
1. Abstract
在资源受限的环境中部署视觉语言模型 (VLMs) 要求低延迟和高吞吐量。然而,现有的轻量级 (Compact) VLMs 往往无法达到其参数量缩减所应带来的推理加速。为了解释这一现象,作者进行了端到端的效率分析,并系统地剖析了推理过程以识别主要瓶颈。
基于这些发现,作者为轻量级 VLMs 量身定制了一系列优化方案 (Recipes),在保持准确性的同时大幅降低了延迟。这些技术将 InternVL3-2B 的首字生成时间 (Time To First Token, TTFT) 降低了 53%,在 SmolVLM-256M 上降低了 93%。作者的优化方案广泛适用于各种 VLM 架构和主流服务框架。
此外,作者研究了如何扩展轻量级 VLM 以支持结构化感知输出,并推出了 ARGUSVLM 模型系列。ARGUSVLM 在多个基准测试中表现强劲,同时保持了紧凑且高效的设计。
2. Introduction
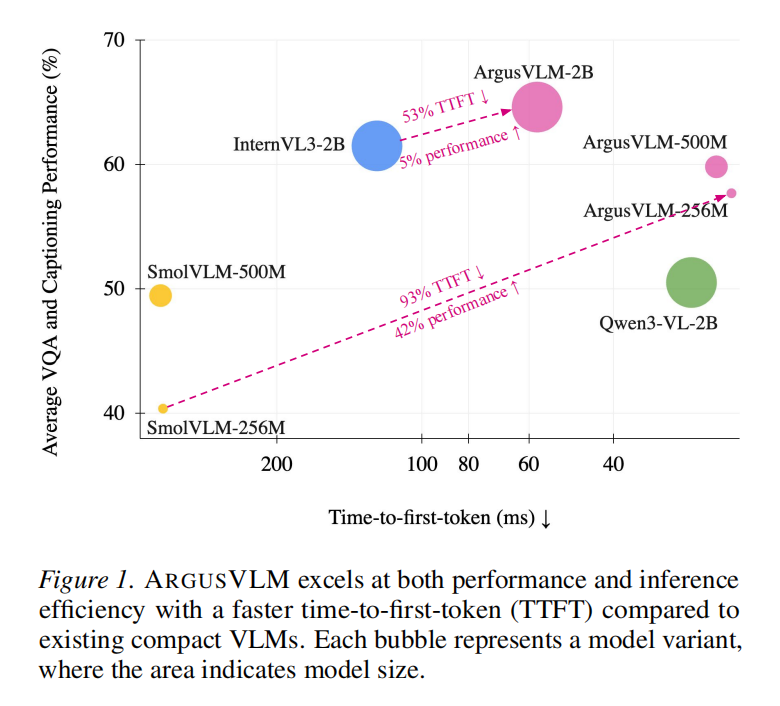
尽管紧凑型模型参数量更小,但它们在端到端效率上的表现往往不如预期。例如,SmolVLM-256M 的参数量远小于 InternVL3-8B,但其 TTFT (344.7 ms) 却比后者 (177.4 ms) 更长。
通过系统性分析,作者发现:在轻量级模型中,以往被忽视的 CPU 端操作(如图像预处理、文本分词)往往主导了整体延迟。相比之下,得益于 FlashAttention、CUDA Graphs 和算子融合 (Kernel Fusion) 等技术,GPU 端的计算占比反而较低。
本研究通过针对性的 CPU 端优化,将 InternVL3-2B 的 TTFT 从 124.0 ms 降至 57.7 ms,将 SmolVLM-256M 的 TTFT 从 344.7 ms 降至 22.8 ms (如图 1 所示)。
3. Contribution
作者的贡献主要分为三个方面:
- 系统性分析:对紧凑型 VLM 进行了端到端的 Profiling 研究,揭示了主要延迟瓶颈并提供了实际部署指南。
- ARGUSVLM 模型系列:开发了参数量覆盖 256M 到 2B 的模型系列,并对边界框 (Bounding-box) 预测公式进行了受控研究,以统一结构化视觉感知与多模态理解。
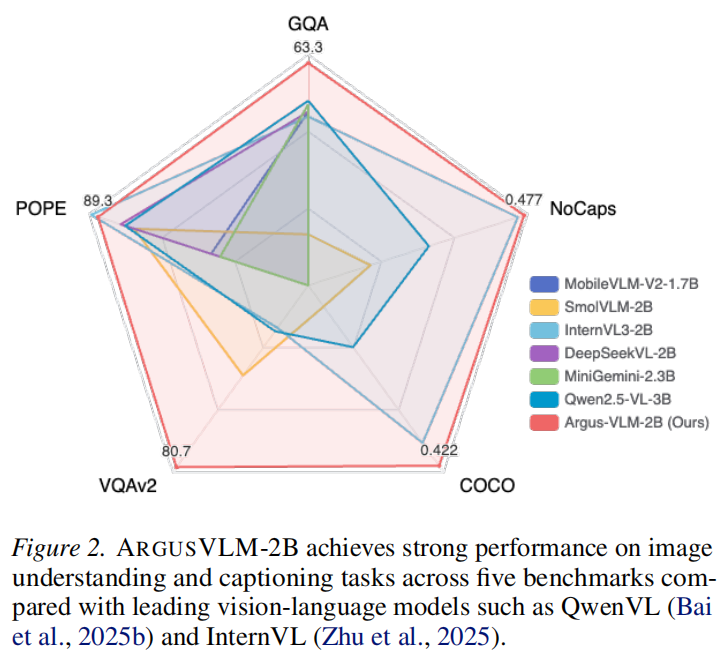
- 卓越性能与效率:ARGUSVLM 在 VQA、图像描述及密集图像描述任务上表现出色,且在延迟和吞吐量上远优达标 (如图 2)。
4. Recipes to Improve Inference Efficiency
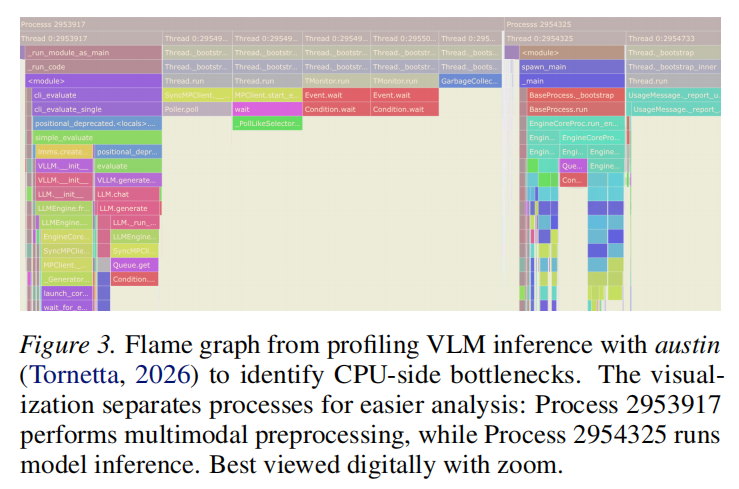

作者基于 vLLM 推理框架构建并识别优化路径。
3.1. Inference Computation Profiling (推理计算剖析)
Profiler 工具选择:
- CPU 端: 推荐使用 austin。相比 cProfile,它的开销更低;相比 py-spy,它对 vLLM 这种多进程应用的支持更好,能有效生成火焰图 (Flame Graphs) 识别热点。
- GPU 端: 使用 NVIDIA Nsight Systems,用于诊断内核计时、内存传输及量化性能。
关键发现:
- 量化在紧凑型模型上可能失效:
在 H100 上对 ARGUSVLM-256M 进行 FP8 W8A8 量化测试发现,量化模型的吞吐量反而比 bfloat16 低 6.4% (499.08 vs 533.28 tokens/s)。
- 原因分析:虽然量化矩阵乘法 (GEMM) 快了 1.1 倍,但激活量化 (Activation Quantization) 引入了显著的额外开销 (+5.50µs),即便已融合进 LayerNorm 或 Silu 内核,该开销仍抵消了计算收益。
- CPU 操作是主要瓶颈: 由于 GPU 端已经高度优化(FlashAttention, CUDA Graphs),GPU 执行时间已接近饱和。在轻量级模型中,CPU 端的任务(如图像解码、Tokenization)由于无法并行且涉及频繁的 Host-to-Device (H2D) 通信,成为了 TTFT 的核心瓶颈。
3.2. Case Studies & 3.3. Practical Recipes
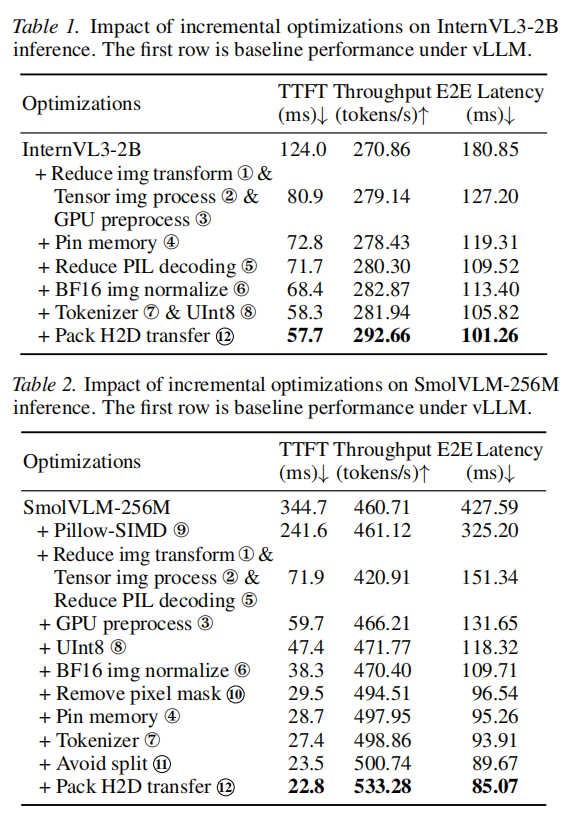
通过对 InternVL3-2B 和 SmolVLM-256M 的案例研究,作者提炼出以下实用优化方案:
A. 最小化关键路径上的图像处理 (Minimize image processing)
- 避免重复操作:减少重复的图像编解码、缩放 (Resizing)、裁剪 (Cropping) 和填充 (Padding)。
- 使用高效库:使用 Pillow-SIMD 替代原生 Pillow 进行图像解码,使用 torchvision 处理转换操作。
- GPU 卸载:尽可能将 Resize 和 Normalize 等预处理步骤从 CPU 转移到 GPU 执行。
- 简化逻辑:去除不必要的图像处理冗余步骤。
B. 减少 CPU-GPU 通信 (Reduce CPU-GPU communication)
- 传输更小的数据类型:传输
UInt8格式的图像而非Float32,在 GPU 设备端再进行类型转换。 - 使用固定内存 (Pinned Memory):利用 Page-locked 内存加速 H2D 传输。
- 合并传输:将多个小的 H2D 传输合并为一个大传输。
C. 优化 Tokenization (分词优化)
- 简化占位符:VLM 通常使用大量重复的图像 Token 占位符(如
<IMG_CONTEXT>),导致 Prompt 极长,显著拖慢分词速度。采用更紧凑的占位符方案可显著提升 TTFT。
D. 策略顺序
- 先剖析,后优化:先用工具定位真实瓶颈,避免过早优化不重要的部分。
5. Recipes for Building Compact VLMs (模型构建方法详解)
本节详细介绍了 ARGUSVLM 的架构设计及如何实现细粒度的结构化感知。
5.1. Model Architecture (模型架构)
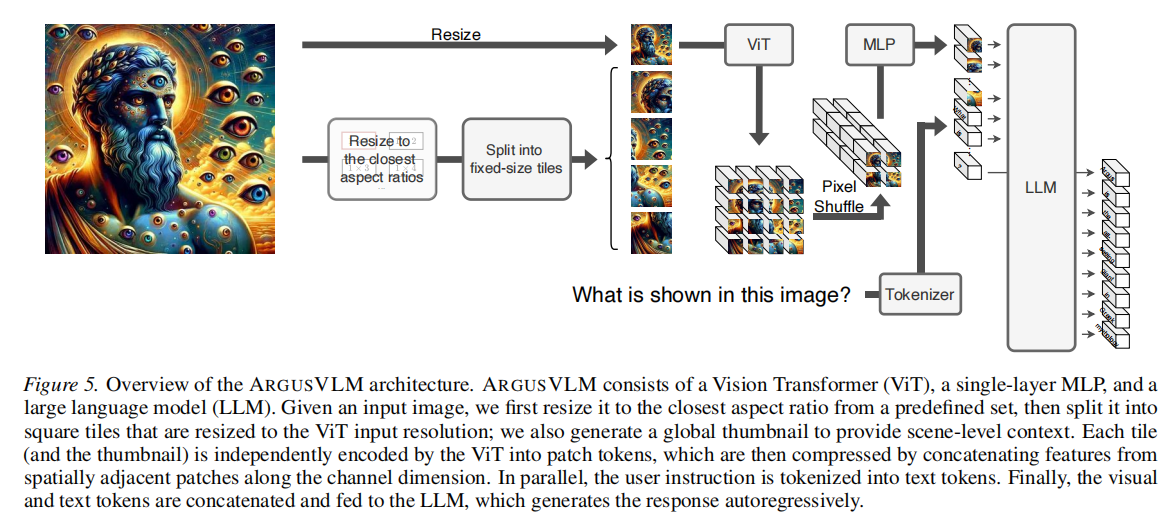
ARGUSVLM 采用标准的 Encoder-Projector-LLM 架构:
- Vision Encoder: 采用 SigLIP-SO400M,能够处理多尺度输入。
- Language Model:
- ARGUSVLM-256M: 基于 SmolLM2-135M。
- ARGUSVLM-2B: 基于 Qwen2.5-1.5B。
- Projector: 简单的 MLP 映射层,将视觉特征对齐到文本空间。
5.2. Structured Perception (结构化感知与边界框预测)
为了让轻量级 VLM 具备检测目标位置的能力,论文研究了三种边界框 ($[x_{min}, y_{min}, x_{max}, y_{max}]$) 的表征方法:
- Float-based (基于浮点数): 直接预测归一化后的浮点数坐标。虽然直观,但与 LLM 的离散 Token 预测本质冲突。
- Bin-based (基于分箱): 将连续坐标映射为离散的整数索引(如 0-999)。 $$\text{bin}_x = \lfloor x \times (N-1) \rfloor$$ 其中 $N$ 是分箱数量。这种方法能很好地适配 LLM 的分类损失函数。
- Codebook-based (基于代码本): 使用类似于 VQ-VAE 的量化方法,从预定义的代码本中选择代表坐标的 Token。
结论:实验表明,对于紧凑型模型,Bin-based 表征在收敛速度和定位精度上表现最佳,因为它利用了 LLM 已有的预测头结构,同时提供了足够的空间分辨率。
5.3. Training Stages (训练阶段)
- Stage 1: Pre-training: 在大规模图像-文本对上训练,重点在于视觉特征与文本语义的对齐。
- Stage 2: Instruction Fine-tuning: 引入混合指令数据集,包括通用 VQA、Dense Captioning 和基于坐标的任务。
6. Evaluation (实验评估)
作者对推理效率和模型能力进行了全面评估。
6.1. Efficiency Evaluation (效率评估)
测试环境:单张 NVIDIA H100 GPU,vLLM 推理后端。
- 延迟对比 (Table 1 & 2):
- InternVL3-2B: 优化后 TTFT 降低 53% (124ms -> 57.7ms),端到端延迟降低 44%。
- SmolVLM-256M: 优化后 TTFT 降低 93% (344.7ms -> 22.8ms),端到端延迟降低 80%。
- 吞吐量 (Throughput): ARGUSVLM 在处理高并发请求时表现出显著优势。在相同的硬件条件下,由于 CPU 开销的移除,ARGUSVLM 的总吞吐量比原始实现的紧凑型 VLM 提升了数倍。
6.2. Benchmarking Model Capability (模型能力基准)
ARGUSVLM 在多个主流榜单上进行了测试:
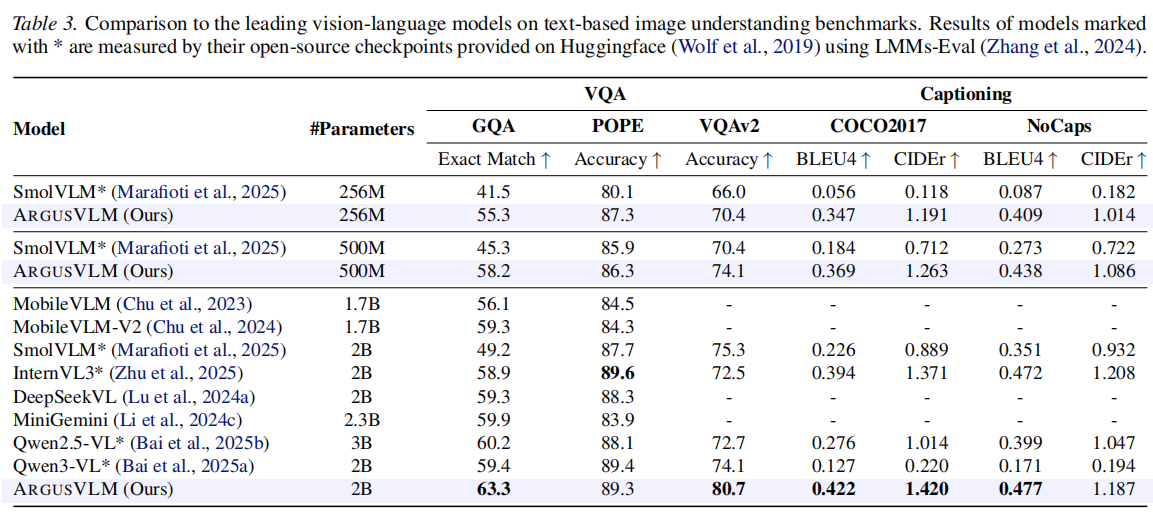
-
常规 VQA 基准 (Table 3): 评估包括 MMBench, SEED-Bench, ScienceQA 等。
- ARGUSVLM-2B 在多个任务上超越了同尺寸的 InternVL2-2B 和 Qwen2-VL-2B。
- ARGUSVLM-256M 尽管参数量极小,但在文本识别和基础推理任务上展现了极高的效率比。
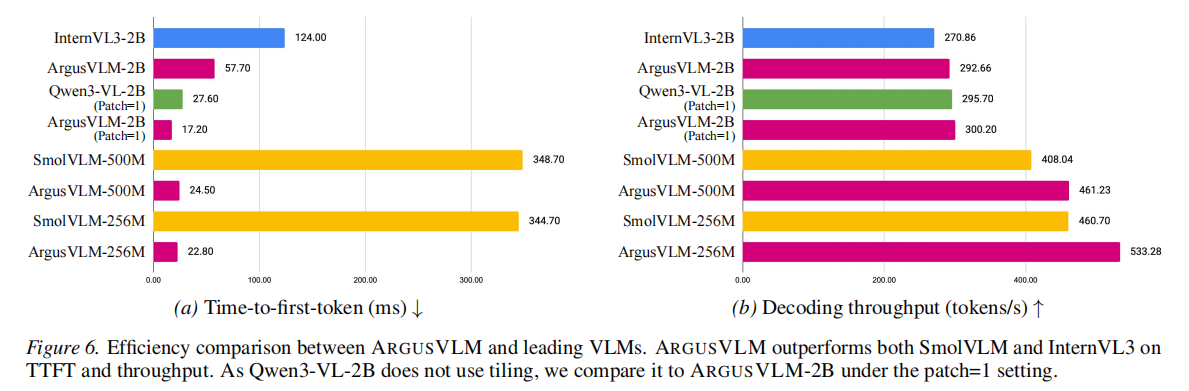
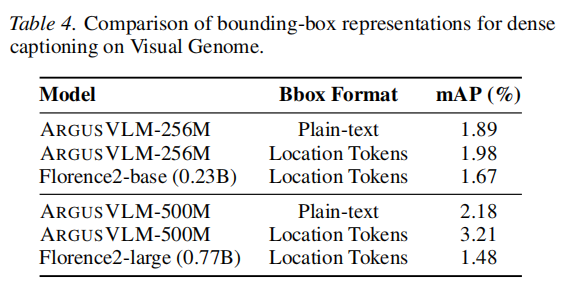
-
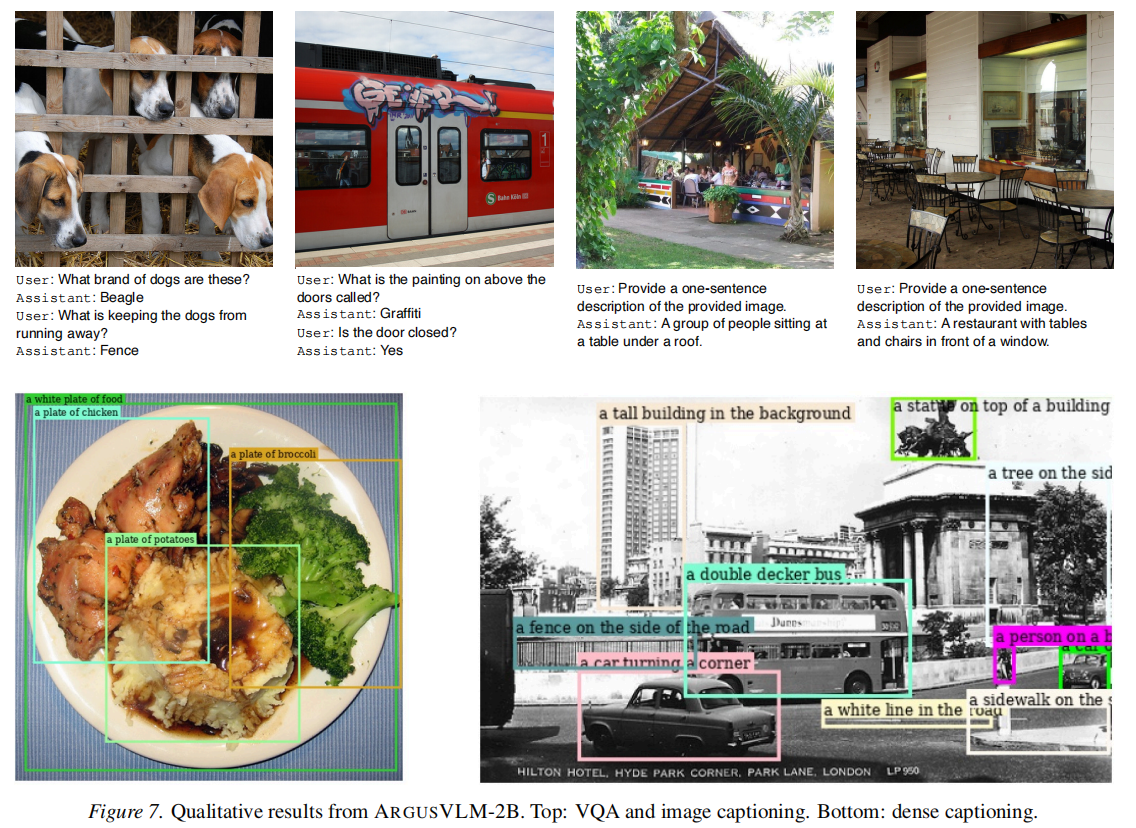
密集感知任务 (Figure 6 & Table 4): 针对边界框预测任务(Visual Grounding & Dense Captioning):
- ARGUSVLM 能够准确生成目标物体的坐标 Token。
- Figure 6 展示了其在复杂场景下的定位能力,不仅能描述物体,还能给出精确的空间范围。
6.3. Quantization vs. FP16 (Figure 4 & 7)
- 图 4 (GPU Timeline): 通过 Nsight 剖析展示了 FP8 量化带来的 Kernel 执行间隙。可以观察到,虽然算子本身变快了,但算子前后的 Data Conversion (bfloat16 $\leftrightarrow$ FP8) 消耗了大量时间,导致 GPU 存在明显的空闲等待。
- 图 7 (Scaling Laws): 研究了模型尺寸与精度之间的平衡,证明了通过优化推理方案,256M 级别的模型可以在极低延迟下达到可用的精度标准。
7. Conclusion
作者推出了 ARGUSVLM,这是一个紧凑且高效的视觉语言模型系列,成功统一了文本视觉理解与精细化感知。
通过对紧凑型 VLM 推理过程的端到端剖析,作者识别了关键的实现瓶颈,并提出了针对性的优化方案,在不损失准确性的前提下显著降低了延迟。为了扩展紧凑型模型的结构化感知能力,作者深入研究了在下次 Token 预测目标下,学习空间定位输出(如边界框)的有效公式。
大量实验证明,ARGUSVLM 在保持轻量化的同时性能强劲,且推理速度远超现有的同类模型。总之,作者的研究为构建高效且强大的视觉语言系统提供了实用的经验指导和实证证据。