
Conference: NeurIPS'25
Github: https://github.com/NVIDIA/kvpress
My Thoughts
- ChunkKV 假定“删除部分 token 不会丢失极其关键的细节”,在法律/医疗等需要逐字级别保真的场景可能不合适(论文明确指出)。
- 当前实现使用固定 size chunk(效率高但语义边界未显式对齐);未来可以尝试基于句法/语义边界的 adaptive chunk(但需权衡额外开销)。
1. Motivation
- 随着 LLM 处理超长上下文(tens of thousands tokens),KV cache 的内存成为推理阶段的主要瓶颈——例如 7B 模型单 token 的 KV cache 大约占 0.5MB,导致 10k token 的 prompt 消耗约 5GB GPU 内存。
- 现有压缩方法(H2O、SnapKV 等)通过删除被认为“不重要”的离散 token 来减少 KV 大小,但孤立地评估 token 重要度会破坏语义连贯性(会把主语或宾语切碎),从而在一些需要语义完整的任务上产生明显性能下降。论文通过示例强调:按 token 剪枝会保留与问题相关的某些词但漏掉关键对象信息,导致语义丢失。
问题:如何避免孤立 token 重要度评估,并在 KV cache 压缩时最大限度保存语义信息?
2. Challenge

- 以往方法在 token 维度上进行稀疏化/删减,忽略了自然语言语义通常以连续片段(chunk)出现的事实;因此需要一个按语义连续段(chunk)作为压缩单位的方法以保留“完整的语义单元”。
3. Contribution

- 发现并量化了“离散 token 压缩会破坏语义”的现象
- 提出 ChunkKV:以固定大小(或可调整)chunk 为单位做 KV 压缩,保留最有信息量的 chunk,尽可能保留主谓宾等语义完整性,并设计了layer-wise index reuse 技术来复用所选索引,从而显著降低额外计算开销。
- 在 LongBench、NIAH、GSM8K、JailbreakV 等多项 benchmark 以及多个模型(DeepSeek-R1、LLaMA-3、Qwen2、Mistral)上进行大规模评测,展示在相同压缩率下 ChunkKV 在准确率/召回/检索等方面优于现有方法,且在 latency/throughput 上得益于索引复用与向量化实现。
4. Method
4.1 Chunk-level compression
- 核心假设:自然语言中的“完整语义信息”通常由一段连续 token 构成(例如主语 + 谓语 + 宾语或整个短语)。将这些 token 作为整体(chunk)保留或删除,比以 token 为单位做稀疏更能保留语义。
- Chunk 的定义:论文采用固定大小滑窗分块(chunk size = $c$),将整个 Key/Value 序列按顺序分为 $C=\lceil T_k / c\rceil$ 个 chunk(最后一个 chunk 可能不足 $c$)。保留策略基于 chunk 的“重要性分数”(由 observe window 的 attention 得到)。
算法伪码:

Algorithm 1 ChunkKV(论文伪码,整理说明)
输入:
Q ∈ R^{T_q × d}, K ∈ R^{T_k × d}, V ∈ R^{T_v × d}
observe window size w
chunk size c
compressed KV cache max length L_max
步骤:
1. 计算 observe window 的 attention scores:
A ← Q_{t_q−w : t_q} K^T (注意 A 的尺寸是 R^{w × T_k})
2. 计算 chunk 数量:
C = ⌈ T_k / c ⌉
3. 对每个 chunk i(i = 1..C),计算 chunk attention score:
A_i = ∑_{j=(i−1)c+1}^{i c} ∑_{q=0}^{w−1} A_{q, j}
(即对 chunk 内所有 token 在 observe window 上的 attention 求和)
4. 选择 top-k chunks,k = ⌊ L_max / c ⌋ (确保压缩后 KV 长度 ≤ L_max)
kept_chunks = TopK(A_i, k)
5. 保证最近上下文(recent window)被保留:
把原始 KV 的最后 w tokens 强制置为保留(用于保持最近信息)
6. 构造选择 mask 并用 indices 做 index_select:
indices = concat(indices_from_kept_chunks, indices_of_recent_window)
K' = index_select(K, indices)
V' = index_select(V, indices)
输出:压缩后的 K', V'
4.2 Layer-Wise Index Reuse(层内索引复用)
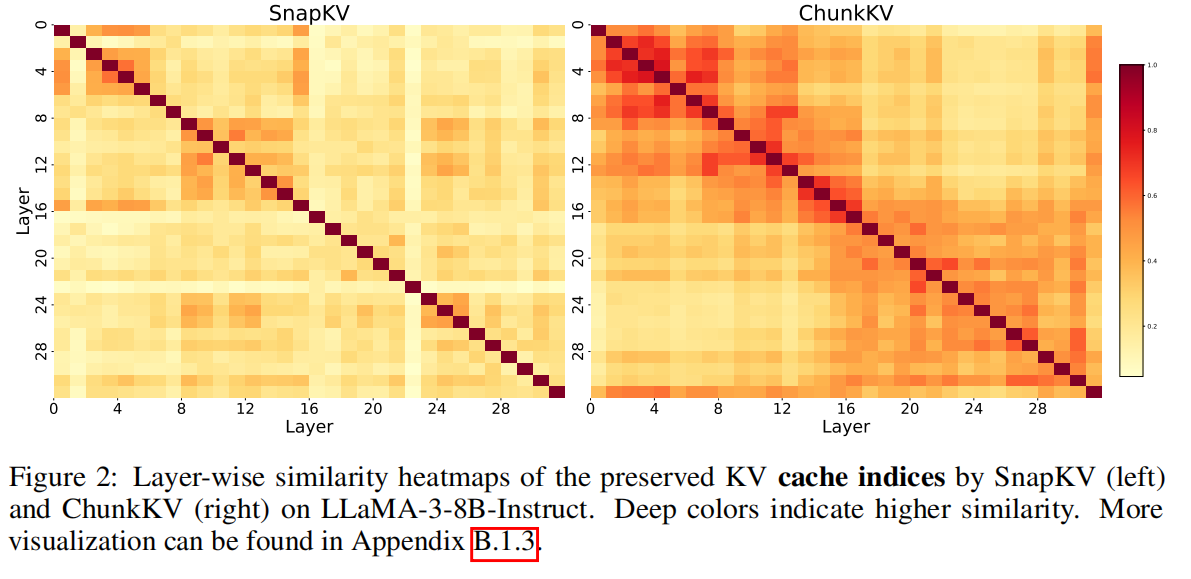
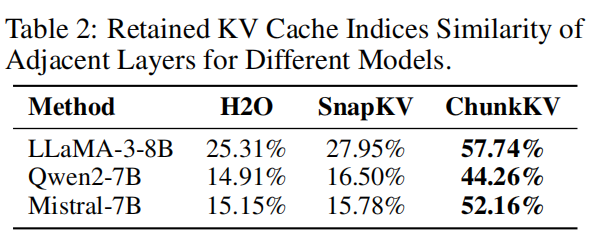
- 观测:ChunkKV 选出的 chunk 索引在相邻层之间具有高相似性(论文用 Jaccard similarity 统计,ChunkKV 在 LLaMA-3-8B 上相邻层平均相似度远高于 SnapKV),因此完全可以在若干连续层间共享索引。
- 算法:

Algorithm 2 Layer-Wise Index Reuse
输入:N_layers, N_reuse
初始化:I_reuse = {}
for l = 0 .. N_layers − 1:
if l mod N_reuse == 0:
(K'_l, V'_l, I_l) ← ChunkKV(K_l, V_l) # 做完整的 chunk 选择
I_reuse[l] ← I_l
else:
# 复用最近的 I_reuse entry
I_l ← I_reuse[floor(l / N_reuse) * N_reuse]
K'_l ← index_select(K_l, I_l)
V'_l ← index_select(V_l, I_l)
- 实测:论文在多个模型/任务上以
N_reuse = 2做评估,Latency/throughput 上均显著提升(见 Table 8);在 LongBench 上的性能下降通常 < 0.6%。
5. Evaluation
5.1 实验设置
- 模型:DeepSeek-R1-Distill-Llama-8B、LLaMA-3-8B-Instruct、LLaMA-3.1-8B-Instruct、Mistral-7B-Instruct、Qwen2-7B-Instruct(部分结果包含 70B 模型,Appendix)。模型参数/配置详见 Appendix E(表格列出 L、N、D 等)。
- benchmarks:GSM8K(及 many-shot 50-shot)、JailbreakV、LongBench(English + LongBench-ZH)、Needle-In-A-HayStack (NIAH)(8k / 32k length)、评价时使用 GPT-4o-mini 作为 judge(NIAH)。
- 压缩率 / KV size:常用比率有 10%、20%、30% 或固定 KV size(e.g., 128, 256, 512),chunk size 默认 $c=10$(论文将 chunk size 的常用范围设为 {3,5,10,20,30} 进行消融)。
- 所有实验重复 3 次取均值以保证鲁棒性(论文说明)。
5.2 In-Context Learning(GSM8K、Many-Shot、Jailbreak)
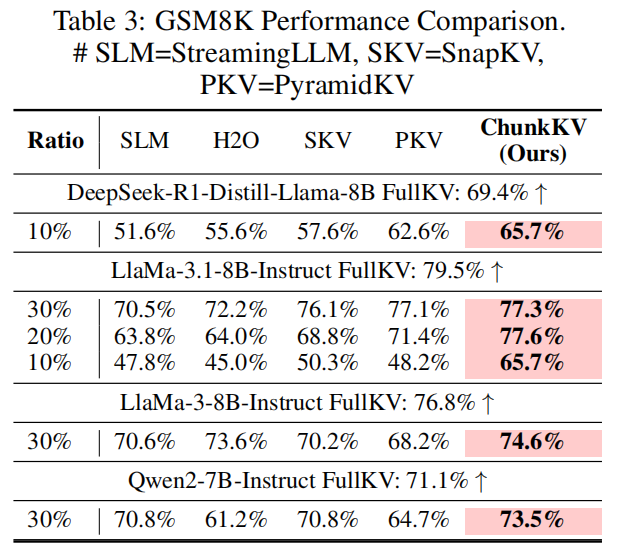
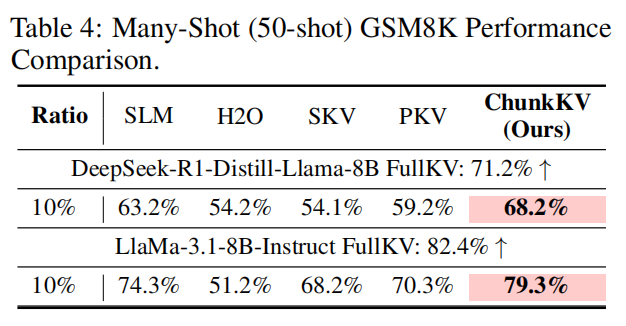
GSM8K(单步/chain of thought 场景)
-
设置:CoT prompt 按 Wei et al. 的标准;many-shot 设置 50-shot(prompt > 4k tokens)。
-
主要结果(摘要):在不同模型与压缩比下,ChunkKV 在保持相同压缩率时,相比 H2O、SnapKV、PyramidKV 等显著更接近 FullKV 基线,甚至在某些配置优于 FullKV(论文表格展示多组数据)。示例(部分摘录):LLaMA-3-8B-Instruct 在 10% 压缩下,ChunkKV 得到 65.7%(vs others 显著更低)。
-
分析要点:
- Many-shot 场景(50-shot)对语义完整性要求更高(示例完整保留对数学推理与 chain-of-thought 非常关键),ChunkKV 在 many-shot 下优势更明显(论文 Table 4)。
- math tasks 对索引复用(index reuse)的敏感度比 LongBench 更高(后文 index reuse 的消融中给出详细曲线)。
JailbreakV(安全评估)
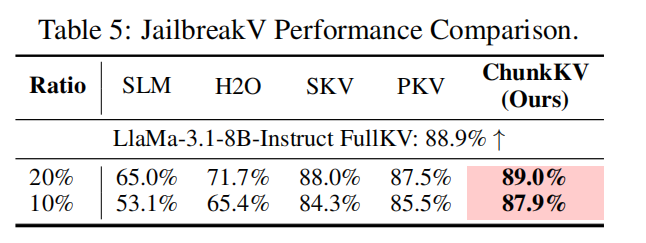
- 设置:Jailbreak prompts 与 Luo et al. 的设置一致。
- 主要发现:ChunkKV 在安全/绕过(jailbreak)评测中也表现优越,说明 chunk 保留能更好地维护 prompt 的对齐/安全相关上下文(Table 5)。在 10%/20% 比例下均优于多数 token-level 方法。
5.3 Long-Context Benchmark(LongBench & NIAH)
LongBench(多任务长上下文)
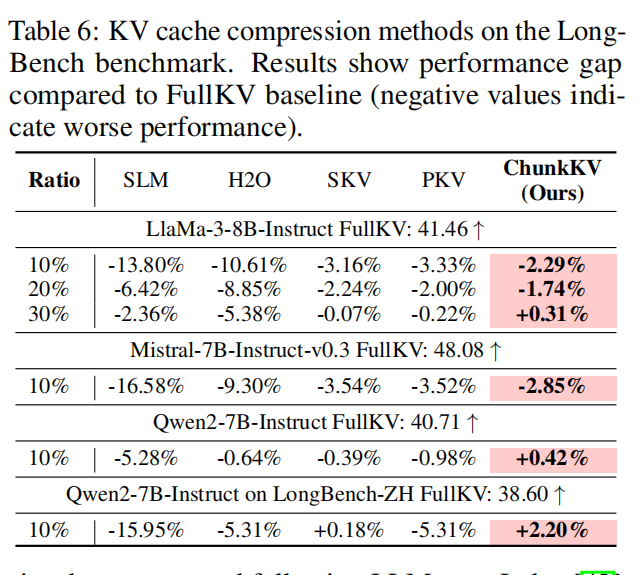
- 整体测评:论文以压缩后性能差距(相对 FullKV)来呈现结果(Table 6)。ChunkKV 在 LLaMA-3-8B、Mistral-7B、Qwen2-7B 的各项子任务上普遍优于或接近最优(在某些 ratio 下甚至小幅超过 FullKV),尤其在 10%~30% 区间效果稳定。
- 任务差异:ChunkKV 对需要“精确片段检索”的单文档/多文档 QA 表现尤为突出,因为 chunk 保持了原文片段完整性,减少碎片化带来的信息丢失。
Needle-In-A-HayStack(NIAH,检索型压力测试)
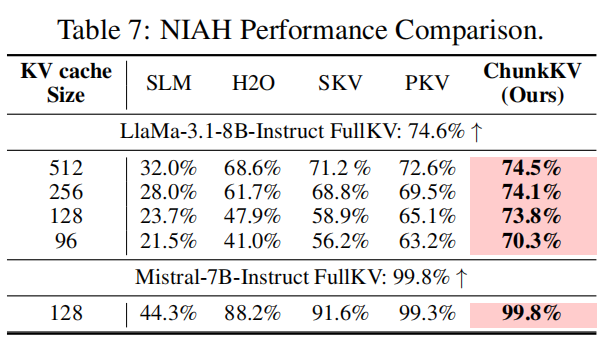
-
设置:用 GPT-4o-mini 做 judge;测试在 8k / 32k 上下文长度与不同 KV cache sizes(128/256/512 等)。
-
主要结果(摘要):
- NIAH 在 LLaMA-3-8B 中,当 KV size = 128 时,ChunkKV 能在更深的 depth% 与更长 token limit 上成功检索到“needle”(Figure 3 的热力图、Table 7 的具体数值)。例如在某些配置下 ChunkKV 的准确率为 73.8%(远超 SnapKV / H2O)。
- Mistral-7B 在 128 的 KV size 下几乎接近 FullKV(99.8%),说明在一些模型上 ChunkKV 几乎不损失性能。
5.4 Index Reuse(效率与性能权衡的详细数据)
性能(Latency / Throughput)
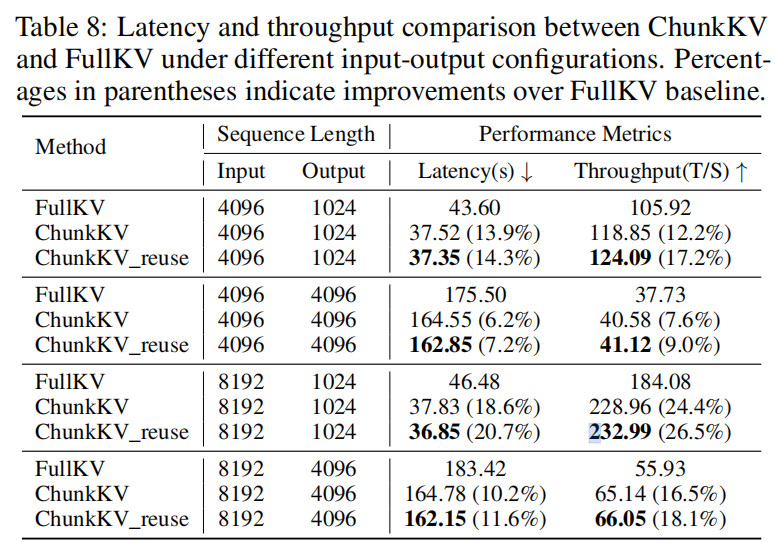
- 在 A40 GPU 上,以 FlashAttention2 进行推理,论文报告了多个 input/output 配置(4096→1024, 4096→4096, 8192→1024, 8192→4096)。ChunkKV 与 ChunkKV_reuse(复用索引)相较 FullKV 在 latency 与 throughput 上均有显著提升,最长输入场景下 ChunkKV_reuse 可达 20.7% latency 减少 与 26.5% throughput 提升(见 Table 8)。
任务性能(复用对准确率的影响)
- Index reuse(以
N_reuse=2为例)在 LongBench 上带来的性能下降通常小于 0.6%;在 GSM8K 上有时表现出中性或微升(Table 9)。论文进一步给出不同 reuse depth 的消融图:数学任务对 reuse depth 更敏感(当 reuse depth 增大到 3、5、8 时性能开始显著下降),因此实际部署时需要在 throughput 和任务敏感度之间做折中。
消融建议(工程)
- 对于“对准确率特别敏感”的任务(数学推理、某些 QA),建议
N_reuse ≤ 2;对延迟敏感但对少量性能下降可容忍的应用,可选择更大 reuse depth 以获取更高 throughput。论文提供了具体的 index-depth vs accuracy 曲线与表格供参考。
5.5 Chunk Size 消融
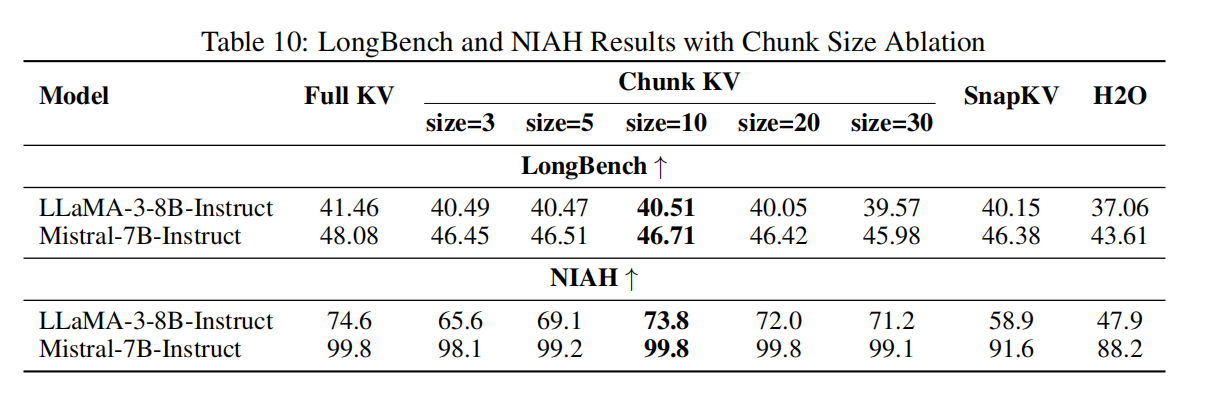
-
实验范围:chunk size ∈ {1, 3, 5, 10, 15, 20, 30}(论文在 LongBench / NIAH / GSM8K 上做了广泛消融)。主要结论:
- 当 chunk size 在 5–20 之间,性能相对稳定(波动 < 1%),$c=10$ 常常为最优或近最优(论文推荐默认 c=10)。
- 当 chunk size 太小(如 1 或 3)时,会把语义片段过度碎片化,导致性能下降(例如 LongBench、NIAH 的结果)。当 chunk size 太大(如 30)时,会丢失细粒度信息,某些任务(需要精确 token 的)出现退化。Table 10 / Table 19/20 显示了完整值。
-
推荐:默认 $c=10$;若任务偏向短 prompt(如 GSM8K 的 CoT ~1k tokens),可在 3–10 范围微调;若对长文档检索更敏感,10–20 也常表现良好。
5.6 与 KV Quantization 的对比(KIVI 等)
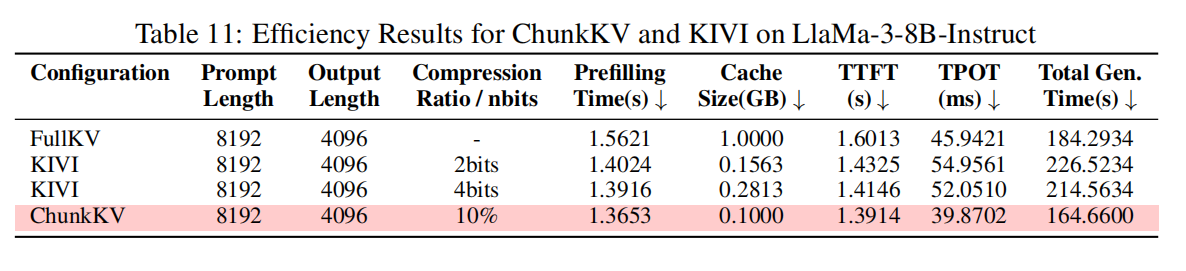
-
核心差异:
- Quantization(如 KIVI)减少的是表示精度(bitwidth),需要在 prefilling 阶段存在 full KV 来生成量化表示;
- ChunkKV 在 prefilling 之前就做 token-eviction(通过删除 token),因此可以在推理全程都只维护压缩后的 KV,节省 prefilling 内存 / 复制开销。
-
性能/效率实测(示例):在 LLaMA-3-8B-Instruct、prompt 8192 / output 4096 的配置下,ChunkKV(10%)在 Total Gen Time 上 164.66s,而 KIVI-2bits 为 226.52s(ChunkKV 有 ~27.3% 的整体推理速度优势);TTFT、TPOT 等延迟关键指标 ChunkKV 也更优(详见 Table 11)。
-
结论:两者属于互补(一个降低 size,一个降低精度);在延迟敏感场景下,ChunkKV 在总体效率上具有显著优势。
5.7 Hybrid Compression(Chunk-level vs Token-level 在不同层深的混合策略)

-
实验:采用 hybrid(下半层用 ChunkKV,上半层用 SnapKV)并与纯 ChunkKV / 纯 SnapKV 比较(同一压缩率)。结果显示:
- 对于局部信息检索(Single-Doc / Multi-Doc QA),纯 ChunkKV 表现最好;
- 对于全局理解(Summarization / Few-shot),混合模型有时候更优(可能因为深层语义表达更抽象,token-level 的多样保留能帮助 global signals)。
-
实践启示:可设计任务感知的分层压缩策略(例如对文档理解任务在 deeper layers 增加 token-level 保留),但论文结论是:作为通用方法,纯 ChunkKV 更稳健。
7. Limitation
- ChunkKV 假定“删除部分 token 不会丢失极其关键的细节”,在法律/医疗等需要逐字级别保真的场景可能不合适(论文明确指出)。
- 当前实现使用固定 size chunk(效率高但语义边界未显式对齐);未来可以尝试基于句法/语义边界的 adaptive chunk(但需权衡额外开销)。
8. Conclusion
- ChunkKV 通过将 KV 压缩单元从“孤立 token”提升为“语义 chunk”,解决了 token-level 压缩破坏语义连续性的问题,从而在 long-context 与 in-context 场景获得更好的任务表现与工程效率。实验在 LongBench、NIAH、GSM8K、JailbreakV 等 benchmark 上均显示优势,并通过 layer-wise index reuse 在延迟/吞吐上取得可观提升(最高 ~20.7% latency 降低、~26.5% throughput 提升)。