1. Motivation
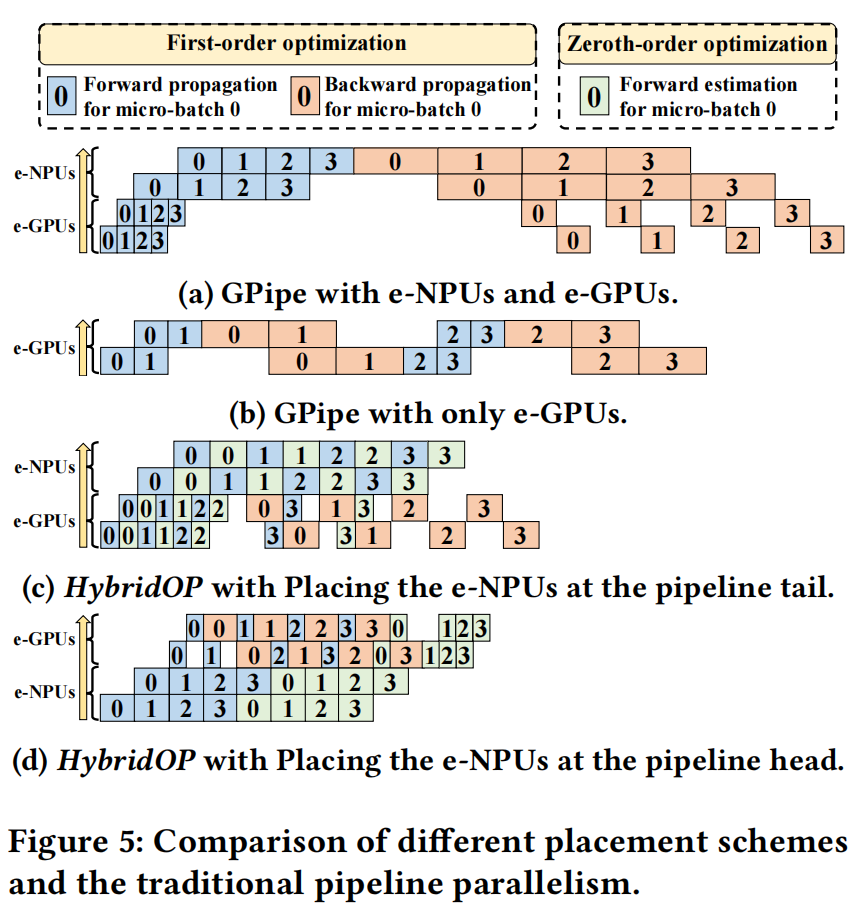
目前边缘GPU(e-GPUs)和边缘NPU(e-NPUs)在硬件架构上存在显著差异,导致运行性能上有很大不同。例如,研究测量显示,某些e-NPUs仅进行前向传播的计算能力在进行反向传播时会降低10倍。具体来说,大多数边缘NPU(e-NPU)设备专为推理任务设计,只支持前向传播(FP),缺乏反向传播(BP)所需的BroadcastGradient和ReluGrad操作,这使得它们不兼容训练或微调任务。以Atlas 200I(e-NPU)的测量结果为例,如图1所示,其仅进行前向传播的计算能力为20 TOPS,而在进行反向传播时会降低约10倍至2.4 TOPS。这与Jetson Orin Nano等e-GPUs形成鲜明对比,后者的前向传播(FP)和反向传播(BP)计算能力保持相同的34 TOPS。因此,当使用现有并行方法将e-NPUs和e-GPUs统一用于LLMs微调时,e-NPUs上的慢速反向传播必然会增加整体延迟,如图5a所示。

因此,如何将e-GPUs和e-NPUs统一到单一的流水线并行中,以实现高效的LLMs微调,是一个尚未充分探索且具有挑战性的问题。
2. Preliminary
与通过反向传播计算梯度的BP-enable设备(e-GPUs)不同,BP-free设备(e-NPUs)仅使用前向传播基于方向导数估计梯度。具体来说,当使用参数高效方法如LoRA微调LLM $\Theta$时,带有可训练参数$\theta$和损失函数$L$的$\Theta$,在小批量$B = {b_1, …, b_M}$上的估计梯度可计算如下:
$$\hat{\nabla}L(\theta|\Theta) = \frac{L(\theta + \epsilon\mathbf{z}|\Theta; B) - L(\theta|\Theta; B)}{\epsilon}\mathbf{z} = g(\mathbf{z})\mathbf{z},$$
其中$L(\theta + \epsilon\mathbf{z}|\Theta)$表示可训练参数$\theta$在方向$\mathbf{z} \sim \mathcal{N}(0, I_d)$上扰动后的损失,这是对可训练参数的随机扰动。$d$表示可训练参数的大小,$\epsilon$表示标量步长。$g(\mathbf{z}) = \frac{L(\theta+\epsilon\mathbf{z}|\Theta;B) - L(\theta|\Theta;B)}{\epsilon}$表示随机方向$\mathbf{z}$的方向导数。因此,基于两次前向传播,作者可以获得$\theta$在方向$\mathbf{z}$上的下降尺度。
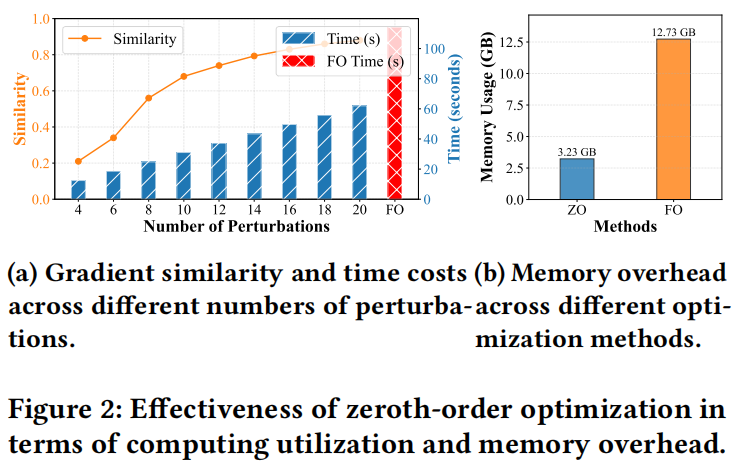
图2a显示了估计梯度与通过带反向传播的一阶优化计算的梯度之间的相似性。作者观察到,添加扰动可以使估计梯度更接近BP梯度,同时仍比一阶优化实现更低的执行时间,如图2a所示。因此,为进一步减少估计方差并稳定微调,估计梯度可以通过对$Q$个独立采样方向$\mathbf{z}_q \sim \mathcal{N}(0, I_d)$取平均来计算:
$$\hat{\nabla}L(\theta|\Theta) = \frac{1}{Q}\sum_{q=1}^{Q}\frac{L(\theta + \epsilon\mathbf{z}_q|\Theta; B) - L(\theta|\Theta; B)}{\epsilon}\mathbf{z}_q,$$
此外,使用零阶优化估计梯度消除了对反向传播和中间激活保存的需求,从而减少了内存消耗,如图2b所示。
3. Contribution
- 作者首次提出了一种统一e-GPUs和e-NPUs的单一pipeline并行方案,用于高效的LLMs微调,该方案融合了无BP的零阶优化和一阶优化,以加速整体微调收敛。
- HybridOP的核心设计解决了两个关键挑战:跨异构e-GPUs和e-NPUs的LLM层划分和计算利用率提升。具体来说,作者开发了专用的成本模型来表征执行延迟和内存开销,这些模型专为HybridOP pipeline定制。分区规划器随后为e-NPUs和e-GPUs采用不同的搜索策略,以高效识别最优层分区方案,从而最小化执行延迟。
- 大量实验表明了HybridOP的收敛性和有效性。与最先进的基线Asteroid相比,HybridOP将计算利用率提高了0.8倍,吞吐量提高了27.7%,并减少了41.2%的收敛时间,用于使用4个e-NPUs和6个e-GPUs微调LLaMA-3.1-8B模型。
4. HYBRIDOP SYSTEM DESIGN
4.1 Overview
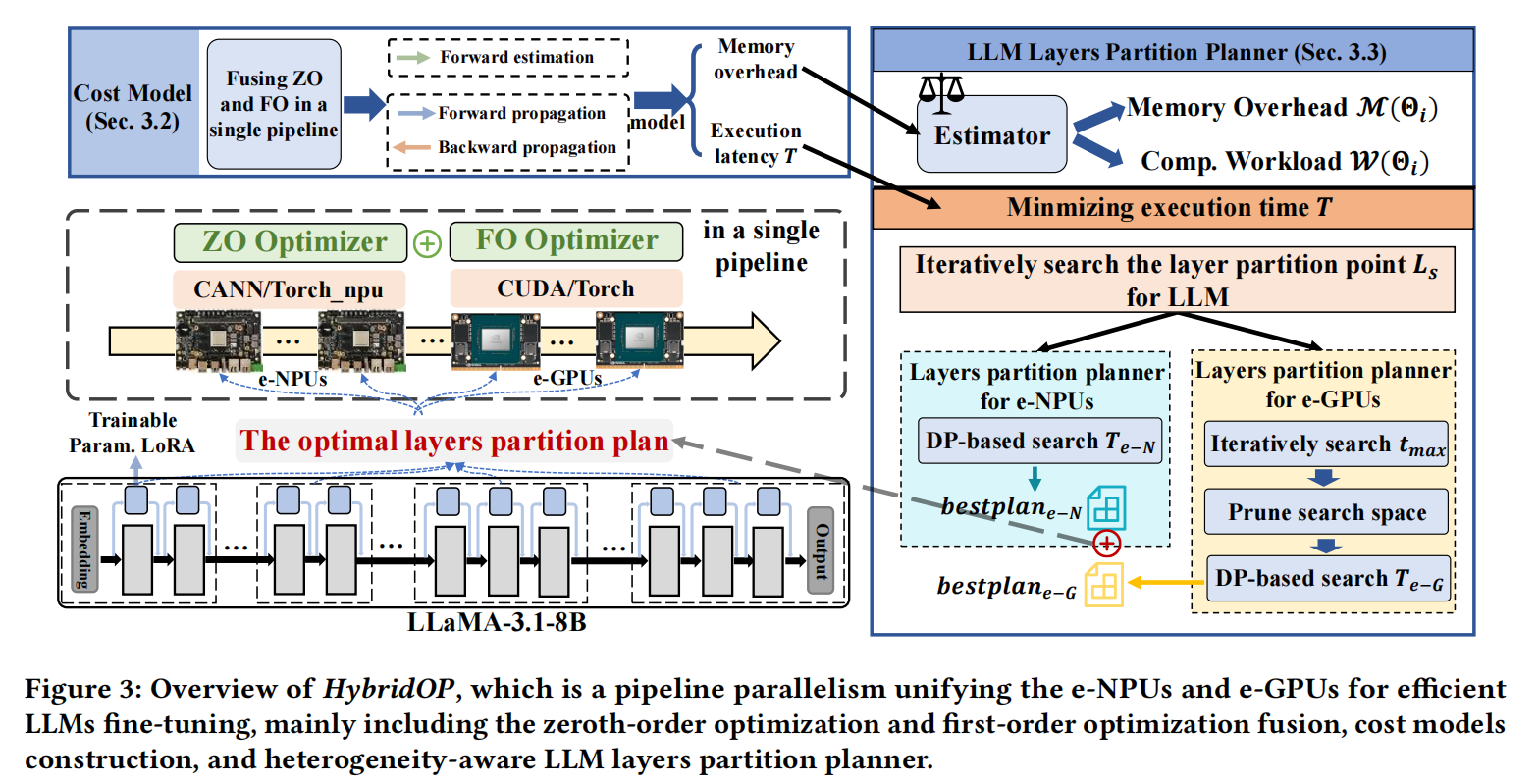
在HybridOP并行方案中,e-GPUs使用反向传播计算BP梯度,而e-NPUs使用多次前向传播计算估计梯度。首先,这些e-GPUs和e-NPUs协作执行第一次前向传播,并获取相应的无扰动基础损失(蓝色箭头)。然后,e-NPU设备生成可训练参数的随机扰动,并基于这些扰动参数执行前向传播(绿色箭头)。同时,e-GPU设备执行反向传播以计算BP梯度(橙色箭头)。流水线的最后一个设备计算损失和对应于随机扰动的方向导数$g(\mathbf{z})$,并将$g(\mathbf{z})$传输到所有e-NPU设备。e-NPU设备基于公式(10)计算估计梯度。最后,所有异构设备在流水线中获取小批量$b_i$的梯度。
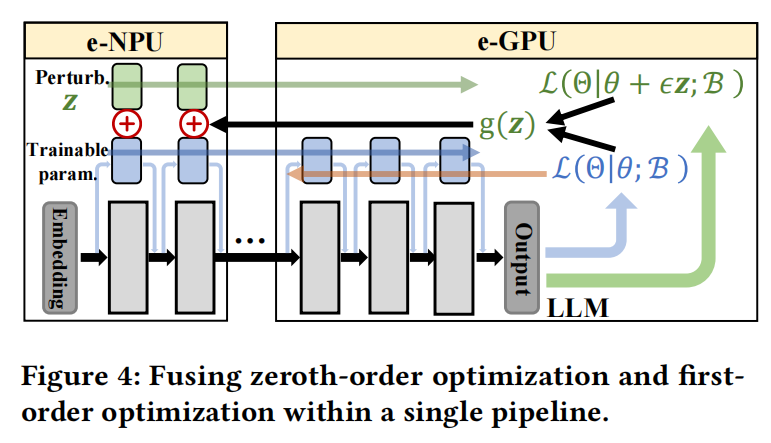
将零阶优化的估计梯度和一阶优化的真实梯度融合到单一流水线中时,需要解决一些棘手的挑战: (1) 如何将LLM层划分到流水线中的异构设备上,以最小化执行延迟? (2) 如何在不延长执行延迟的情况下进一步提高计算利用率?
因此,在这项工作中,作者提出了HybridOP,一种新颖的流水线并行方案,能够高效地统一异构e-NPUs和e-GPUs,并充分发挥计算潜力,如图3所示。具体来说,作者构建了专用的成本模型,这些模型表征了针对HybridOP流水线定制的执行延迟和内存开销,并分析了最优设备放置方案。然后,新设计的LLM层分区规划器为异构e-NPUs和e-GPUs采用不同的搜索策略,快速搜索最优层分区计划,从而最小化执行延迟。作者进一步引入基于零阶优化的提前退出微调,以提高计算利用率。
4.2 Cost Model: Execution Latency and Memory Overhead
与现有流水线不同,HybridOP流水线中的异构设备以不同的计算模式进行微调。这些设备的不同放置方案将影响整体收敛性能和流水线效率。在这里,作者从两个方面分析这些e-NPU和e-GPU设备不同放置方案的影响:执行延迟和内存开销。
执行延迟。如图5所示,作者比较了不同的设备放置方案与传统的流水线并行GPipe,使用四个设备和四个微批次在一个流水线迭代中。作者假设每个设备的前向传播时间为$t_i$,通常来说,其反向传播时间可以表示为$2 \cdot t_i$。因此,对于GPipe,其在单次迭代中的总时间为:
$$T_{gpipe} = 3 \cdot (\sum_{i \in D_{e-G} \cup D_{e-N}} t_i + (M - 1) \cdot \max_{i \in D_{e-G} \cup D_{e-N}}{t_i}),$$
其中$M$表示小批量中的微批次数。此外,如图5b所示,当使用没有e-NPUs的GPipe时,LLM仅在这些e-GPU设备上分区。由于分配给单个设备的层数增加,前向传播的执行时间增加,流水线中的微批次数减少。
如图5c所示,在HybridOP流水线中,e-NPU设备放置在流水线尾部,e-GPU设备放置在流水线头部。e-GPUs在e-NPUs通过多次前向传播获得估计梯度后计算BP梯度。因此,其在单次迭代中的总时间为:
$$T_{tail} = 3\sum_{i \in D_{e-G}} t_i + \sum_{i \in D_{e-N}} t_i + ((1+Q)M-1) \cdot \max_{i \in D_{e-N}}{t_i}.$$
如图5d所示,e-NPU设备和e-GPU设备分别放置在流水线头部和尾部。这些e-NPUs和e-GPUs首先对多个微批次执行前向传播,计算它们相应的无扰动基础损失。随后,e-GPU设备执行反向传播以获取BP梯度,e-NPU设备扰动LLM的可训练参数以获取估计损失,然后计算估计梯度。单次迭代的总时间为:
$$T_{head} = \sum_{i \in D_{e-N}} t_i + 3\sum_{i \in D_{e-G}} t_i + 3(M-1)\max_{i \in D_{e-G}}{t_i} + MQ t^*,$$
其中$t^*$表示流水线中第一个e-GPU设备的前向执行时间。
为便于比较,作者假设e-GPU的计算能力是e-NPU的ZO计算能力的两倍,是e-NPU的FO计算能力的三倍。因此,四种流水线方案的单次迭代时间分别为51$t_i$、36$t_i$、24$t_i$和23$t_i$。因此,HybridOP流水线可以同时减少执行延迟,并且将e-NPU设备放置在流水线头部可以进一步扩大优势。
内存开销。作者从两部分分析每个设备的内存开销:$M_{states}$和$M_{act}$。$M_{states}$表示存储模型参数、梯度和优化器状态所需的内存。$M_{act}$表示维护用于在反向传播中计算梯度的前向传播中间激活所需的内存。
对于GPipe,所有设备协作维护单个完整LLM,因此$M_{states} = \lambda_1|\Theta| + (\lambda_2 + \lambda_3)|\theta|$,其中$\lambda_1$、$\lambda_2$和$\lambda_3$分别表示参数、梯度和优化器状态在内存中占用的字节数。考虑到激活的内存$M_{act}$,所有设备在对所有微批次执行前向传播后执行反向传播,因此所有设备保留的中间激活受模型大小和可训练参数影响,与微批次数线性相关,即$M_{act} = M|\Theta|$。
在HybridOP并行方案中,所有设备仍然协作维护单个完整LLM,因此$M_{states} = \lambda_1|\Theta| + (\lambda_2 + \lambda_3)|\theta|$与GPipe相同。然而,由于e-NPU设备不需要执行反向传播,因此不需要保留中间激活。因此,HybridOP并行方案可以减少部分激活所需的内存。此外,HybridOP并行方案使所有e-GPUs在接收到梯度后立即执行反向传播。因此,GPU设备在流水线中的位置越靠前,保留的中间激活就越多。给定完整LLM为$\Theta = {L_1, .., L_K}$,包含$K$层,设$\Theta_i = {L_k}{l_i}^{r_i}$表示分配给每个设备的层。因此$\Theta = {\Theta_i}{i \in D_{e-N} \cup D_{e-G}}$。对于一个小批次,内存开销与分配的模型大小线性相关,可以表示为$\lambda_4|\Theta_i|$。当将e-NPUs放置在流水线尾部时,每个e-GPU设备的激活所需内存为$\lambda_4(|D_{e-N}| + |D_{e-G}| - i)|\Theta_i|$。HybridOP流水线中激活所需的总内存$M_{act} = \lambda_4\sum_{i \in D_{e-G}}((|D_{e-N}| + |D_{e-G}| - i)|\Theta_i|)$。当将e-NPUs放置在流水线尾部时,每个e-GPU设备的激活所需内存为$\lambda_4(|D_{e-G}| - i)|\Theta_i|$。HybridOP流水线中激活所需的总内存$M_{act} = \lambda_4\sum_{i \in D_{e-G}}((|D_{e-G}| - i)|\Theta_i|)$。因此,将e-NPUs放置在流水线头部的HybridOP并行方案可以显著减少内存开销,从而提高流水线的吞吐量,如图5所示。
4.3 LLM Layers Partition Planner
HybridOP的目标是充分利用异构e-GPU和e-NPU设备的计算潜力,加速设备上的LLM微调。如第3.2节所述,e-NPU设备应放置在HybridOP流水线头部。在HybridOP并行方案中,每次迭代的执行延迟为$T_{head}$,如公式(5)所述。为简化,作者将其表示为$T$。然后,作者通过搜索跨异构设备的最优层分区计划来设计新的LLM分区规划器,以最小化执行延迟$T$,如下所示:
$$\min T = \sum_{i \in D_{e-N}} \underbrace{t_i}{T{e-N}} + 3\sum_{i \in D_{e-G}} t_i + 3(M - 1)\max_{i \in D_{e-G}}{t_i} + MQ t^* \underbrace{}{T{e-G}},$$ $$\text{s.t. } t_i = \frac{W(\Theta_i)}{p_i},$$ $$M(\Theta_i) \leq m_i,$$
其中$T_{e-N}$和$T_{e-G}$分别表示影响$T$的e-NPUs和e-GPUs的执行延迟。$\Theta_i = {L_k}_{l_i}^{r_i}$表示分配给每个设备的层,其中$l_i$和$r_i$分别表示这些层的开始和结束。$W(\Theta_i)$表示模型$\theta_i$执行前向传播所需的计算工作量。$M(\Theta_i)$表示微调模型$\theta_i$所需的内存开销。
估计器。为了快速确定给定任何分区计划的执行延迟,作者首先估计影响$T$的两个关键因素:$M(\Theta_i)$和$W(\Theta_i)$。如第3.2节所述,微调所需的内存来自$M_{state}$和$M_{act}$。e-NPU设备不维护中间激活,因此e-NPU的内存开销为$M(\theta_i) = \lambda_1|\Theta_i| + (\lambda_2 + \lambda_3)|\theta_i|$。e-GPU设备需要维护额外的中间激活,其大小取决于分配的模型大小和在HybridOP流水线中的深度。因此,作者估计e-GPU设备的内存开销$M(\Theta_i) = \lambda_1|\Theta_i| + (\lambda_2 + \lambda_3)|\theta_i| + \lambda_4(|D_{e-G}| - i)|\Theta_i|$。作者预先测量不同部分层和维护激活所需的相应内存开销,以拟合系数$\lambda_4$。
考虑到前向传播的计算工作量$W(\Theta_i)$,它可以通过累积多个不同层的计算工作量来估计,即$W(\Theta_i) = \sum_{k \in (\Theta_i)} W(L_k)$。因此,作者预先测量LLM中不同层的计算工作量,以计算$W(\Theta_i)$。基于这些估计,作者可以快速获取任何给定层分区计划下每个设备的内存开销和计算工作量。
在HybridOP流水线中,e-NPUs和e-GPUs分别放置在流水线头部和尾部。为了搜索最优层分区方案,作者分别搜索e-NPUs和e-GPUs的层分区,以降低搜索复杂度。作者首先迭代搜索层分区$s$,其中${L_1, .., L_s}$层和${L_{s+1}, .., L_l}$层分别在e-NPUs和e-GPUs上分区。为降低搜索复杂度,作者设计了异构感知搜索算法,包括两个高效的动态规划(DP)算法,分别用于最小化$T_{zo}$和$T_{fo}$,如算法1所述。
最小化$T_{e-N}$。直观上,前$k$层的最小执行时间由前$k-1$层决定,这意味着最优解可以从子问题的最优结果构建,这促使作者使用动态规划来解决最优分区。因此,作者设计了一个层分区DP算法,搜索e-NPU设备的最优层分区${[l_i, r_i]}{i \in D{e-N}}$。设$DP_{e-N}(D_i, L_k)$表示e-NPU设备${D_1, .., D_i}$覆盖前$k$层${L_1, …, L_k}$所使用的最小总执行时间。状态转移方程表述为:
$$DP_{e-N}(D_i, L_k) = \min_t (DP_{e-N}(D_{i-1}, L_t) + t_{e-N}(D_i, L_{t+1}, L_k))$$
其中$t_{e-N}(D_i, L_{t+1}, L_k) = \frac{W(\Theta_i)}{p_i}$表示在第$i$个e-NPU设备上对由这些层${L_{t+1}, …, L_k}$组成的$\Theta_i$执行前向传播所需的时间,$t \in [i-1, k-1]$。公式(7)显示$DP_{e-N}(D_i, L_k)$通过遍历所有在$(i-1)$-th层和$(k-1)$-th层之间的可能层来确定,并选择最小化前$k$层执行延迟的那个。搜索从$(i-1)$-th层开始的原因是确保前$i-1$个设备每个至少分配一层。当$i = |D_{e-N}|$和$k = s$时,作者搜索最小的$T_{e-N} = DP_{e-N}(D_{|D_{e-N}|}, L_s)$和e-NPUs对应的最优分区计划。此外,在搜索过程中,需要确保总内存消耗不超过设备的可用显存,即$M(\Theta_i) \leq m_i$。
最小化$T_{e-G}$。类似于最小化$T_{e-N}$,这里作者设计层分区DP算法,搜索e-GPU设备的最优层分区${[l_i, r_i]}{i \in D{e-G}}$,以最小化$T_{e-G}$。由于$\max$操作$\max_{i \in D_{e-G}}{t_i}$不能直接用于DP搜索,作者首先枚举$\max$项$t_{max} = \max_{i \in D_{e-G}}{t_i}$,并对每个不同的$t_{max}$最小化以下方程:
$$T_{e-G} = 3\sum_{d_i \in D_{e-G}} t_i + MQ t^* + 3(M - 1)t_{max}.$$
设$DP_{e-G}(D_i, L_k)$表示设备${D_1, .., D_i}$覆盖$j$层${L_{s+1}, …, L_{s+k}}$所使用的最小总执行时间。对于第一个e-GPU设备,$DP_{e-G}(1, j) = (3 + MQ)t_{e-G}(D_1, L_{s+1}, L_{s+j})$。状态转移方程表述为:
$$DP_{e-G}(D_i, L_k) = \min_t (DP_{e-G}(D_{i-1}, L_t)) + 3t_{e-G}(D_i, L_{s+t+1}, L_{s+k})),$$
其中$t_{e-G}(D_i, L_{s+t+1}, L_{s+k}) = \frac{W(\Theta_i)}{p_i}$表示在第$i$个e-GPU设备上对由这些层${L_{s+t+1}, …, L_{s+k}}$组成的模型$\Theta_i$执行前向传播所需的时间,$t \in [\max{s+1, i-1}, k-1]$。公式(9)显示,当$\max$项固定时,$DP_{e-G}(D_i, L_k)$通过遍历所有可能层来确定,并选择最小化前$k$层执行延迟的那个。当$i = |D_{e-G}|$和$k = K$时,作者获得最优值$DP_{e-G}(D_{|D_{e-G}|}, L_K)$和固定$t_{max}$对应的最优层分区。随后,通过比较不同$t_{max}$下的$DP_{e-G}(c, s) + 3(N-1)t_{max}$,作者确定最优分区计划。
此外,作者确定$t_{max}$的下限和上限以加速搜索。其下限为$\frac{W(\sum_{i \in D_{e-G}} \Theta_i)}{\sum_{i \in D_{e-G}} p_i}$,上限为$\frac{W(\sum_{i \in D_{e-G}} \Theta_i)}{\min_{i \in D_{e-G}} p_i}$。此外,在枚举$t_{max}$时,作者评估$t_{max}$比上一个$t_{max}$至少大$\varepsilon$的情况。
复杂度分析。在时间复杂度方面,在所有可能的层分区$s$上运行两个DP算法的成本为$\sum_{s=1}^K [O(|D_{e-N}| \cdot s^2) + O(|D_{e-G}| \cdot (l - s)^2 I)]$,其中$I$是$t_{max}$的搜索迭代次数。


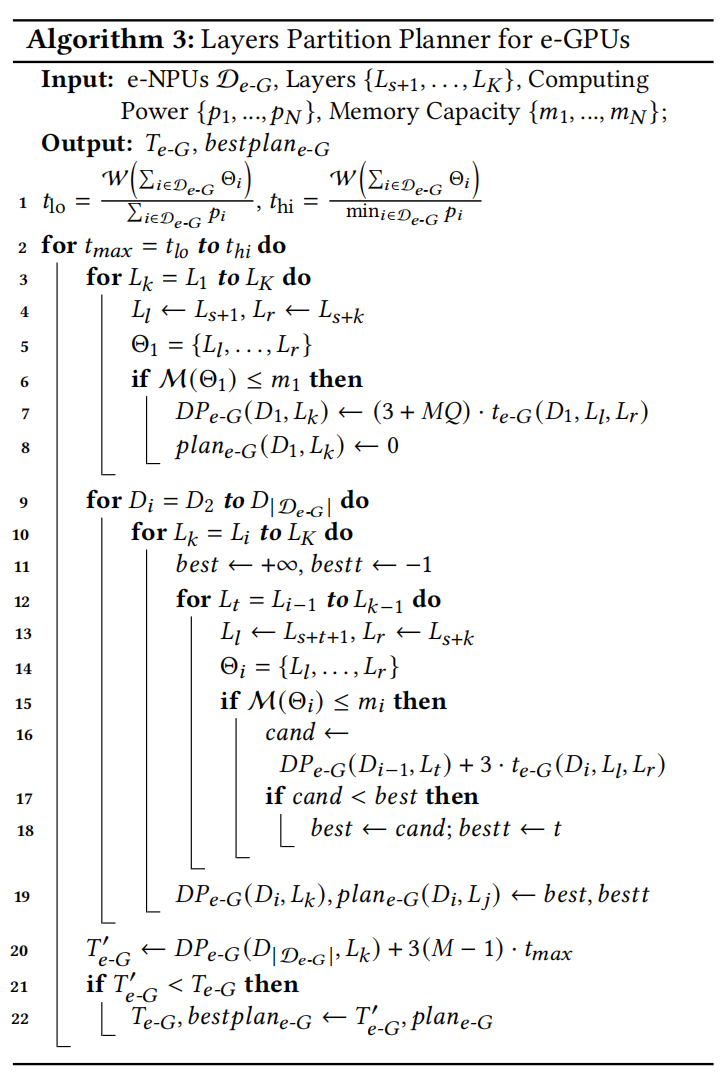
4.4 Zeroth-order Early-exit Fine-tuning
在HybridOP流水线中,e-GPU设备位于流水线尾部,这些设备的前向和反向传播都依赖于零阶设备的前向传播。此外,它们还需要为e-NPU设备执行前向估计并计算估计损失。当设计的LLM分区规划器在异构e-GPUs和e-NPUs上实现相对平衡的计算工作量时,e-NPU设备将经历一些空闲时间,如图6顶部所示。为了充分利用计算能力,作者进一步设计了一种新颖的提前退出微调模式,以增加e-GPUs和e-NPUs上计算的并行性,如图6底部所示。
现有的一些工作使用提前退出机制来减少LLM微调的复杂性和收敛时间。作者在最后一个零阶设备上添加一个额外的输出层,以执行提前退出并计算估计损失。具体来说,在e-NPUs完成所有微批次的$Q$次前向估计后,作者将微批次注入流水线,并再次执行$Q’$次扰动。与之前的$Q$次前向估计不同,提前退出前向估计在执行e-NPUs的前向传播后直接进入提前退出层。最后一个e-NPU设备从最后一个e-GPU获取基础损失,并计算小批量$b_i$的估计损失以及相应的梯度,如下所示:
$$\hat{\nabla}L’(\theta’|\Theta) = \frac{1}{Q’}\sum_{q=1}^{Q’}\frac{L’(\theta’ + \epsilon\mathbf{z}_q|\Theta;b_i) - L(\theta|\Theta;b_i)}{\epsilon}\mathbf{z}_q,$$
其中$\theta’$表示由e-NPU设备层和提前退出输出层组成的提前退出模型。通过引入提前退出微调机制,作者可以进一步利用HybridOP流水线中的空闲计算资源。此外,在e-NPU设备上添加可训练参数扰动的方向可以进一步提高训练稳定性和收敛性能。

4.5 Convergence Analysis
为了分析所提出的HybridOP的收敛性,作者首先界定估计梯度相对于实际随机梯度的误差。然后,在关于梯度的Lipschitz连续性和有界梯度方差的温和假设下,作者可以获得平均梯度范数的上界:
$$\frac{1}{\Gamma}\sum_{\tau=1}^{\Gamma} \mathbb{E}[|\nabla F(\theta_{\tau})|^2] \leq O(\frac{\mathbb{E}[F(\theta_1)] - \mathbb{E}[F(\theta_{\Gamma+1})]}{\sqrt{\Gamma}} + \frac{1}{\sqrt{\Gamma}}\delta^2 + \frac{1}{\sqrt{\Gamma}}\sigma^2),$$
其中$F(\theta) := \mathbb{E}_{B \sim S}[L(\theta; B)]$,$\tau$表示迭代索引,$\Gamma$表示总迭代次数,$\delta$表示估计梯度与真实随机梯度的误差界限,$\sigma$表示随机梯度方差的上限。这表明HybridOP可以达到渐近最优的收敛率$O(1/\sqrt{\Gamma})$,与一般非凸设置的速率相匹配。详细内容可在附录A中找到。
5. Evaluation
5.1 Experimental Setup
硬件测试平台。作者构建了真实世界的硬件测试平台,包括边缘NPUs:华为Atlas 200I DK A2,以及边缘GPUs:NVIDIA Jetson Orin,Xavier。详细的内存容量、计算能力和功耗模式如表1所示。
实现。作者为Atlas 200I DK A2设备配置CANN版本8.0,为所有Jetson设备配置Jetpack版本5.2。HybridOP系统使用PyTorch和torch_npu库实现。HybridOP和所有基线模型中异构设备之间的通信使用带有GLOO后端的torch.distributed实现。HybridOP的核心使用1300多行Python代码实现。
基线。作者选择了7个广泛使用的基线:
- 张量并行(TP):Accpar将层划分为具有不同张量大小的异构设备。
- 流水线并行(PP):GPipe将模型划分为流水线中的顺序阶段。PipeDream-Flush在获得梯度后立即执行反向传播,以减少激活所需的内存开销。Chimera是一种双向流水线方案,将两个流水线阶段放在每个设备上,以减少气泡率。
- 混合并行(HP):混合数据并行(HDP)通过在异构GPU集群上使用组内PP和组间DP,促进并行训练。Dapple提出了一种混合流水线并行,使用组内DP和组间PP。Asteroid采用混合流水线并行,并将层分区,以在资源有限的场景中最大化吞吐量。
微调和评估。作者对LLaMA-3.2-3B和LLaMA-3.1-8B进行了参数高效微调LoRA实验,使用三个不同的NLP数据集:(1) AGNEWS数据集是一个具有4个类别的序列分类数据集,包括12万个训练样本和7.6k测试样本。序列的最大长度设置为384。(2) Multi-RC数据集是一个问答数据集,包括>27k训练样本和>4.8k测试样本。序列的最大长度设置为1024。(3) SQuAD数据集是一个阅读理解数据集,其中每个问题的答案是相应阅读段落的一段文本或跨度。训练和测试样本的数量分别为>87k和>10k。同样,序列的最大长度设置为1024。
对于所有实验,作者测量吞吐量(样本/秒)、收敛时间和收敛性能(F1分数)。此外,为了评估计算利用率,作者使用评估指标$Comu_{ti}$,表示总时间中的计算时间。对于流水线并行,$Comu_{ti}$和气泡率相加为1。
实验设置。对于微调LLaMA-3.2-3B模型,作者使用2个Atlas 200I DK A2 + 2个Jetson Orin Nano + 2个Jetson Orin NX。对于LLaMA-3.2-8B模型,作者选择4个Atlas 200I DK A2 + 2个Jetson Orin Nano设备 + 2个Jetson Xavier NX + 2个Jetson Orin NX。为了公平起见,所有基线都是在有和没有Atlas设备的情况下进行的。
作者使用早停策略和Adam优化器微调LLMs,LoRA秩设置为8,LoRA alpha为16。每个小批次的扰动数量设置为不同LLMs的12和20。作者将AGNEWS和Multi-RC数据集的初始学习率设置为5e-5,SQuAD数据集设置为2e-5。
5.2 Efficiency of HybridOP
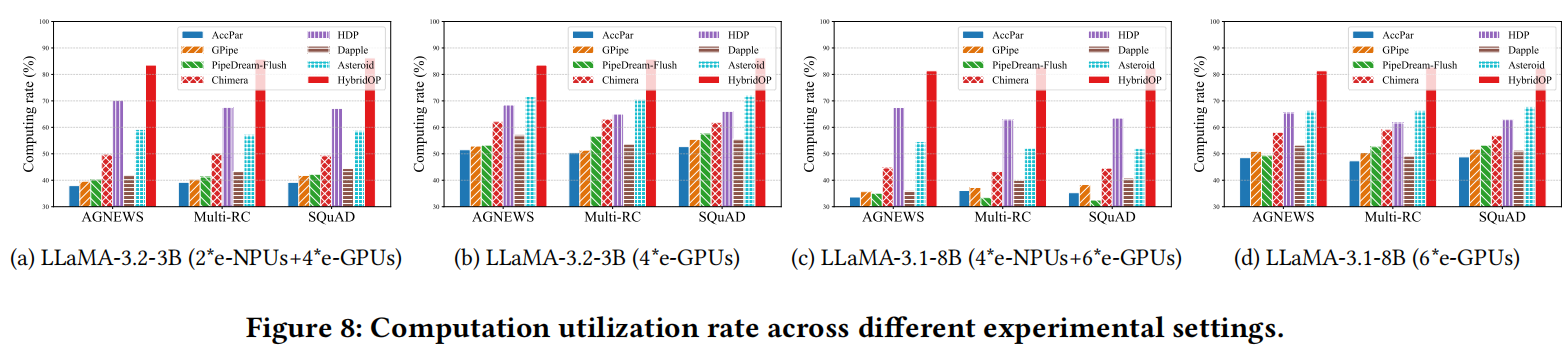
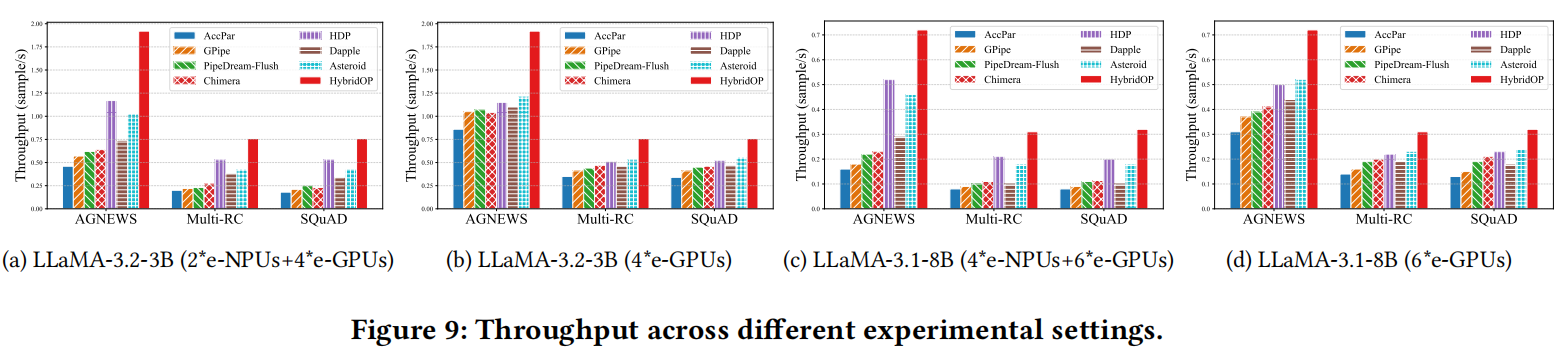
在本节中,作者将所有基线的计算利用率$Comu_{ti}$和吞吐量与所提出的HybridOP进行比较,如图8和图9所示。
与张量并行的比较。在跨不同任务微调LLaMA-3.2-3B和LLaMA-3.1-8B时,与AccPar相比,HybridOP的吞吐量提高了117.1%-322.2%和121.4%-350.0%。此外,HybridOP的计算利用率$Comu_{ti}$提高了26.6%-41.6%和27.5%-42.68%。此外,由于在异构设备(e-NPUs和e-GPUs)之间频繁进行全收集通信,AccPar的$Comu_{ti}$和吞吐量分别比流水线并行低9.4%-19.6%和10.0%-39.0%。
与流水线并行的比较。(1) 在跨不同任务微调LLaMA-3.2-3B和LLaMA-3.1-8B时,与GPipe相比,HybridOP实现了0.8×-3.0×的吞吐量提升和29.0%-44.7%的计算利用率提升。与PipeDream-Flush相比,HybridOP提供了0.6×-2.3×的吞吐量提升和25.7%-46.9%的计算利用率提升。这是因为GPipe和PipeDream-Flush都是为同构集群设计的,导致异构设备的层分区不平衡。(2) Chimera通过引入双向流水线减少气泡率。然而,在不同实验设置下,HybridOP将气泡率降低了18.41%-36.5%,同时将吞吐量提高了2.3倍。这表明HybridOP使e-NPUs和e-GPUs能够分别执行前向估计和反向传播来计算梯度,而无需依赖。(3) 观察到在使用e-NPUs的异构环境中,各种流水线并行和Accpar的平均吞吐量降低了0.43倍,计算利用率降低了13.1%。这是因为这些并行方法无法有效利用e-NPUs上ZO的计算能力,导致这些设备成为整个微调过程的瓶颈。
与混合并行的比较。(1) 与HDP相比,HybridOP在不同实验设置下实现了38.5%-67.0%的吞吐量提升,并将$Comu_{ti}$提高了10.34%-18.18%。与仅GPU配置相比,带有e-NPUs的HDP的吞吐量保持稳定甚至有所提升。这是因为HDP将e-NPU设备分成一个DP组,并为该组分配非常小的微批次(大小=1),确保不同设备组的执行延迟相似。(2) 与Dapple相比,HybridOP将吞吐量提高了2.2倍,最大吞吐量提升了42.2%。Dapple的吞吐量和$Comu_{ti}$最低,因为它无法根据异构资源调整计算和内存工作量。(3) Asteroid专为使用异构边缘设备微调模型而设计,是最先进的基线。在跨不同任务微调LLaMA-3.2-3B和LLaMA-3.1-8B时,HybridOP将吞吐量提高了0.8倍。与Asteroid相比,HybridOP将计算利用率提高了8.87%-27.7%。这些实验结果证实,HybridOP可以更充分利用异构资源,并确保流水线可以注入更大的批次以提高吞吐量。
5.3 Convergence Performance
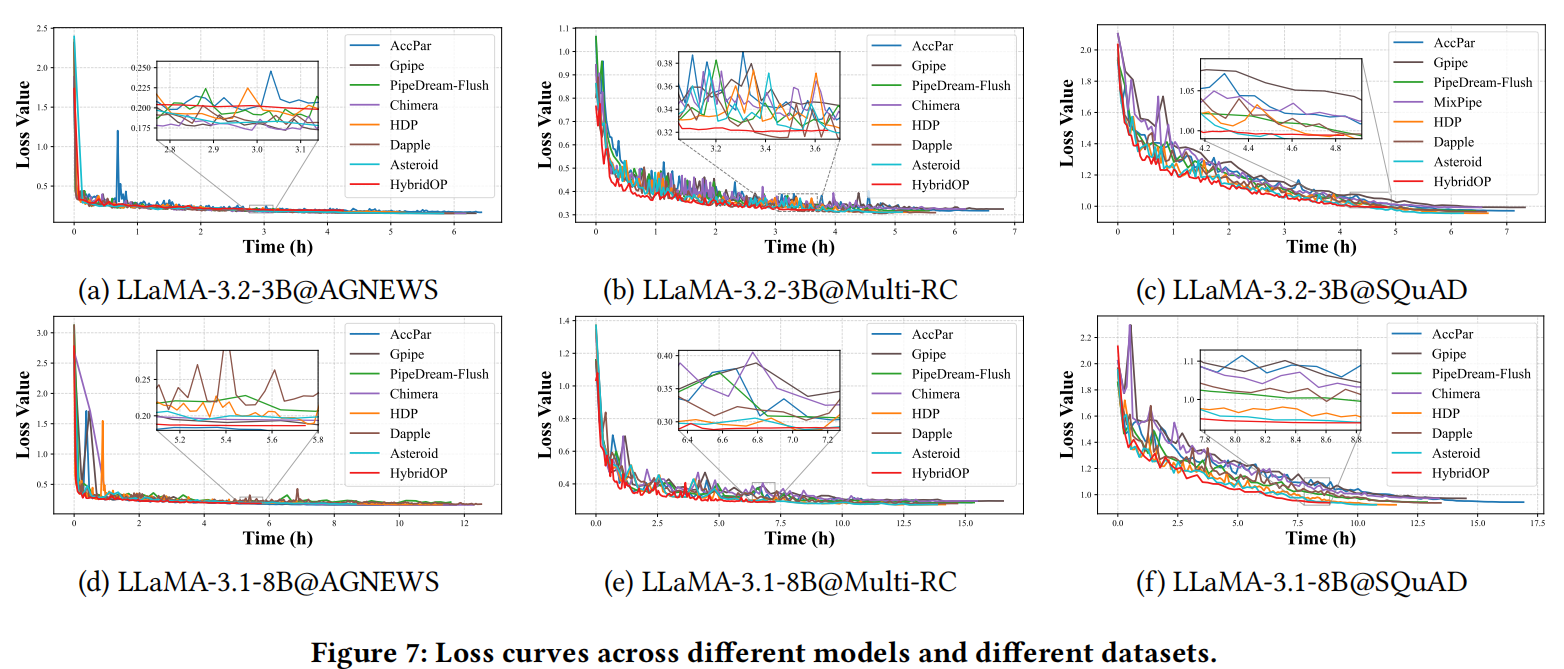
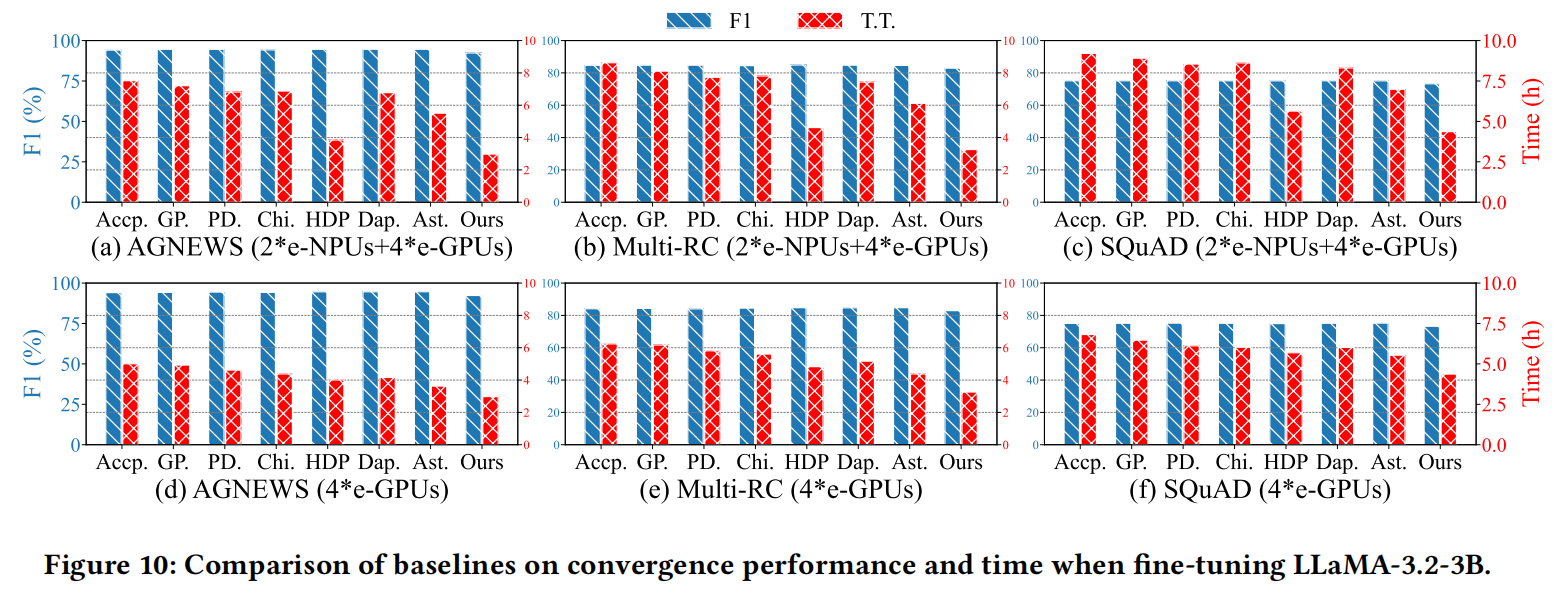
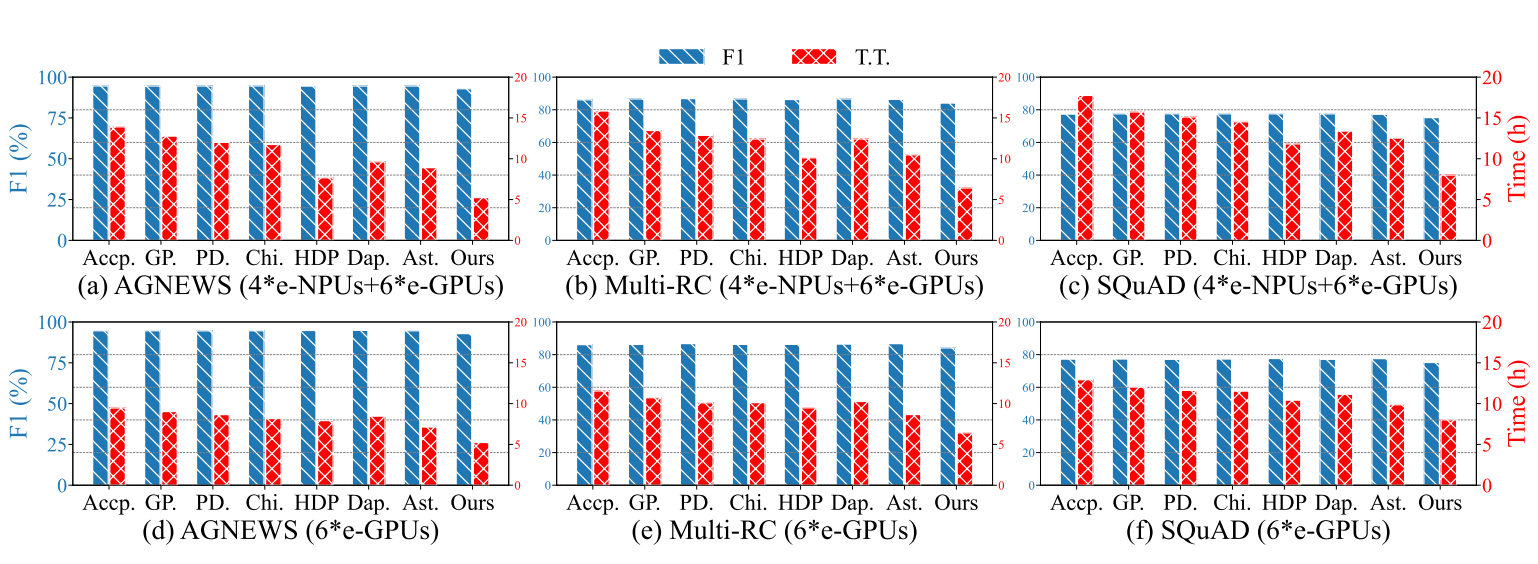
在本节中,作者进行了大量实验,证明HybridOP在保持可比较的收敛性能的同时,显著减少了各种模型和微调任务的收敛时间,如图7、图10和图11所示。图7描绘了在不同实验设置下使用各种并行方法进行微调的损失曲线。图10和图11显示了HybridOP和所有基线的最终收敛性能和收敛时间,说明HybridOP比所有基线实现了更快的收敛。
在三个NLP微调任务中,使用HybridOP微调的LLaMA-3.2-3B模型的收敛性能下降分别控制在1.61%、1.97%和1.89%以内,而收敛时间减少了165.5%。对于LLaMA-3.1-8B模型,HybridOP实现了高达146.9%的收敛加速,所有任务的性能仅牺牲了约2.37%。这些结果表明,HybridOP在各种微调任务和模型中有效地加速了收敛,同时保持了可比较的性能。收敛时间的显著减少进一步凸显了HybridOP在设备上LLMs微调场景中的实际优势。
5.4 Impact of Model Scale
HybridOP和所有基线在不同模型规模下表现出不同的性能。随着模型规模从3B增加到8B,AccPar、PipeDream-flush、Asteroid和HybridOP的平均收敛时间分别增加了89.7%、87.2%、57.8%和46.7%。HybridOP较小的增幅主要归因于新设计的LLM分区规划器和提前退出微调模块,这些模块最小化了执行延迟并提高了微调LLaMA-3.1-8B模型的吞吐量。随着模型规模的扩大,HybridOP为异构e-NPUs和e-GPUs分区层,以最小化执行延迟。与最先进的基线Asteroid相比,HybridOP仍然实现了0.8倍的吞吐量提升。这证明了HybridOP在最大化吞吐量和充分发挥计算潜力方面的有效性,即使在更大的模型规模下也是如此。
5.5 Perturbations Analysis
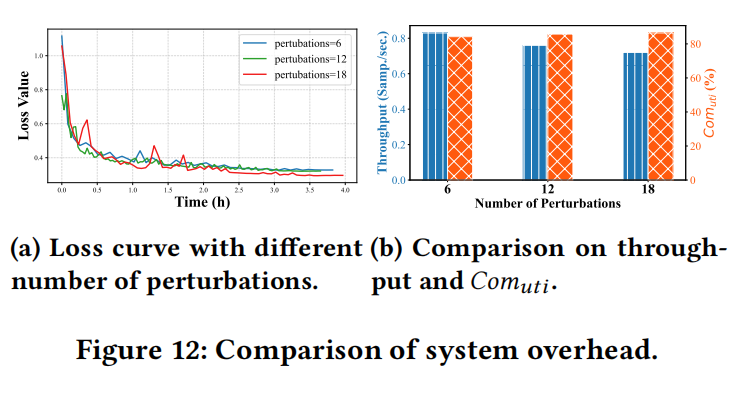
在本节中,作者研究了不同扰动数量对收敛性能和流水线效率的影响,如图12所示。随着扰动数量的增加,收敛损失减少,作者观察到将扰动数量设置为12时,收敛时间最短。这是因为增加扰动数量延长了每次迭代的时间,降低了整体吞吐量,从而延长了总收敛时间。此外,作者观察到,尽管扰动计数增加,HybridOP的计算利用率几乎保持不变。这是因为设计的提前退出微调模块有效地确保了流水线中空闲的e-NPUs得到充分利用。作者进一步分析了该模块的有效性。
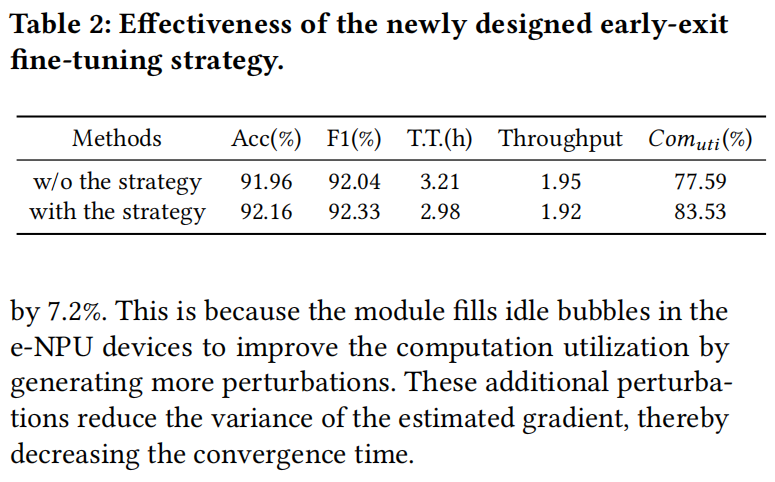
新设计的提前退出微调模块可以在保持高效流水线微调的同时增加扰动数量。因此,作者进行了一系列对比实验,证明该模块在使用AGNEWS数据集微调LLaMA-3.2-3B时的有效性。如表2所示,使用该模块将计算利用率提高了5.94%,将收敛时间减少了7.2%。这是因为该模块通过生成更多扰动来填充e-NPU设备中的空闲气泡,从而提高计算利用率。这些额外的扰动减少了估计梯度的方差,从而减少了收敛时间。
5.6 System Overhead
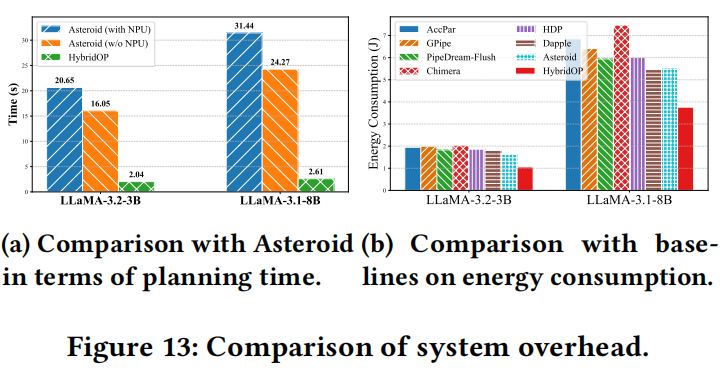
规划器开销。为了最小化单次迭代内的执行延迟,作者为HybridOP流水线新设计了LLM分区规划器,以确定异构设备的最优层分区计划。在这里,作者评估执行LLM分区规划器的时间开销。如图13a所示,Jetson Orin NX设备需要2.04秒来确定具有28个transformer块的LLaMA-3.2-3B模型的最优分区,对于具有32个transformer块的LLaMA-3.1-8B模型需要2.61秒。与Asteroid相比,搜索最优层分区的时间减少了8倍到12倍。与微调LLMs所需的执行延迟相比,HybridOP的规划时间可以忽略不计。
能耗。在这里,作者测量了使用AGNEWS数据集微调LLaMA-3.2-3B和LLaMA-3.1-8B模型时的能耗。如图13b所示,实验结果表明,HybridOP系统微调这两个模型每训练样本的能耗分别为1.06 J和3.76 J,与基线相比,最大减少了49.7%。这一改进可归因于减少的收敛时间和计算空闲时间。
6. Conclusion
为了充分发挥异构e-NPUs和e-GPUs的计算潜力,作者提出了HybridOP,一种新颖的流水线并行方案,将零阶优化和一阶优化融合到单一流水线中。HybridOP首先对不同设备放置方案的执行延迟和内存开销进行建模。然后,新设计的LLM分区规划器搜索最优层分区计划,以最小化执行延迟。为了进一步提高计算利用率并确保稳定微调,HybridOP设计了提前退出微调模块,在不延长执行延迟的情况下生成更多扰动。作者基于PyTorch和torch_npu实现了HybridOP,并在不同任务上对LLaMA-3B和LLaMA-8B进行了大量实验。数值结果表明,HybridOP显著优于现有的最先进技术。