
Conference: MobiCom ‘25
Github: https://github.com/yinwangsong/ElastiLM
1. Motivation
端侧 LLM 需要弹性(Elasticity)。LLM 虽然能够处理广泛的语言任务,但其巨大的参数量使得在设备上为每个任务部署独立的模型既不“必要”也不“实际”。因此,端侧 LLM 通常作为系统服务(LLM-as-a-Service)被多个任务和 APP 共享。然而,单一的静态 LLM 无法满足不同任务对服务水平目标(Service-Level Objectives, SLOs)的多样化需求。
因此,端侧 LLM 必须具备弹性。由于 LLM 推理包含两个截然不同的阶段,这种弹性的需求变得更加复杂:
- Prefill(预填充阶段):处理 Prompt 的速度,由 Time-To-First-Token (TTFT) 衡量。
- Decode(解码阶段):生成 Token 的速度,由 Time-Per-Output-Token (TPOT) 衡量。

不同的应用对这两个指标有截然不同的要求(如上表所示):
- Chatbot:需要低 TTFT 和低 TPOT 以匹配人类阅读速度。
- UI 自动化 Agent:需要低 TTFT 来快速响应首个动作,但对 TPOT 要求较低(因为生成过程可以与 UI 操作重叠)。
- 后台屏幕录制器:对 TTFT/TPOT 的容忍度都很高。
如果无法满足 SLO,会导致用户体验严重下降或 Agent 交互失败。理想情况下,请求发送给弹性 LLM 时会附带 Prompt 和预期的 SLO,LLM 需要在不违反 SLO 的前提下提供最高的文本生成质量。
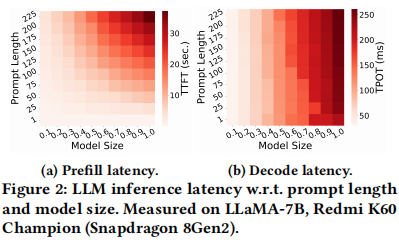
作者的先导实验表明(如图2):
- TTFT 与 Prompt 长度和模型大小均成正比:$TTFT \propto PromptLength \times ModelSize$。
- TPOT 在 KV Cache 的帮助下,主要与模型大小成正比:$TPOT \propto ModelSize$。
这意味着作者需要同时从 模型维度(Model Dimension) 和 Prompt 维度(Prompt Dimension) 进行弹性化。
面临的挑战 (Challenges): 尽管现有的剪枝技术(Pruning)和 Prompt 压缩技术存在,但在端侧实现弹性服务面临独特挑战:
-
昂贵的运行时切换开销 (Costly runtime switching):
- 传统的结构化剪枝(Structural Pruning)产生的子模型(Sub-models)在内存中是不连续的(如图3a)。
- 为了利用端侧深度优化的密集计算内核(Dense Kernels),必须在推理前重新排列权重以保证内存连续性(Data movement),或者在内存中维护多份模型副本(内存不可接受)。
- 数据: 例如,在 Redmi K60 上,将 LLaMA-7B 的 20% 子模型切换到 30% 子模型需要 8.2秒,这对于实时服务是不可接受的,且这部分时间会计入 TTFT。
-
敏感的 Prompt-Model 编排策略 (Sensitive prompt-model orchestration):

- 对于一个特定的 SLO,存在多种“Prompt 压缩率 + 模型剪枝率”的组合策略。
- 数据: 如图 5 所示,对于 ARC_E 数据集的一个 Prompt,策略 A(50% Prompt / 80% Model)和策略 B(80% Prompt / 50% Model)虽都能满足延时要求,但只有策略 A 能生成正确答案。
- 随机选择策略会导致显著的精度下降(在 Octopus 数据集上相比 Oracle 策略下降 15.2%)。
2. Contribution
作者的解决方案:ElastiLM。作者提出了 ElastiLM,这是一个为端侧 LLM 设计的弹性服务系统。它通过以下核心技术解决了上述挑战:
-
One-shot reordering of permutation consistent units (置换一致单元的一次性重排序):
- 利用 Transformer 模型中固有的“置换一致性(Permutation Consistency)”特性。
- 核心思想:识别出可以任意重新排列且不改变模块输出的单元(即 Attention Heads 和 MLP Neurons)。
- 方法:离线通过可解释性 AI(XAI)方法分析单元重要性,依据重要性对单元进行重排序,确保存储时重要单元在内存上是连续的。
- 优势:在线推理时,模型切换(升级/降级)变成了零成本的内存指针移动(Slicing),无需任何数据搬运。
-
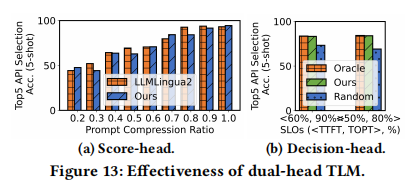
Dual-head Tiny Language Model (TLM) for prompt-model orchestration (双头微型语言模型用于编排):
- 设计了一个仅有 40M 参数的轻量级模型(基于 MobileBert)。
- Score-head:用于评估 Token 重要性并进行 Prompt 压缩。
- Decision-head:用于根据当前 Prompt 和 SLO,预测最佳的 Prompt 压缩率和模型大小组合。
- 优势:通过离线的“自诱导标注(Self-induced labelling)”进行训练,实现了端到端的最佳策略选择。
-
全面的评估:
- 在 3 款商用智能手机和 5 个 LLM(3B-7B)上进行了实现。
- ElastiLM 在满足所有请求 SLO 的前提下,端到端准确率平均比强基线高出 10.45%(最高达 14.83%)。
- 切换开销小于 TTFT 的 1%,且离线处理成本极低(<100 GPU hours)。
3. ElastiLM Design
3.1 Overview
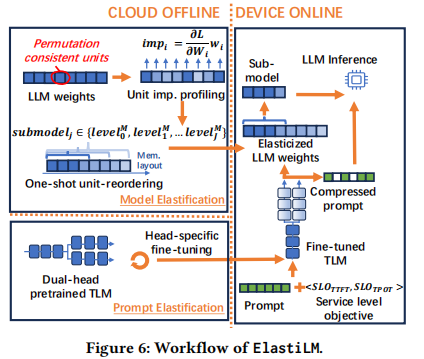
如图 6 所示,ElastiLM 采用 两阶段工作流(Two-stage workflow):
-
云端离线阶段 (Cloud Offline Stage):
- 模型弹性化:对 LLM 进行处理,生成一系列共享内存权重的子模型。利用重排序技术确保子模型间的切换成本极低。
- Prompt 弹性化:微调一个双头 TLM(Tiny Language Model),用于在线决策。
-
设备在线阶段 (Device Online Stage):
- 部署弹性化后的 LLM 和微调后的 TLM。
- 当请求到达时(包含 Prompt 和 SLO $< \alpha_{TTFT}, \alpha_{TPOT} >$),TLM 接收输入并输出压缩后的 Prompt 以及合适的子模型大小。
- LLM 基于选定的配置执行推理。
3.2 Model elastification (模型弹性化)
这是 ElastiLM 解决“昂贵切换开销”的核心设计。
3.2.1 Permutation Consistent Units (置换一致性单元)
ElastiLM 利用了 Transformer 模型的数学特性——置换一致性。
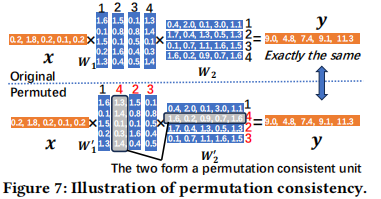
- Property 1:如果在神经网络的一个 Block 内部重新排列单元(Units)的顺序,只要输入/输出保持不变,计算结果就是等价的。这是因为 Reduce 算子(如 Sum/Add)满足交换律和结合律。
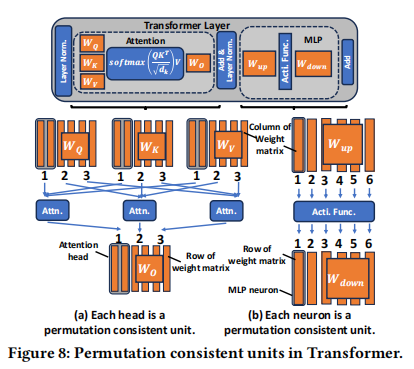
- Property 2:在 Transformer 中,Attention Heads(注意力头) 和 MLP Neurons(MLP 神经元) 是相互独立的置换一致性单元。
- Attention Head Unit: 包含 $W_Q, W_K, W_V$ 的对应列以及 $W_O$ 的对应行。
- MLP Neuron Unit: 包含 $W_{up}$ 的对应列和 $W_{down}$ 的对应行。
3.2.2 One-shot Unit-reordering (一次性单元重排序)
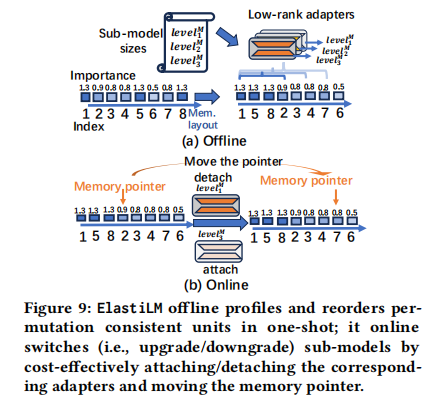
ElastiLM 不像传统剪枝那样直接删除权重,而是通过 重排序(Reordering) 来构造子模型。
-
Unit Importance Profiling (单元重要性分析):
-
使用 XAI (可解释 AI) 的思想,通过梯度来衡量单元的重要性。
-
定义单元 $i$ 的重要性 $imp_i$ 为移除该单元后 Loss 的变化量。基于泰勒展开近似:
$$ imp_i = |L - L_{W_i=0}| \approx |\frac{\partial L}{\partial W_i}W_i| $$
-
使用校准数据集(如 Bookcorpus)计算上述重要性得分。
-
-
Offline Reordering (离线重排序):
- 根据 $imp_i$ 对 Block 内部的单元进行降序排列。
- 结果:最重要的单元被移动到了权重矩阵的前部(Base address),最不重要的在后部。
- Sub-model Construction:子模型被定义为从基地址开始的连续内存段。例如,50% 大小的子模型就是重排序后权重矩阵的前 50% 部分。
-
Sub-model Recovery with LoRA (基于 LoRA 的子模型恢复):
- 剪枝(即只取前 N% 的单元)可能会导致精度损失。ElastiLM 为每个子模型级别(如 50%, 60%…)训练一个对应的 Low-Rank Adapter (LoRA)。
- LoRA 参数量极小(< 0.5%),不会带来显著的内存开销。
-
Online Switching (在线切换):
- 零拷贝(Zero-copy):由于子模型在物理内存上是连续的(都在前部),从 20% 切换到 50% 只需要移动内存指针(Memory Pointer),这在 C++ 中几乎是零成本的操作。
- 操作流程:Detach 当前 LoRA -> 移动权重指针 -> Attach 新的 LoRA。
- 数据:在 Redmi K60 上,升级 $W_O$ 矩阵仅需 2ms,而传统方法的数据搬运需要 140ms。
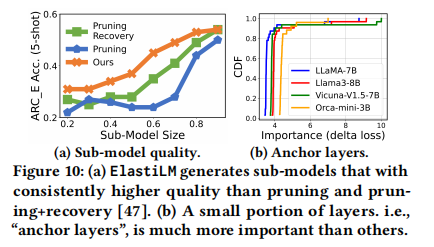
3.2.3 Anchor Layers Locking (锚点层锁定)
作者发现层的重要性分布遵循 幂律分布(Power-law distribution)(80/20 法则)。约 20% 的层(称为 Anchor Layers)对模型性能至关重要。
- 策略:ElastiLM 锁定这些锚点层,不对其进行弹性化(即始终保持完整大小),只对剩余层进行弹性化。这显著提升了子模型的质量。
3.3 Prompt elastification (Prompt 弹性化)
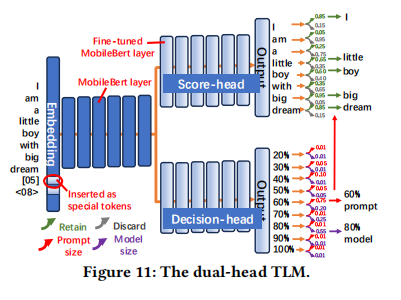
ElastiLM 使用一个 Dual-head TLM 来解决 Prompt 压缩和 Prompt-Model 编排问题。
3.3.1 Dual-head TLM Architecture (双头 TLM 架构)
- Backbone: 基于 MobileBert(仅为 BERT_base 参数量的 20%),轻量且高效。
- Input: 原始 Prompt + SLO Special Tokens。
- SLO 被编码为特殊 Token 插入 Embedding 层,例如
[05]代表 50% TTFT,<08>代表 80% TPOT。
- SLO 被编码为特殊 Token 插入 Embedding 层,例如
- Head 1: Score-head (打分头):
- 任务:二分类问题。判断每个 Token 是“保留(Retain)”还是“丢弃(Discard)”。
- 输出:Token 的重要性分数,用于后续压缩。
- Head 2: Decision-head (决策头):
- 任务:多分类问题。
- 输出:选择最佳的 Prompt 压缩率(如 60%)和 模型大小(如 80%)。
- Shared Bottom Layers: 两个头共享底层的 12 层 Transformer,以最小化开销。
3.3.2 Training Strategy (训练策略)
- Score-head Training: 使用 MeetingBank 数据集(由 GPT-4 标注 Token 重要性)进行微调。
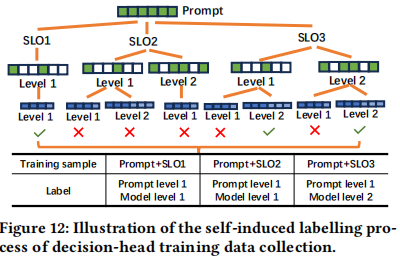
- Decision-head Training (Self-induced labelling):
- 为了解决“不知道哪个策略组合最好”的问题,ElastiLM 采用 自诱导标注。
- 过程:离线遍历所有可能的 Prompt 压缩率和模型大小组合,找到能够满足 SLO 且能够输出正确答案的最轻量级组合作为 Label(标签)。
- 使用 MMLU-Pro 等数据集生成训练样本。
3.3.3 Inference Workflow (推理流程)
- TLM 接收 Prompt 和 SLO。
- Decision-head 输出推荐的配置(例如:60% Prompt + 80% Model)。
- Score-head 计算每个 Token 的保留概率。
- 根据推荐的 Prompt 比例(60%),保留 Score 最高的 Top-60% Token。
- 如果 Decision-head 的决策无法满足 SLO(极少数情况),系统会回退到满足 SLO 的随机安全策略。
4. Implementation and Evaluation
4.0 Implementation (实现细节)
- Offline: 基于 PyTorch 和 HuggingFace Transformers 库修改,增加了单元重要性分析和重排序功能。
- Online: 基于 mllm(一个轻量级端侧 LLM 推理库,C++/Assembly 编写)。
- Kernel: 实现了
ElasticLinear算子,替换了标准的Linear算子。该算子封装了原始的 Dense Kernel,增加了一个内存指针用于指定子模型的权重地址,从而支持零拷贝切换。 - LoRA: 使用 ARM NEON 指令集优化了 LoRA 的矩阵乘法和加法。
4.1 Experimental settings (实验设置)

- Devices: Redmi K60 Champion (SD 8Gen2), Mi 14 (SD 8Gen3), Redmi K70 Pro.
- Models: LLaMA-7B, Llama3-8B, Vicuna-V1.5-7B, Orca-mini-3B.
- Baselines:
- PFS (Pre-trained From Scratch): 为每个 SLO 部署一个独立大小的模型(如 OPT-1.3B, 2.7B)。
- LLMPruner (LPruner): SOTA 结构化剪枝方法。
- LLMLingua2 + Contextual Sparsity (LG2+CS): Prompt 压缩 + 上下文稀疏化。
- Layer-wise Elastification (LE) / LaCo: 层级剪枝方法。
- Workload: 6 个数据集(ARC_E, Octopus 等)和合成的端到端 Trace(模拟不同 SLO 分布)。
4.2 End-to-end performance (端到端性能)
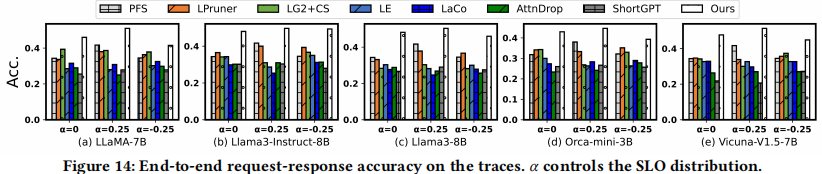
- Accuracy: 在混合 SLO 的 Trace 测试中,ElastiLM 的准确率显著优于所有基线,平均提升 10.45%,最高提升 14.83%(如图 14)。
- 优于 PFS 的原因:PFS 无法充分利用 SLO 之间的空间,且 ElastiLM 继承了大模型的涌现能力。
- 优于 LPruner 的原因:ElastiLM 结合了 Prompt 弹性化,且没有切换开销。
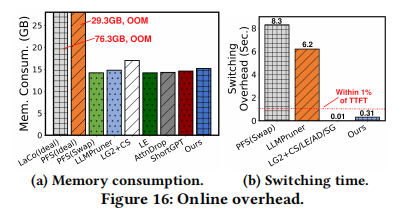
- Switching Overhead (切换开销)(如图 16b):
- PFS (Swap) 和 LPruner 需要 6.2s - 8.3s 来切换模型(因为涉及内存数据搬运或磁盘 I/O)。
- ElastiLM 仅需 0.31s,低于平均 TTFT 的 1%,几乎可以忽略不计。
4.3 Performance on standalone datasets (独立数据集性能)
- 在给定的特定 SLO 下,ElastiLM 在所有数据集上均表现出色。
- 特别是在 紧缩的 SLO (Tight SLOs) 下,ElastiLM 通过同时压缩 Prompt 和模型,能够在基线方法无法运行或精度极低的情况下保持较高的准确率(提升高达 40%)。
4.4 Offline stage overhead (离线阶段开销)
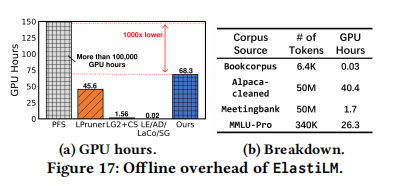
- GPU Hours: 弹性化 LLaMA-7B 仅需 68.3 GPU hours(约 100 美元成本)。
- 相比之下,PFS 需要从头训练多个模型,耗时超过 100,000 GPU hours(相差 1000 倍)。
- ElastiLM 的主要时间花费在 Model Recovery (40.4h) 和 Self-induced labelling (26.3h) 上,这是一次性成本。
4.5 Sensitivity analysis (敏感性分析)
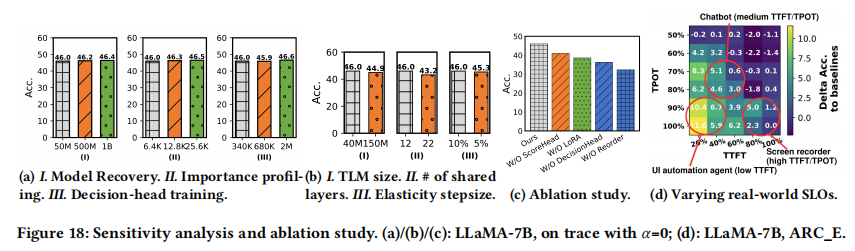
- Ablation Study (消融实验)(图 18c):
- 移除 Reordering (重排序) 导致最大的性能下降(>10%),证明了保留重要权重位置的重要性。
- 移除 Decision-head 或 LoRA 也会导致明显的精度损失。
- Data Scale: 增加恢复数据量带来的收益呈边际递减,当前的配置(50M Token)是性价比最高的甜点。
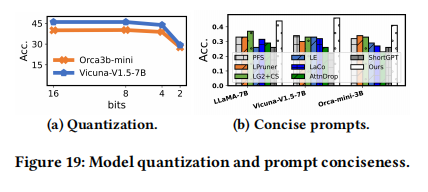
- Quantization: 结合 8-bit 量化几乎无损,4-bit 量化仅损失 3% 精度。
5. Discussion
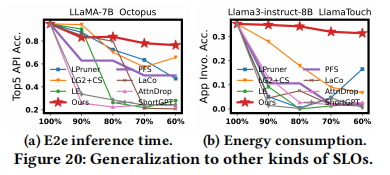
Generalization to other SLOs (泛化到其他 SLO)。虽然本文主要关注推理延迟(Latency),但 ElastiLM 的方法可以轻松泛化到其他指标。
- Total Time SLO ($SLO_{time}$): 端到端总时间(Prefill + Decode)。
- Energy Consumption SLO ($SLO_{energy}$): 推理能耗。 作者在 Mi 14 上进行了实验(如图 20),结果表明 ElastiLM 在这些新的 SLO 定义下依然持续优于基线。这是因为这些资源约束本质上都可以分解为 Prompt 和 Model 维度的计算量缩减。
Apps with competing demands (多应用竞争资源)。在常规端侧 LLM 服务模型中,通常没有并发请求。但在极端场景下,如果有多个 App 竞争资源,ElastiLM 可以通过上层调度机制(如 Batching)来处理,这对开发者是透明的。
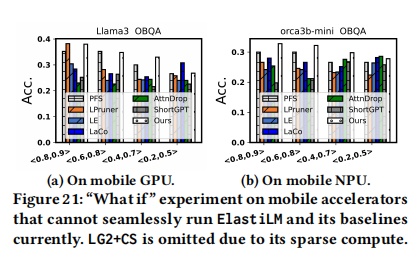
On mobile SoC accelerators (移动 SoC 加速器)。目前(2024年8月),移动端的 NPU/DSP SDK(如 SNPE, QNN)尚不支持 ElastiLM 所需的动态 Shape、动态图构建或非稀疏内核的无缝运行。因此,作者进行了一个 “What if” 实验:通过将理论计算/内存负载映射到 Profiling 数据来模拟性能。
- 使用 MNN 和 mllm-NPU 分别在 Mi 14 的 GPU 和 NPU 上进行模拟。
- 结果(如图 21)显示,即使在加速器上,ElastiLM 依然显著优于基线。作者相信随着 AI 硬件和编译器的成熟,ElastiLM 将变得更加实用。
6. Conclusion
本文提出了 ElastiLM,一种面向端侧的弹性 LLM 服务,能够适应具有多样化 SLO 的 App 请求。
- 通过 One-shot reordering of permutation consistent units,实现了零成本的运行时模型切换。
- 通过 Dual-head TLM,实现了 Prompt 和 Model 弹性化的智能编排。
- 实验证明,ElastiLM 在准确率上比竞争基线高出 14.83%(平均 10.45%),并且具有极低的切换开销和离线成本,是目前端侧弹性 LLM 服务的最佳解决方案。