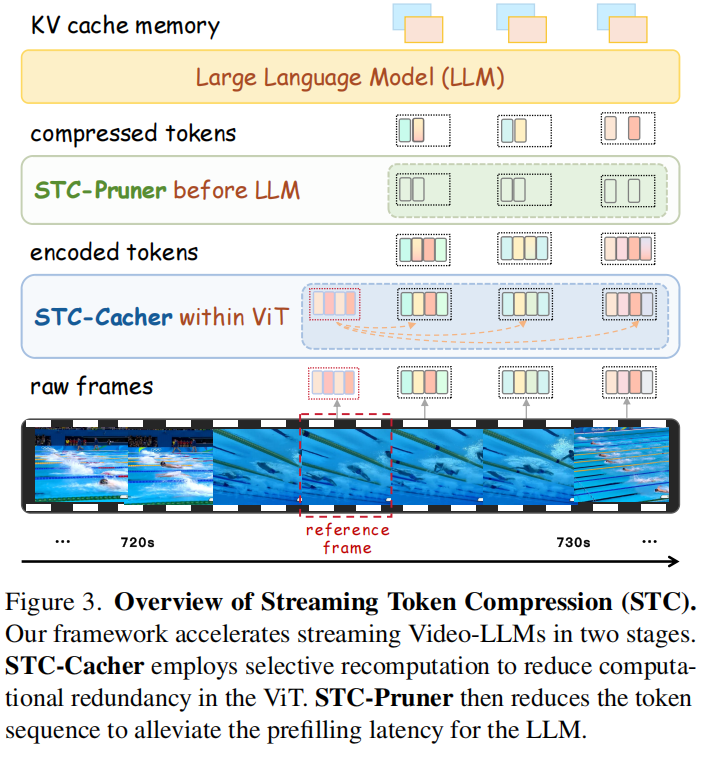
STC 框架通过以下两个模块解决上述瓶颈:
-
STC-Cacher:结合时间变化信息,缓存并重用静态内容的视觉特征,仅选择性地计算时间上的“动态标记” 。
-
STC-Pruner:结合因果事件信息,在标记进入 LLM 之前对其进行剪枝,缩短上下文长度 。
两个组件均是查询无关(query-agnostic)且未来无关(future-agnostic)的 。
$$ \mathbf{Z}t^{\text{compressed}} = f(\mathbf{Z}{\le t}), \quad \mathbf{Z}t^{\text{compressed}} \perp \mathbf{Z}{> t} $$
3.3. STC-Cacher: Selective Computation in ViT

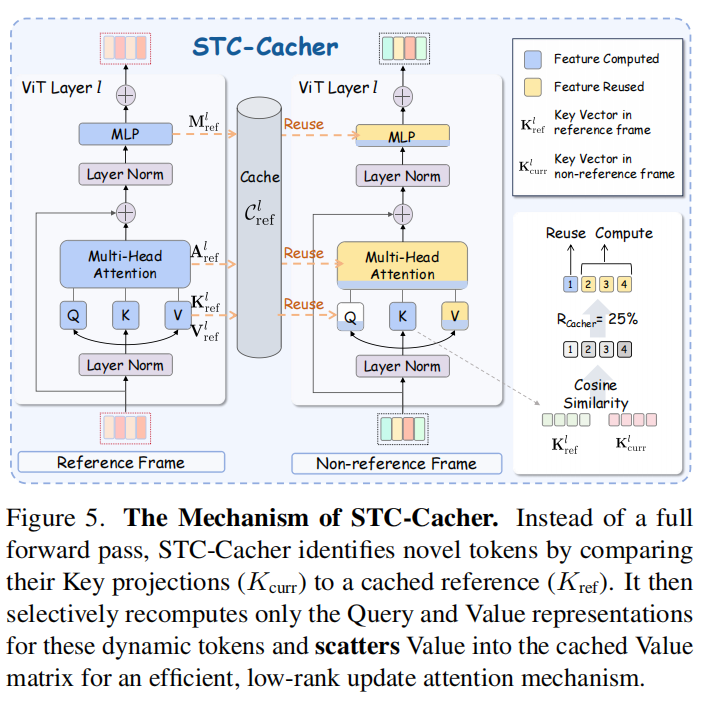
STC-Cacher 的核心思想是选择性重计算 (Selective Recomputation)。它通过识别动态标记来避免对冗余帧进行完整的 ViT 前向传播 。
具体步骤如下:
- 参考帧处理 (Full Computation & Caching): 对于参考帧 (由缓存间隔 决定,如每 4 帧更新一次),执行完整的 ViT 前向传播 。缓存每一层 的中间表示 :
$$ \mathcal{C}_t^{(l)} = \left{ \mathbf{K}_t^{(l)}, \mathbf{V}_t^{(l)}, \mathbf{A}_t^{(l)}, \mathbf{H}_t^{(l)} \right} $$
其中包含 Key、Value、Attention 输出和 MLP 输出 。
- 非参考帧处理 (Selective Computation): 对于后续帧 ,利用缓存旁路大部分计算,仅聚焦于包含新信息的动态标记 。
- 识别动态标记:计算当前 Key 投影 与缓存参考 之间的余弦相似度:
$$ s_i = \frac{ \langle \mathbf{k}{t,i}, \mathbf{k}{\text{ref},i} \rangle }{ |\mathbf{k}{t,i}| , |\mathbf{k}{\text{ref},i}| } $$
选择相似度最低的前 个标记作为动态集合 :
$$ \mathcal{D}t = \operatorname{TopK}{i} \left( 1 - s_i , ; k = \rho N \right) $$
- 选择性注意力 (Selective Attention):仅为 中的标记计算 Query 和 Value:
$$ \mathbf{Q}_t^{\mathcal{D}} = \mathbf{Z}_t^{\mathcal{D}} \mathbf{W}_Q, \quad \mathbf{V}_t^{\mathcal{D}} = \mathbf{Z}_t^{\mathcal{D}} \mathbf{W}_V $$
构建完整的 Value 矩阵 :先从缓存 初始化,然后将新计算的 散布(scatter)更新到相应位置 。注意力计算如下:
$$ \mathbf{V}t = \mathbf{V}{\text{cache}} ;; \text{with} ;; \mathbf{V}_t[\mathcal{D}_t] \leftarrow \mathbf{V}_t^{\mathcal{D}} $$
$$ \begin{aligned} \mathrm{Attn}(\mathbf{Q}_t^{\mathcal{D}}, \mathbf{K}_t, \mathbf{V}_t) &= \mathrm{softmax} \left( \frac{\mathbf{Q}_t^{\mathcal{D}} \mathbf{K}_t^\top}{\sqrt{d}} \right) \mathbf{V}_t \end{aligned} $$
- 散布更新输出 (Scatter-Update):将计算结果散布回缓存的 中形成更新后的 ,后续的 MLP 块也采用类似的散布逻辑 。
$$ \mathbf{H}_t[\mathcal{D}_t] \leftarrow \hat{\mathbf{H}}_t^{\mathcal{D}}, \quad \mathbf{H}_t[\bar{\mathcal{D}}t] \leftarrow \mathbf{H}{\text{cache}} $$
3.4. STC-Pruner: Dual-Anchor Pruning for LLM
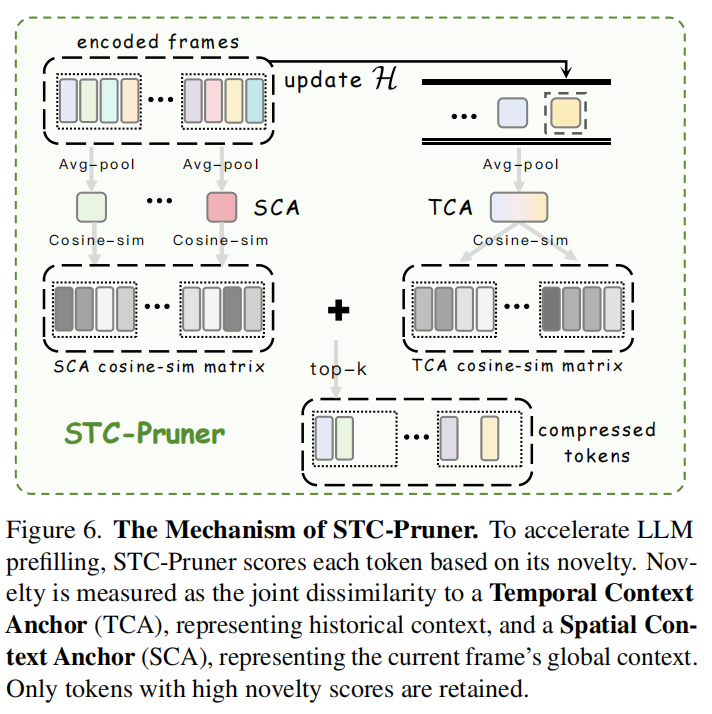
STC-Pruner 旨在通过双锚点剪枝策略减少输入 LLM 的标记数量 。它衡量标记相对于历史上下文(时间)和当前帧背景(空间)的新颖性 。
具体机制包括:
- 锚点建立 (Anchor Establishment):
- 时间上下文锚点 (Temporal Context Anchor, TCA):历史缓冲区 中过去 帧标记向量的均值,代表累积的历史背景:
$$ \mathbf{a}{\text{TCA}} = \frac{1}{|\mathcal{B}|} \sum{\mathbf{z} \in \mathcal{B}} \mathbf{z} $$
- 空间上下文锚点 (Spatial Context Anchor, SCA):当前帧所有标记的均值,代表该帧的全局背景或静态信息:
$$ \mathbf{a}{\text{SCA}} = \frac{1}{N} \sum{i=1}^{N} \mathbf{z}_{t,i} $$
- 动态性评分 (Dynamics Scoring): 使用余弦距离 计算每个标记 的评分。评分公式结合了时间与空间的新颖性:
$$ s_i = \lambda \cdot \left( 1 - \cos(\mathbf{z}{t,i}, \mathbf{a}{\text{TCA}}) \right) + (1 - \lambda) \cdot \left( 1 - \cos(\mathbf{z}{t,i}, \mathbf{a}{\text{SCA}}) \right) $$
其中 是调节时空显著性的权重。该评分会优先保留那些既不同于过去也不同于当前背景的标记 。
- 标记剪枝 (Token Pruning): 根据剪枝比例 ,保留评分最高的前 个标记:
$$ \mathcal{Z}t^{\text{keep}} = \operatorname{TopK}{i} \left( s_i, ; k = \gamma N \right) $$
4. Experiments
4.1. Experimental Setup
-
基线模型:Dispider, LiveCC, StreamForest, ReKV 。
-
数据集 (OVO-Bench):涵盖实时视觉感知(OCR、动作识别等)、后向追踪(情节记忆等)和前向主动响应(重复事件计数等)三类任务 。
4.2. Main Comparisons
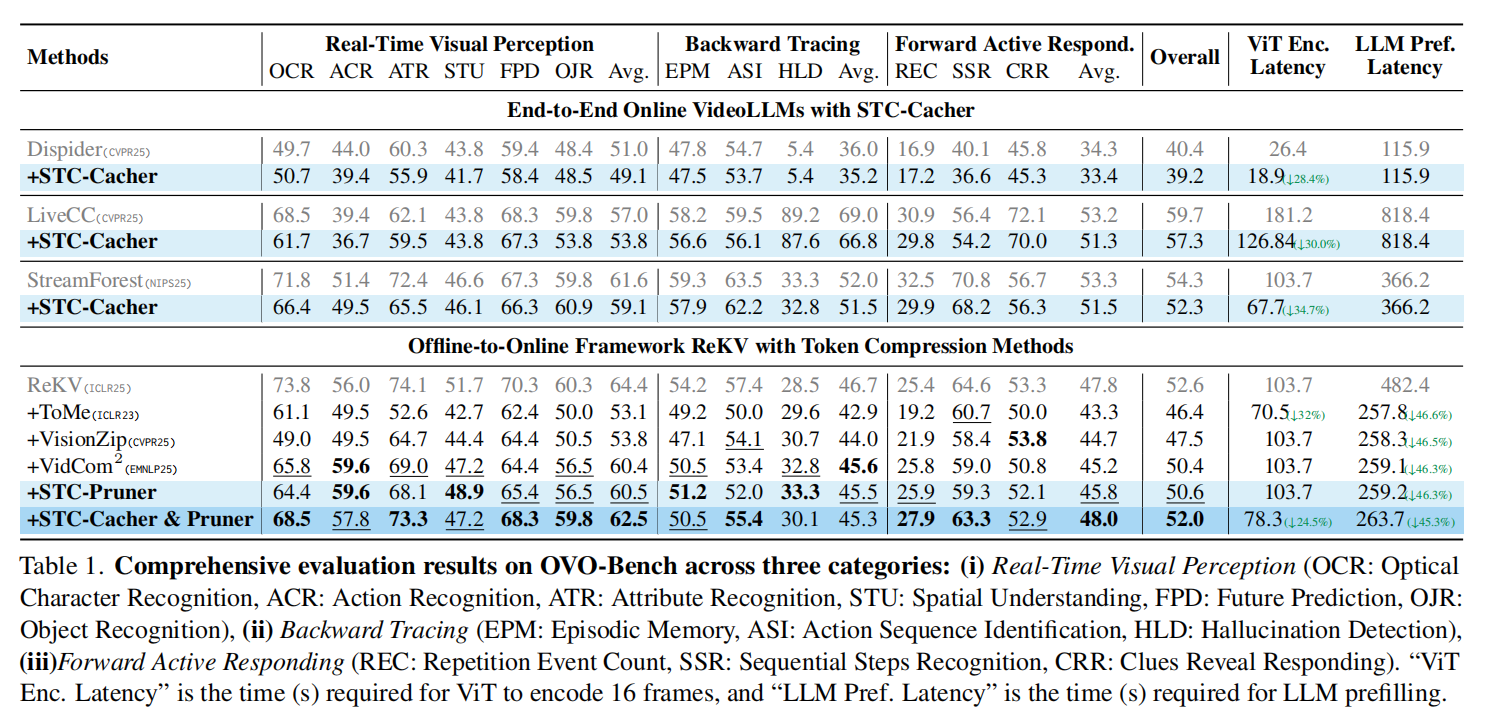
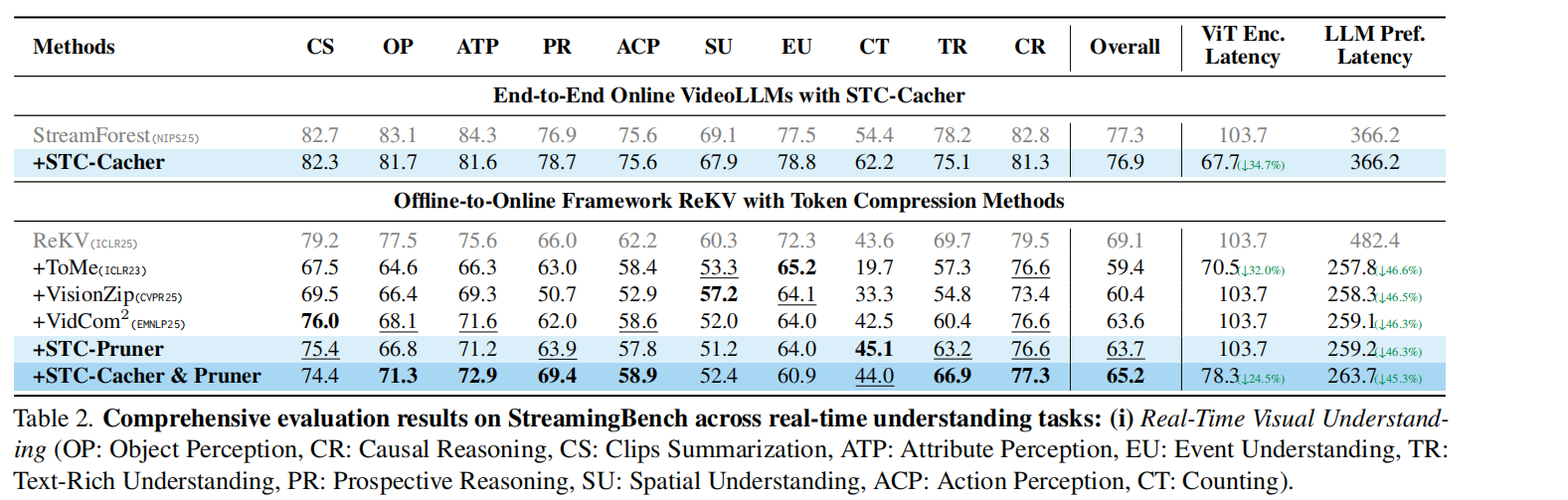
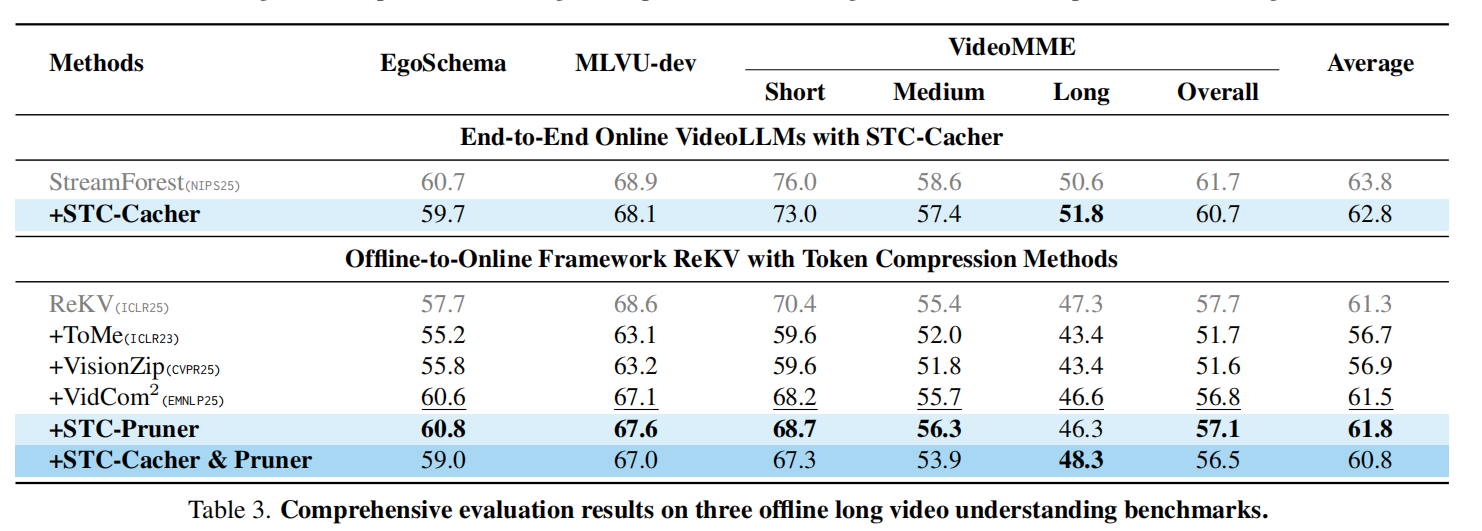
根据表 1 的实验结果,STC 展示了显著的加速效果和极高的精度保留 :
-
效率提升:与原始 ReKV 相比,STC 组合将 LLM 预填充延迟从 482.4s 大幅降至 263.7s(约减少 45.3%),同时通过 Cacher 有效降低了 ViT 编码延迟 。
-
性能对比:在保持较高推理速度的同时,STC 的综合准确度(52.0)优于许多同类压缩方法(如 ToMe 在某些感知任务上由于信息丢失严重导致性能下滑) 。
4.3. Ablation Studies and Analysis
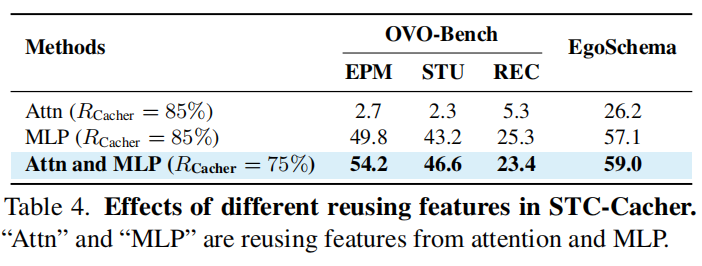
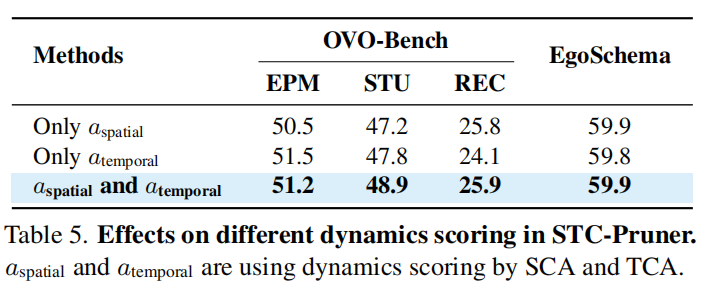
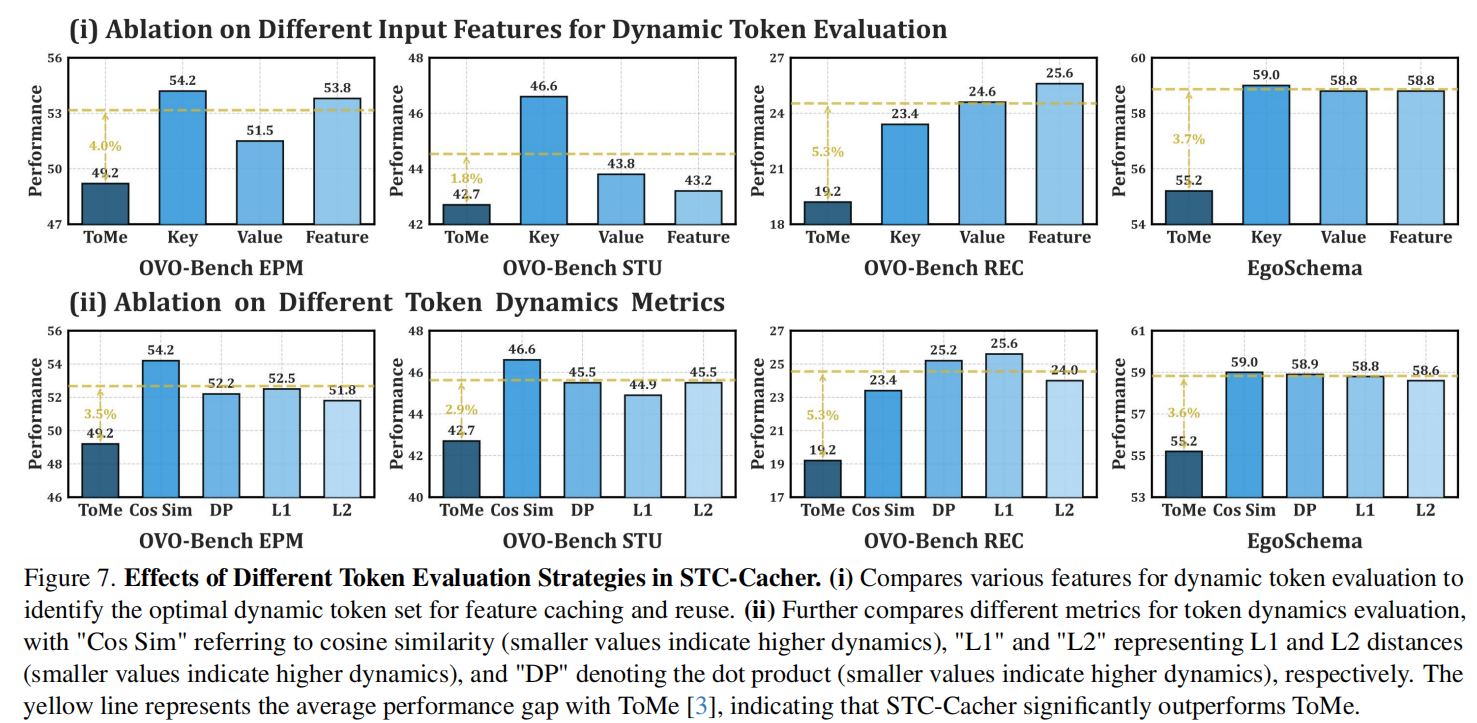
-
模块独立性:STC-Cacher 显著降低了 ViT 的计算负担,而 STC-Pruner 在减少 LLM 处理的序列长度方面效果卓著 。
-
鲁棒性:即便在极高的剪枝比例下,双锚点策略也能确保关键的语义标记(如移动的物体、新出现的文字)不被误删 。
5. Conclusion
本研究提出了 Streaming Token Compression (STC) 框架,通过 STC-Cacher 解决 ViT 编码中的时间冗余,以及通过 STC-Pruner 解决 LLM 预填充阶段的序列长度挑战 。该方法不仅保留了流式处理所需的因果性,还在无需重新训练的前提下显著提升了现有 VideoLLM 的实时性能。实验结果证明,STC 是在延迟敏感应用中部署大规模视频语言模型的一种高效且实用的解决方案 。