
Conference: NeurIPS'25 Oral
1. Background and Motivation
多模态大语言模型(Multimodal Large Language Models, MLLMs)在传统 LLM 的基础上扩展了图像、视频、音频等输入模态,使模型能够进行跨模态理解与推理。然而,这些额外组件(如视觉编码器、投影模块等)带来了显著的推理开销。由于多模态推理流程复杂、任务异构,MLLM 的高效部署成为一个重大挑战。
现有的大多数推理服务架构(serving architecture)采用紧耦合(tightly coupled)设计,无法区分不同请求类型,也无法在不同阶段灵活地调整并行策略,导致 time-to-first-token (TTFT) 延迟增大、GPU 资源利用率低下。
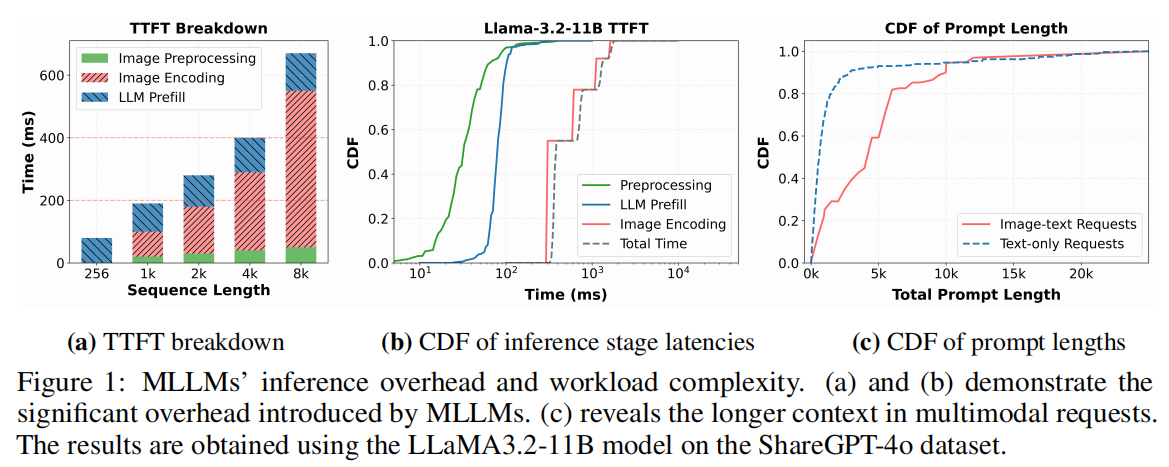
与传统仅处理文本的 LLM 不同,MLLM 需要同时处理多种模态的输入,因此推理流程更复杂,通常包括:
- Image Preprocessing:对原始图像进行裁剪、缩放、分块;
- Image Encoding:通过视觉编码器提取特征并转化为 vision token;
- Text Generation:将 vision token 与文本 prompt 拼接后输入语言模型,经过 prefill 和 decode 阶段生成输出。
这些额外阶段显著增加了推理复杂度和平均上下文长度,从而导致计算与内存开销的上升。
1.1 Multimodal Large Language Models Inference
MLLM 的推理流水线可以拆分为三个关键阶段:
- 图像预处理:原图像被缩放或分块;
- 图像编码:视觉编码器提取视觉 token;
- 文本生成阶段:LLM 同时处理视觉与文本 token 并生成响应。
现代 MLLM 的架构可分为两类:
- Decoder-only (DecOnly):如 LLaVA-OneVision、Qwen-VL、Janus、InternVL。视觉与文本 token 拼接后共同输入模型,视觉 token 参与每一步生成;
- Encoder-decoder (EncDec):如 LLaMA-3.2 Vision、NVLM-X、Flamingo。视觉 token 通过 cross-attention 与文本 token 交互,仅在 cross-attention 层中出现。
两者的主要差异在于视觉 token 的交互方式:前者在每一步生成都参与计算,后者仅在交叉注意力阶段出现。 由于视觉 token 的数量通常远大于文本 token,这两种架构都在推理中引入了大量的额外开销,包括更长的上下文、更高的显存使用率和更慢的推理速度。

1.2 LLM Serving Systems
现有 LLM 推理系统(如 vLLM、SGLang)通常采用 KV cache 复用 技术,将推理划分为 prefill 和 decode 两个阶段。
- Prefill 阶段:计算输入 token 的 KV cache 并生成首个输出 token;
- Decode 阶段:每次迭代生成一个新 token。
Prefill 阶段计算负载更重,而 decode 阶段更受限于显存。系统通过连续批处理(continuous batching)和 chunked prefill 等方式提升效率,但 prefill 与 decode 之间的干扰仍难以消除。
近年的工作如 ORCA、LoongServe 尝试通过 prefill-decoding disaggregation 将两个阶段分离到不同 GPU 实例中运行,以提升利用率。然而这些系统在多模态场景下依然存在严重的耦合问题:
- 服务级别耦合:将文本与多模态请求混合处理,无法区分其负载特性;
- 基础设施级别耦合:视觉编码器与语言模型共占 GPU 资源,无法独立扩缩容。
1.3 Research Challenges and Motivations
现有紧耦合架构在多模态任务中面临两个核心问题:
- 服务层问题:文本与多模态请求的计算开销差异巨大。混合处理会导致整体资源利用率下降、TTFT 增加,并容易造成服务级别目标(SLO)违反。
- 体系结构问题:Encoder-decoder 模型引入 cross-attention,无法在混合 batch 中高效运行,导致吞吐下降。
关键洞察 1:需要采用解耦架构,将文本与多模态请求分别处理。 关键洞察 2:静态解耦无法适应动态负载变化,必须实现 弹性(elastic) 资源分配。
因此,作者提出了 Elastic Multimodal Parallelism (EMP) —— 一种结合解耦与弹性资源调度的新范式。
2. Challenge
现有系统采用紧耦合架构,不区分请求类型,也不解耦推理组件,所有阶段都在同一 GPU 上执行。结果是在多模态负载下,TTFT 急剧上升,尤其是当 Encoder-decoder 模型中引入 cross-attention 后,计算异构性进一步加剧,导致批处理效率显著降低。
3. Contribution
为了解决上述问题,论文提出了 Elastic Multimodal Parallelism (EMP),并基于该框架实现了推理系统 ElasticMM。其主要贡献如下:
-
发现瓶颈:明确指出现有系统紧耦合是 MLLM 服务性能瓶颈;
-
提出 EMP 框架:将文本和多模态请求分为独立模态组(modality group),并在组内对不同推理阶段(encoding、prefill、decode)施加阶段级并行策略;
-
设计两项关键技术:
- 模态感知负载均衡(Modality-aware Load Balancing):根据实时负载波动动态调整 GPU 分配;
- 分阶段弹性调度(Elastic Partition Scheduling):针对每个推理阶段独立调整并行度与资源;
-
两项优化:
- 统一多模态前缀缓存(Unified Multimodal Prefix Cache):减少重复编码与数据传输;
- 非阻塞编码(Non-blocking Encoding):异步解耦视觉编码过程;
-
实证结果:相比 vLLM,ElasticMM 在 TTFT 上降低 4.2×,吞吐提升 3.2×–4.5×,同时满足 SLO 要求。
4. Elastic Multimodal Parallelism
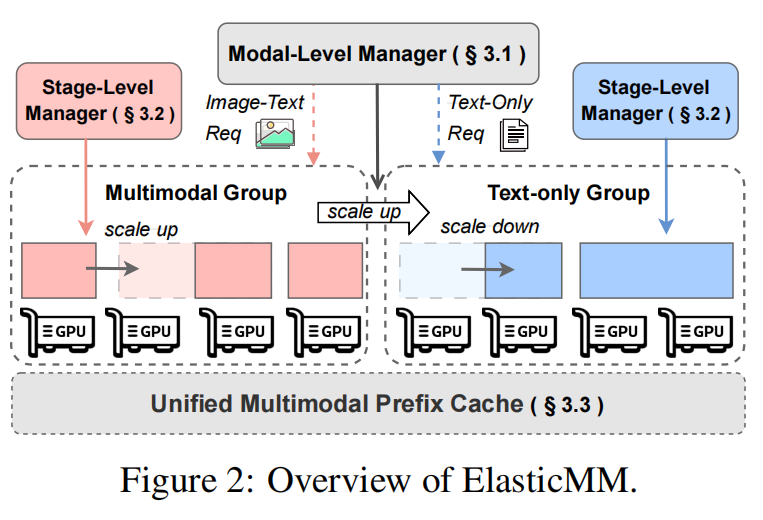
ElasticMM 的核心在于 两层解耦:
- 第一层(模态级):根据请求类型分为文本组与多模态组;
- 第二层(阶段级):进一步拆分为 encoding、prefill、decode 阶段。
在两层上均引入弹性调度机制,避免资源争用、提升利用率。
4.1 Modality-Aware Load Balancing
为解决多模态请求在时间维度上的突发性负载问题,ElasticMM 采用主动 + 被动相结合的调度机制。
主动机制(Proactive Mechanism) 系统分析长期负载模式,发现文本请求稳定而多模态请求呈周期性波动。 因此,在分配 GPU 实例时,优先保证各模态组的“突发容忍度(burst tolerance)”:
$$ bt(i) = \frac{N_i^{peak}}{N_i^{avg}} $$
其中:
- $bt(i)$ 表示第 $i$ 个模态组的突发容忍度;
- $N_i^{peak}$ 表示该模态组在峰值负载时可用的 GPU 实例数;
- $N_i^{avg}$ 表示其平均负载下所需的 GPU 实例数。
系统采用贪心算法,每次将空闲实例分配给当前 burst tolerance 最低的组,直至资源分配完毕。
被动机制(Reactive Scaling) 面对短期突发(如图像流输入激增),系统根据 gain-cost 模型动态扩缩容。如果 inter-group 抢占(从其他组借 GPU)收益更高,管理器将选择影响最小的实例进行抢占,并迁移其 workload 至其他实例继续执行。
4.2 Stage Partition Scheduling
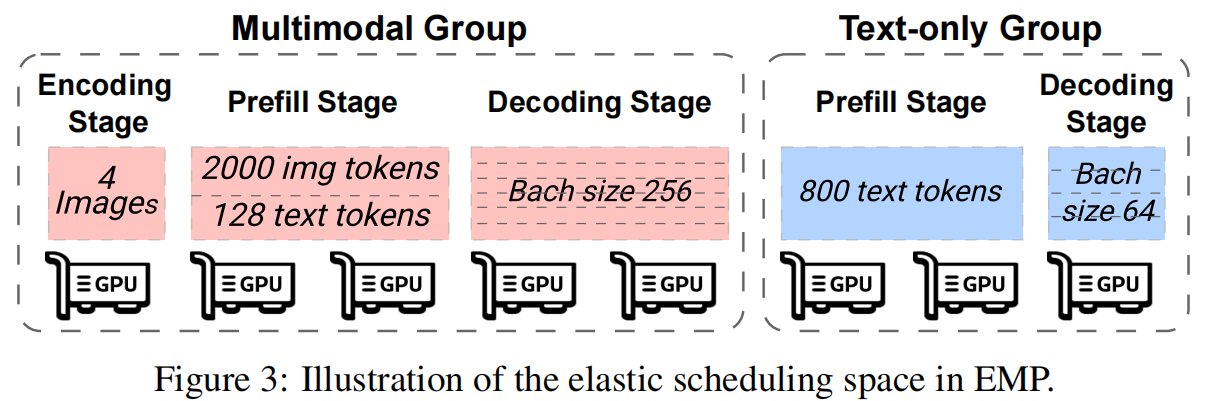
该部分处理模态组内部各阶段(encoding、prefill、decode)的资源调度与伸缩。
Request Dispatching
系统采用 FCFS(先来先服务)策略,但当文本请求与多模态请求绑定时(如同一对话中含图像),优先调度以减少迁移延迟。调度时需同时考虑:
- 显存约束:确保 KV cache slot 充足;
- 计算约束:避免超过 compute-bound tipping point。
Elastic Instance Allocation
Prefill 阶段计算密集,优先分配更多 GPU;若资源不足,则允许从 decode 阶段抢占空闲实例。 系统使用 gain-cost 模型评估抢占收益:
$$ \text{Gain} = \sum_{r\in R_p} \frac{T(R_p, E_p) - T(R_p, E_p \cup e_{max})}{r.input_len} $$ $$ \text{Cost} = \sum_{r\in B_d} \frac{M(e_{max}) + w \cdot L(B_d, E_d - e_{max})}{r.output_len} $$ 当 $\text{Gain}>\text{Cost}$ 时执行抢占。迁移仅移动 KV cache,不移动模型权重。
其中:
- $r$ 表示单个请求;
- $R_p$ 为当前 prefill 阶段的请求集合;
- $B_d$ 为当前 decode 阶段的批次集合;
- $E_p$、$E_d$ 分别为 prefill 和 decode 阶段分配的实例集合;
- $e_{\text{max}}$ 表示拥有最多空闲 KV slot 的候选实例;
- $T(\cdot)$ 表示任务在对应实例集上的执行时间;
- $M(e_{\text{max}})$ 为迁移开销;
- $L(\cdot)$ 表示因抢占造成的性能损失;
- $w$ 为惩罚因子,用于控制抢占的激进程度。
当 $\text{Gain} > \text{Cost}$ 时执行抢占。迁移仅移动 KV cache,不移动模型权重。
Elastic Auto-Scaling
Decode 阶段可扩展性差,当检测到延迟上升或显存不足时触发伸缩。若组内资源不足,则跨组抢占:
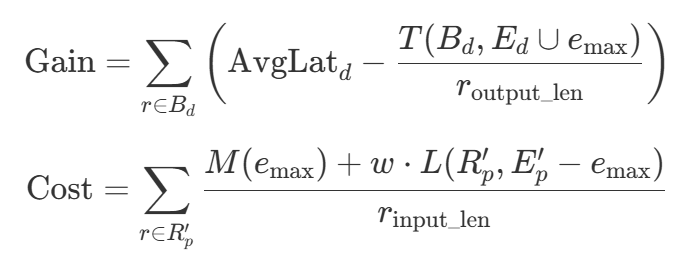
解释: 系统通过比较 $\text{Gain}$ 与 $\text{Cost}$ 判断是否执行跨组伸缩:
- 当 $\text{Gain} > \text{Cost}$ 时,表示将 GPU 实例从 prefill 组迁移到 decode 组能够带来更高整体收益,系统触发跨组扩展;
- 否则维持现有分配,避免抢占导致的性能震荡。
通过离线 profiling 设定伸缩阈值,系统可根据 decode 阶段瓶颈自动调节资源,实现精细化动态弹性。
4.3 Multimodal Inference Optimization
Unified Multimodal Prefix Cache
ElasticMM 通过统一缓存机制减少重复计算:
-
缓存池 1:视觉特征缓存池(CV pool),存储图像哈希与对应视觉 token;
-
缓存池 2:前缀缓存池(Prefix pool),存储已生成的 KV cache 片段;
-
工作流程:
- 对输入图像生成哈希;
- 若命中缓存,则直接复用视觉 token;
- 查找前缀树以匹配最长已缓存前缀,跳过重复 prefill;
- 两池均采用 LRU 策略控制显存。
Non-blocking Encoding
由于图像编码耗时通常为 prefill 的数倍,传统系统中 encoding 与 prefill 串行执行造成阻塞。ElasticMM 将 encoding 分离为异步进程或独立实例,与语言模型部分并行执行。结合统一缓存机制,可显著减少阻塞并降低 TTFT。
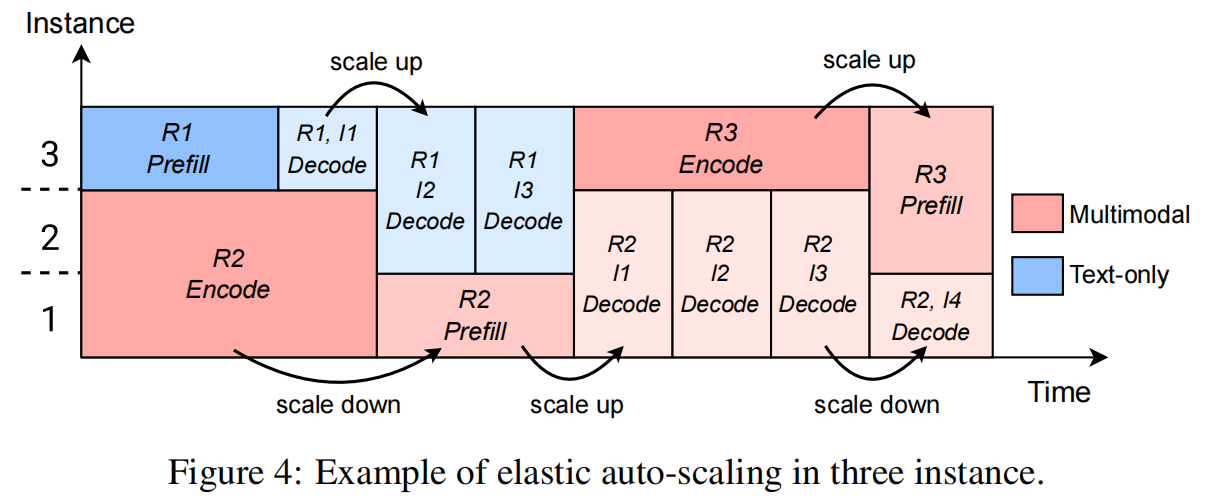
5. Evaluation
5.1 Experimental Setup
-
硬件环境:8 × NVIDIA A800 80GB GPU,2 × Intel Xeon 8358P(64核),2TB 内存,NVLink 带宽 400GB/s;
-
对比基线:
- vLLM (coupled):原始架构;
- vLLM-Decouple:静态解耦版本;
- ElasticMM:启用 EMP 与两项优化;
-
模型与数据集:
- 模型:Qwen2.5-VL、LLaMA3.2-Vision;
- 数据集:ShareGPT-4o、COCO Caption;
-
指标:TTFT、吞吐量、SLO 满足率。
5.2 End-to-End Performance
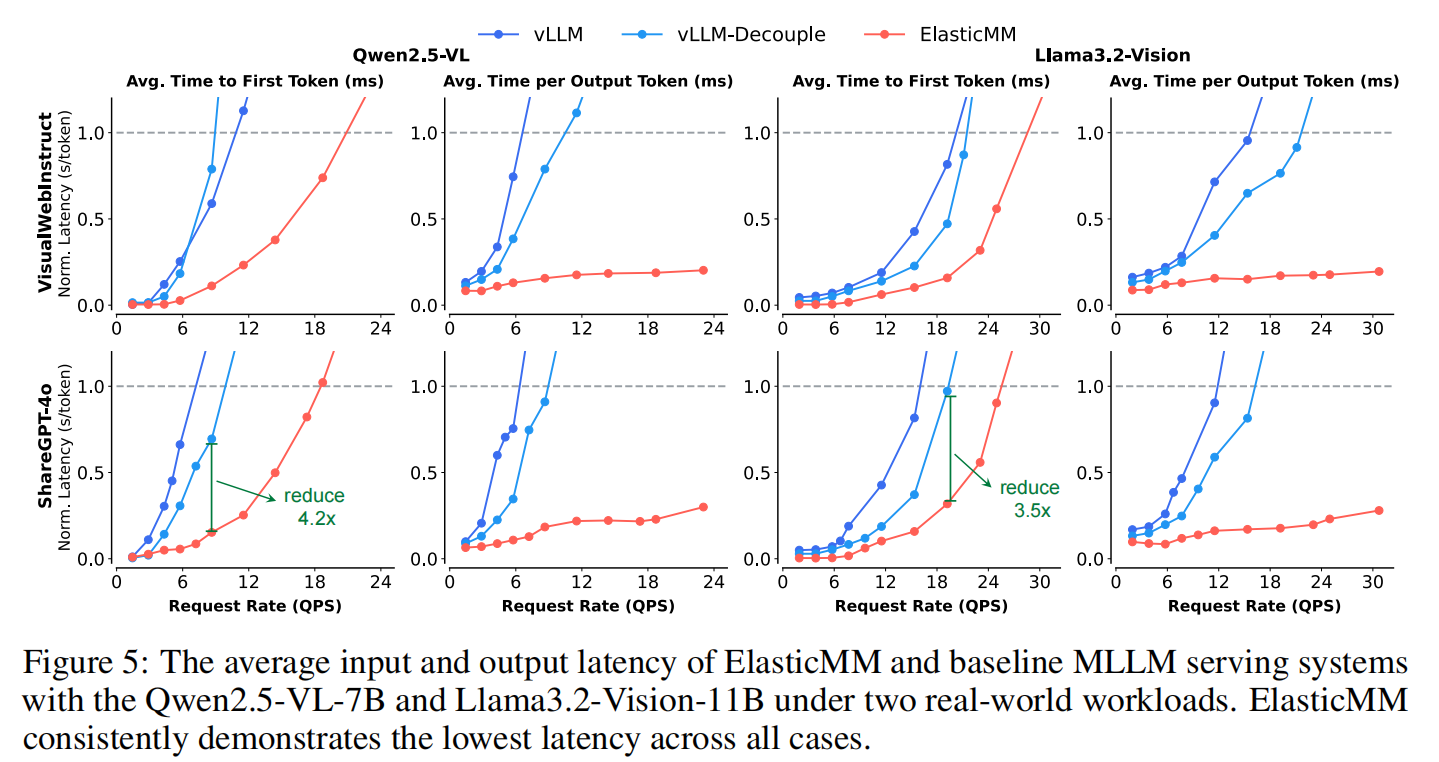
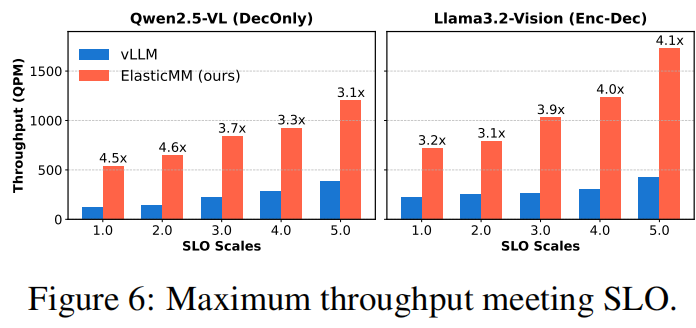
结果显示:
- 在多模态请求比例较高的负载下,ElasticMM 相比 vLLM 将 TTFT 降低最高 4.2×;
- 平均吞吐量提升 3.2×–4.5×;
- 在混合场景中依然保持较高的 GPU 利用率与稳定的 SLO 满足率。
5.3 Ablation Study
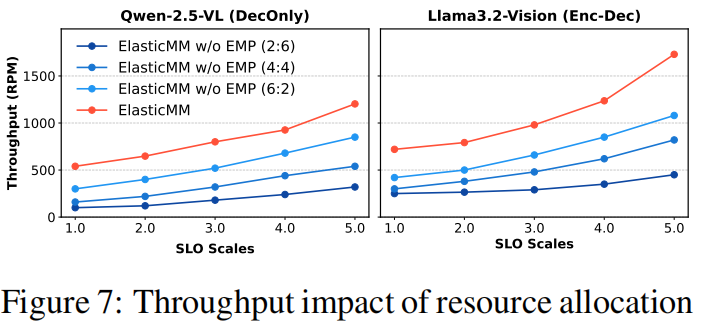
EMP 有效性
对比三种静态资源分配策略(文本优先 / 平均分配 / 多模态优先),ElasticMM 动态分配的策略表现最优,吞吐量分别提升:
- Qwen2.5-VL:1.8×;
- LLaMA3.2-Vision:2.3×。
MLLM 优化模块有效性
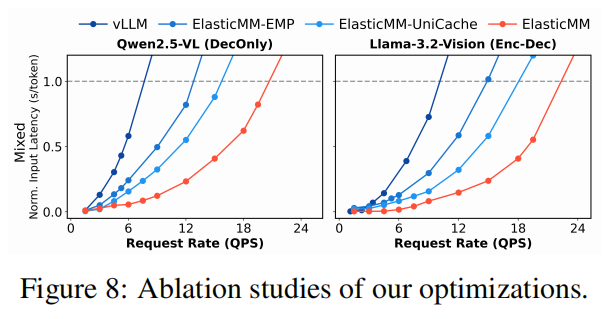
对比以下系统:
- ElasticMM-EMP:无缓存优化;
- ElasticMM-UniCache:仅启用缓存;
- ElasticMM:完整系统。
结果表明:
- 统一前缀缓存显著减少重复计算,降低输入 token 延迟;
- 非阻塞编码进一步减少编码阻塞,使平均 TTFT 下降 50%;
- 两者结合后在高负载下仍保持稳定吞吐。
6. Related Work
现有 MLLM 推理优化多聚焦于模型结构简化(TinyGPT-V、TinyLLaVA)、视觉 token 剪枝(Dynamic-LLaVA、VTM)或 KV cache 压缩(InfMLLM、Elastic Cache),通常以牺牲精度换取速度。 ElasticMM 不涉及模型精度变化,可兼容任意 MLLM 架构。 与 Splitwise、DistServe 等静态分片方案不同,ElasticMM 在模态与阶段上实现动态弹性调度,性能提升更显著。
7. Conclusion
本文提出了 ElasticMM —— 基于 Elastic Multimodal Parallelism (EMP) 的多模态大语言模型推理系统,通过模态级与阶段级的双层解耦与弹性伸缩,实现了对动态多模态负载的高效服务。
ElasticMM 的三项核心创新:
- 模态感知负载均衡;
- 分阶段弹性调度;
- 多模态特定优化(统一缓存与非阻塞编码);
在真实数据集实验中,ElasticMM 相比 vLLM 实现最高 4.2× 的 TTFT 降低 与 4.5× 的吞吐提升。