
1. Motivation
随着数据质量的提高和模型架构设计的成熟,LLM 的 Densing Law [Yao et al., 2024] 不断提升,使得小参数模型也能获得强大的通用能力。这一趋势为大模型的端侧部署(On-device deployment)提供了实际的基础。最近,紧凑型 MLLM(如 Qwen3 VL 2B [Bai et al., 2025a] 和 InternVL 2B [Zhu et al., 2025, Wang et al., 2025])展示了极具竞争力的性能。
然而,一个关键的瓶颈依然存在:这些模型通常依赖标准的 Vision Transformer (ViT) 编码器,而 ViT 具有二次复杂度(Quadratic Complexity)。当处理高分辨率输入(这在用户界面 UI 理解和 grounding 等典型端侧场景中至关重要)时,它们在端侧部署期间容易产生高内存消耗和明显的推理延迟。为了缓解这一问题,一些尝试(如 Apple 的 FastVLM [Vasu et al., 2025])通常诉诸于通过激进的卷积下采样(Convolutional Downsampling)来减少视觉 token,但这往往以性能大幅下降为代价。
2. Conclusion
为此,作者推出了 HyperVL,这是一种专为端侧推理量身定制的高效多模态大语言模型。
具体而言,作者采用了图像切片策略(Image-tiling strategy),将高分辨率输入划分为可以独立编码的小块,从而降低峰值内存消耗。在此基础上,作者通过两项关键技术进一步降低端侧推理成本:
- 视觉分辨率压缩器 (Visual Resolution Compressor, VRC):自适应地根据图像信息密度预测最佳视觉编码分辨率,避免不必要的高分辨率计算,降低视觉编码延迟。
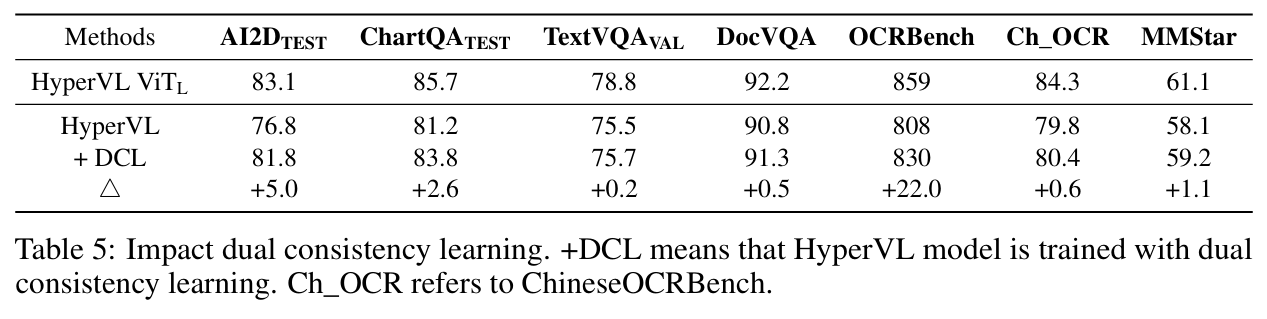
- 双重一致性学习 (Dual Consistency Learning, DCL):在不同容量的 ViT 编码器上应用 DCL,使它们能够无缝连接到共享的 LLM,从而根据任务类型、延迟预算或设备计算能力,在轻量级和高精度视觉路径之间实现动态切换。
总结作者的贡献如下:
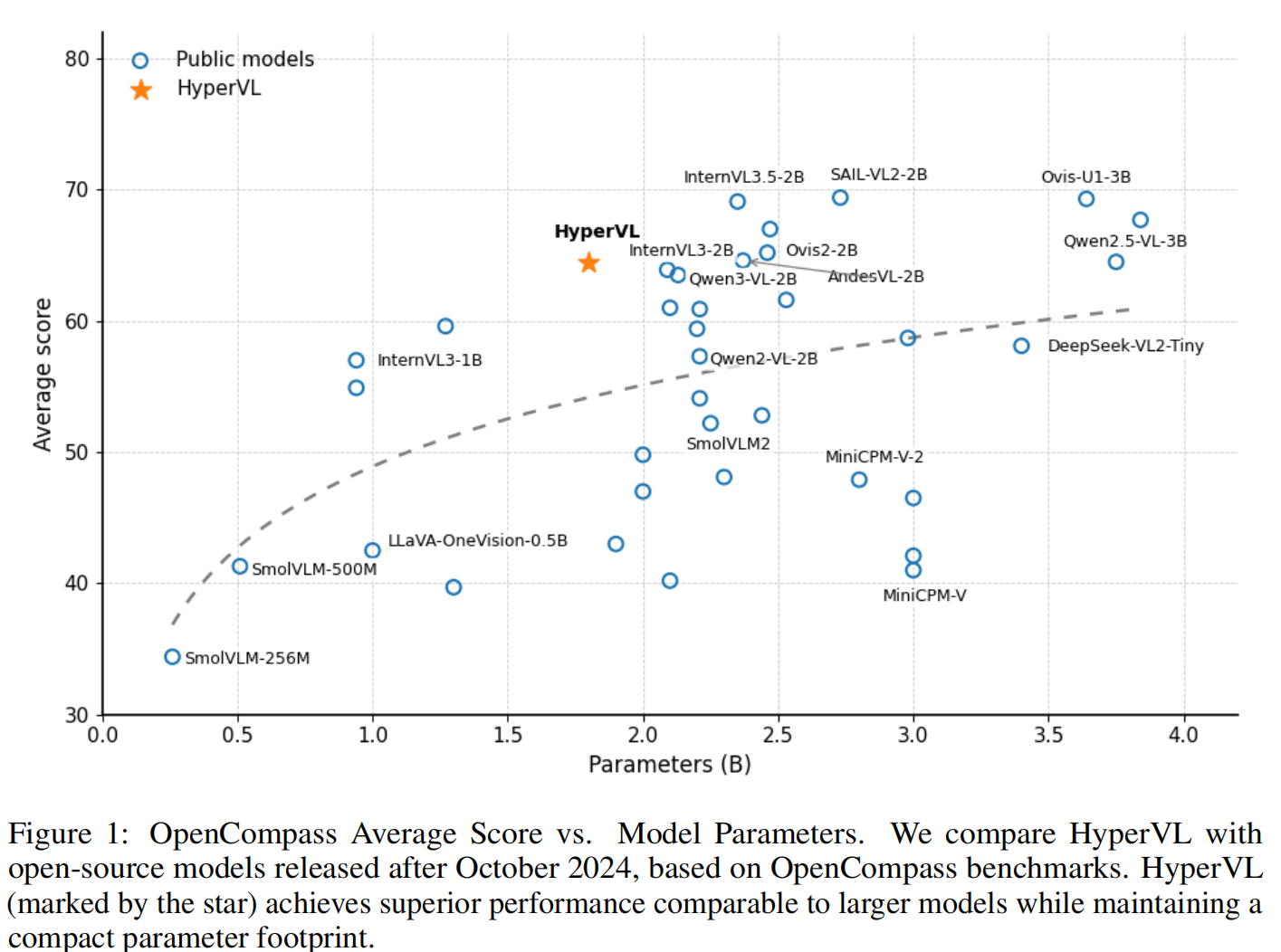
- 作者提出了 HyperVL,一个专为高效端侧推理设计的多模态大语言模型。如 Fig. 1 所示,在同等模型规模下,HyperVL 在多个权威多模态基准测试中达到了 SOTA(State-of-the-art)结果,并在端侧场景中超越了现有的通用模型,为实际端侧应用实现了重大的能力突破。
- 作者通过 ViT 双重一致性学习和视觉分辨率压缩器显著提升了视觉编码效率。该压缩器是即插即用的(Plug-and-play),可以直接集成到任何预训练的 MLLM 中,为端侧多模态推理提供了一种通用的加速方案。
- 作者在真实硬件上系统地验证了端侧推理性能。作者量化了商业移动设备上延迟和内存消耗的降低,为优化端侧部署的高效多模态推理流水线提供了全面的系统级演示。
3. HyperVL
3.1 Architecture
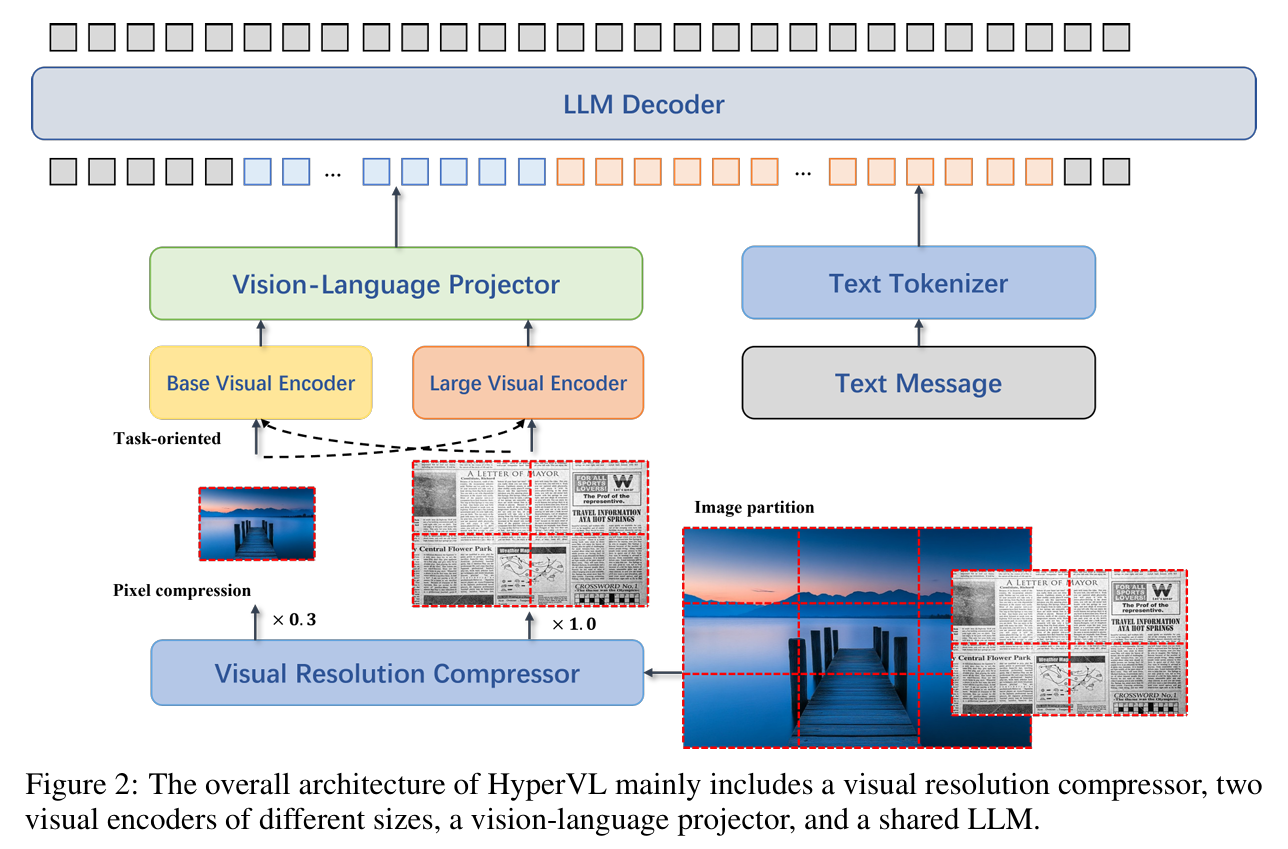
[Fig. 2: HyperVL Overall Architecture. 展示了 VRC、双视觉编码器分支、Projector 以及共享 LLM 的连接方式]
如 Figure 2 所示,HyperVL 包含四个核心模块:视觉分辨率压缩器、两个不同尺寸的视觉编码器、视觉-语言投影器(Vision-language projector)以及共享的大语言模型(LLM)。
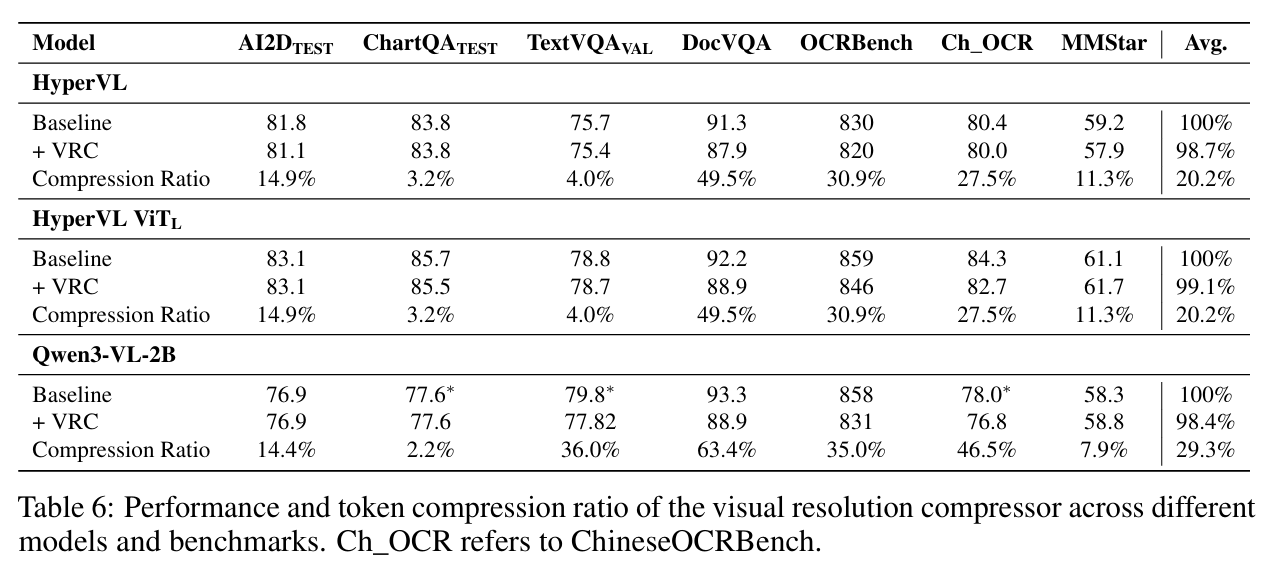
- Visual Resolution Compressor (VRC): 作者观察到,高分辨率图像并不总是必需的——大图会显著增加端侧 ViT 的推理延迟和内存占用,而在某些场景下,低分辨率图像已足以支持高质量响应。为此,作者设计了 VRC,它根据输入图像的信息密度预测压缩率 ,将图像缩放至原始尺寸的 10%–100%。该压缩器由一个轻量级的 CNN 主干网络组成,推理延迟极低(约 2ms)。

-
Visual Encoders: 作者采用了两种不同尺寸的 ViT 变体——SigLIP2-Large 和 SigLIP2-Base 作为视觉编码器。
-
SigLIP2-Large: 24 层,约 300M 参数,用于高精度需求的任务。
-
SigLIP2-Base: 18 层,约 93M 参数,用于低延迟需求的任务。 为了处理任意宽高比和分辨率的图像,作者集成了 AnyRes 策略:通过最小比例缩放保持原始宽高比,并在必要时添加 padding,随后将处理后的图像切分为不重叠的 patches。
-
Vision-language Projector: 为了将视觉表示映射到 LLM 的输入空间,作者使用一个两层 MLP 作为 Projector,将 ViT 输出与 LLM 的嵌入层(Embedding layer)对齐。此外,作者引入了 Pixel Shuffle 技术,将视觉 token 序列在空间维度上进行压缩,使输入 LLM 的 token 长度减少为原始的 ,显著缓解了 LLM 处理长序列的压力。
-
Shared LLM: 为了平衡端侧的计算资源与推理性能,作者选择了 Qwen3-1.7B 作为基础大语言模型。两个视觉分支共享该 LLM 的参数。
3.2 Dual Consistency Learning (DCL)
为了使不同规模的视觉编码器(Base 和 Large)能与同一个 LLM 兼容并保持语义一致性,作者设计了双重一致性学习策略。其核心思想是让两个分支在训练过程中相互对齐。
- Dual-Branch Alternating Training (双分支交替训练): 在训练过程中,作者以一定的概率交替激活 分支或 分支。这种策略确保了 LLM 能够适应来自不同视觉编码器的特征分布。
- Semantic Consistency Distillation (语义一致性蒸馏): 为了进一步缩小两个分支间的性能差距,作者将 分支视为教师(Teacher), 分支视为学生(Student)。通过最小化两者预测概率分布之间的 KL 散度,引导小模型学习大模型的逻辑。
其中 和 分别代表学生和教师模型在给定图像 和历史文本 下,对下一个 token 的预测分布。这种方法确保了在切换到轻量级分支时,模型性能依然稳健。
3.3 Visual Resolution Compressor (VRC)
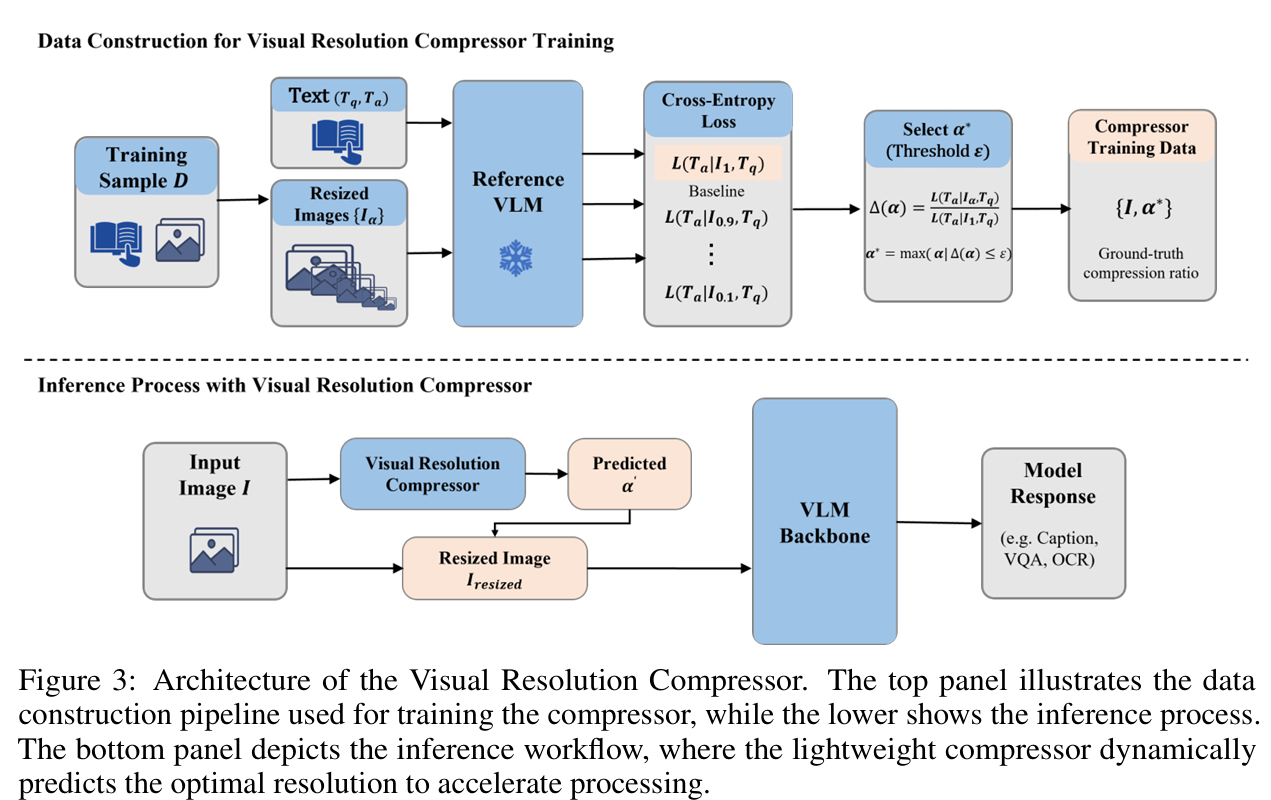
VRC 是实现端侧高效推理的关键。它并不是简单地缩放图片,而是**内容自适应(Content-adaptive)**的。
-
工作流程: 输入图像首先经过一个极小的编码器提取全局特征,回归出一个标量 。图像会根据 动态调整分辨率。
-
按需分配计算资源:
-
对于信息冗余度高的任务(如 DocVQA 中的文档背景),VRC 会预测较小的 ,减少视觉 token 数量,减少量可达 49.5%–63.4%。
-
对于细节密集型任务(如 ChartQA 中的微小文字),VRC 会自动预测 ,保留原始高分辨率以维持精度。
-
效率提升: 实验证明,VRC 在减少约 20.2% 的视觉 token 的前提下,仍能保留 98.7% 的基准性能。
3.4 Training Data
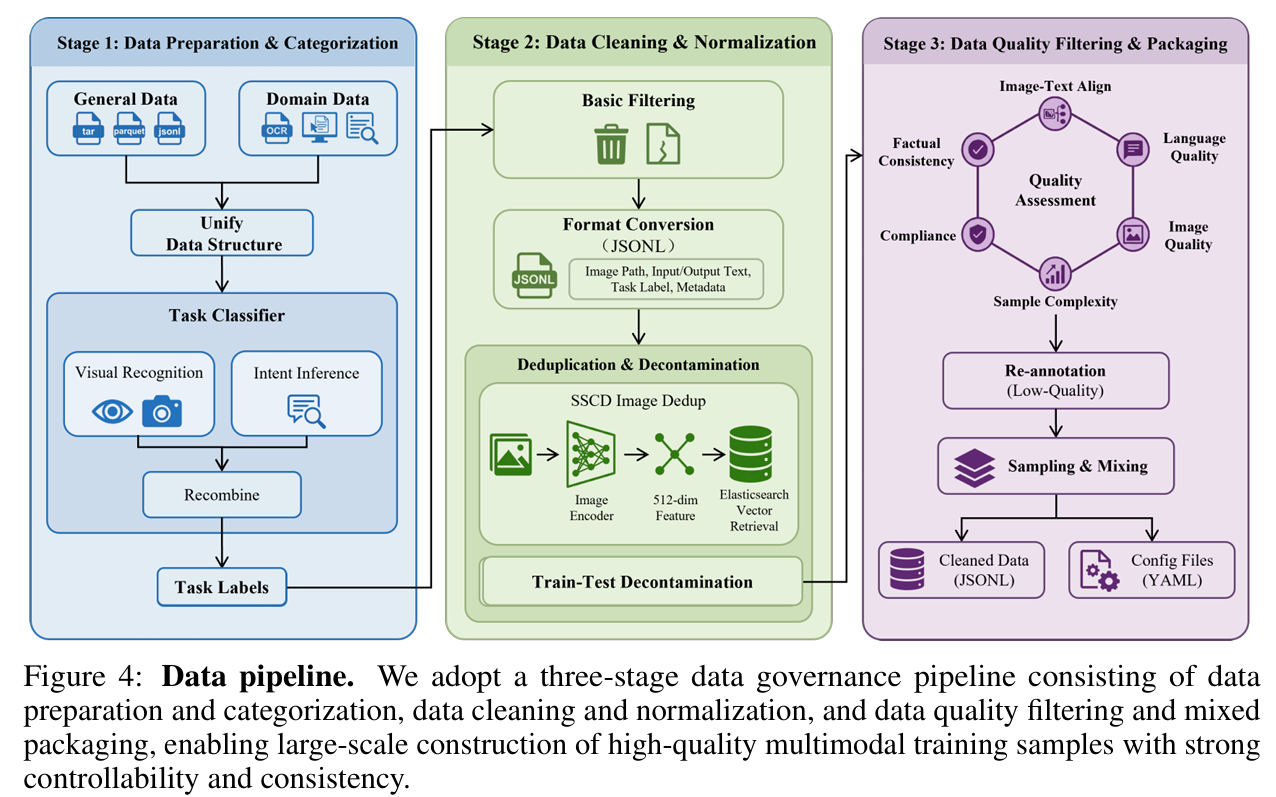
作者构建了一个三阶段的数据治理流水线,确保训练数据的多样性与高质量:
- Data Classification (数据分类): 采用“任务分解-重组”策略,将样本分为视觉识别(Content-based)和意图推理(Instruction-based)两大类,分类准确率超过 96%。
- Quality Filtering (质量过滤): 使用包含图文对齐度、图像质量、事实一致性等 12 个指标的量化框架进行筛选。
- Diversity (多样性): 涵盖了通用任务(如 COCO, GQA)、STEM 领域(ART500K, ScienceQA)、OCR 以及大量的 GUI 落地数据(用于增强端侧 UI 理解能力)。
3.5 Training Pipeline
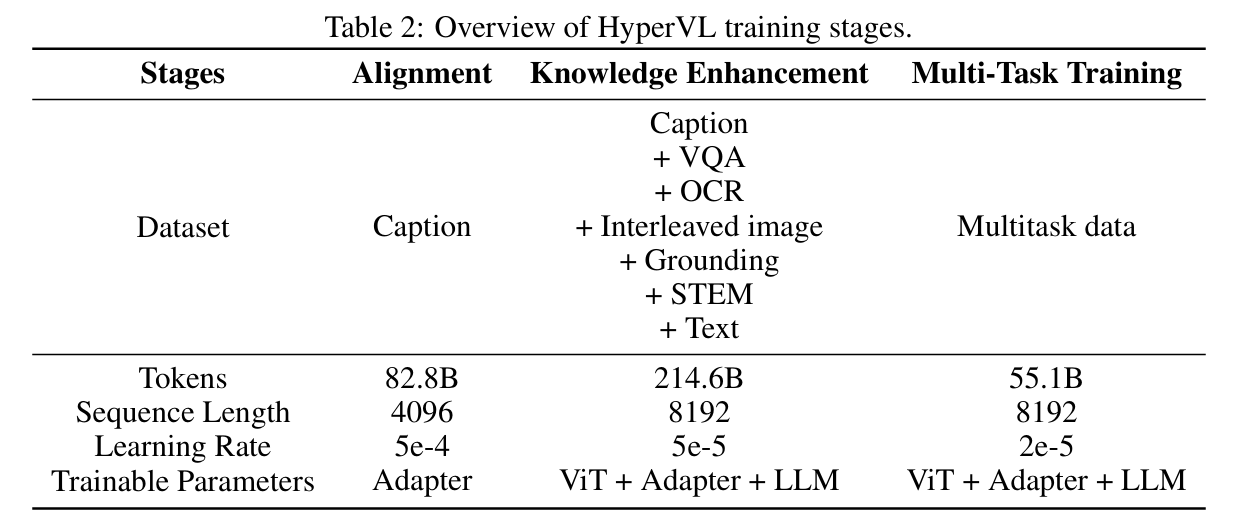
HyperVL 的训练分为三个关键阶段:
- Stage 1: Vision-Language Alignment (图文对齐): 冻结 ViT 和 LLM,仅训练 Projector。使用大规模图文对数据,让视觉特征初步映射到文本空间。
- Stage 2: Knowledge Enhancement (知识增强): 解冻全参数。使用混合的多模态数据进行全参数预训练,提升模型的视觉知识储备。此时引入 DCL 策略,训练双分支的一致性。
- Stage 3: Multi-Task Supervised Fine-Tuning (多任务微调): 在高质量、经过精挑细选的指令遵循数据集上进行微调,优化模型在特定端侧任务(如 UI 导航、数学推理)上的表现。
4. Evaluation
4.1 Public Benchmarks
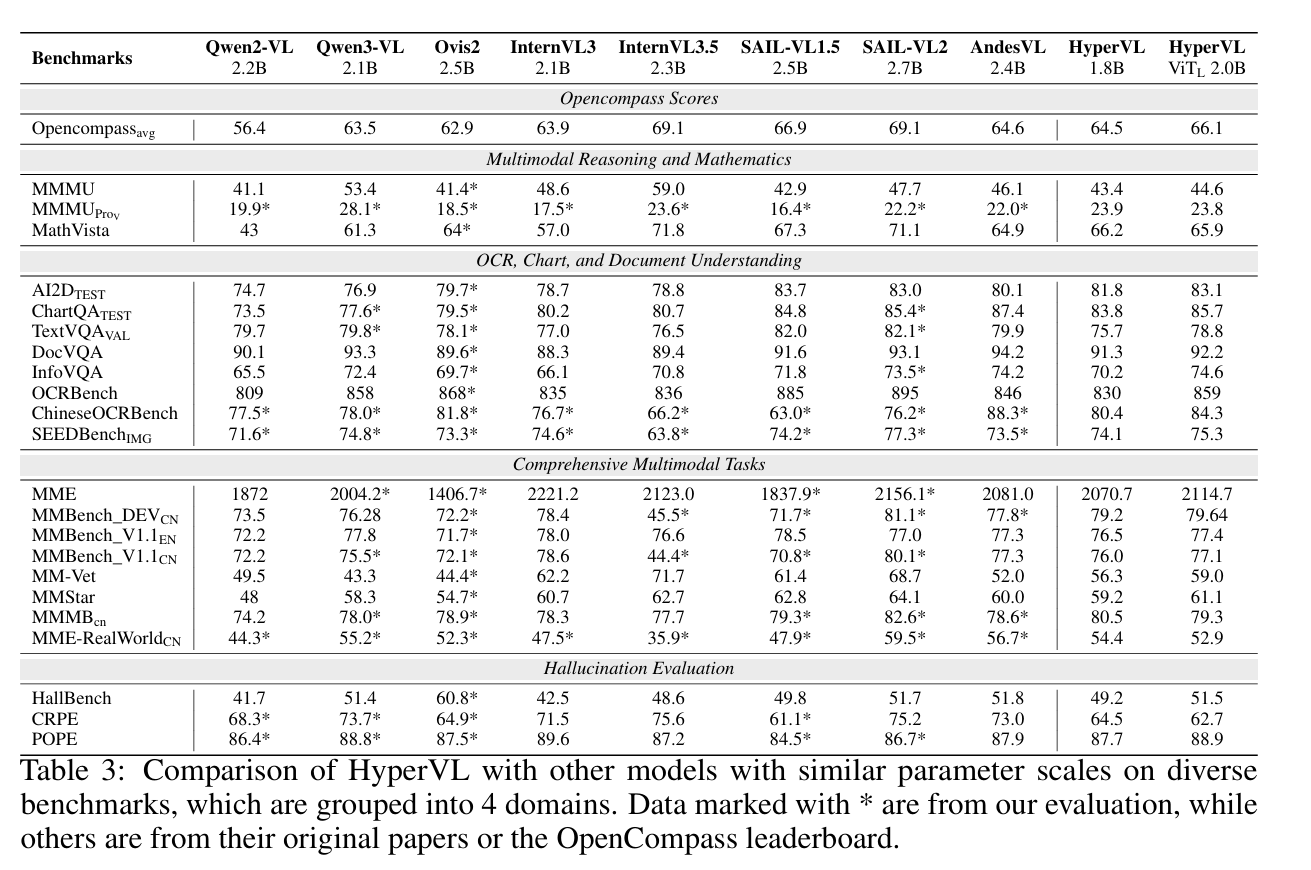
作者在 OpenCompass 框架下对 HyperVL (1.8B) 进行了全面评估。
-
综合性能: HyperVL 在 OpenCompass 平均分达到 64.5。
-
细粒度任务表现:
-
ChartQA: 83.8(在同规模模型中处于领先地位)。
-
DocVQA: 91.3(证明了强大的 OCR 和文档理解能力)。
-
AI2D: 81.8(展现了优秀的科学图表解析力)。
-
MathVista: 66.2(强于许多更大参数的模型)。
-
Scale-up 效果: 使用 分支的 HyperVL (2.0B) 平均分进一步提升至 66.1。
4.2 Internal Benchmarks (端侧实用场景)
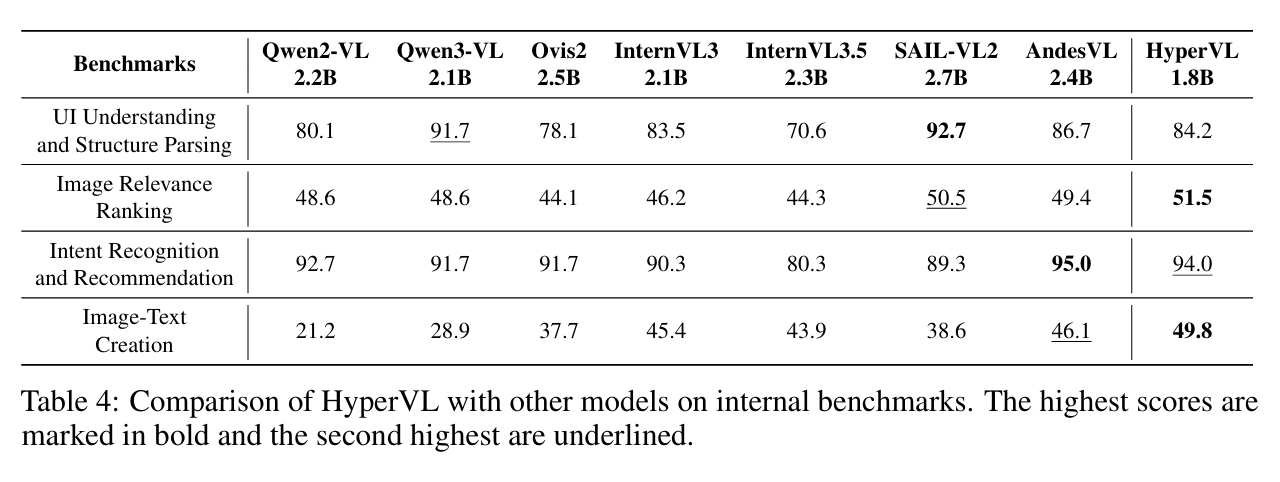
 针对真实的端侧应用,作者测试了三个核心场景:
针对真实的端侧应用,作者测试了三个核心场景:
- UI 理解与结构解析: 准确率 84.2%。
- 意图建议与推荐: 准确率 94.0%。
- 图文创作: 评分 49.8。
4.3 On-device Efficiency (真实硬件表现)
作者在 Qualcomm 8750 移动平台上验证了 HyperVL 的系统级优化效果:
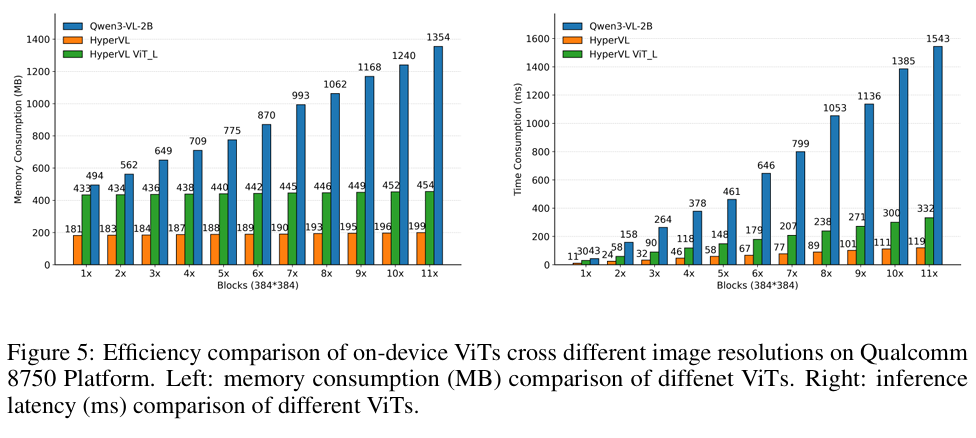
- Memory Consumption (内存消耗): 标准的 Qwen3-VL 在处理高分辨率时内存会激增(峰值达 1354MB)。相比之下,HyperVL 通过图像切片和 VRC 策略,将峰值内存降低了 6.8倍。
- Inference Latency (推理延迟): 通过 DCL 切换到 分支并配合 VRC,推理速度提升了约 12.9倍。
- Hardware-aware Optimization: 作者实现了将图像 patches 串行输入硬件加速器,确保中间激活值(Activations)始终保留在片上高速存储 VTCM 中,避免了频繁的 DDR 访问,极大降低了功耗。
5. Conclusion
作者提出了 HyperVL,这是一个专为端侧推理设计的高效多模态大语言模型。通过图像切片(Image tiling)、视觉分辨率压缩器(VRC)和双重一致性学习(DCL),HyperVL 在显著降低移动设备延迟和内存占用的同时,在多个基准测试中达到了 SOTA 性能。
该模型在 UI 理解、意图推荐和图文创作等实际端侧任务中展现出强大的泛化能力。未来工作将探索自适应 token 稀疏化、注意力剪枝,并将其扩展到视频理解和实时交互场景,进一步提升在真实移动应用中的资源感知性能和用户个性化体验。