
Conference: NeurIPS 2025
Github: https://github.com/ZichenWen1/EPIC
My Thoughts
EPIC 这篇论文的核心思想是在不改动模型结构的前提下,通过渐进式一致性蒸馏(Progressive Consistency Distillation),让多模态大语言模型在token 层面(Token Consistency Distillation, TCD) 和 层级层面(Layer Consistency Distillation, LCD) 逐步适应视觉 token 压缩带来的特征分布变化,从而实现从低压缩到高压缩的平滑过渡,在显著降低计算量与显存占用的同时仍保持甚至提升模型性能。这种从训练策略层面解决效率问题的思路,兼具理论优雅性与实用性。
日后如果有需要用到 Knowledge Dsitillation 的 idea 或者 训练策略,可以借鉴其思想。
1. Motivation
多模态大语言模型(MLLM)需要同时处理文本与视觉模态的信息。与仅需处理少量高信息密度文本 token 的 LLM 不同,MLLM 在输入中包含大量视觉 token,这些 token 在高分辨率图像或多帧视频任务中尤为庞大。这种“视觉 token 爆炸”(visual token explosion)带来了显著的计算负担与存储压力,尤其在推理时对 KV cache 和显存的占用极大。
因此,如何在不显著降低性能的前提下减少视觉 token 的数量,成为提升 MLLM 效率的核心问题。
2. Challenge
视觉 token 数量通常比文本 token 多出几个数量级,但其包含的空间信息高度冗余。近年来,研究者提出了两大类视觉 token 压缩方法:
-
Training-free 方法: 不需要额外训练,通过简单的启发式规则压缩视觉 token。
- 基于重要性(importance-based):如 FastV、SparseVLM,依据注意力得分筛选重要 token。
- 基于冗余(redundancy-based):如 DART、G-Prune,通过 token 相似度评估合并或舍弃冗余特征。
-
Training-aware 方法: 在训练阶段显式引入压缩模块,让模型学习在压缩下保持性能。 典型工作包括:
- LLaVA-PruMerge(基于注意力的合并)
- VoCo-LLaMA(压缩 VoCo token)
- MQT-LLaVA(动态 Q-Former 编码)
- TokenPacker(粗到细迭代压缩)
- LLaVA-Mini(利用辅助模块实现近无损压缩)
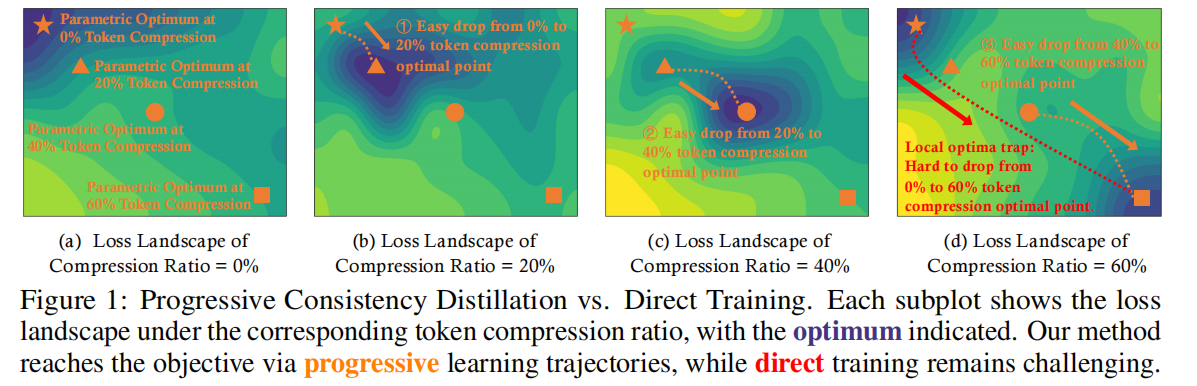
然而问题在于: 在训练过程中进行 token 压缩时,压缩后的特征分布会与原始分布产生偏移(即特征空间扰动,feature-space perturbation)。这种扰动会使模型参数空间中的最优点发生漂移。压缩越激进,漂移越大,从而导致模型更容易陷入局部最优,训练收敛困难。
因此,核心挑战在于: 如何在高压缩率下仍能保持稳定的训练与性能一致性。
3. Contribution
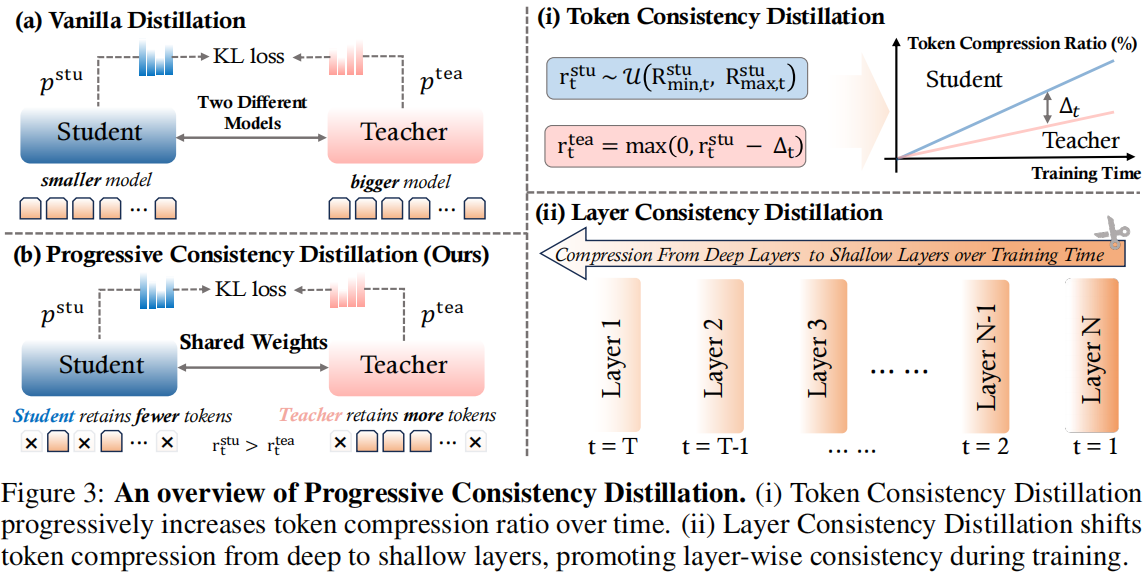
本文提出了一种渐进一致性蒸馏学习框架(Progressive Consistency Distillation Learning Framework) —— EPIC,用于解决 token 压缩带来的训练扰动问题。
核心思想是: 通过渐进学习(progressive learning)和一致性蒸馏(consistency distillation),让模型从“低压缩、易学习”的状态逐步适应“高压缩、难优化”的场景,从而实现平滑过渡。
核心贡献包括:
-
Token Consistency Distillation (TCD): 从 token 维度进行渐进蒸馏。 在训练初期,teacher 与 student 使用较低压缩率;随着训练推进,压缩率逐步提高。teacher 始终比 student 稍微“容易”一些,从而提供稳定的蒸馏指导。
-
Layer Consistency Distillation (LCD): 从层级维度进行渐进蒸馏。 视觉 token 在模型深层的贡献较小,因此训练初期在深层执行压缩影响较小,随后逐渐将压缩迁移到浅层,实现“由易到难”的层级学习。
-
统一框架与兼容性: EPIC 不需要修改模型结构,也不依赖特定的 token 压缩算法,可与 DART、FastV、Random 等方法兼容。
4. Method
4.1 Progressive Consistency Distillation Learning
在高压缩训练中,视觉特征分布的扰动会导致模型收敛困难。EPIC 提出的**渐进一致性蒸馏学习(PCDL)**框架,旨在通过逐步增加压缩难度,让模型平滑过渡至最终目标。
该框架包含两个主要部分:
- Token Consistency Distillation (TCD):从 token 维度逐步提高压缩率;
- Layer Consistency Distillation (LCD):从层级维度逐步从深层过渡到浅层进行压缩。
两者均通过共享权重的 teacher-student 架构实现一致性蒸馏。teacher 使用略低压缩率(如低 5%)指导 student,随着训练进行逐渐拉大 gap(如 10%),实现阶段式指导。
4.2 Theoretical Intuition: A 1D Prototype for Progressive Consistency Distillation Learning
为理解 PCDL 的有效性,论文构建了一个一维标量模型。假设模型输出为 $\theta \in \mathbb{R}$,每个压缩率 $r \in [0, r_{\max}]$ 对应一个目标中心 $c_r$。设函数 $c(r)$ 满足:
- 单调递增:$c’(r) \ge 0$
- Lipschitz 连续:存在常数 $\gamma > 0$,使得 $|c’(r)| \le \gamma$
- 凸性:$c’’(r) \ge 0$
定义两种训练目标:
- 直接训练: $$ L_{\text{dir}}(r,\theta) = \frac{1}{2}(\theta - c_r)^2 $$
- 渐进蒸馏: $$ L_{\text{prog}}(r,\theta) = \frac{1}{2}(\theta - c_r)^2 + \frac{\lambda}{2}(\theta - c_{r-\Delta})^2 $$
第二项表示来自压缩率更低的 teacher 的蒸馏约束。该设计能平滑学习轨迹,避免参数在压缩率变化时剧烈振荡。
理论上可证明,在满足上述条件时,渐进路径的总变化量(Total Variation)严格小于直接训练路径,即学习过程更平滑、更稳定。
4.3 Token Consistency Distillation (TCD)
TCD 从 token 维度 逐步增加压缩比,实现模型对视觉 token 压缩的渐进适应。
设模型为 $f_\theta$(teacher 与 student 共享参数),图像输入 $I$,文本提示 $P$。
定义压缩算子 $C(I, r, \ell)$ 表示在第 $\ell$ 层以比例 $r$ 压缩视觉 token(保留 $1-r$ 的比例)。
在训练第 $t$ 步时:
-
从一个随时间变化的区间中随机采样 student 压缩率: $$ r_t^{\text{stu}} \sim \mathcal{U}(R_{\min,t}^{\text{stu}}, R_{\max,t}^{\text{stu}}) $$ 随着训练进行,$R_{\max,t}$ 逐渐增大(压缩率提高)。
-
teacher 压缩率略低: $$ r_t^{\text{tea}} = \max(0, r_t^{\text{stu}} - \Delta_t) $$ gap $\Delta_t$ 也随时间逐步增大(防止初期蒸馏难度过大)。
-
teacher 与 student 的前向输出分别为: $$ h_{\text{tea}} = f_\theta(C(I, r_t^{\text{tea}}, \ell); P),\quad h_{\text{stu}} = f_\theta(C(I, r_t^{\text{stu}}, \ell); P) $$
-
定义蒸馏损失(KL 散度): $$ L_{\text{TCD}} = \mathrm{KL}(p_{\text{tea}} \Vert p_{\text{stu}}),\quad p = \mathrm{Softmax}(h / \tau) $$ 其中 $\tau$ 为温度参数。
-
总损失为: $$ L_{\text{total}} = (1 - \lambda)L_{\text{SFT}} + \lambda L_{\text{TCD}} $$
直观理解: teacher 使用轻度压缩得到平滑特征分布,student 使用更高压缩率学习在更困难分布下保持一致性。随着训练推进,teacher 与 student 的压缩率差距增大,学习难度逐步提升,形成稳定的“课程学习(curriculum learning)”路径。
4.4 Layer Consistency Distillation (LCD)
先前研究发现,视觉 token 在模型深层的注意力权重较低,而浅层特征对视觉语义贡献更大。 基于此,LCD 采用一种从深层向浅层逐步压缩的策略。
定义模型总层数为 $L$,训练步数为 $T$,当前步 $t$ 的归一化进度为 $\beta_t = t / T$。 选择压缩层: $$ \ell_t = \text{Round}(L - \beta_t(L - \ell_{\min})) $$
即在训练初期仅压缩最深层(影响最小),随后逐渐向浅层推进。
其损失函数与 TCD 类似,也采用 KL 散度形式: $$ L_{\text{LCD}} = \mathrm{KL}(p_{\text{tea}} \Vert p_{\text{stu}}) $$
最终训练目标: $$ L_{\text{total}} = (1 - \lambda)L_{\text{SFT}} + \lambda L_{\text{LCD}} $$
总结: TCD 聚焦 token 数量层面,LCD 聚焦层级深度,两者结合构成完整的渐进一致性蒸馏框架。
5. Evaluation
论文在多个视觉理解基准上进行了实验,包括 VQAv2、GQA、VizWiz、MME、MMBench、VQAT、POPE 等。
5.1 实验结果
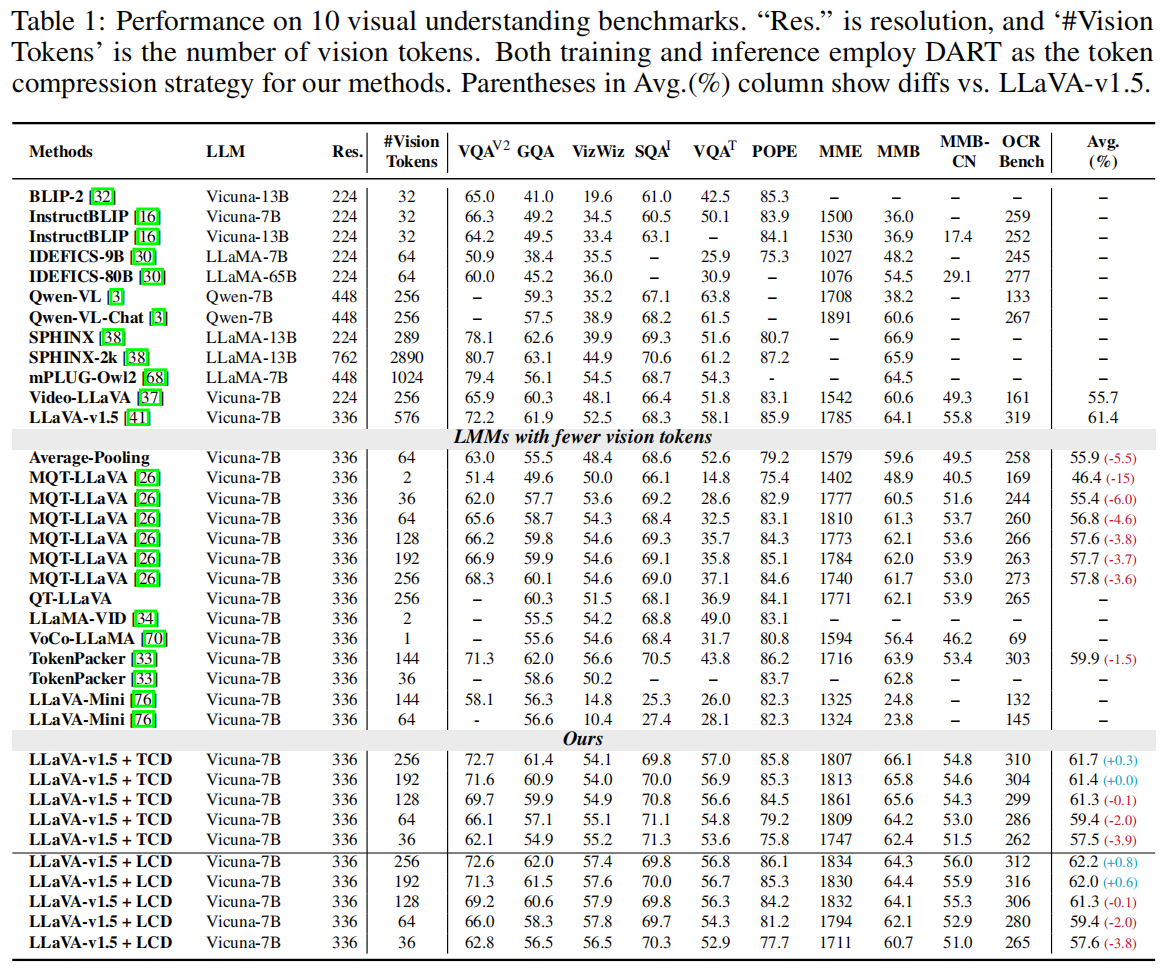
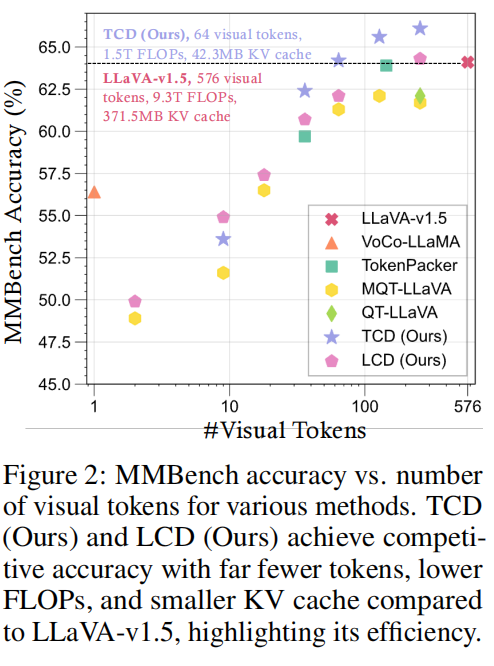
当保留 128 个视觉 token 时,EPIC 模型的性能与原始 LLaVA-v1.5-7B 几乎持平;当 token 数为 192 以上时甚至超越原始模型。这表明视觉 token 中存在大量冗余,压缩并不会显著损害性能。
在 MME、MMBench、VQA V2 等视觉密集型任务上,EPIC 的性能提升最为明显。 此外,模型在不同压缩率下表现稳定:当仅保留 64 个 token 时,性能下降不到 2%,128~256 token 区间几乎无损。
5.2 效率分析
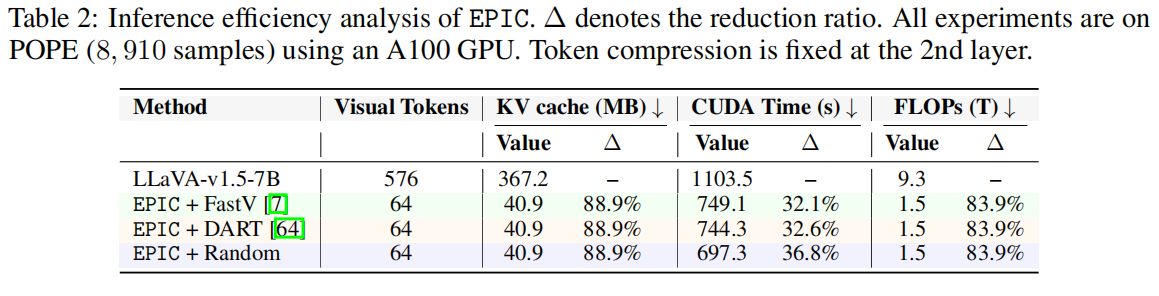
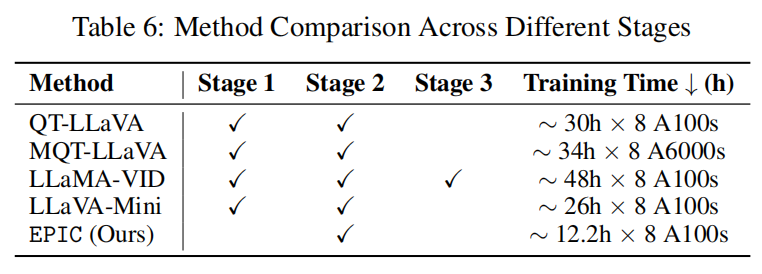
EPIC 在训练和推理效率上均优于其他方法。
-
训练阶段: 由于 EPIC 不修改模型结构,只需一次监督微调(Supervised Fine-tuning),在 8×A100 上训练约 12 小时。 而如 MQT-LLaVA、TokenPacker 等架构改造型方法需 30~48 小时。
-
推理阶段: 在 64 个 token 情况下,KV cache 占用下降约 90%,FLOPs 减少 80% 以上,推理速度提升约 1.6×。 即使采用最简单的 Random 压缩策略,也能显著降低延迟和显存消耗。
EPIC 的主要收益来自训练策略优化,而非复杂架构修改。
6. Analysis
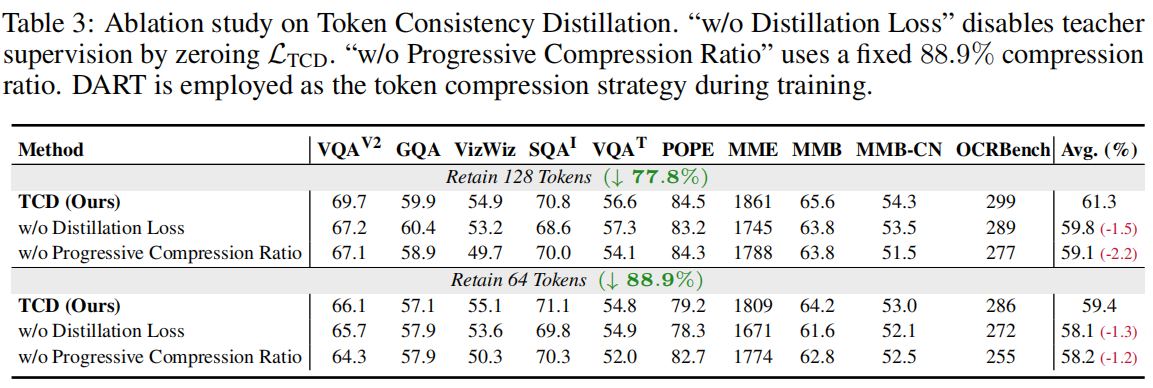
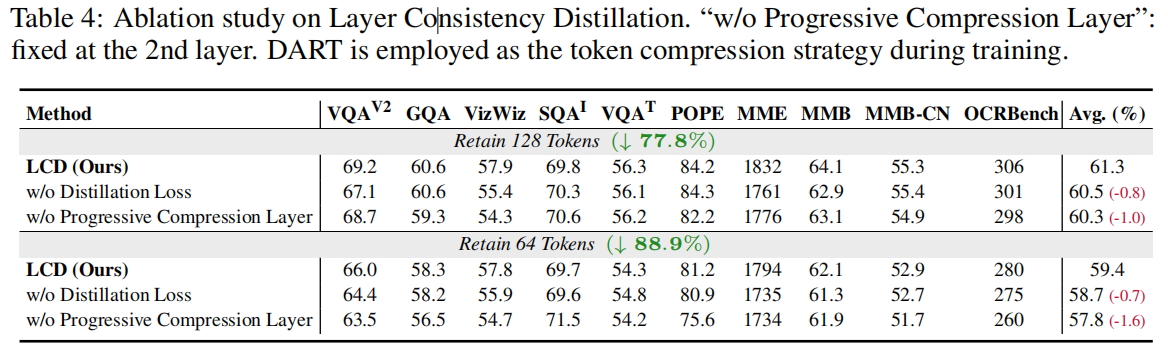
6.1 消融实验
- 无蒸馏 (w/o TCD/LCD): 性能显著下降,验证 teacher guidance 的必要性。
- 无渐进策略 (no progression): 直接使用固定压缩率训练时收敛不稳定,验证 progressive 学习的重要性。
- 跨压缩方法泛化性: 用 DART 训练、FastV 推理仍能保持性能,说明 EPIC 具备良好的跨策略鲁棒性。
6.2 是否需要极端压缩
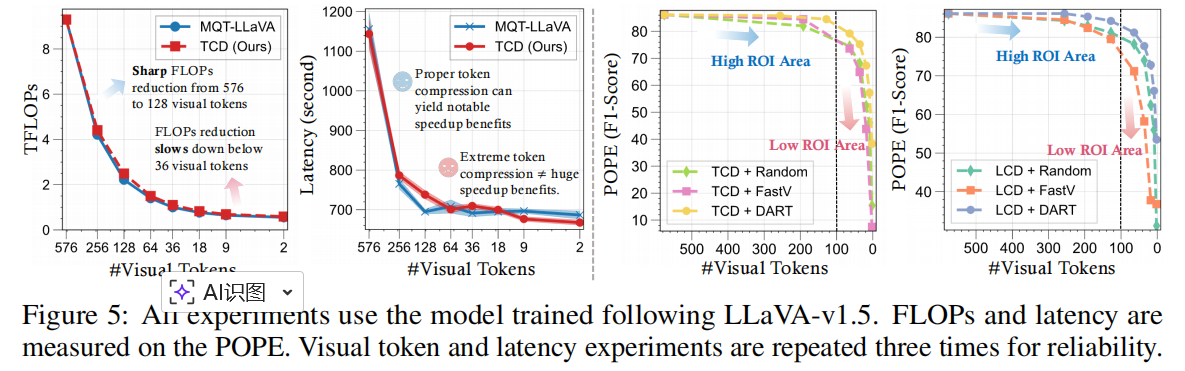
论文指出,虽然极端压缩(1 ~ 2 token)可进一步降低计算量,但性能下降剧烈,且 GPU 延迟收益有限。最佳权衡点通常在 64 ~128 tokens 区间,兼顾性能与速度。
7. Conclusion
本文提出的 EPIC 框架 在不改变模型结构的情况下,通过渐进一致性蒸馏实现了对视觉 token 压缩的高效训练。 其主要优势包括:
- 无需额外模块,直接与现有 MLLM 兼容;
- 训练稳定、收敛快速(12 小时即可完成);
- 在多项视觉基准上性能与原始模型持平或更优;
- 在 64~128 token 区间显著提升推理效率与资源利用率。
实验结果表明,合理的渐进蒸馏策略能够在不牺牲性能的前提下,大幅度提升多模态大语言模型的效率与鲁棒性。