
Conference: Eurosys'25
1. Motivation
尽管 LMMs (Large Multimodal Models) 在通用视觉任务上表现出色,但在应用于需要领域特定知识 (Domain-specific knowledge) 的实际场景时,其表现往往不如人意,类似于早期 LLM 的幻觉问题。
虽然 RAG (Retrieval-Augmented Generation) 是 LLM 中常用的补充知识的方法,但对于时间敏感的视觉应用 (Time-sensitive vision applications) 来说并不适用:
- RAG 的检索过程和附加的长上下文请求会导致超过 10 倍的响应延迟。
- 相比之下,LoRA (Low-Rank Adaptation) 提供了一种更有前景的方案。它通过在运行时将微调后的 Adapter 合并到 LMM 中,能够高效地生成高质量且一致的领域特定响应,且没有额外的推理开销。
然而,现有的 LoRA 服务系统(如 Punica, S-LoRA, dLoRA)主要针对纯文本 LLM 优化,无法满足视觉应用的高效性和多样化需求:
- Unmerged Inference (不合并推理):为了支持多 Adapter 并行,现有系统通常采用不合并推理模式。虽然这解决了并发问题,但额外引入的计算开销导致了极高的延迟。
- Vision Workloads (视觉负载):视觉任务通常包含大量的视觉 Token 处理,对计算资源的消耗与纯文本不同,现有系统的 Batching 策略效率低下。
Research Question: 我们能否利用 LoRA LMM 来丰富视觉应用,同时满足其严格的性能要求? 作者认为答案是肯定的,但必须解决 Capacity、Batching Efficiency 和 Orchestration Flexibility 三大挑战。
2. Contribution
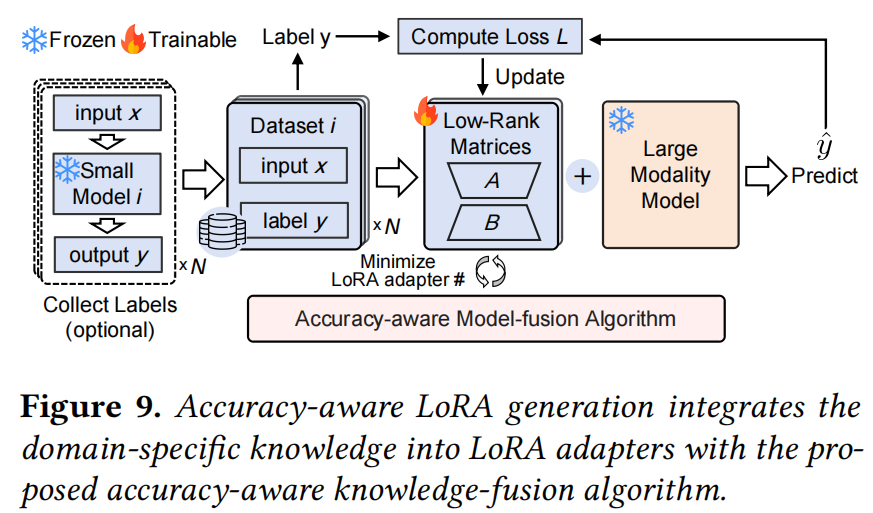
本文提出了 VaLoRA,这是一个端到端的 LoRA LMM 服务系统,包含 LoRA Adapter 的准备阶段 (§4.2) 和推理运行时 (§4.3, §4.4)。VaLoRA 通过以下核心技术解决了上述挑战:
-
Accuracy-aware LoRA Adapter Generation (精度感知的 LoRA Adapter 生成):
- 提出了一种 LoRA 生成器,旨在生成富含领域特定知识的 Adapter,以满足特定应用的精度要求。
- 将 LoRA 生成问题建模为约束装箱问题 (Constrained Bin Packing Problem):给定外部知识(如小模型或特定数据集),目标是生成最少数量的 LoRA Adapters,同时保证满足视觉应用的精度要求。
- 设计了一种贪婪启发式算法 (Greedy heuristic algorithm) 来解决这一问题。此外,引入了 Vision Task Head (视觉任务头) 作为 LoRA Adapter 的一部分,显著降低了视觉任务的响应延迟。
-
Adaptive-tiling LoRA Adapters Batching (自适应分块 LoRA Adapter 批处理):
- 提出了一种并发 LoRA Adapters 批处理方法,核心是 ATMM (Adaptive-Tiling Matrix Multiplication) 算子及其最优分块搜索算法。
- Offline Phase: 搜索算法识别每个可能的输入矩阵形状的最佳分块配置 (Tiling configurations),建立哈希表存储这些“输入-最优分块”对,并预编译代码实现。
- Runtime: ATMM 根据并发请求和调用的 LoRA Adapters 的输入形状,自适应地从哈希表中选择最佳分块配置,并以极高的效率执行相应的代码实现。
-
Flexible LoRA Adapters Orchestration (灵活的 LoRA Adapter 编排):
- 针对视觉应用的多样化需求,提出了一个编排器 (Orchestrator),在运行时高效、灵活地调度 LoRA Adapters。
- 开发了两个工具:
- Switcher: 利用 ATMM 和统一内存管理,实现快速的推理模式切换 (Merge/Unmerge) 和 LoRA Adapter 交换 (Swap)。
- Mixture Inference Mode (deLoRA): 一种混合推理模式,缓解请求饥饿 (Starvation) 问题。
- 设计了一种调度算法,在三种推理模式之间动态切换,调度请求并管理 Adapters,以实现最低的平均响应延迟。
3. Challenges
为了利用 LoRA LMM 赋能视觉应用,系统必须克服以下三个主要挑战:
-
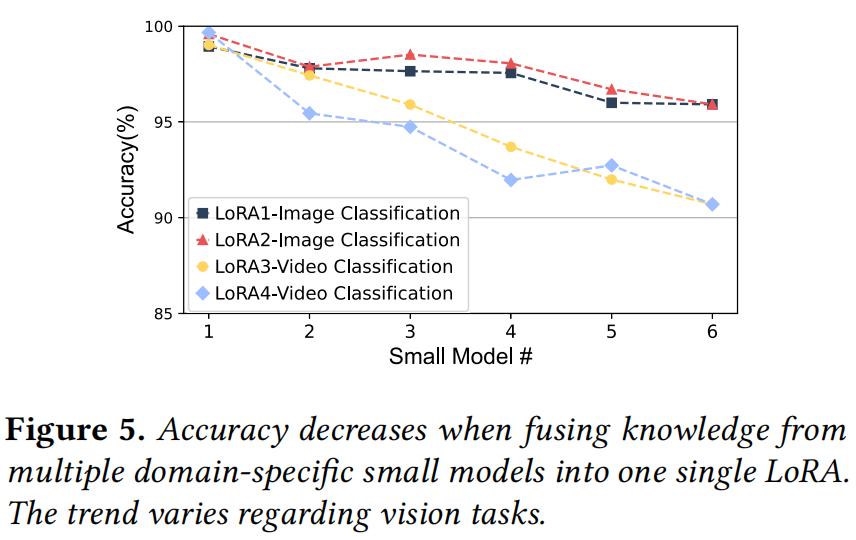
C1: Limited capacity of LoRA adapter (LoRA Adapter 的容量限制) 虽然将领域知识(如现有的小模型或特定数据集)集成到 LMM 中是必要的,但 LoRA Adapter 的容量有限。如图 5 所示,简单地为每个任务训练一个 Adapter 是不经济的;而试图将过多的外部知识(如多个小模型)融合到单个 Adapter 中,会导致不可避免的精度下降。如何在“Adapter 数量”和“任务精度”之间找到平衡点是一个难题。
-
C2: Inefficient concurrent requests batching (低效的并发请求批处理)
一个视觉应用通常涉及多个小模型,这意味着服务多个应用时,极有可能需要同时调用多个异构的 LoRA Adapters。
现有的 LoRA 推理系统(如 Punica, S-LoRA, dLoRA)在处理高并发异构 Adapter 时效率低下。
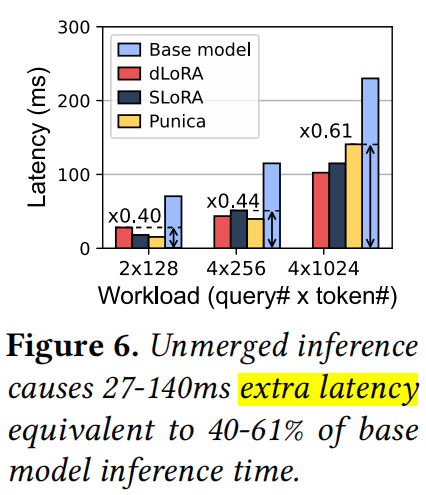
* **Unmerged Inference Overhead:** 如图 6 所示,Unmerged 推理模式引入了额外的矩阵乘法和加法,导致高达 140ms 的额外延迟。
* **Hardware Underutilization:** 现有的 Batching 算子由于存在大量的 Padding(填充)或采用了不合理的矩阵分块 (Matrix Tiling) 策略,无法充分利用 GPU 计算单元。
- C3: Inflexible LoRA adapters orchestration (不灵活的 LoRA Adapter 编排)
不同的视觉应用有截然不同的性能需求(例如,视频分析需要低延迟,视觉检索偏好高吞吐)。
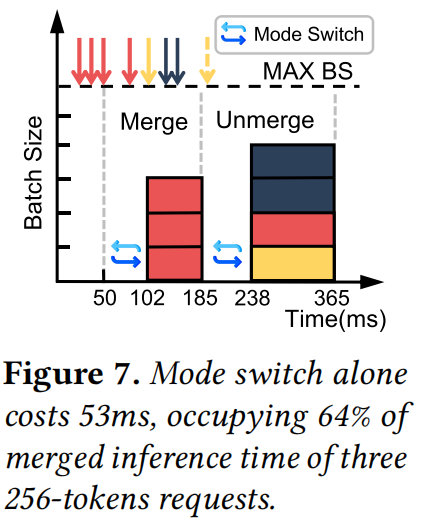
现有的编排器(如 dLoRA)虽然支持模式切换,但开销巨大。如图 7 所示,仅模式切换就可能耗时 **53ms**,这主要是由于低效的内存管理导致的 LoRA 矩阵拷贝,以及通过 PyTorch `addmm` 调用计算 LoRA 权重 $\Delta W$ 的巨大开销。这导致了服务请求的长时间等待(Starvation)。
4. VaLoRA Design
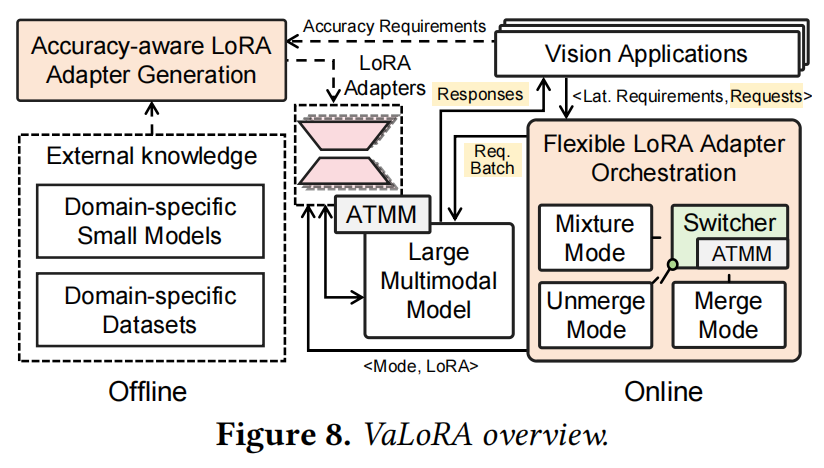
VaLoRA 是一个端到端系统,设计包含离线 (Offline) 和在线 (Online) 两个阶段,如图 8 所示。
4.2 Accuracy-aware LoRA Adapter Generation (离线阶段)
该阶段的目标是利用外部知识生成最少数量的 LoRA Adapters,同时确保每个 Adapter 都能满足视觉应用指定的精度要求。
4.2.1 Accuracy-aware knowledge-fusion algorithm (精度感知知识融合算法)
这是一个约束装箱问题 (Constrained Bin Packing Problem) 的变体。由于寻找最优解是 NP-hard 的,且不存在能预知任意知识组合后精度的 Oracle,作者设计了一种基于贪婪启发式 (Greedy Heuristic) 的算法:
- Dataset Collection: 收集领域特定小模型的训练数据(Label 由小模型生成或直接使用原数据集)。
- Greedy Fusion: 算法从一个空的 LoRA Adapter 开始,按顺序尝试融合每一个领域的数据集(Knowledge)。
- Training & Validation: 使用交叉熵损失 $L=CE(y, \hat{y})$ 进行训练。每融合一个新数据集,就在该 Adapter 负责的所有任务上验证精度。
- Rollback & Split: 如果融合某个数据集导致 Adapter 在任一先前任务上的精度低于阈值,则回滚 (Rollback) 权重,并在前一个状态结束该 Adapter 的生成(封箱)。然后初始化一个新的 Adapter 继续尝试融合当前数据集。
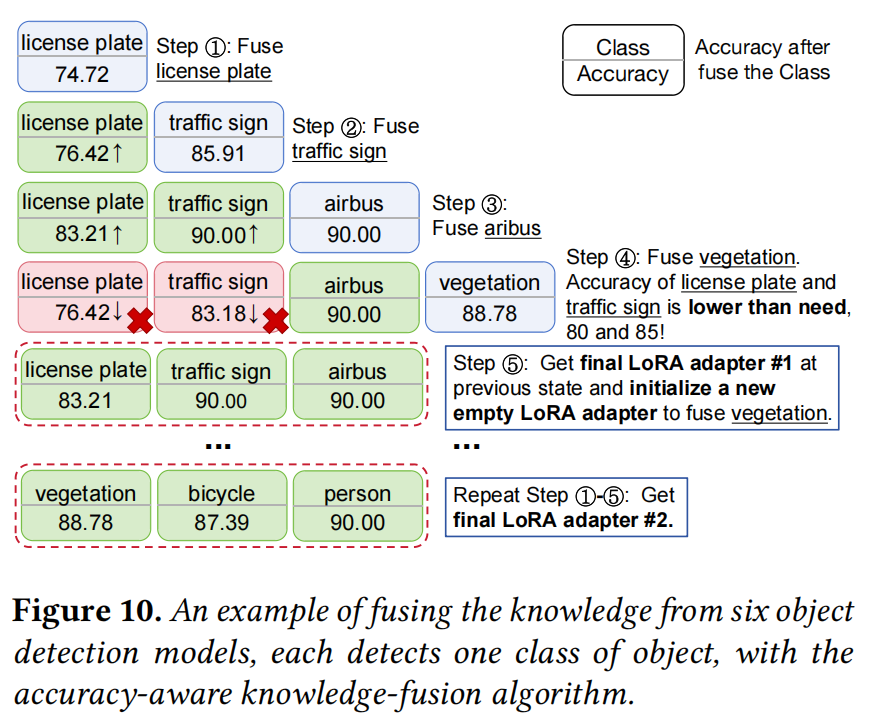
例如: 如图 10,当 Adapter 1 试图融合 “vegetation” 任务时,导致 “license plate” 的精度降至 80% 以下(违背要求),算法会回滚并完成 Adapter 1,然后创建 Adapter 2 来承载 “vegetation” 及其后续任务。
4.2.2 Vision task head (视觉任务头)
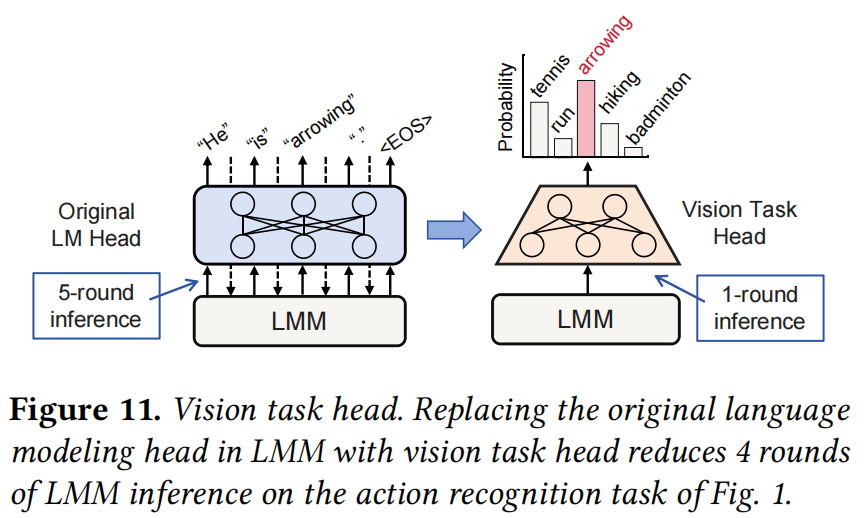
为了降低推理延迟,VaLoRA 将 LMM 原有的语言建模头 (LM Head) 替换为 Vision Task Head。
- Structure: 这是一个作为 LoRA Adapter 一部分的可训练线性层 (Linear Layer)。
- Benefit: 许多视觉任务(如动作识别、计数)的输出是有限的离散集合。使用 Vision Task Head 可以避免 LLM 昂贵的自回归生成过程(逐 Token 生成)。如图 11 所示,它可以将原本需要 5 轮推理的过程缩减为 1 轮,节省约 180ms。
- Coexistence: 对于需要自然语言接口的任务(如 VQA),系统仍保留 LM Head。得益于 ATMM 算子,不同类型的 Head 可以并发执行。
4.3 Adaptive-tiling LoRA Adapters Batching (在线运行时 - 核心算子)
为了高效处理并发的异构 LoRA Adapters,VaLoRA 提出了 ATMM (Adaptive-Tiling Matrix Multiplication) 算子。
4.3.1 ATMM Operator (自适应分块矩阵乘法算子)
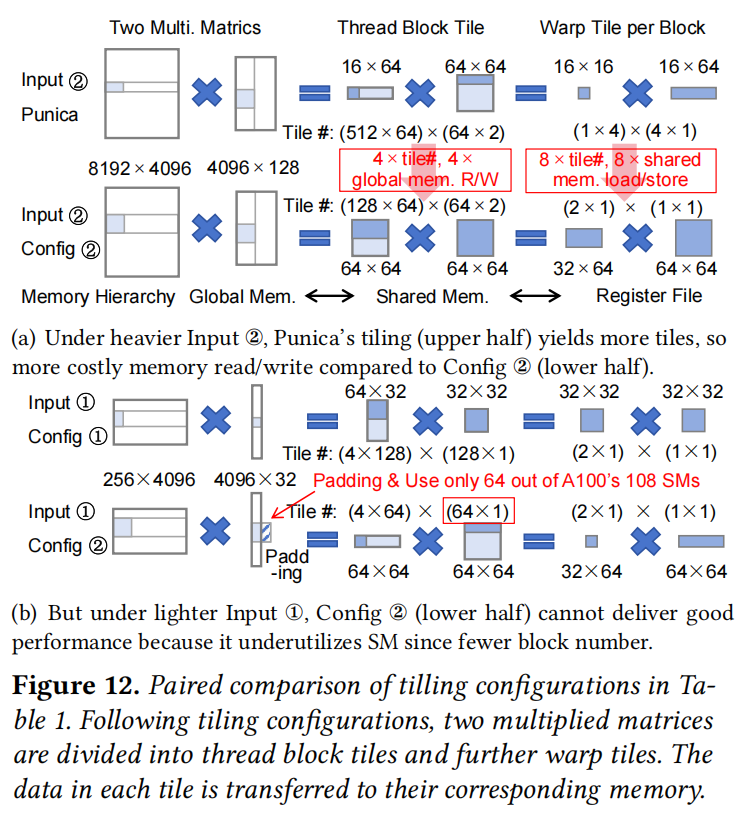
传统的 Batched GEMM 需要将异构矩阵填充 (Pad) 到统一形状,导致计算浪费;而 S-LoRA 和 Punica 的自定义 Kernel 使用静态分块 (Static Tiling),无法适应多变的输入形状,导致 GPU 利用率低或显存访问频繁(见图 12)。
ATMM 的核心设计:
- Adaptive Tiling (自适应分块): 针对每一个具体的输入矩阵形状 $(M, K, N)$,ATMM 会动态选择最优的分块策略(Tile Shape)。它将矩阵划分为 Thread Block Tiles,再细分为 Warp Tiles。
- Pipeline Data Loading & Double Buffering:
- 为了掩盖数据加载延迟,ATMM 在 Shared Memory 和 Register File 中分配了双倍空间 (Double Buffering)。
- 一组 Buffer 用于当前 Tile 的计算,另一组用于预取 (Prefetch) 下一个 Tile 的数据。这是一种纯 Cache 策略,不增加显存开销。
4.3.2 Profile-based optimal tiling search (基于分析的最优分块搜索)
为了支持运行时的自适应分块,VaLoRA 在离线阶段进行搜索:
- Search Space Reduction: 利用硬件限制(Shared Memory 大小)和模型特征(LMM 维度通常是 64 或 128 的倍数)将搜索空间缩小 20 倍。
- Profiling: 使用 CUTLASS Profiler 遍历所有可能的输入形状,测量不同分块配置的执行时间。
- Compilation: 将每个输入形状对应的最优分块配置存储在哈希表中,并将对应的 Kernel 代码预编译为可执行文件。
- Runtime Mapping: 运行时,ATMM 直接根据输入形状查表并调用对应的 Kernel,几乎无额外开销。
4.4 Flexible LoRA Adapters Orchestration (在线运行时 - 编排与调度)
VaLoRA 的编排器旨在满足不同应用的延迟需求。
4.4.1 Swift Inference Mode Switch (极速模式切换)
为了解决 dLoRA 模式切换慢的问题(>50ms),VaLoRA 实现了 Swift Switcher,将切换时间降至 <10ms:
- Contiguous Memory Allocation: 预先为权重矩阵分配连续内存,避免了 Tensor Reshape 时的内存拷贝。
- Runtime Computation: 不在显存中存储巨大的预计算权重 ($W + BA$),而是仅存储小巧的 Adapter ($A, B$)。利用 ATMM 算子,在运行时高效地计算 $\Delta W = B \times A$ 并将其一次性加/减到 Base Model 上。
- Async Swap: 当 Adapter 数量超出 GPU 显存时,仅在主存和 GPU 间异步交换 $A$ 和 $B$ 矩阵(极小,约 43MB),而非巨大的完整模型权重。
4.4.2 Mixture Inference Mode (混合推理模式 / deLoRA)
为了解决请求饥饿 (Starvation) 问题(即:当系统运行在 Merged 模式处理 Adapter 1 时,请求 Adapter 2 的任务必须等待),VaLoRA 引入了 deLoRA 模式,允许 Merged 和 Unmerged 模式并行。
原理公式: 假设 Base Model 已经融合了 Adapter 1 ($W_{merge} = W_{base} + W_{LoRA_1}$)。对于需要 Adapter $x$ 的请求 $input_x$,计算逻辑为: $$ output_x = input_x \times (W_{merge} - W_{deLoRA_1} + W_{LoRA_x}) $$ 其中 $W_{deLoRA_1}$ 等同于 $W_{LoRA_1}$。这相当于在数学上先“减去”当前融合的 Adapter,再“加上”目标 Adapter,从而在不进行物理权重回滚的情况下,正确处理异构请求。
4.4.3 Scheduling Policy (调度策略)
调度算法 (Alg. 1) 遵循贪婪原则:
- 优先 Merged Mode: 只要可能,就使用 Merged 模式,因为它最快(无额外计算)。
- Starvation Handling: 给每个等待的请求分配 Credit(等待时间 + 执行时间)。
- Mode Switching:
- 当饥饿请求出现时,首先切换到 Mixture Mode(开销最小)。
- 只有当饥饿请求数量超过 Max Batch Size 的一半时,才切换到完全的 Unmerged Mode。
5. Implementation and Evaluation
5.1 Implementation
- Codebase: 约 7.1K 行代码,基于 PyTorch, Triton, CUTLASS 和 vLLM (LightLLM version)。
- Key Tech:
- ATMM 使用 CUDA C++ 基于 CUTLASS 3.5.1 实现。
- 利用 Pybind11 封装预编译的 Kernel。
- 集成 PagedAttention 和 Unified Memory Management (统一 KV Cache 和 Adapter 内存)。
- 实现了 Prefix Caching 以复用多轮对话中的图像特征。
5.2 Evaluation Setup
- Hardware: NVIDIA A100 (80GB), Intel Xeon Platinum CPU.
- Models: Qwen-VL-7B, LLaVA-1.5-7B/13B.
- Tasks:
- Visual Retrieval: Visual QA (VQAv2), Image Captioning. (Workload: Azure LLM trace).
- Video Analytics: Object Detection (YODA, Cityscapes), Video Understanding (UCF101). (Workload: 1 video chunk/sec).
- Baselines: S-LoRA, Punica, dLoRA (State-of-the-Art).
5.3 Experimental Results
5.3.1 End-to-End Performance (端到端性能)
- Visual Retrieval: 如图 14 (上),VaLoRA 相比 dLoRA, Punica, S-LoRA 分别降低了 72%, 50%, 20% 的平均 Token 延迟。这得益于 ATMM 的高效和 Mixture Mode 避免了频繁的重型切换。
- Video Analytics: 如图 14 (下),性能提升更为显著,延迟降低了 89%, 83%, 71%。主要归功于 Vision Task Head 消除了多轮自回归推理,以及对长 Input Token 的高效处理。
5.3.2 Accuracy (精度表现)
- VaLoRA 生成的 Adapter 使 Qwen-VL 在 Visual QA 和 Image Caption 上提升了 4.3-5% 的精度。
- 在传统小模型擅长的任务(如目标检测)上,VaLoRA 提升了 Base Model 24.5-62.2% 的精度,达到与 SOTA 专用小模型(如 YOLO, VisionMamba)相当的水平。
5.3.3 Component Analysis (组件分析)
- Vision Task Head: 相比原始 LM Head,在视频分析任务中减少了 41-63% 的延迟,仅需一轮推理。
- ATMM Efficiency: 如图 17,ATMM 在各种 Batch Size 下均保持最低延迟,速度是 S-LoRA 的 2.7倍,Punica 的 2.3倍。特别是在 Batch Size > 1024 时,自适应大 Tile 优势明显。 稳定性方面,ATMM 将延迟波动降低了 2-3 倍。
- Orchestration: 在不同负载倾斜度 (Skewness) 下,VaLoRA 的混合调度策略比 dLoRA 降低了 21% 的延迟,比纯 Unmerge 模式降低了 59%。Swift Switcher 将切换速度提升了 >5 倍。
5.3.4 Scalability (扩展性)
在多 GPU 环境下表现出良好的线性扩展能力。从 1 张到 4 张 A100,系统总吞吐量从 6.07 req/s 提升至 23.97 req/s。
6. Discussion and Limitations
- Limited flexibility of vision task head: Vision Task Head 是针对特定任务(如分类数)定制的线性层,灵活性不如自然语言接口。因此 VaLoRA 对于 VQA 等任务仍保留 LM Head,通过 ATMM 实现两者的并发执行。
- Knowledge fusion order: 知识融合的顺序会影响最终 LoRA 的质量(如图 5 所示)。目前主要依赖启发式方法,未来可引入 Curriculum Learning 等技术优化融合顺序。
- Knowledge pre-clustering: 数据聚类方式也会影响效果。目前 VaLoRA 按视觉任务类型聚类,未来可探索更细粒度的聚类方法。
7. Conclusion
本文首次探索了利用 LMM 作为视觉应用的基础模型,旨在实现高效的服务和用户友好的自然语言接口。为此,作者提出了 VaLoRA,这是一个端到端的系统,通过 Accuracy-aware LoRA Adapter Generation 适配领域特定任务,并通过 Adaptive-tiling Batching 和 Flexible Orchestration 在运行时高效管理这些 Adapters。在两个典型的视觉应用中,VaLoRA 证明了单个 LMM 可以有效替代多个专用小模型,在大幅降低延迟(20-89%)的同时保持相当的精度表现。这为未来基于 LMM 的多任务视觉应用设计奠定了基础。