
Conference: ICML'25
Github: https://github.com/vbdi/epdserve
1. Motivation
Large Multimodal Models (LMMs) 将视觉/音频/视频等感知模态引入到 LLM 的推理流程中,从而带来更强的能力,但随之而来的是额外的编码(encoding)阶段,该阶段会产生大量视觉(或音频)token,显著增加计算与内存消耗,并对关键的 SLO(如 TTFT、TPOT)造成负面影响。当前主流的 LLM-serving 系统(如 vLLM、DistServe 等)要么将编码与 prefill 聚合在同一资源上导致干扰与内存竞争,要么只对 LLM 的 prefill/decode 做优化,无法从根本上缓解 LMM 的编码瓶颈。因此论文提出通过**将 Encoding / Prefill / Decode 三阶段进行严格分离(EPD Disaggregation)**来重新设计服务架构,以解耦资源、并提供针对每阶段的定制优化,从而减少延迟、提升 SLO 达成率并大幅节省内存。
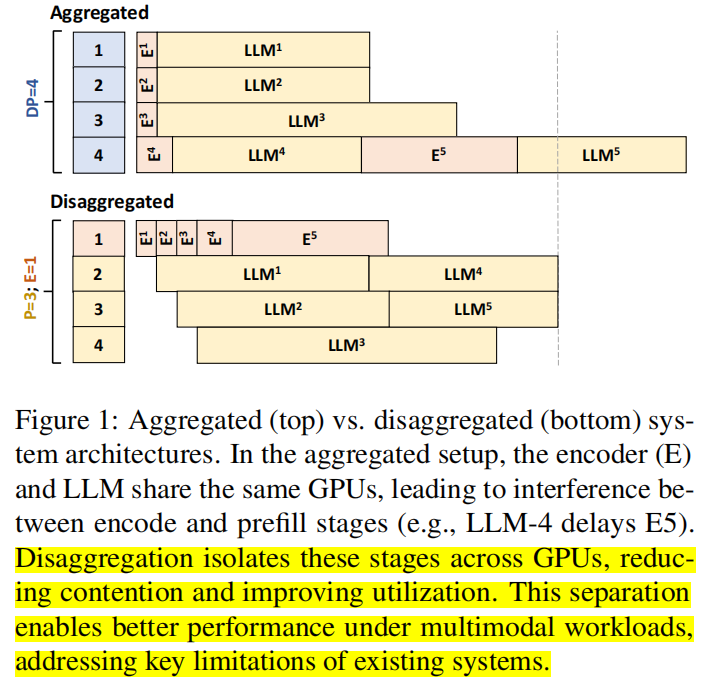
2. Related Work

- 现有 LLM 服务(vLLM、SARATHI、Orca 等)与 Disaggregated-serving(SplitWise、DistServe、DéjàVu 等)对 LLM 的 prefill/decode 分离带来了可观改进,但这些工作通常忽略或未充分优化编码(encoding)阶段,因此不适用于 LMM 的编码密集型工作负载。相较之下,本文填补该空白,提出将编码也作为独立可调度阶段,从而开启新的并行化、缓存与资源分配策略。
3. Method
3.1. EPD Disaggregation
EPD 把推理流程明确划分为三个独立阶段:Encoding (E)、Prefill (P)、Decode (D),并定义两类跨阶段迁移(migration)函数:
- EP-migration:编码阶段生成的 multimodal tokens $v^e_t$ 被传递到 prefill: $$v^p_t = \psi_{EP}(v^e_t)$$
- PD-migration:prefill 生成的初始 KV cache 与首个 token 经迁移至 decode: $$(kv^d_1, o^d_1) = \psi_{PD}(kv^p_1, o^p_1)$$
阶段内部流程:
- Encoding (E):把原始多模态输入 $i_m$(图像/音频/视频帧集合)通过 multimodal encoder $E$ 编码为视觉/模态 token 序列 $v^e_t = E(i_m)$。编码器通常为 ViT / CNN-backbone / audio-encoder 等组成的 MME(Multimodal Encoder)。
- Prefill (P):接受 $v^p_t$ 与文本 prompt $i_p$,生成 LLM 所需的初始 KV cache(prefill 阶段的 key/value)并产生第一个输出 token:$(kv^p_1, o^p_1) = P(v^p_t, i_p)$。
- Decode (D):标准自回归解码,用接收到的 KV cache 继续生成后续 token,更新 KV cache: $$(kv^d_{t+1}, o^d_{t+1}) = D(kv^d_t, o^d_t)$$
设计要点:解耦使每个阶段能独立做 batching、调度与 parallelism 策略(例如 E 可做 IRP,P/D 可做 TP/PP)。同时需要高效的跨阶段 token 迁移机制,以避免额外传输延迟吞噬分离带来的收益。
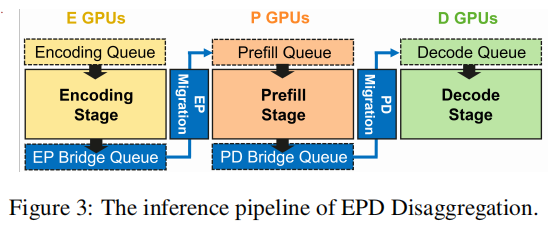
3.2. System Design and Optimization
总体架构(见 Figure 4):每个 stage 运行若干 instance(数据并行 DP),每个 instance 含 scheduler、block manager(缓存管理)、多个 worker(可内部做 TP/PP)。E workers 只加载 encoder 权重并维护 MM-cache;P workers 加载 LLM 权重并维护 MM + KV 缓存;D workers 仅加载 LLM 权重并维护 KV 缓存。实例之间以队列和异步传输进行耦合。
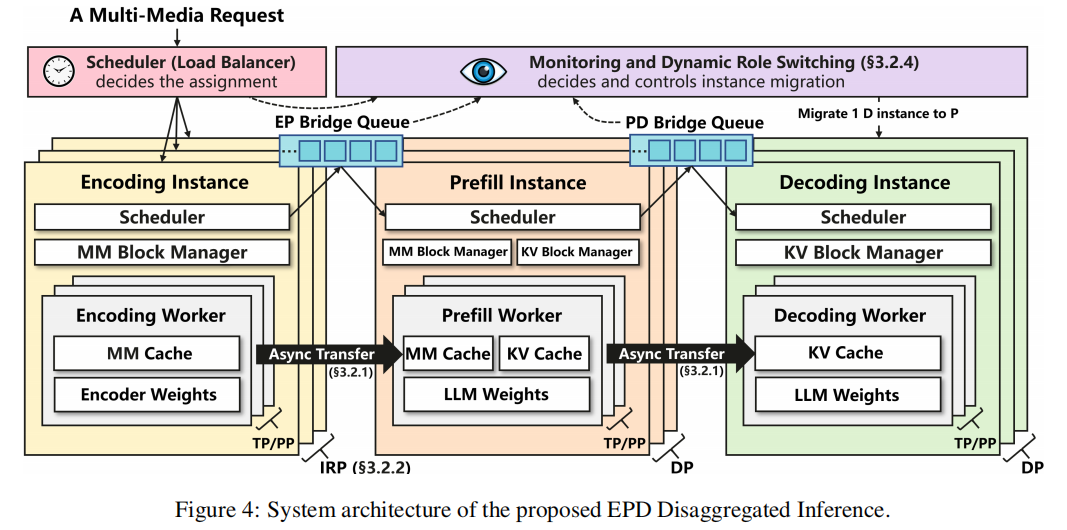
3.2.1. Asynchronous Token Transfer(异步 token 迁移)
-
问题:E → P 迁移新增了视觉 token 的传输步骤,如果同步阻塞会导致编码端无法接新请求,丧失并行优势。
-
方案要点:
-
使用高带宽直连通道(NVLink / InfiniBand / NCCL)进行直接异步传输,减少拷贝步骤。
-
MM cache:E 与 P 各自维护 MM cache(按请求粒度 pre-allocate block),编码完成后把 token 写入 E 的 MM cache,并由异步事件循环监测完成任务并触发迁移。
-
MMBlockManager:预分配 cache block,根据每个 request 的 token 大小分配、复用/回收 block,避免频繁的内存分配导致性能波动。
-
传输流程(伪代码):
on encoding_complete(request_id): mark MMBlock(request_id) ready enqueue transfer_task(request_id) to transfer_loop transfer_loop(): for task in pending_transfers: initiate async transfer via NCCL/CudaMemcpy/IB await confirmation update P.MM_cache[request_id] = received_tokens free E.MM_block(request_id)
-
-
实现细节:
- 在 intra-node(同机)用异步
cudaMemcpyAsync,跨节点用 NCCL / IB RDMA。 - 传输确认可通过短控制消息(tiny RPC)或直接核对目标缓存写入完成标志位。
- 为避免 head-of-line blocking,对 transfer_queue 需按 SLO 优先级(或短作业优先)调度。
- 在 intra-node(同机)用异步
3.2.2. Intra-Request Parallelism (IRP)
-
动机:单个请求常包含多张高分辨率图片或视频若干帧,MME 对每张图片会产生大量 patch-level tokens,使单请求编码成为瓶颈。
-
核心思想:把同一请求内部的 patch 划分为多个独立子任务,分配给多台编码 worker 并行处理(数据并行),各 worker 负责一部分 patch 的 embedding 计算,计算完后异步地将 patch-level token 传输到 P 端,P 端负责对齐(alignment)、线性投影(projection)与合并(merge)成最终的 multimodal tokens。
-
细节与保证一致性:
- 分割策略:按图像 patch 的空间切分(均匀划分)或按帧划分(视频),并记录 patch 元信息(position / order)。
- 对齐与合并:P 端在收到某请求的全部 patch-token 之后进行排序与合并。若缺少某些子块(如传输慢),可设置超时策略或先进行部分 prefill(trade-off)。
- 通信优化:由于 IRP 的 patch-level计算之间无需频繁通信(独立),在编码节点上可以避免 TP 带来的通信开销,故论文建议采用 IRP 而非传统的 TP 来并行化 E 阶段。
-
工程实现建议:
- 为每个编码子任务维护小的 request-id 与 patch-index metadata,确保 P 端能通过 metadata 重构顺序。
- 对高优先级 SLO 请求可采用更细粒度的分裂以减小 TTFT。
3.2.3. Optimized Resource Allocation
-
问题:系统有大量可调参数(每个 instance 的并行化 p、batch 大小 b、调度策略 s、实例数量等),需要在吞吐、延迟和 GPU 成本间权衡。
-
形式化:设性能函数 $f(p,b,s)$(好比 goodput),目标: $$ \max_{(p,b,s)\in X} f(p,b,s) - \beta \cdot cost(p) $$ 其中 $cost(p)$ 与使用 GPU 数量成正比,$\beta$ 控制成本惩罚权重。论文使用基于模拟器(扩展自 DistServe)的黑箱优化器(采用贝叶斯优化)来搜索配置空间。公式与约束写法保持论文原式。
-
搜索空间细化:
- 每个 instance 的并行化向量 $p_i$:对于 P/D 包括 $p^{TP}_i$(tensor-parallel)与 $p^{PP}_i$(pipeline-parallel);对于 E 使用 $p^{IRP}_i$(IRP 的 worker 数)替代 TP 的概念。
- Batch size 向量 $b$:每实例最大 batch(影响 latency vs throughput trade-off)。
- Scheduling 策略 s:Round-Robin / Least-Loaded / SLO-aware priority / Shortest-job-first 等。
-
实现策略:
- 先用快速模拟器评估大量配置,再对若干候选在真实集群上微调验证。
- 对 metric 采用多目标处理:基于目标的层次化目标(首先保证 SLO 达成,然后最大化 goodput)。
- 为避免搜索收敛到局部最优,论文在初始阶段使用随机样本+贝叶斯优化混合策略。
3.2.4. Dynamic Role Switching
-
动机:线上负载会动态变化,静态离线优化配置在工作负载突变时会失效。重启或重新初始化实例代价高且会影响已在处理的请求(需保留缓存)。
-
机制:
- 监控所有 stage 的队列统计(队列长度、等待时间、SLO 违约率),当检测到某阶段负载高时,系统将把一台或多台 instance 从源阶段 S 迁移到目标阶段 T。
- 迁移流程分三步:Offload(停止接新请求并把队列内任务迁移给同阶段其他实例)、Migration(更换模型与缓存类型,例如从 LLM→MME,KV cache↔MM cache)、Onload(恢复接新请求)。
- 迁移时间:论文测得通常小于 0.7s;E 相关迁移更耗时(需加载 MME 权重与切换 cache),P↔D 切换较快(可复用 LLM 权重与 KV cache)。
-
实验中的角色切换示例:在一个实验中,系统会从初始 5E1P2D 配置动态转为 2E1P5D,以应对解码负载从 50 tokens → 500 tokens 的突发增长,显著降低 TPOT 与总体延迟。
4. Experiments
实验平台与超参数
- 硬件:8 × NVIDIA A100(82GB),每台服务器 128 CPU cores,1TB RAM,CUDA 12.2。NPU 实验使用 Huawei Ascend(论文 Appendix F)。
- 数值精度:FP16;attention 使用 FlashAttention-2。
- 统一推理引擎设置:block size=16;最大 2048 blocks/request;context tokens 上限 49152;decoding tokens 上限 81920/batch;调度策略 FCFS;KV cache GPU 利用率设置为 50%;每 prompt 最大 multimodal 数据 32;MM cache size 固定为 3000;vLLM 版本 0.6.1.post1(作为 baseline 的实现基础)。在线实验使用 Poisson 到达过程(每 trial 至少完成 100 requests)。
Baselines 与模型
-
Baselines:
- vLLM:聚合式(monolithic)服务,E/P/D 全放同一组 GPU。
- DistServe:PD disaggregation(prefill-decode 分离),但 E 与 P 聚合在同一组 GPU(论文对其做了扩展以支持 multimodal)。
-
Models:
- MiniCPM-V 2.6(8B total,SigLip-400M encoder + Qwen2-7B LM)。
- InternVL2-8B(InternViT-300M-448px + internlm2 7.7B)。
- InternVL2-26B(InternViT-6B-448px + internlm2-chat-20B)。 详细模型说明见 Appendix E.2。
-
Datasets:
- Synthetic workload(可配置 prompt 长度 / images per request / resolution / output length / sampling 等);
- NextQA(视频 QA,真实分布,sampled frames=8);
- Video-MME(Video 多模态 benchmark,multiple-choice QA,支持变量帧数,按 MiniCPM 推荐 frame 设置实验)。
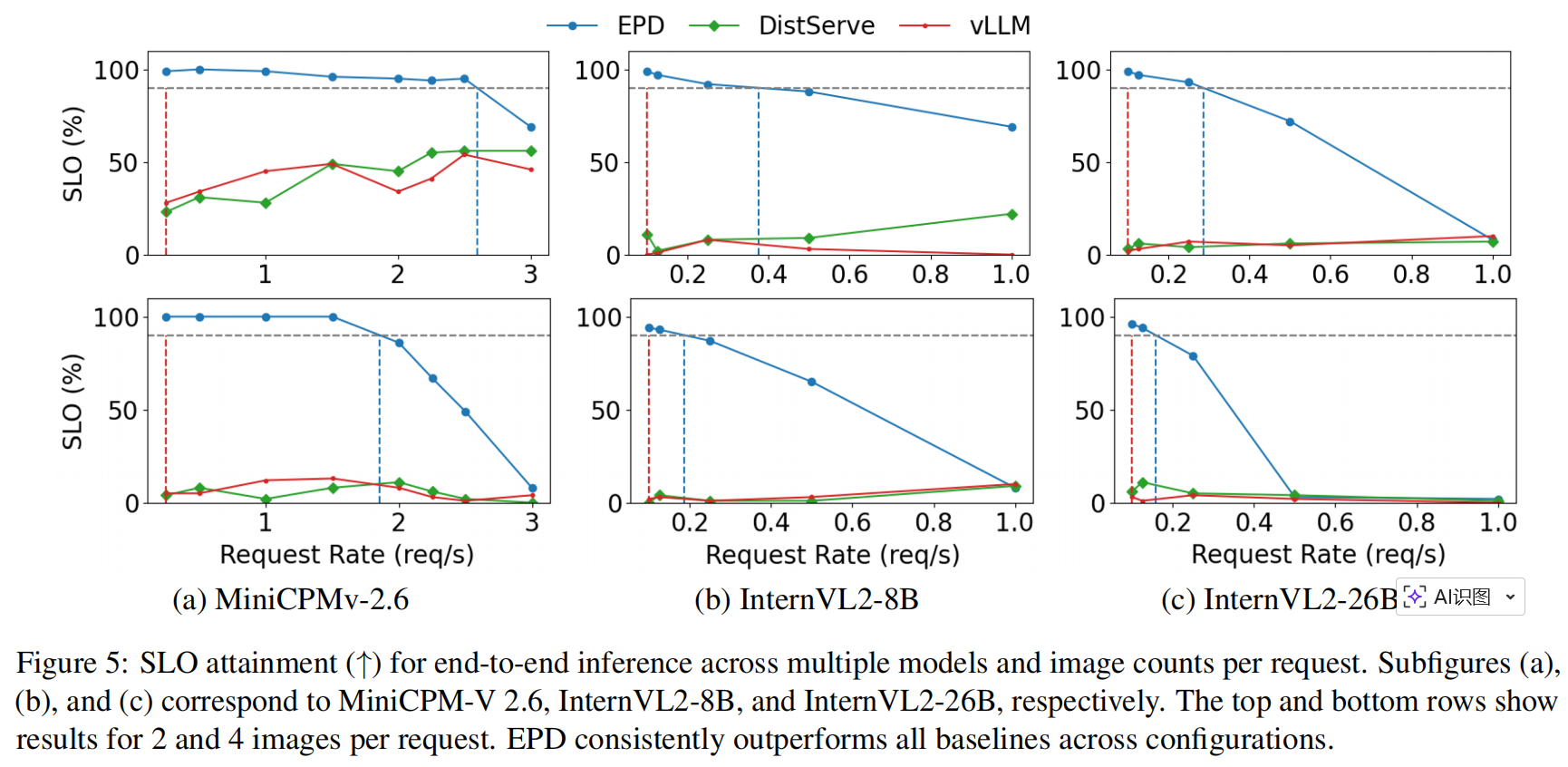
4.1. SLO Attainment for End-to-End Generation
-
实验设计:
- 在线 setting,100 requests 按 Poisson(λ) 到达;输出长度固定为 10 tokens;测试 2 / 4 images per request(res=4032×3024)。
- SLO 条件(不同模型/ #I/R)详见 Appendix E.3(例如 MiniCPM-V TTFT=1.40(#I/R=2)等)。
-
关键结论:
- EPD 在较低请求率下就能达到 ≥90% SLO attainment(goodput 明显优于 baselines),因为 EPD 能把编码并行化到多 GPU(IRP),减少编码对 prefill 的 head-of-line blocking,进而减少 TTFT 与 TPOT 的违约;DistServe 与 vLLM 因资源争用和队列积压在高负载下 SLO 达成率会陡降。
-
图表:Figure 5 展示不同模型与不同 images-per-request 的 SLO attainment 曲线(EPD 恒优)。
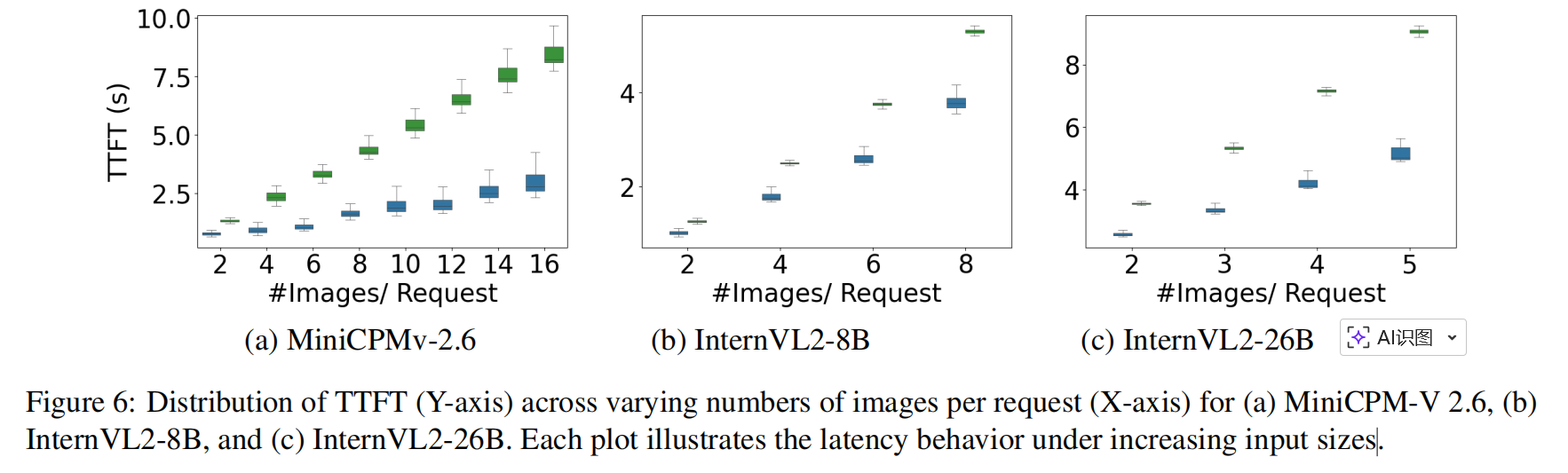
4.2. First Token Generation Latency(TTFT)
-
实验:
- 分析 TTFT 分布(boxplot),比较 EPD 与 baselines(vLLM/DistServe),不同模型、不同 image counts。
- 对 MiniCPM-V 2.6 采用 λ = 0.25;InternVL2-8B 与 26B 采用 λ = 0.08(paper 中设定)。
-
发现:
- IRP 极大降低 TTFT:相对 DistServe,EPD 在 MiniCPM-V 上可降低 TTFT 约 71.9%,在 InternVL2-26B 上 44.9%。视频任务(Video-MME)上 Table 1 给出不同帧数下的 mean TTFT(EPD 明显更低,且随着帧数增长,差距放大)。

- IRP 极大降低 TTFT:相对 DistServe,EPD 在 MiniCPM-V 上可降低 TTFT 约 71.9%,在 InternVL2-26B 上 44.9%。视频任务(Video-MME)上 Table 1 给出不同帧数下的 mean TTFT(EPD 明显更低,且随着帧数增长,差距放大)。
(单位:秒;EPD 在所有帧数下最低,尤其在长视频/大帧数时优势更明显。)
4.3. Memory Savings through Stage Disaggregation
-
核心事实:
- E workers 无需加载 LLM 权重与 KV cache,因此单从权重角度计算,E worker 的内存需求能减小约 78%–96%(取决于模型)。论文在 profiling 中测得实际峰值 memory 可达 15× 的降低(约 93.3% saving)。
-
影响:
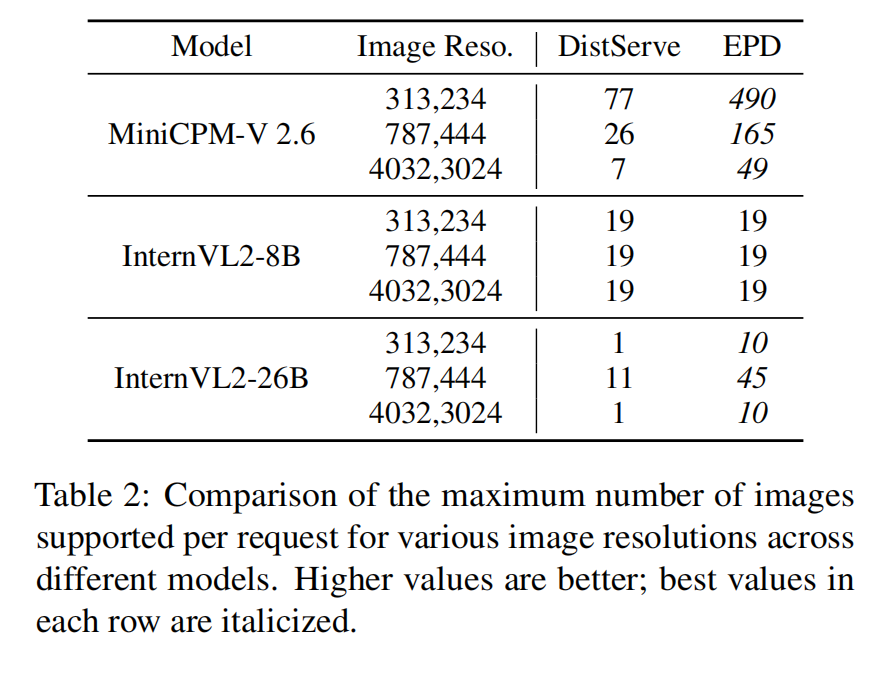
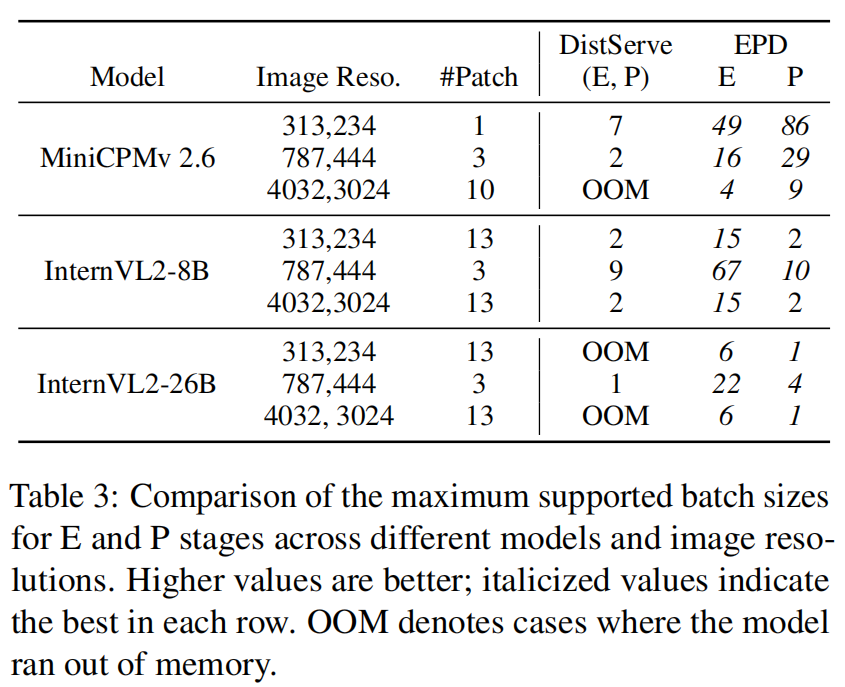
- 导致支持的 images-per-request 与 batch size 显著增加(Table 2, Table 3)。
- 例如,在 4032×3024 分辨率下,InternVL2-26B 对比 DistServe,EPD 支持的 images/req 增长 7×(表中列举)。
-
代表表格片段(论文 Table 2/3):显示了不同模型/分辨率下 EPD 与 DistServe 的最大 images-per-request 与最大 batch sizes(E、P 两阶段),EPD 在很多配置下避免 OOM 并显著提升 batch/图片容量。
4.4. Ablation Study(消融)
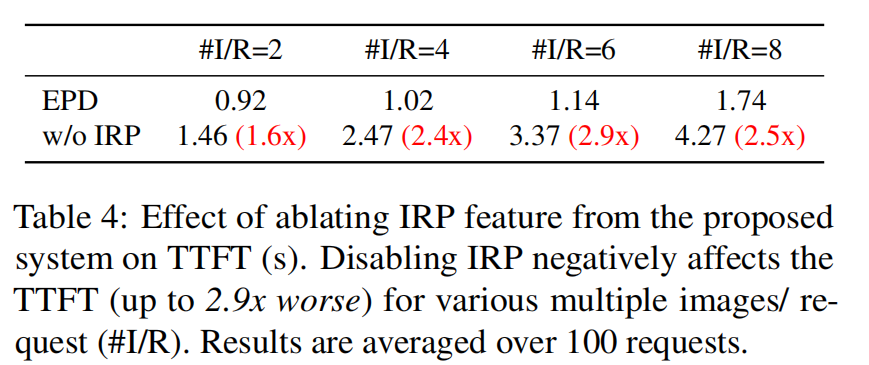


论文对关键组件做了系统消融以量化其贡献,主要包括 IRP、offline optimizer、dynamic role switching:
- Effect of IRP(Table 4):关闭 IRP 导致 TTFT 增加 1.6×–2.9×(随图片数增加作用更强)。说明 IRP 对于多图请求/长视频场景是关键。
- Effect of Offline Optimizer(Table 5):若随机选择配置代替优化器,goodput 平均下降 2.2×,TTFT 变差约 2.1×,说明黑箱优化器在配置选择上很重要(论文用贝叶斯优化 + 模拟器加速搜索)。
- Effect of Dynamic Role Switching(Table 6):在工作负载突变的场景下(前 10 请求 50 tokens,后 90 请求 500 tokens),若禁用 dynamic switch,总体延迟与 TPOT 均显著恶化(end-to-end latency 从 28.01s → 61.10s,TPOT 从 0.05 → 0.12,表中给出具体倍数)。说明动态迁移对于在线系统稳定性至关重要。
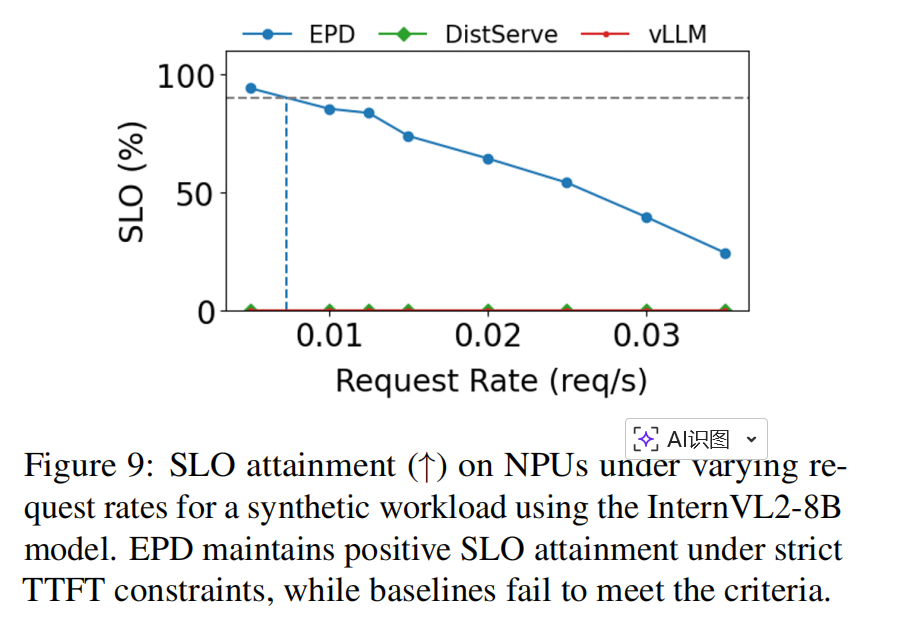
4.5. Adaptation to Neural Processing Units (NPUs)
-
动机:NPUs(如 Ascend)在 encode→prefill 延迟比上通常更高(encode 成本更重),因此 EPD 的 disaggregation 对 NPU 的增益可能更明显。
-
实验与结论:
- 在 InternVL2-8B 的 NPU 实验(8 × 4K images/request,最佳配置 5E2P1D)中,EPD 是唯一能满足 SLO(TTFT ≤ 8.5s, TPOT ≤ 0.12s)的方案,vLLM/DistServe 均无法达成。
- EPD-NPU 相较于 vLLM 的 TTFT 改进达到 35.2%(比 GPU 场景的 24.4% 更优),原因是 NPU 上 encoding 相对更耗时,分离带来的平行化收益更大。
5. Conclusion
EPD Disaggregation 通过把编码(E)、prefill(P)与 decode(D)三阶段解耦,结合异步 token 迁移、IRP、资源分配黑箱优化器与动态角色切换,在多模型、多数据集与多硬件平台(GPU / NPU)上验证了显著优势:更低的峰值内存(高达 15×)、更大 batch 与更多 images-per-request、显著更高的 SLO attainment 与更低 TTFT。论文同时指出:当吞吐(throughput)而非 SLO 为首要目标时,聚合式方案在 GPU 利用率上可能更具成本效益;因此 EPD 适合对 latency 有强约束的云服务场景。
6. Limitations
- Disaggregation 引入跨阶段通信开销与 pipeline bubble 风险;在一些以吞吐为主、对延迟 SLO 不敏感的场景下,聚合式配置可能更划算(higher GPU utilization)。
- EPD 的收益对工作负载特性敏感:编码-预填内存/计算不平衡时需要精细调节资源分配与动态迁移策略;visual token migration 在高并发下可能成为瓶颈(可通过 token 压缩/剪枝缓解)。
7. Future Work
- 异构硬件调度:在 EPD 框架中将 E 部署到低内存高计算设备(或边缘设备)而 P 部署到高内存 GPU,可进一步提升成本效率。
- 视觉 token 压缩:利用 token pruning / compress 技术(如 DivPrune 等)减少迁移带宽占用与传输延迟。
- 隐私相关的边缘-云混合部署:把编码放在边缘设备上,云端仅处理编码表示以减少隐私风险。