
Conference: NeurIPS'25
My Thoughts
当时在复现 SpinQuant 的时候,确实感受到了 training 的计算资源需求非常大。记得训练一个 epoch 都一些时间,而 SpinQuant 官方给的 example script 甚至建议训练 100 个 epoch。当时就意识到:针对旋转矩阵的优化(Rotation Optimization)需要更高效的方式。
结果果然别人的手速很快,NeurIPS’25 上就出现了这个 DartQuant 工作,它不仅加速了旋转矩阵的优化过程,还能缓解 calibration 阶段的 task-specific overfitting 问题和通过QR分解解决必须正交的问题,非常巧妙。
1. Motivation
近年来,大型语言模型(LLMs)在多种 NLP 任务上表现卓越,如文本生成、翻译、问答系统等。然而,其推理阶段的计算与内存开销极高,限制了在边缘设备或资源受限场景下的部署。
在各种模型压缩方法中(剪枝、蒸馏、参数共享、量化等),后训练量化(Post-Training Quantization, PTQ) 因为不需要重新训练、可直接作用于现成模型,而在实际部署中最具实用价值。
不过,激活分布中存在的极端值(outliers)严重影响了低比特量化效果。为了解决这一问题,研究者提出了 旋转变换(rotation transformation) 来改变激活分布,使其更适合量化。旋转矩阵具有以下优势:
- 保持范数不变;
- 可逆;
- 能在推理阶段与权重线性层融合,不增加推理时延。
例如,QuaRot 和 SpinQuant 分别使用随机或可训练旋转矩阵来削弱 outlier 的影响。然而,SpinQuant 的 end-to-end 旋转训练开销巨大(显存、时间都极高),同时容易在小规模 calibration set 上 过拟合。 这正是 DartQuant 要解决的痛点:如何在不做昂贵端到端微调的情况下,快速获得合适的旋转矩阵。
2. Challenge
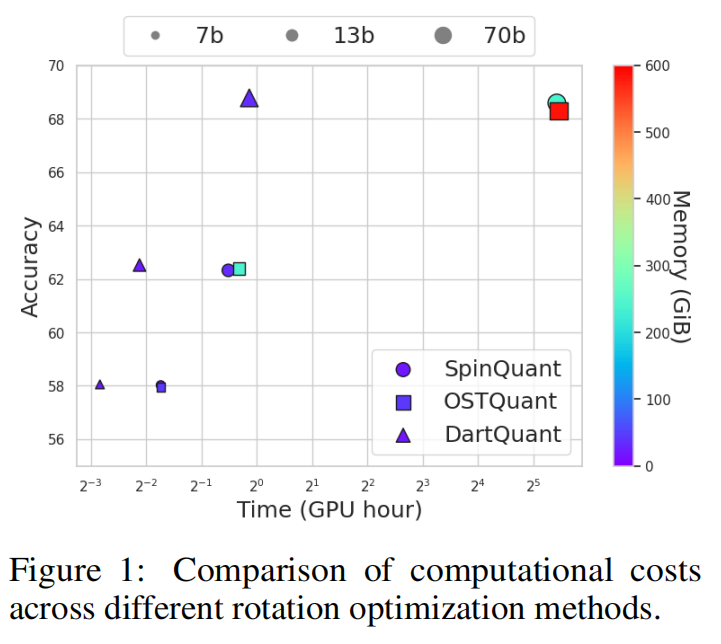
现有的基于旋转的量化方法(如 SpinQuant、OSTQuant)主要问题如下:
-
计算与显存开销过大: 对 70B 模型进行旋转矩阵优化需要上百 GiB 显存与数十 GPU 小时,完全不符合 PTQ 快速部署的目标。
-
优化复杂(正交约束): 旋转矩阵必须保持正交性 $RR^\top = I$,因此需要在黎曼流形(Stiefel / Grassmann manifold)上优化。常用方法如 Cayley 优化器 或 Riemannian SGD,均需进行复杂的投影计算,带来额外的时间消耗。
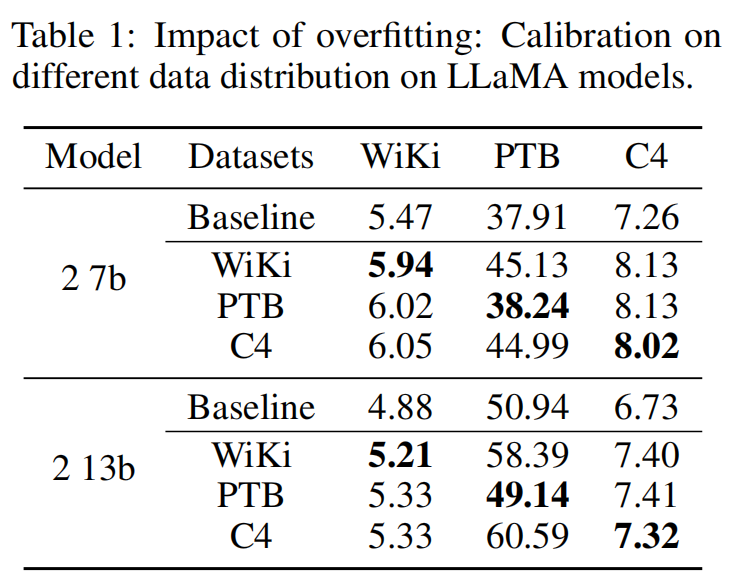
- 过拟合风险高: calibration 数据有限时,end-to-end fine-tuning 容易对特定分布过拟合,使量化后模型在 0-shot 等下游任务上泛化能力下降。
3. Contribution
DartQuant 针对上述挑战,提出了一个高效的旋转分布校准框架(Rotational Distribution Calibration),主要贡献如下:
-
提出分布校准式旋转优化: 不依赖任务损失(如 cross-entropy),而是直接优化旋转后激活的统计分布,使其更适合量化,从而减少过拟合。
-
设计 Whip Loss: 一种基于分布均匀化的损失函数,使旋转后的激活趋向均匀分布,显著降低量化误差并加速收敛。
-
提出 QR-Orth 优化器: 通过 QR 分解保持旋转矩阵的正交性,无需使用复杂的流形优化器,大幅降低计算复杂度。
-
显著提升性能与效率: 在 Llama-2/3 等模型上,DartQuant 实现了 47× 的 GPU 时间加速、10× 的显存节省;并首次在单张 RTX 3090 上完成了 70B 模型的旋转校准(仅约 3 小时)。
4. Related Work
4.1 LLM 量化挑战
激活中的异常值(outliers)会占据量化区间,导致有效精度降低。早期方法采用 mixed precision(不同层或通道使用不同精度),但增加了实现复杂度。
4.2 基于缩放的 outlier 处理
例如:
- SmoothQuant:将 outlier 从激活转移到权重;
- Outlier Suppression+:对激活通道进行缩放与偏移;
- OmniQuant:通过可学习裁剪(learnable clipping)进行误差补偿。
这些方法能缓解激活异常值,但可能转移问题到权重侧,并在极端 outlier 情况下失效。
4.3 基于旋转的 outlier 处理
旋转方法的典型代表包括:
- QuIP / QuIP#:使用随机正交变换或 Hadamard 变换降低相关性;
- QuaRot:结合旋转与缩放,适用于 LLaMA 大模型;
- SpinQuant / OSTQuant:将旋转矩阵视为可训练参数,用端到端方式优化。
然而,端到端优化需大量资源,并存在 overfitting 与复杂正交约束问题。 DartQuant 则提出无任务损失的“分布校准”方案,显著简化了优化过程。
5. Method
🔹 Preliminaries and Difficulty
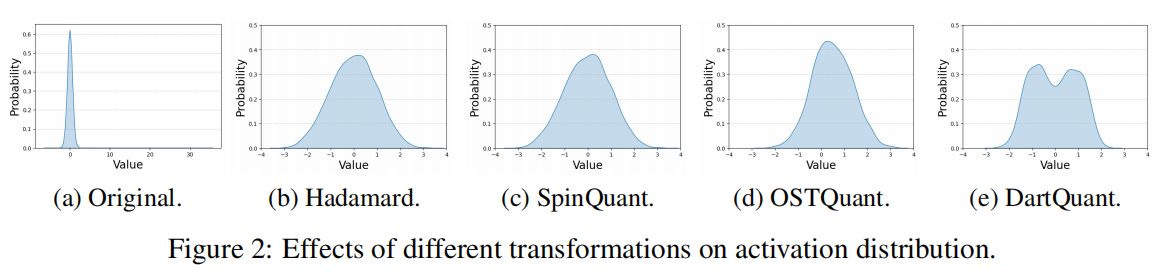
在 Transformer 中,线性层输出为:
$$ Y = XW^\top $$
若插入旋转矩阵 $R$(满足 $RR^\top = I$),则:
$$ Y = (XR)(R^\top W^\top) $$
由于旋转保持范数不变,上式与原输出等价,因此可以安全插入旋转矩阵来调整激活分布,而不会改变模型推理输出。
现有工作(如 SpinQuant)通过 end-to-end 微调学习 $R$,但这种方式计算和显存消耗巨大。 此外,旋转矩阵的优化需保持正交约束,使得优化过程位于 Stiefel 流形 上:
$$ \mathcal{S}(n,p) = { R \in \mathbb{R}^{n \times p} | R^\top R = I_p } $$
这需要特定的优化器(如 Riemannian SGD),实现复杂且效率低。
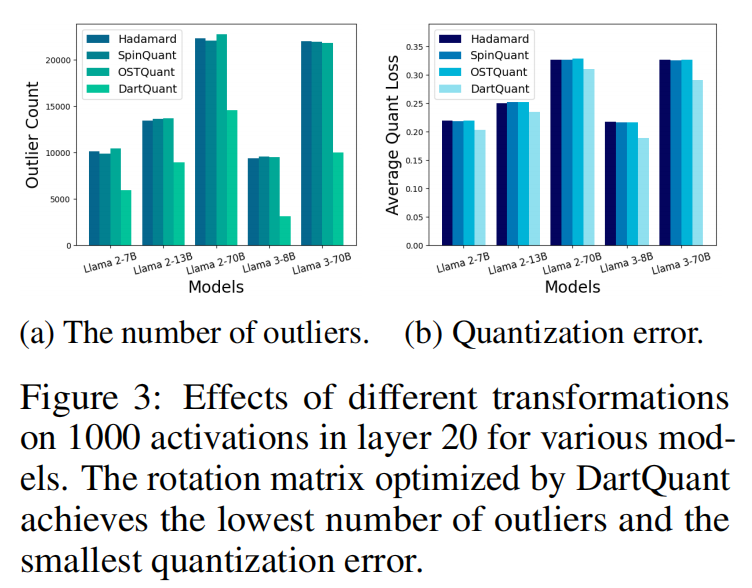
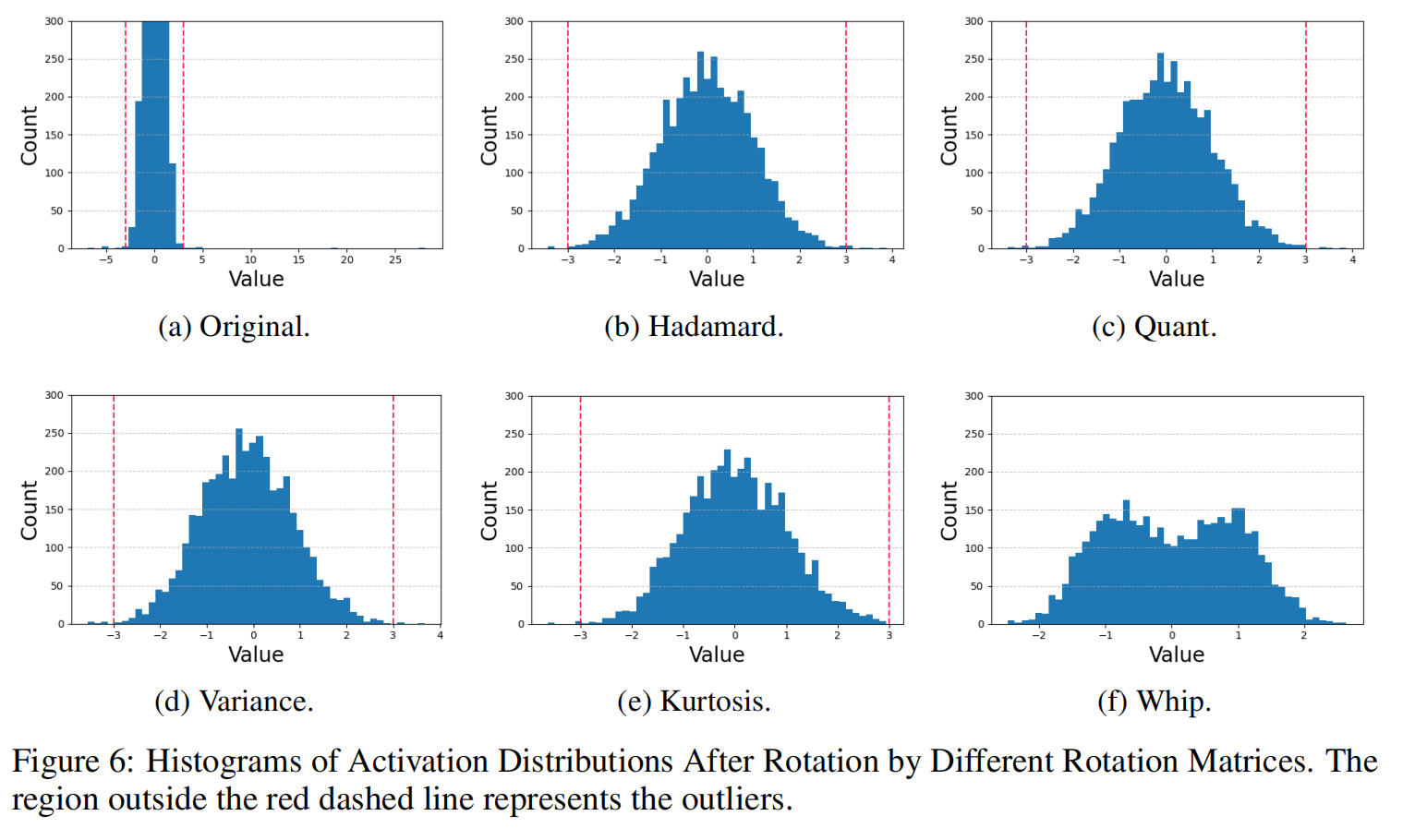
上图展示了不同旋转方法在 20 层激活的 outlier 数量与量化误差对比。 可以看出,即使经过 end-to-end fine-tuning,outlier 数量下降有限,说明该过程并未有效调整激活分布。
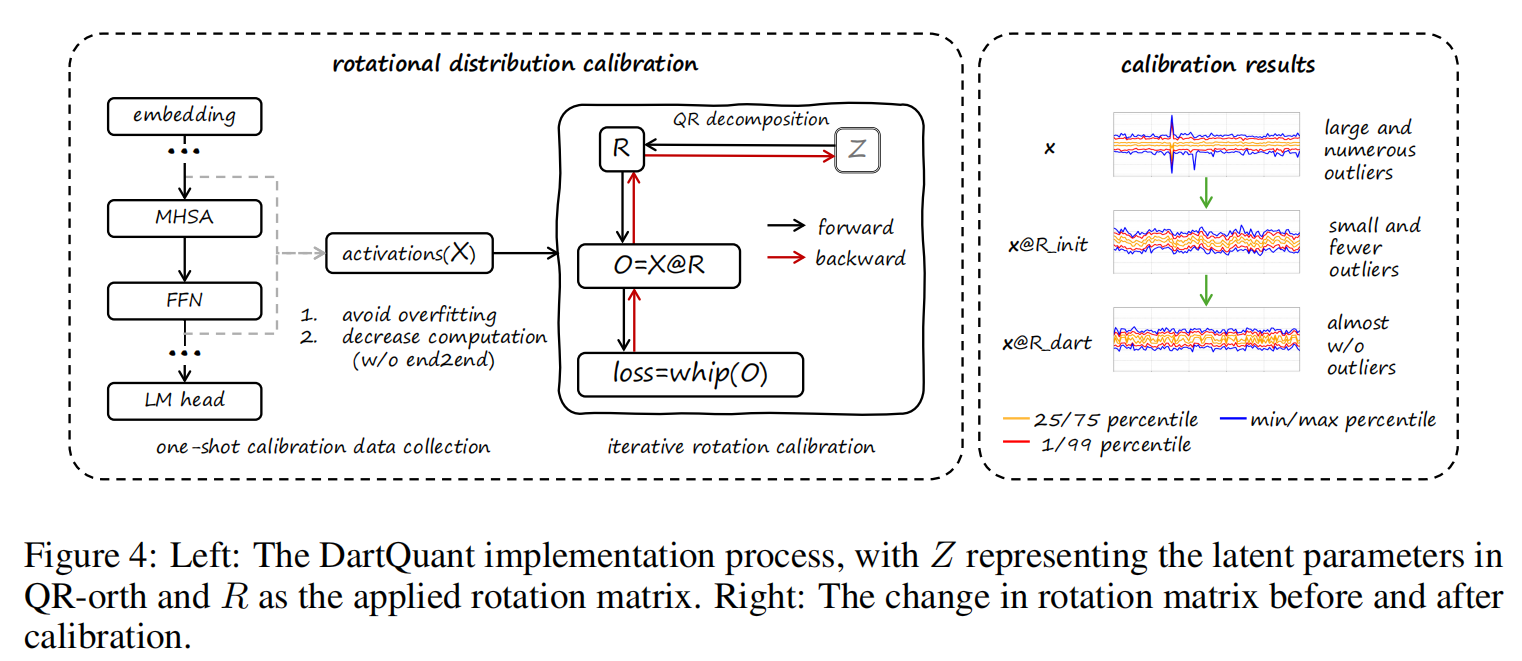
5.1 Rotational Distribution Calibration
DartQuant 重新定义旋转优化问题,从“任务损失最小化”转向“分布校准最优”。 目标是寻找一个旋转矩阵 $R$,使得旋转后的激活分布更接近量化友好的均匀分布:
$$ \min_R \sum_{i=1}^{C_{in}} \mathbb{I}(|(R x)_i| > \tau) $$
其中,$\mathbb{I}(\cdot)$ 为指示函数,$\tau$ 是 outlier 阈值。 但该目标不可导,因此作者提出可微近似方法,并分析了三种传统度量(方差、峰度、量化误差)的不足:
- 方差(variance):由于旋转不改变范数,优化无效;
- 峰度(kurtosis):仅在尾部分布极端时有效;
- 量化误差(quantization loss):难以直接反向传播。
因此,论文提出新的度量 —— Whip Loss。
5.2 Activation Uniformity via Whip Loss
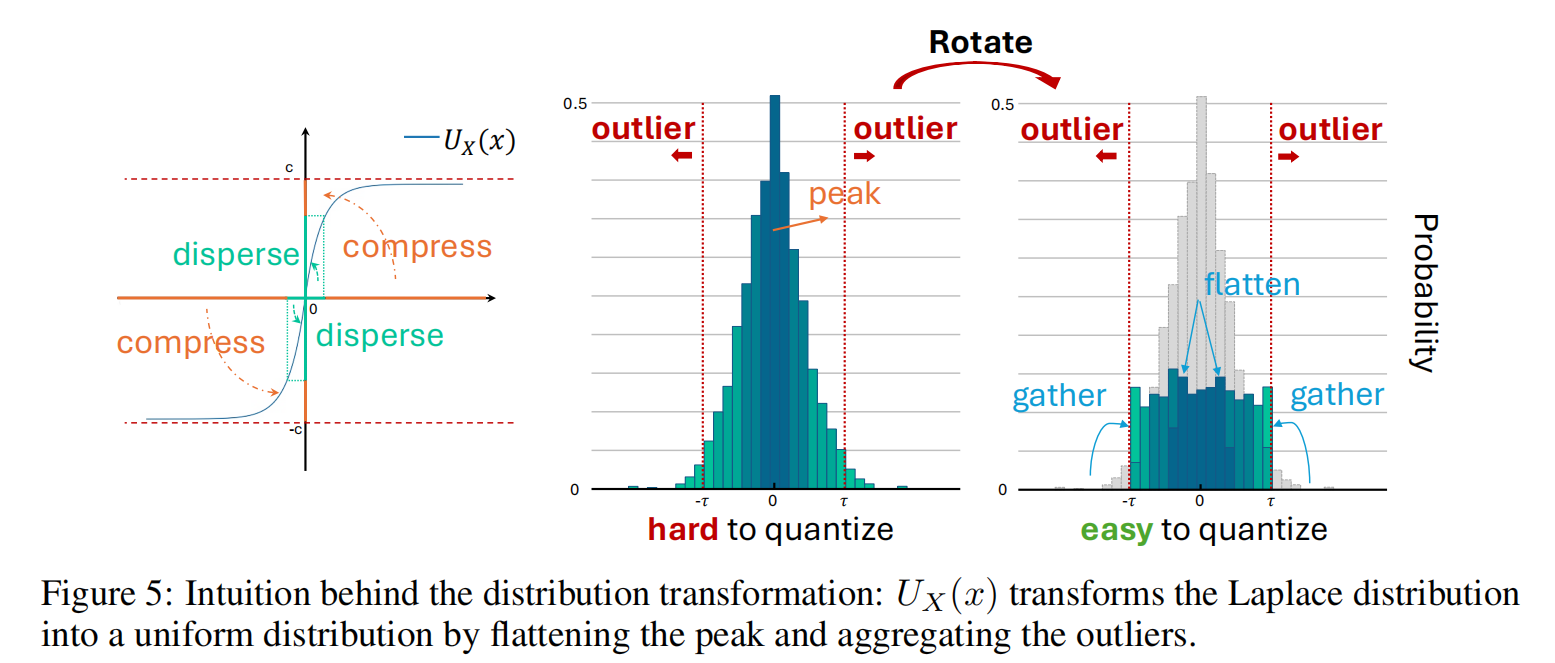
论文观察到,激活值近似服从对称的 Laplace 分布:
$$ f(x) = \frac{1}{2b} e^{-|x|/b} $$
目标是将其变换为更平坦的 均匀分布,可通过累积分布函数(CDF)映射实现:
$$ U_X(x) = 2\tau \left( \int_{-\infty}^{x} \frac{1}{2b} e^{-|t|/b}dt - \frac{1}{2} \right) $$
计算得:
$$
U_X(x) =
\begin{cases}
\tau (e^{x/b} - 1), & x \le 0
\tau (1 - e^{-x/b}), & x > 0
\end{cases}
$$
这一变换可将“中心峰值”平展、同时压缩尾部 outlier。
基于该思路,提出可微损失函数 Whip Loss:
$$ \mathcal{L}_{\text{Whip}}(x) = \sum_i e^{-|x_i|} $$
- 对小幅度激活(接近 0)梯度较大,使其远离中心;
- 由于旋转保持范数,放大中间值会间接压缩 outlier;
- 整体激活分布趋向均匀,减少量化误差。
Whip Loss 可直接使用常规优化器(如 SGD)训练,收敛快且稳定。 实验显示,相较 variance/kurtosis/quantization loss,Whip Loss 在数个迭代内即可显著降低激活量化误差(见 Figure 6 与 Figure 7)。
5.3 Enforcing Orthogonality with QR-Orth

为避免昂贵的流形优化,DartQuant 提出 QR-Orth:
通过引入潜在矩阵 $Z \in \mathbb{R}^{n \times n}$,对其进行 QR 分解:
$$ Z = QR $$
取 $Q$ 作为正交矩阵,即旋转矩阵 $R$。 这样就可以在普通欧几里得空间中更新 $Z$,每次通过 QR 分解获得新的正交矩阵,完全避免了 Cayley 或 Riemannian 投影(很巧妙的做法)。
复杂度分析:
- Householder QR 分解复杂度约为 $\frac{4}{3}n^3$;
- Cayley 变换需多次矩阵乘法,复杂度约 $6n^3$;
- 实测 QR-Orth 比 Cayley 优化快 1.4×,并支持单 GPU 运行。
实现要点:
- 使用一次 token sampling 收集激活样本;
- $Z_0$ 采用随机 Hadamard 初始化;
- 优化器可用 SGD 或 Adam;
- Whip Loss 收敛速度快,仅需少量迭代即可完成校准。
6. Evaluation
6.1 主实验结果
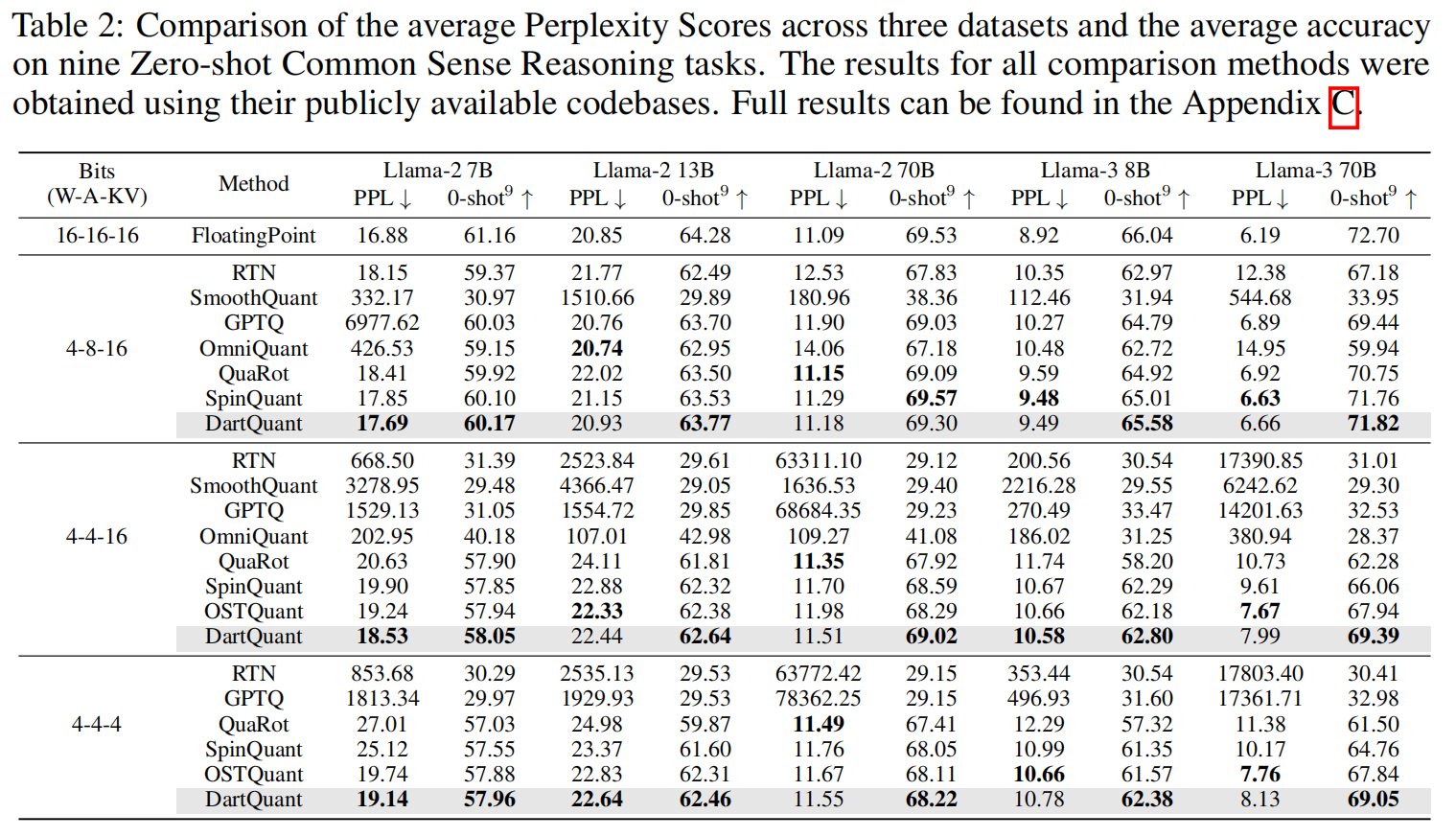
在多种模型与位宽设置(Llama-2/3、70B/13B/7B)下:
- 当权重为 8-bit 时,各方法差距不大;
- 当权重为 4-bit、激活为 8-bit 时,SmoothQuant / OmniQuant 性能大幅下降;
- 而 DartQuant 能保持与原模型接近的性能;
- 在 70B 模型 w4a4kv16 设置下,性能损失仅 0.5%。
此外,SpinQuant / OSTQuant 虽能降低 PPL,但 zero-shot 任务上性能不稳,说明存在过拟合。 DartQuant 则通过分布校准机制实现更好的泛化性能。
6.2 Ablation Studies
(1) 不同优化目标
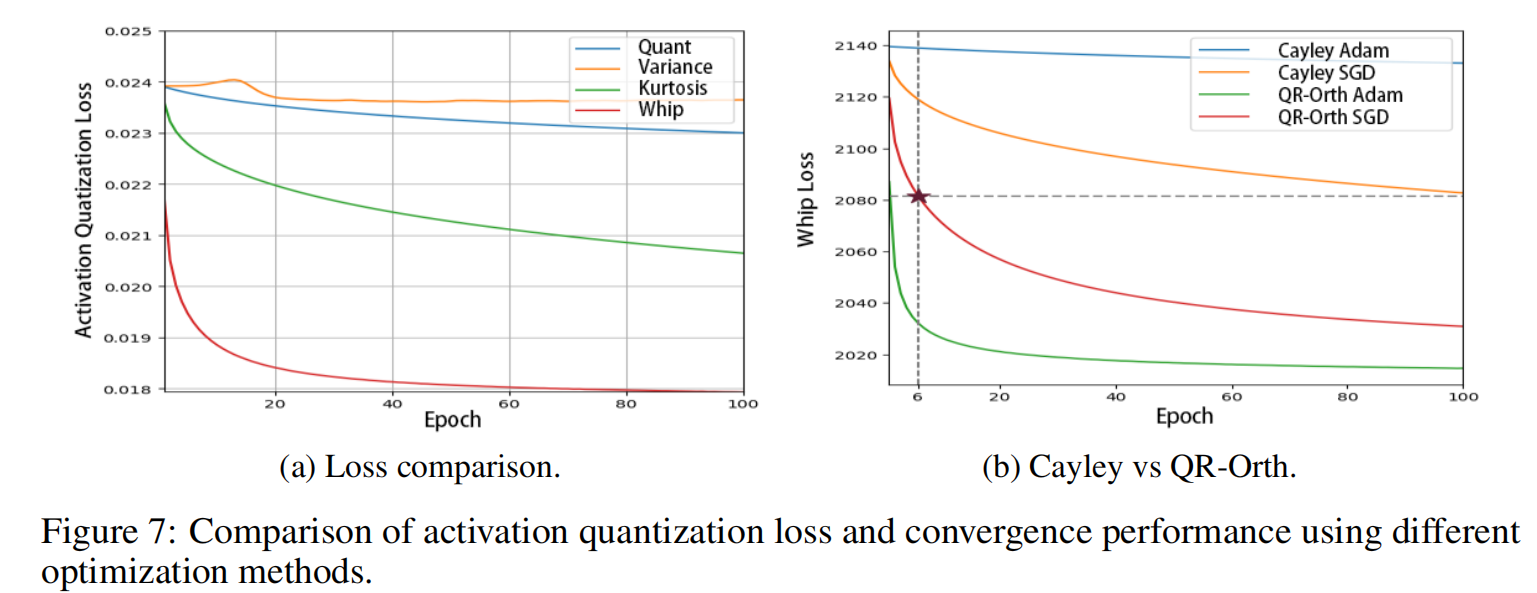 比较四种目标函数:Quantization Loss、Variance、Kurtosis、Whip。
实验表明:
比较四种目标函数:Quantization Loss、Variance、Kurtosis、Whip。
实验表明:
- Whip Loss 收敛更快;
- 最终量化误差最低;
- 迭代次数更少(Figure 7a)。
(2) 不同优化器
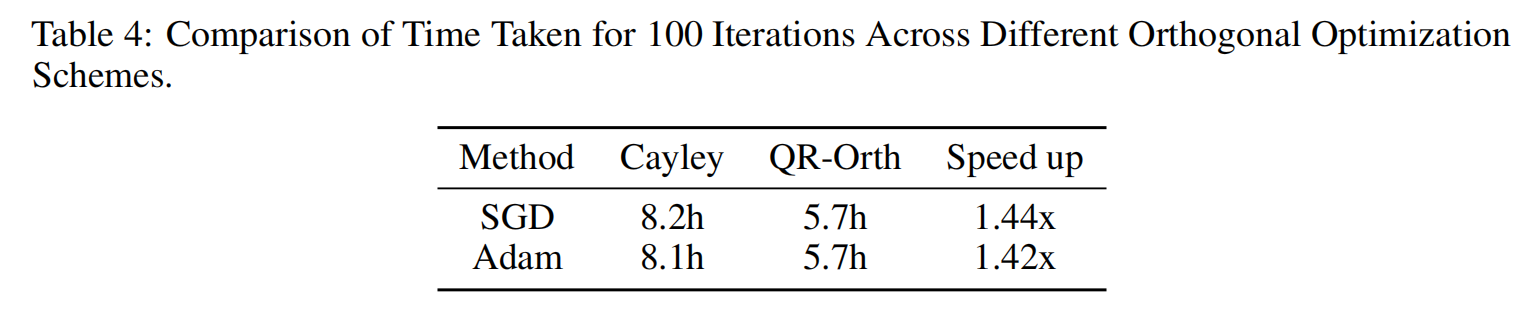
比较 Cayley 优化器 与 QR-Orth:
- QR-Orth 收敛更快,最终误差更低;
- QR-Orth 的时间消耗减少约 1.4×;
- 实测 QR-SGD 6 步即可达到 Cayley-SGD 100 步的效果;
- 总加速约 41×。
6.3 不同数据集的鲁棒性
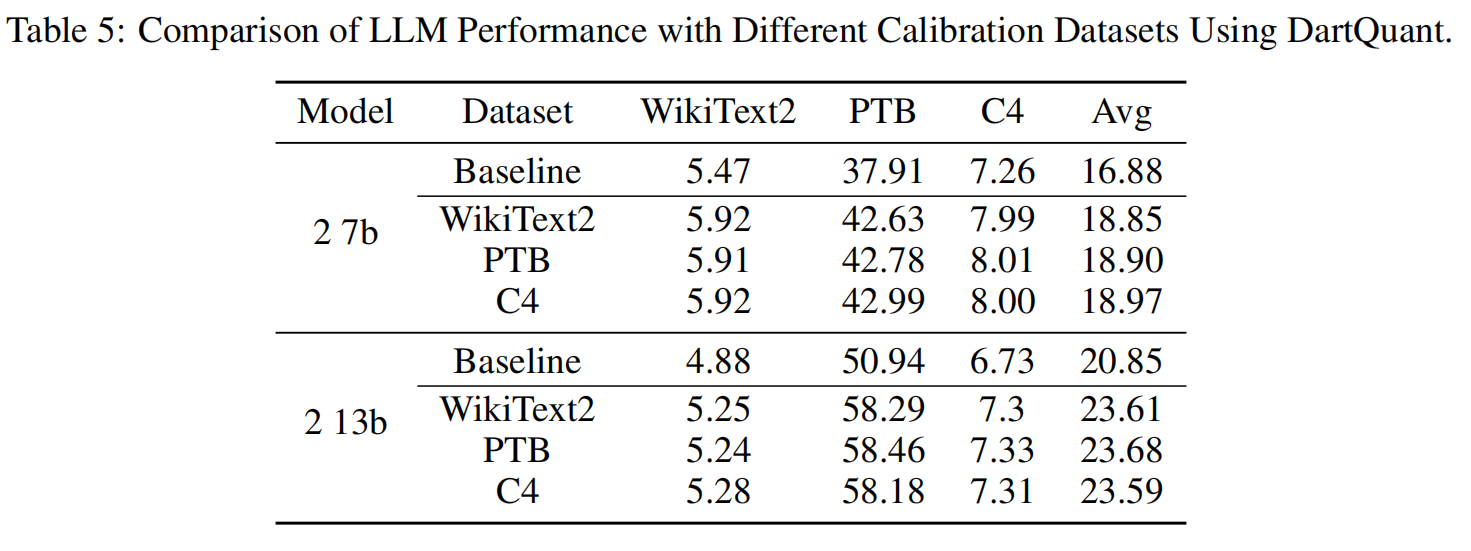
使用三种校准数据集(WikiText2, PTB, C4)分别优化旋转矩阵,结果几乎一致。 说明 DartQuant 对数据集不敏感,不会因校准样本不同而影响最终量化精度。 这进一步验证了“分布校准”比“任务损失微调”更稳健的优势。
6.4 效率与资源开销
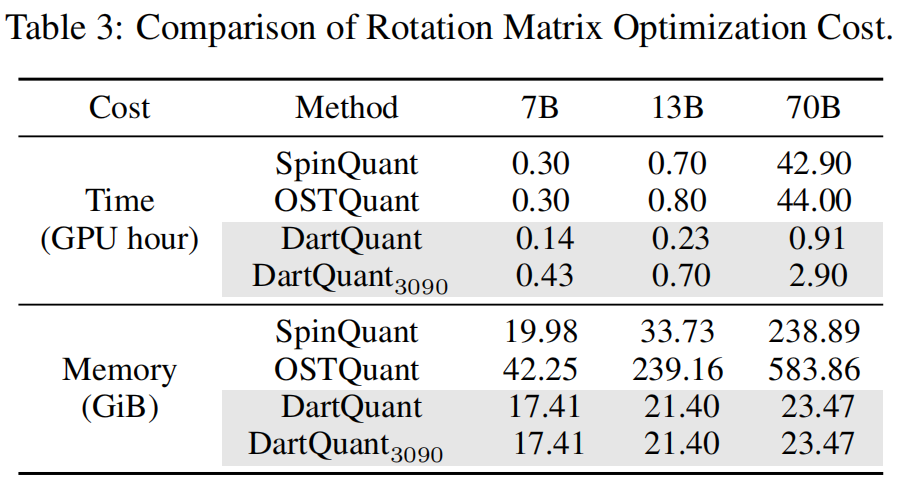
在 A800 GPU 上的比较:
| 方法 | GPU小时 | 显存 (GiB) |
|---|---|---|
| SpinQuant | 42.9 | 238.89 |
| OSTQuant | 44.0 | 583.86 |
| DartQuant | 0.91 | 23.47 |
DartQuant 相较于现有方法:
- 计算时间减少 47×;
- 显存开销减少 10×;
- 并能在单张 RTX 3090 上完成 70B 模型旋转优化,仅需约 3 小时。
6.5 在 MoE 模型上的表现
DartQuant 还被验证可应用于 Mixture-of-Experts (MoE) 架构(如 Mixtral、DeepSeek-MoE)。 实验表明,即使在专家切换的非均匀分布下,Whip Loss 仍能稳定收敛,验证了其通用性。
7. Conclusion
本文提出的 DartQuant 框架通过:
- Whip Loss 将激活分布校准为更均匀形态;
- QR-Orth 避免复杂的流形优化; 实现了在 大模型量化(尤其是 4-bit 级别) 下的高效与高精度统一。
它显著降低了旋转矩阵优化的时间与显存成本,使得在单 GPU 上优化 70B 模型成为可能。 DartQuant 为未来在资源受限环境中部署 LLM 提供了重要启发。