
Conference: ICML'25 Workshop on Long-Context Foundation Models
Github: https://github.com/wdlctc/headinfer
1. Motivation
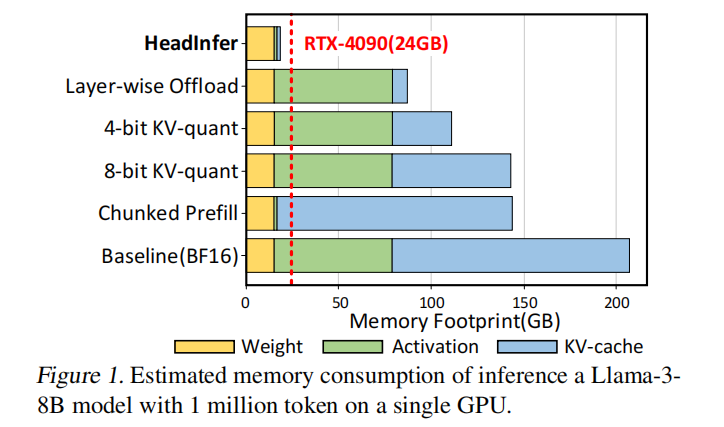
Transformer-based LLM 在长上下文场景下的推理性能显著,但随着上下文长度的扩展,KV cache(key-value cache)迅速成为内存占用的主要瓶颈。论文指出:例如对 Llama-3-8B 进行 1M token 推理时,KV cache 可达 128 GB,整体内存可达 207 GB(权重 + activation + KV cache),这是在常见 BF16 设置下的估算,使得在消费级 GPU(如 RTX-4090,24GB)上无法直接执行长上下文推理。为解决此类问题,作者提出 HEADINFER —— 通过按 attention head 维度进行细粒度 KV cache 离线/回传(offload),仅在 GPU 上保留部分 attention heads 的 KV,从而极大地压缩 GPU 端 KV 的占用,同时保证数学等价性(lossless)和兼容各种 attention 形式(dense / sparse)。论文摘要与引言的核心论点与数据来自原文说明。
2. Relative Work
-
生成式推理与 KV 缓存(Generative Inference & KV Caching):预填(prefill)和解码(decoding)阶段的概念与常用 chunked prefill 思路(将长输入切为若干 chunk 逐步构建 KV cache)被回顾,用以说明激活内存与 KV cache 在不同阶段的不同开销特征。
-
有损的 KV 管理(Lossy KV Management):提到 Sliding Window、Heavy Hitter、StreamingLLM 等方法,这些方法通过丢弃或压缩不重要 token / head 来缩内存(有精度/信息权衡)。HEADINFER 与这些方法不同:它保持“无损”的等价性(数学一致),但通过更细粒度的 offload 控制来降低 GPU 占用。
-
KV Offloading 的既有工作:LayerKV、FastDecode、NEO、ShadowKV、FlexInfer、Infinigen 等都是将 KV 缓存移动到外部(CPU/磁盘/压缩表征)来换取更长的上下文,HEADINFER 在粒度和 overlapped transfer 上做了不同的工程设计以实现对消费级 GPU 的支持。
3. Challenge
- 核心挑战:当上下文 $S$ 到百万级别时,KV cache 的线性增长会使得 GPU HBM 无法承载,导致运行时 OOM。现有的粗粒度 offload(按 layer)仍然无法在剩余的 GPU 内存、激活(activations)与 KV cache 三者之间取得平衡,尤其是在消费级 GPU(如 RTX-4090)上。即便 offloading 把 KV 放到 CPU,激活内存(activations)仍占很大比例,且粗粒度 offload 导致 GPU 仍需保留数量可观的 KV。
4. Contribution
简要列出本文主要贡献:
- 提出 HEADINFER:基于 head-wise offloading 的 KV 管理策略,使 GPU 端只保留极少的 head KV(甚至每次只保留 1 个 head),实现数学等价的长上下文推理。
- 使用 roofline 模型系统性分析,实现 prefill 阶段仍保持 compute-bound、避免陷入 memory-bound,从而在一定上下文规模下保持高效能。
- 设计 adaptive head grouping、chunked prefill、ping-pong 异步数据搬运与 pre-allocation 等工程优化,保证实际系统性能与可用性(支持 dense / sparse attention,如 duo-attention)。
- 在 RTX-4090(24GB)上对 Llama-3-8B、Llama-3-70B 等模型进行实验,展示在 8B 模型上实现百万级(甚至到 4M)context 的能力。
5. Method
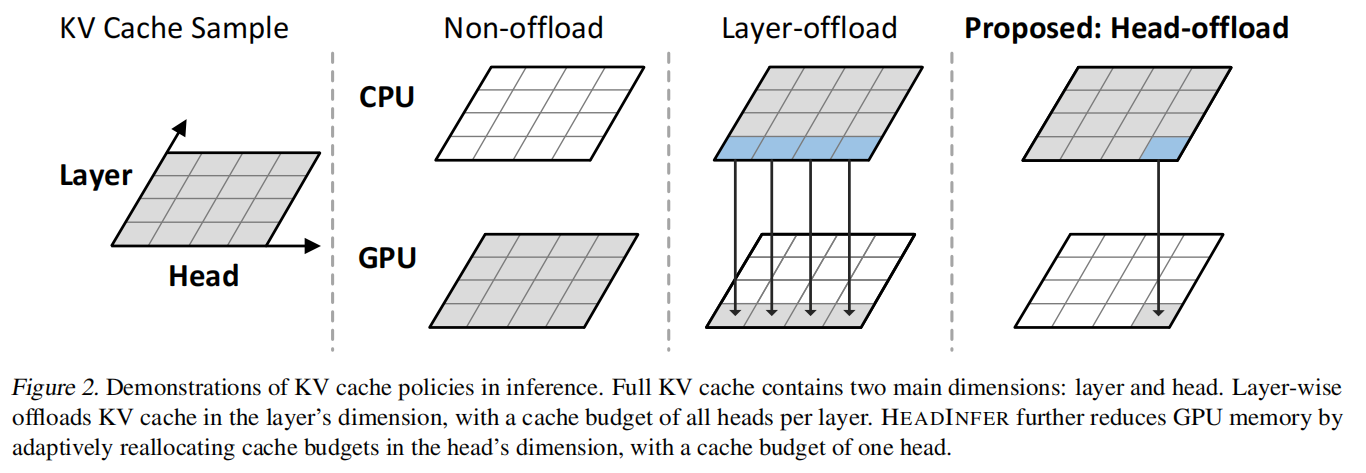
HEADINFER 的核心思想是:利用 transformer 中 attention heads 的计算独立性,将 KV cache 在 head 维度做分区(head-wise partition),并在 GPU 上仅保持少量(甚至 1 个)head 的 KV,其余 KV 保存在 CPU RAM。当需要计算某 head 的 attention 时,通过异步预取(prefetch)将该 head 的 KV 载入 GPU,计算完成后异步将其写回 CPU。通过ping-pong memory 设计,HEADINFER 能够在计算和 PCIe 传输之间实现重叠,从而把通信开销隐藏到计算时间里(当计算时间足够长时,可以几乎不引入额外延迟)。
5.1 基础公式与组织方式(数学陈述)
-
在常规设置下,每个 time-step $t$ 的 key/value 由线性投影得到: $$ K_t = W_K E(x_t), \quad V_t = W_V E(x_t) $$ 序列长度为 $S$ 时,整个 layer 的 KV cache: $$ K_{cache} = [K_1, \ldots, K_t],\quad V_{cache} = [V_1,\ldots, V_t] $$
-
在 head-wise 表示下,模型有 $H$ 个 heads(每层),每个 head 的维度为 $D_h = D / H$。第 $h$ 个 head 的 KV: $$ K^{(h)} \in \mathbb{R}^{S \times D_h},\quad V^{(h)} \in \mathbb{R}^{S \times D_h} $$ attention 的 head-level 输出为: $$ A^{(h)}t = \text{Softmax}\left(\frac{Q^{(h)}t (K^{(h)}{cache})^\top}{\sqrt{d_k}}\right) V^{(h)}{cache} $$ 最终将所有 heads 的输出拼接(concatenate)得到层输出。HEADINFER 利用这个 head-local 的计算等价性来按 head 做 KV 的分区和迁移。
5.2 HEADINFER: Head-wise Offload
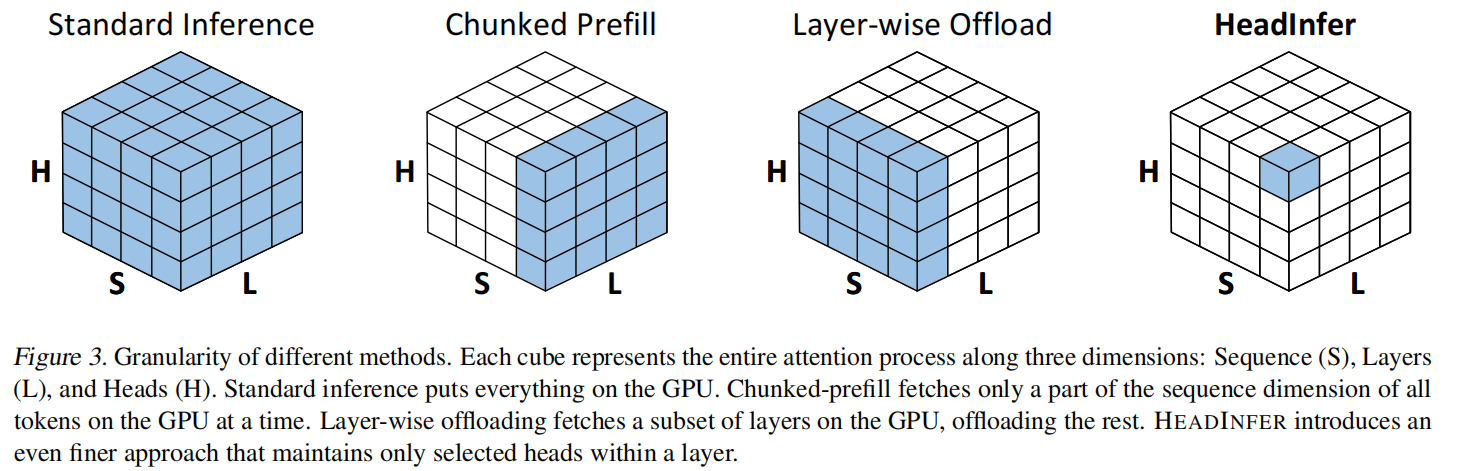
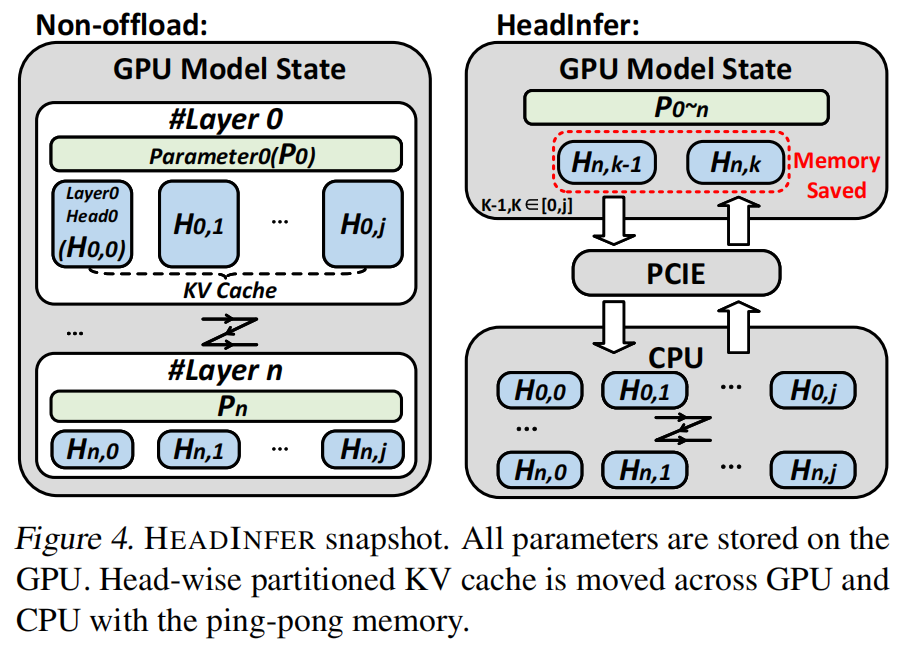
算法概览(伪代码、流程)
论文提供了 Algorithm ,主要流程如下:
 初始化:
初始化:
- 在 GPU 上为 $H_{on}$(保留在 GPU 的 heads)预分配 ping-pong buffer(避免运行时频繁分配)。
- 在 CPU 上为 $H_{off}$(offloaded heads)预分配 KV 存储(并尽可能使用 pinned memory 以提高 PCIe 传输效率)。
Prefill 阶段(输入处理):
-
使用 chunked prefill:把长输入按 chunk(论文建议 chunk size = 10K,基于 roofline 分析)分块处理,减少 activation 峰值内存。对每个 chunk:
- 对每个 layer、每个 head 逐个计算 $K^{(h)},V^{(h)}$;
- 若该 head 在 GPU($h\in H_{on}$),则更新 GPU 端 KV buffer;
- 否则($h\in H_{off}$),启动 异步预取(async prefetch) 和 异步更新(async update back to CPU):即边计算当前 head,边用 DMA/async PCIe 将下一个所需 head 的 KV 从 CPU 读到 GPU,同时把当前 head 的 KV 写回 CPU。这样利用 ping-pong 将通信与计算重叠,减少阻塞。详见 Algorithm 1 的第 6–13 行与第 10–11 行。
Decoding 阶段(自回归生成):
- 每生成一个 token 都要对所有先前 token 的 KV 做 attention(对应的 head-level KV 也随之增长)。HEADINFER 在 decoding 阶段仍然采用相同的 head-wise 迁移策略,保证每个 head 的 attention output 在 GPU 上计算,KV 的移动通过异步预取 / 异步写回完成,算法在 Algorithm 1 的第 18–32 行给出完整流程。
关键工程优化(实现细节)
-
Ping-pong memory:在 GPU 侧维护双缓冲区(ping & pong),保证在计算一个缓冲区时,另一个缓冲区正在进行 DMA 传输(prefetch / writeback),从而实现 compute <-> transfer 的 overlap。论文强调这对长上下文尤为关键。
-
Pre-allocation(预分配):GPU / CPU 的 KV buffer 在推理开始时预分配,以避免在线程/内存碎片化和频繁分配导致的抖动。论文中明确建议为 CPU(host)端的 KV 使用 pinned memory,以提升 PCIe 带宽利用率并减少复制开销。
-
Adaptive head grouping(自适应头分组):为减少 kernel launch overhead(小 head 粒度会导致大量 kernel 启动),HEADINFER 在不同上下文阶段选择不同的 head grouping:
- 小上下文(短 S):倾向把多个 head fuse 到一个 kernel(例如 group=8,即把一层所有 head 一次性处理,这与 layer-wise offload 等价);
- 大上下文(长 S):逐渐降低 group 大小,到最终最细粒度(group=8 -> group=4 -> group=2 -> group=1 的演进),以在内存占用和通信开销之间取得平衡。论文给出了 500K、1M、2M、4M 等阈值下的分组策略。
-
与 head-wise sparsity 的结合:HEADINFER 与 duo-attention、HeadKV、Razorattention 等 head-wise sparsity 方法兼容。具体策略是把“重要且长的 retrieval heads” 视为需要保留在 GPU(on-GPU Hon),而把短的、可截断的 heads 仍 offload 或做截断(典型阈值:长度 < 1k 时不值得 offload 因为 PCIe / kernel overhead 反而降性能)。详细扩展在 Appendix D。
空间复杂度与 $\alpha$(GPU 上保留比例)
定义 $\alpha$ 为保留在 GPU 上的 KV fraction($0\le \alpha \le 1$)。若只保留单个 head(整个模型的 $1/(L\times H)$),则: $$ \alpha = \frac{H_{on}}{H_{all}} \quad\Rightarrow\quad \alpha = \frac{1}{L\times H} $$ GPU 上的 KV 大小约为: $$ S_{onGPU} = 2 \times B \times S \times D_h \times \text{sizeof(datatype)} $$ 从而在理论上可把 GPU KV 缩至极小比例(例如 Llama-3-8B 在 1M token 下 GPU KV 从 128GB 降到 1GB 的示例)。
6. Analysis and Evaluation
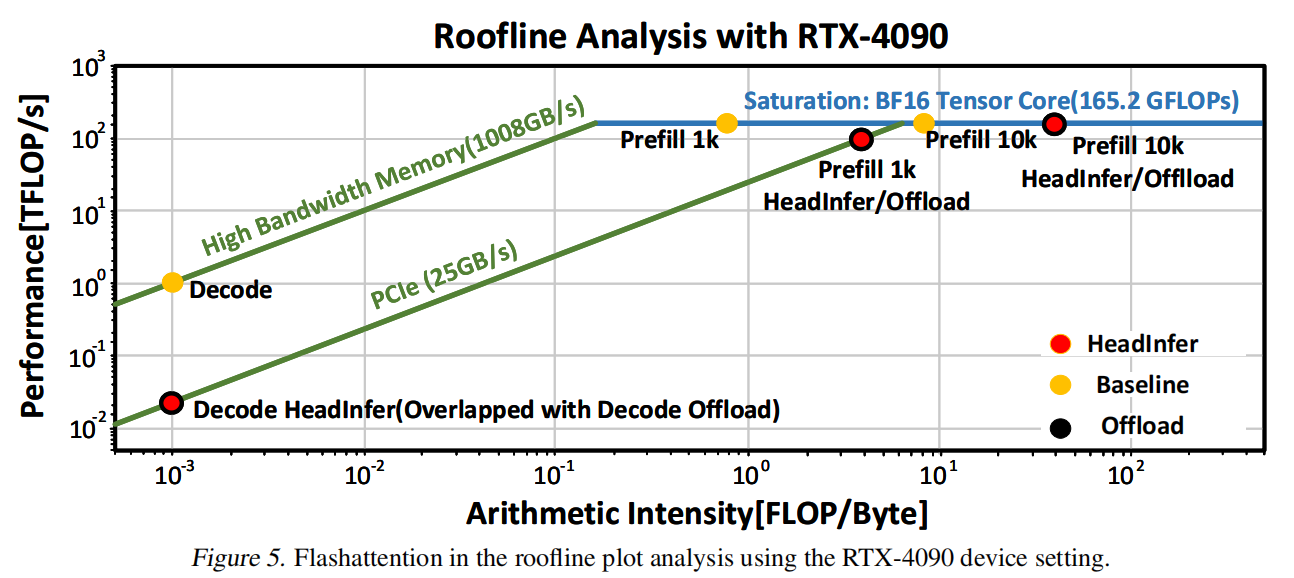
6.1 Roofline 分析(性能模型与结论)
-
性能模型:论文用一个简化的时间模型把每个 token 的时间近似为: $$ T \approx \max(T_{comp}, T_{mem}) $$ 其中 $T_{comp}\propto \frac{D \times S^2 \times L \times H}{F_{GPU}}$(prefill 的 compute 成分与 $S^2$ 相关),而 $T_{mem}\propto \frac{D \times S \times L \times H}{B_{mem}}$。解码阶段(每 token attend 先前 tokens)为线性随 $S$ 增长。
-
主要观察(基于 RTX-4090 的 roofline):
- Prefill 阶段在较大上下文($S\ge 10$k)下仍为 compute-bound(即算力主导),因此对 PCIe offload 的依赖不会显著将其拉入 memory-bound,使得异步 offload 的通信开销可以通过 compute 来掩盖(overlap)。
- 对于短上下文($S\le 1$k)或某些极短场景,offload 会把工作搬到 memory-bound,导致开销上升(turning point 在 ~2k)。因此 HEADINFER 在短上下文下可能不如标准推理快。
- 解码阶段通常 memory-bound,因此在解码时依赖 PCIe 带宽会显著降低吞吐,解法上依靠 adaptive 分组和尽量把 compute 与 transfer 重叠来缓解。
6.2 Long-Context Benchmarks(LongBench v2 / SCBench / Ruler / NIAH)

-
实验平台:RTX-4090(24.5GB HBM3),host:AMD EPYC 家族多核 + 大量 DDR5 + NVMe,PCIe 4.0 单向约 25GB/s(用于 pinned host memory)——这是实验环境设定,会影响能否完全重叠通信/计算。
-
LongBench v2 结果(表 1):HEADINFER 在 Llama-3-8B(1024k)上在 Medium / Long 子集上得分最高(表中给出整体与分项),这表明在需要长上下文理解/检索的任务上,扩展上下文带来的信息增益超过 offload 带来的开销。
-
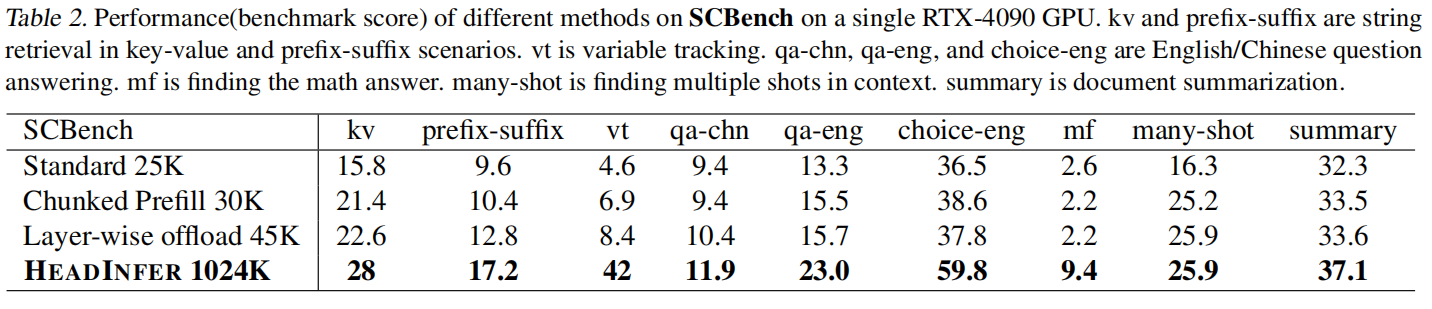
SCBench(表 2):HEADINFER 在一组 KV-centric 任务上全项优于其他方法(例如 kv、prefix-suffix、variable tracking 等),尤其在 many-shot / retrieval 类任务增益明显,说明更长上下文显著提升实际能力(而且 HEADINFER 保证无损)。
-
Ruler / Needle-in-a-Haystack / NIAH:HEADINFER 在大型 synthetic benchmark(Ruler)中将可处理最大序列长度提升到 128K(相比标准 16K / chunked 32K),在 NIAH 中 HEADINFER 在 1024K 情况仍能保持与标准推理等价的检索准确度(见 Figure 6),进一步证明数学一致性与检索能力。
6.3 内存与吞吐(表 3、表 10、表 11)

-
关键实验结论:
- 在 Llama-3-8B、1M token 的场景下:HEADINFER 在 prefill 时使用约 17GB,decode 时约 16.4GB,而标准 BF16 设置下需要 207GB,因此 HEADINFER 将 GPU 内存占用从数百 GB 级别压缩到接近 17GB,从而在单张 24GB 卡上实现 1M+ 上下文推理(数值来自论文)。
- 表 10 / 11 给出详细的权重 / KV / activation 的分解(以 Llama-3-8B + 1M 为例),HEADINFER 的总估算约 16.7GB,与实测 17GB 非常接近,说明估算模型合理。
-
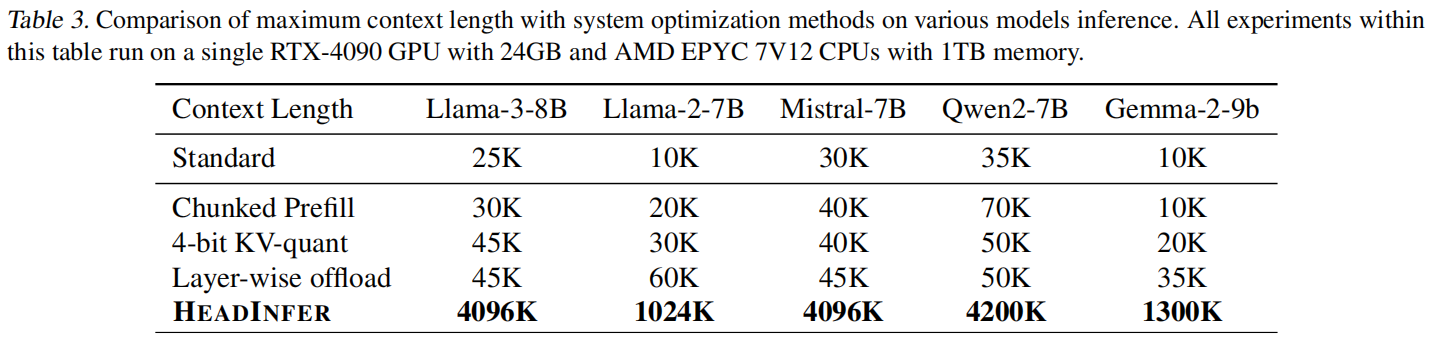
最大支持的 context length(表 3):
- 比较结果(在单卡 RTX-4090 上)显示:Standard ~ 25K,Chunked ~ 30K,4-bit KV-quant ~ 45K,Layer-wise offload ~ 45K,而 HEADINFER 可以达到 4096K(4,096K)(对于 Llama-3-8B),其他模型也有大幅扩展(例如 Qwen2-7B 到 4200K)。这说明 HEADINFER 的 head-wise 策略能把限制从 GPU HBM 转移到 CPU RAM(可配置更大),从而显著提升最大可支持的上下文长度。
6.4 吞吐与延迟(prefill / decode)(A.1 表 6 / 表 7)
-
Prefill 吞吐(对 Llama-3-8B):
- 在短输入(如 1k、10k、20k)阶段,HEADINFER 与标准方法的 prefill 吞吐几乎一致(例如 ~0.11–0.14s 的 prefill latency),在长输入(>100k)开始出现更大差别,但 HEADINFER 仍能在百万级上下文下完成 prefill(表 6)。
-
Decode 延迟(每 token):
- 标准推理在短上下文 decod e 速度较高(例如 ~0.03s/token),而 layer-wise offload 与 HEADINFER 在解码时随着上下文增加会出现显著延迟增长(因 memory-bound),但 HEADINFER 通过 adaptive grouping 在中等上下文(20k–100k)仍维持可接受延迟,且在极大上下文(1M,2M)时延迟虽然增加但仍可完成任务(表 7)。
6.5 Ablation Study(表 5)—— 粒度对最大上下文长度的影响
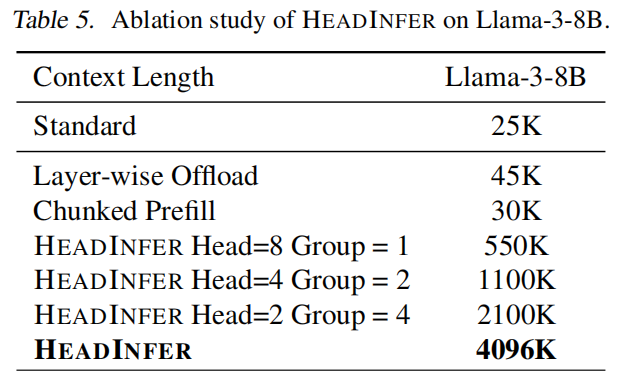
-
论文通过把 head grouping 从粗到细做对比(Head=8 Group=1 相当于 layer-wise offload;Head=1 Group=8 为最细粒度)表明:
- 粗粒度(大 group)在短至中等上下文时能减少 kernel 启动开销,性能更好;
- 细粒度(小 group)在超长上下文时能节省最大内存,从而支持更大的 context length(从 550K → 4096K);
- 因此 Adaptive Head Grouping(根据当前上下文规模动态选择 group)是必要且有效的折中策略。
6.6 实验可重复性与实现注意事项
- 使用 pinned host memory(page-locked)来减少 PCIe 复制开销。
- chunk size 的选取影响 roofline 上的 compute-vs-memory tradeoff:作者根据 RTX-4090 的 roofline 建议默认 chunk size = 10K(prefill 在 10K 级别能保持 compute-bound)。
- CPU RAM 容量是限制 HEADINFER 能否继续扩展上下文的另一个瓶颈(论文在多处说明 Llama-3 / Mistral 等模型的 1M+/4M 支持最终受 CPU RAM 限制)。若需要更大上下文,可把 offload 目标改为 NVMe,但需要考虑更高的延迟。
7. Conclusion
HEADINFER 提出并实现了按 attention head 做 KV cache 离线/回传的细粒度 offloading 框架,结合 ping-pong 异步传输、chunked prefill 和 adaptive head grouping 等技术,使得在消费级 GPU(如 RTX-4090)上可以实现百万级乃至千万级上下文长度的无损推理。论文通过 roofline 分析、多个长上下文 benchmark(LongBench v2、SCBench、Ruler、NIAH)以及系统级的内存 / 吞吐度测量,验证了 HEADINFER 在内存效率和实际性能之间的折中与优势。作者还讨论了与 head-wise sparsity 方法的兼容性,并演示在多卡 pipeline 场景下扩展到 70B 规模模型的可行性。