
Conference: INFOCOM'25
Github: https://github.com/ysyisyourbrother/Jupiter
1. Motivation
- 随着生成式大型语言模型(LLMs)在边缘场景(如智能家居、个人设备)中应用需求上升,越来越多研究尝试将 LLM 服务下沉到受限的边缘设备上以保护隐私与降低云依赖。
- 单个边缘设备通常计算/内存受限:长上下文导致 prefill 阶段时间增长,autoregressive decoding(逐token生成)也会因逐步依赖导致高延迟。
- 现有协同边缘推理方法(TP/SequenceParallel 等)要么在每层进行大量 tensor 同步造成通信瓶颈(在低带宽下尤其明显),要么在单序列场景下无法并行利用多台设备(pipeline 在单序列下退化为串行)。
- 此外,大多数现有工作只优化 prefill,相对忽略 decoding 阶段(但对于生成式任务,decoding 也可能主导延迟)。
- 因此,论文动机是设计一个面向边缘、多设备、既能优化 prefill 又能加速 decoding,且通信高效、资源可扩展的协同推理系统 — 即 Jupiter。
2. Contribution
-
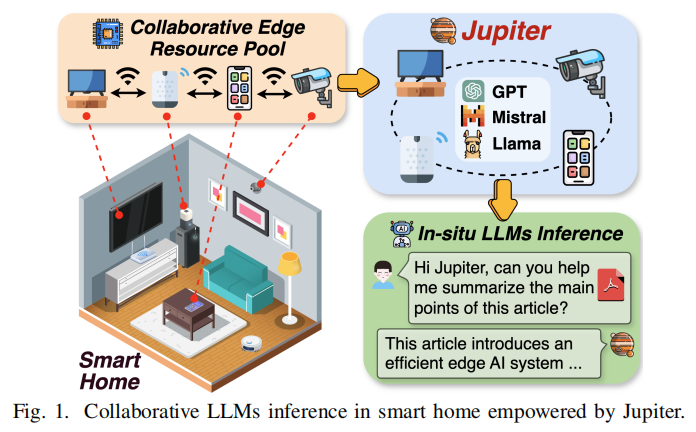
提出以**pipelined architecture(流水线并行)**为原则的协同边缘推理系统设计,强调通过分层映射(layer→stage→device)来“拼装”多设备内存以容纳更大模型,同时只在相邻 stage 之间交换小量激活(activation),从而极大降低通信量。
-
在 prefill 阶段提出 intra-sequence pipeline parallelism —— 将单条输入序列切分为多个连续子序列并并行注入流水线,同时依靠缓存的 hidden states 保障 self-attention 的正确性,从而在单序列场景下也能实现并发。
-
设计了基于动态规划(dynamic programming)的资源高效并行规划(parallelism planning),同时考虑设备异构、内存预算和可变输入长度,自动求解最优的模型层划分(LLM partition)与序列划分(sequence partition)。
-
在 decoding 阶段,引入并整合 speculative decoding(自我/轻量 draft heads 或小 draft 模型产生候选 token ,随后并行验证)以并行化 token 生成,并进一步提出 outline-based pipeline parallel decoding —— 先生成答案大纲(outline),再把大纲的每个点作为独立并行的“point-extending”请求注入流水线以并行生成每个点,从而充分利用多设备空闲计算资源。
-
在真实边缘测试平台实现并评估 Jupiter,展示在多种场景下(不同模型、设备拓扑和带宽限制)相较最先进方法最高可达 26.1× 的端到端延迟缩减,并保持近似的生成质量(在某些需要强链式推理的任务上 outline 方法略有下降,系统可选择性关闭)。
3. PRELIMINARIES
3.1 Collaborative Edge Computing for Generative LLMs
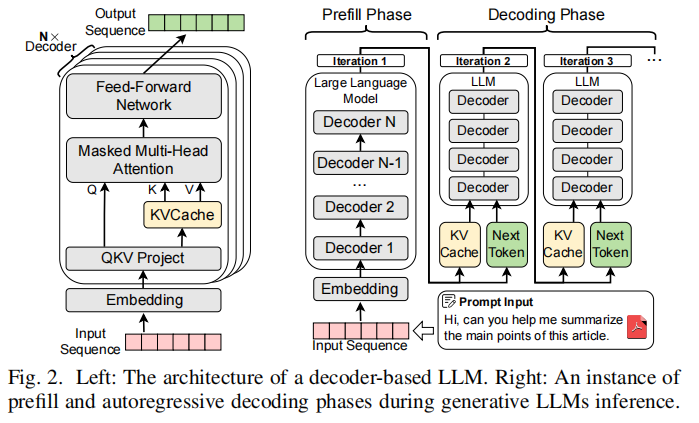
Decoder-based 模型结构
- Decoder-based LLM(如 GPT、LLaMA、Mistral)由 embedding、若干 decoder layer 叠加和输出 head 组成。每个 decoder layer 包含:QKV projection、Masked MHA、FFN、以及运行时的大量 KVCache(用于 decoding 中重用)。图示:
 。
。
两阶段推理
- Prefill Phase(prefill):将 prompt(上下文)完整前向一次,生成第一个 token,并把每层的 K/V 保存在 KVCache 中,time-to-first-token 是此阶段关键延迟指标。
- Autoregressive Decoding(decoding):逐 token 生成,新的 token 会被反馈并与之前的 KVCache 一起用于下个 token 的生成。长生成会使 decoding 成为主导延迟。
并行化方法对比(四类)
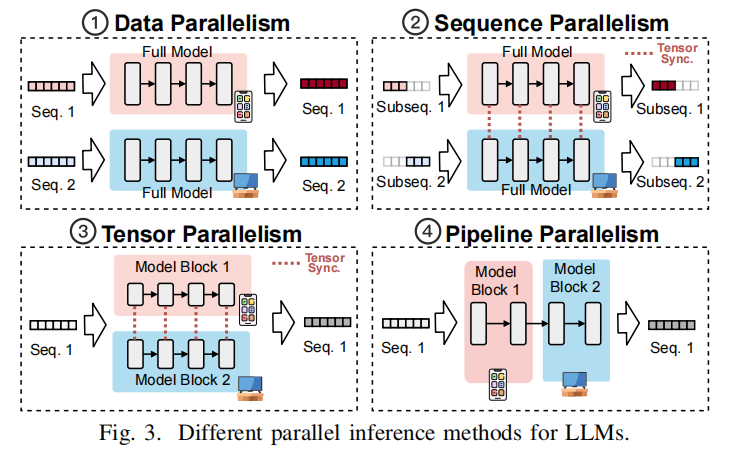
- Data Parallelism (DP):样本维度复制模型,不适合单序列并发。
- Sequence Parallelism (SP):每台设备保留完整模型,将序列按子段并行,但每层需 all-gather 同步(通信高)。
- Tensor Parallelism (TP):将权重切分,需 per-layer all-reduce(通信高)。
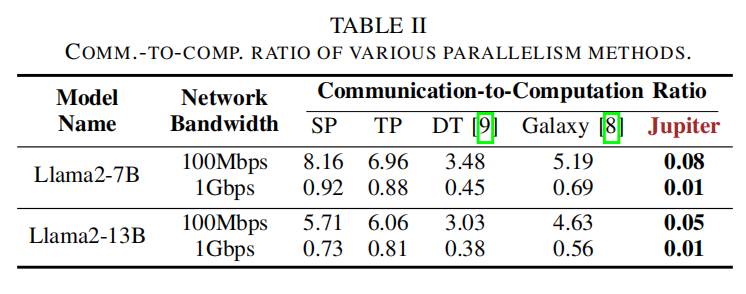
- Pipeline Parallelism (PP):按层切分为 stage 映射到设备,通信仅限邻居激活(更低通信),但在单序列下易退化为串行 —— 需要新方法挖掘 intra-sequence 并行机会(见 Jupiter 提案)。表格与复杂度见 Table I/II。
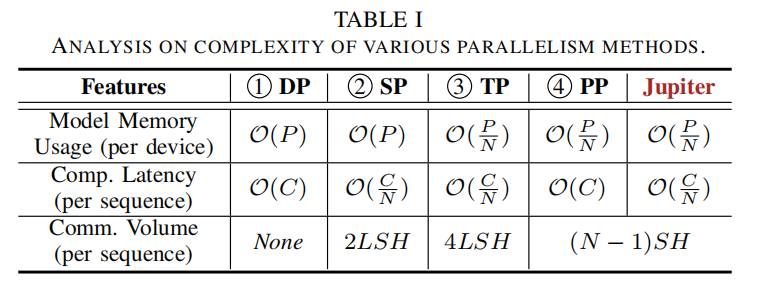
基础符号定义(符号与 Table I 对应)
| 符号 | 含义 |
|---|---|
| $P$ | 模型参数总量(字节或元素个数) |
| $C$ | 完整单序列前向推理的总计算量(FLOPs) |
| $L$ | 模型 decoder 层数 |
| $S$ | 输入序列长度(prefill 阶段特别重要) |
| $H$ | Hidden size(即每个 token 的向量维度) |
4. Method
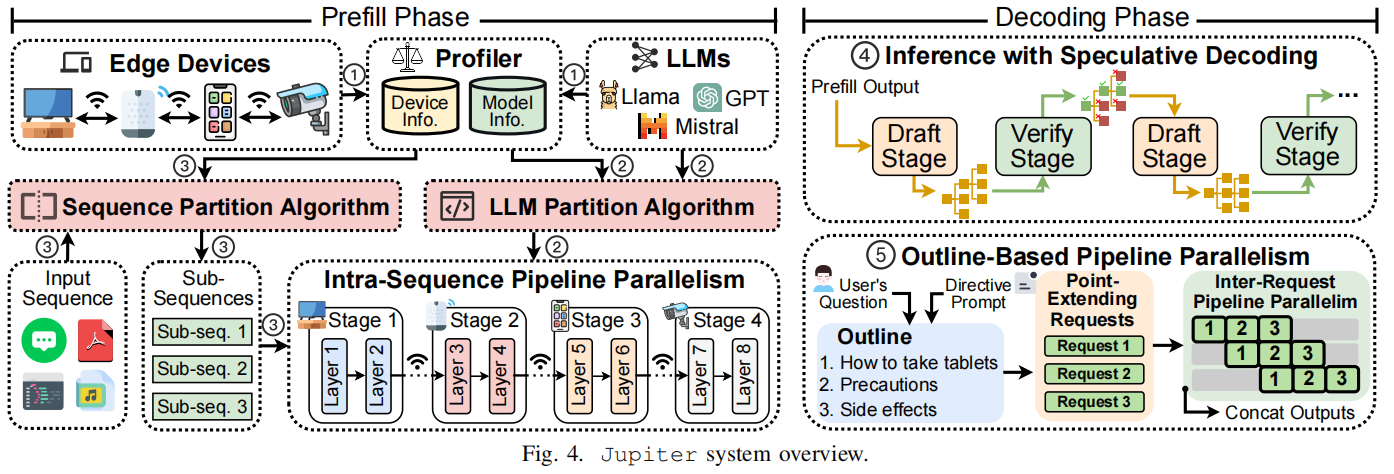
总体流程(系统概览):
- Profiler:用不同长度的 calibration sequences 在每台边缘设备上进行预填(prefill)测试,记录运行时 trace(层级延迟、内存占用、加速器利用率等),用于并行规划。
- LLM Partition Algorithm(模型层划分):基于 profiling 数据与设备集合 D,使用动态规划求解将 L 层划分为多个 stage 的最优策略,使得最慢 stage 的执行时间最小化(平衡负载),并考虑内存约束(若 stage 模型超过设备内存则该划分不可用)。
- Sequence Partition Algorithm(序列划分):基于设备加速器在不同输入长度下的利用率,选出最小子序列长度 $b$(避免 under-utilization),然后使用动态规划对每种输入长度 $y$ 找到最优的子序列划分数 $k$ 与划分方案,使得慢子序列的延迟平衡且每段长度 $\ge b$。
- Prefill 推理:将子序列并行注入流水线,各 stage 缓存每个子序列的 hidden states,计算时可利用前面子序列的缓存以保证 causal attention 的正确性(详见 Intra-Sequence 部分)。
- Decoding:结合 Speculative Decoding(自我 drafting)和 Outline-based 并行扩展两种策略以加速 autoregressive 流程。
在下面的子节中详细展开关键模块。
4.1 PARALLEL ACCELERATION FOR PREFILL PHASE
4.1.1 Intra-Sequence Pipeline Parallelism for Generative LLMs
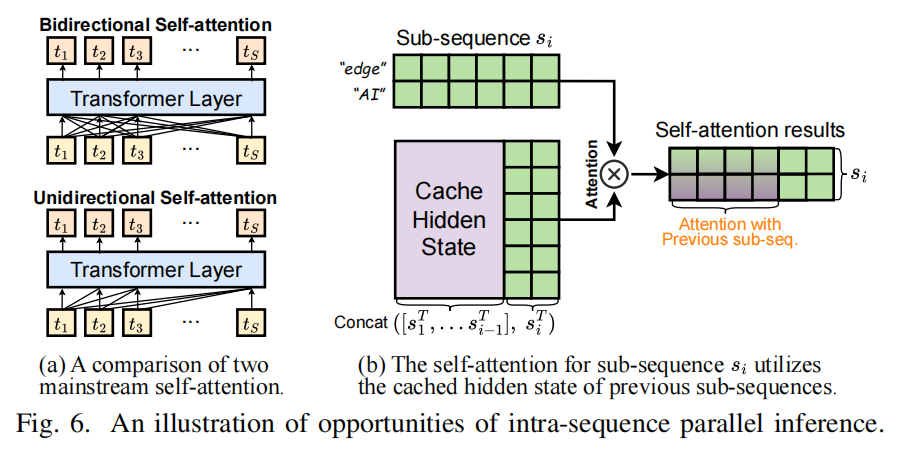
基本思想:利用 causal decoder 的单向注意力(token $t_i$ 只依赖此前 token $t_1 … t_{i-1}$),把一个长输入序列划分成 $M$ 个连续子序列 $(s_1, s_2, …, s_M)$,然后把这些子序列顺序注入流水线并并行计算:每个 stage 对每个子序列都保存其 hidden states(KVCache-like),当处理子序列 $s_i$ 时,可以直接利用缓存的 $s_1…s_{i-1}$ 的 hidden states 来正确计算 self-attention,从而不用把整个序列一次性在单台设备上串行处理。见图: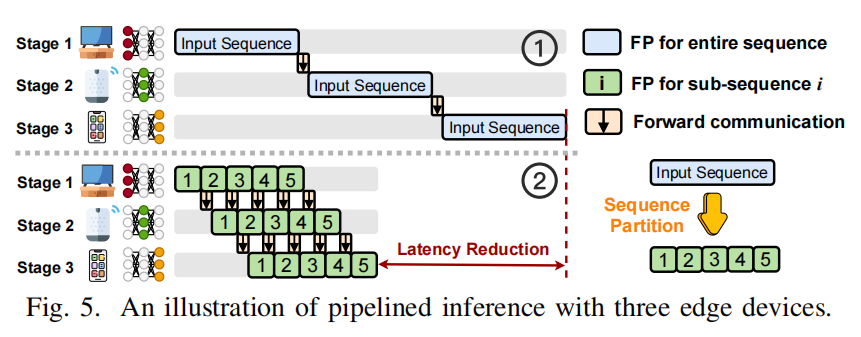 、
、 。
。
关键工程与正确性注意点:
- 每个 stage 需要缓存所有注入过的子序列的 hidden states(内存/KVCache 管理需谨慎),因此需要在 partition planning 时考虑 KVCache 的内存占用。
- 子序列越短,流水线 bubble 越少并行度越高,但短段会导致加速器 under-utilization;因此序列划分不能一味细分,需要平衡(见下节规划算法)。
- 对 self-attention 的正确性:只要子序列间缓存和数据传递牢靠(保证 earlier sub-seq hidden states 在 later sub-seq 计算时可用),则 causal mask 的语义保持,从而输出与完整序列顺序计算一致(等价性依赖于实现对 KVCache 的精确维护与传输顺序)。
4.1.2 Resource-Efficient Parallelism Planning
并行规划分为两部分:(A)LLM 层划分与 (B)输入序列划分。两者都使用动态规划方法求解最优(或近似最优)方案。
(A)LLM Partition(层划分) 目标:把 $L$ 层划分为若干 stage 并映射到设备集 $D={d_1,…,d_n}$,使得 pipeline 的 steady-state throughput 由最慢 stage 决定时,该最慢 stage 的运行时间最小化。 动态规划核心公式为(论文给出的形式):
$$ A(1 \rightarrow y, D_n) = \min_{1 \le l < y} \max { A(1 \rightarrow l, D_{n-1}),; T(l+1 \rightarrow y, d_n) } $$
其中 $T(i\rightarrow j, n) = \sum_{l=i}^{j} t^n_l$ 表示设备 $d_n$ 处理层 $i$ 到 $j$ 的时间(通过 profiling 得到 $t^n_l$)。若某个 stage 模型(含参数与 KVCache)超出设备内存预算,则令对应 $T$ 为 $+\infty$(不可行)。该方法时间复杂度 $O(L^2 |D|)$。
(B)Sequence Partition(序列划分) 目标:对给定句长 $y$,将其划分为 $k$ 段,使得每段处理延迟尽可能平衡,同时每段长度 $\ge b$(避免加速器 under-utilization)。论文定义了函数 $q(x,y)$:表示子序列长度为 $x$、其前面累计长度为 $y$ 时,在某 stage 上的推理延迟(通过离线 profiling 获得并可插值)。动态规划公式为:
$$ W(1 \rightarrow y, k) = \min_{1 \le l < y} \max { W(1 \rightarrow l, k-1),; T^*(y-l, l) } $$
并且
$$
T^*(y-l, l) =
\begin{cases}
+\infty, & \text{if } y-l < b,
q(y-l, l), & \text{otherwise.}
\end{cases}
$$
解释:$W(1\to y, k)$ 表示将句子 $1..y$ 划分为 $k$ 段后,最慢段的延迟(该值希望尽可能小)。最终选择 $k$ 时还结合一个对整体预计延迟的估计:
$$ \text{Latency} = \sum_{i=1}^k h_i + (|D|-1)\times W(1 \rightarrow y, k) $$
其中 $h_i$ 是子序列 $s_i$ 在每 stage 的推理延迟(由 $q(\cdot)$ 得到),$(|D|-1)\times W$ 表示 pipeline 中填满之后的 steady-state 影响项。论文在实现上为避免开销过大,将 $k$ 限制为 $\le 4|D|$ 并对 $y$ 迭代到 $S_{max}$,时间复杂度 $O(S_{max}^2 |D|)$。该规划为一次性离线过程,论文中实测在边缘设备上不到 5 分钟即可完成(可被多次推理均摊)。
实现要点与工程折衷
- profiling 需覆盖不同 $x,y$ 组合,但可通过并行采样与插值来降低实际开销。
- KVCache 内存估计必须包含所有 stage 的缓存需求(特别是当同时存在多个子序列在 pipeline 中),否则会出现 OOM。
- 划分策略在同一设备集上针对不同输入长度可以预先计算并缓存,运行时只需 lookup 对应策略以快速部署。
4.2 COLLABORATIVE INFERENCE FOR DECODING PHASE
Decoding 阶段的难点在于其自回归(autoregressive)性质:每个新 token 依赖前面的完整上下文,传统上难以并行。Jupiter 在这部分提出两条主线优化:Speculative Decoding(草稿式并行) 与 Outline-Based Pipeline Parallel Decoding(大纲引导并行),二者可以组合使用。
4.2.1 Collaborative Inference with Speculative Decoding
基本思路:在每个 decoding 步,使用额外的 lightweight heads(或小的独立 draft model)基于当前 logits 预测多个 candidate tokens(draft),然后把这些候选并行验证(通过原始 LLM 前向)以确认哪些 candidate 可接受,从而用并行化减少需要逐 token 由原 LLM 处理的轮数(Draft-then-Verify Paradigm)。论文实现采用 Self-Drafting(在主模型上加 FFN heads),流程如下(图示见 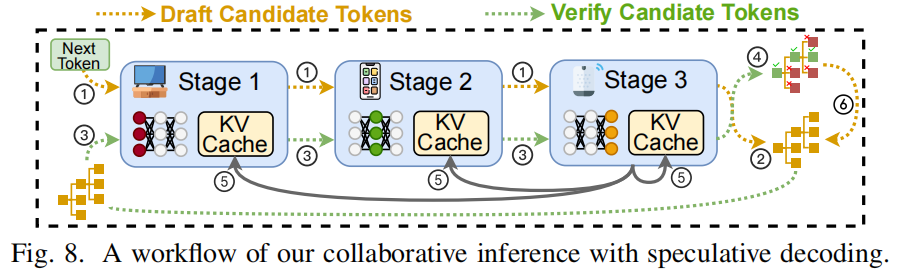 ):
):
- 将当前 token 输入 LLM 前向,得到 logits。
- logits 由头部(draft heads,FFN)并行生成多个 candidate tokens。
- 把 candidate tokens 从最末 stage 传回起始 stage,作为多个并行请求再次送入 LLM 前向;所有 candidate 的 intermediate 计算结果写入 KVCache。
- 对每个 candidate 计算 posterior probability(或基于验证机制)决定接受/拒绝。被拒绝的 candidate 在 KVCache 中被清除(通知各 stage),被接受的则直接使用其预先算出的 logits 作为生成结果或继续作为下轮 drafting 的输入。
- 从已接受 token 的输出中提取 logits 继续产生下一批 candidate。
工程亮点:Jupiter 的工作流使每一次 draft + verify 只需要一次完整 LLM 前向(而非多次),并精心管理 KVCache 与候选 token 的同步删除/保留,最大限度避免冗余计算。论文在实验中采用了 Medusa 的 token-tree speculative decoding 算法作为具体实现示例(5 个 draft head,top-1 策略等)。
4.2.2 Outline-Based Pipeline Parallel Decoding
核心动机:仅用 speculative decoding 虽能并行化 token 生成,但流水线仍可能串行化(尤其当 draft → verify 仍形成串行依赖)。借鉴“人类先列提纲再逐点展开”的思路,Jupiter 提出在 prefill 时先让模型生成回答的大纲(outline),再把大纲中的每个要点作为独立“point-extending request”并行送入 pipeline 扩展,最终把每个点的输出拼接得到完整答案。流程概览(见图 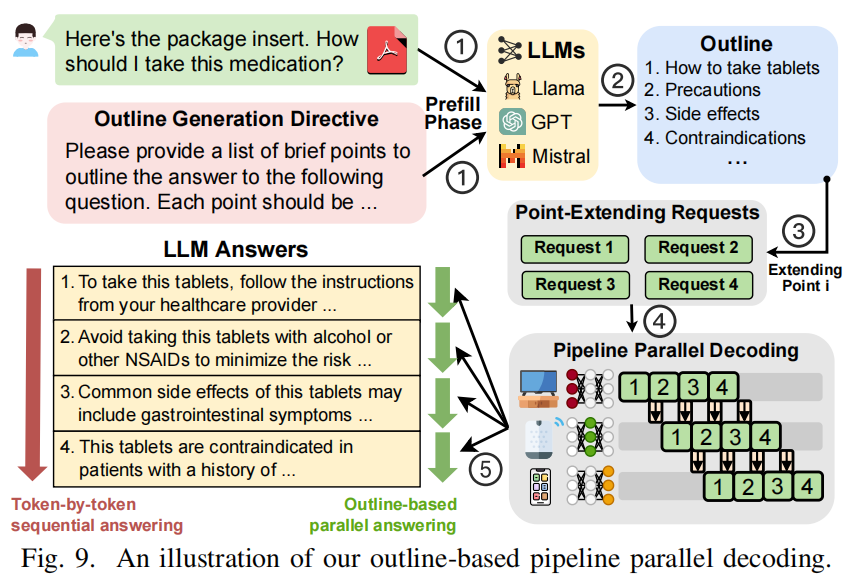 ):
):
- 在 prefill 阶段,把用户 query 与“大纲生成指令”拼接并进行 prefill(该静态 guide prompt 的 prefill 可离线 cache 到 KVCache)。
- 模型输出一个有序大纲(例如 3–6 点)。
- 将大纲中的每一点分别封装为单独请求(point-extending request),每个请求只引导模型针对该点展开,且这些请求可并发注入 pipeline(共享初始 prefill 的 KVCache,避免重复计算)。
- 等所有 point 扩展完成后把结果按顺序 concat 回来,得到最终回答。
适用/不适用场景:outline 方法在文档摘要、问答、知识类或需要分条回答的任务上效果很好(并行度高、速度快)。但对于需要强链式推理、step-by-step 的数学或编程题,按点并行可能破坏跨点的逻辑依赖,影响生成质量。因此该模块设计为可插拔:系统可自动判断或让用户选择是否启用(paper 中实验显示在 coding/math 类任务上 outline variant 的质量下降明显)。
5. Evaluation
A. Experimental Setups
模型与数据集
- 使用 Llama2 系列:Llama2-7B 与 Llama2-13B(均采用 INT4 量化以降低内存)。
- 使用三种 assistant-style 数据集评估生成质量:LiMA(用于延迟基准主要),Vicuna-80、WizardLM(用于评估生成质量)。
边缘设备与环境

- 三类 off-the-shelf 设备:Jetson Xavier NX(384-core Volta,8GB,20W)、Jetson TX2(256-core,8GB,20W)、Jetson Nano(128-core,8GB,10W)。
- 定义两种实验环境:Homogeneous Environment A(4×NX)与 Heterogeneous Environment B(1×NX + 2×TX2 + 1×Nano)。
- 带宽仿真:通过调整设备间带宽模拟 100Mbps/500Mbps/1Gbps 等不同网络状况,重点考察带宽受限下的行为。
基线 与 5 种最先进并行/协同方法比较:Sequence Parallelism (SP)、Megatron-LM (M-LM, tensor-parallel)、DeTransformer (DT, TP-based edge)、Galaxy(TP across MHA/FFN + SP in connecting ops)、EdgeShard(pipelined architecture)。论文对这些基线在 decoding 阶段统一采用了 naive token-by-token 生成(以便对比 Jupiter 在 decoding 加速方面的改善)。
B. End-to-End Performance
实验设置:从 LiMA 中抽样 prompts(平均 prompt 长度 ~260 tokens),max generation length = 64。测量端到端生成延迟(包括 prefill 与 decoding)。结果见 Table IV;下为重要观察与解释(结合表格数据):
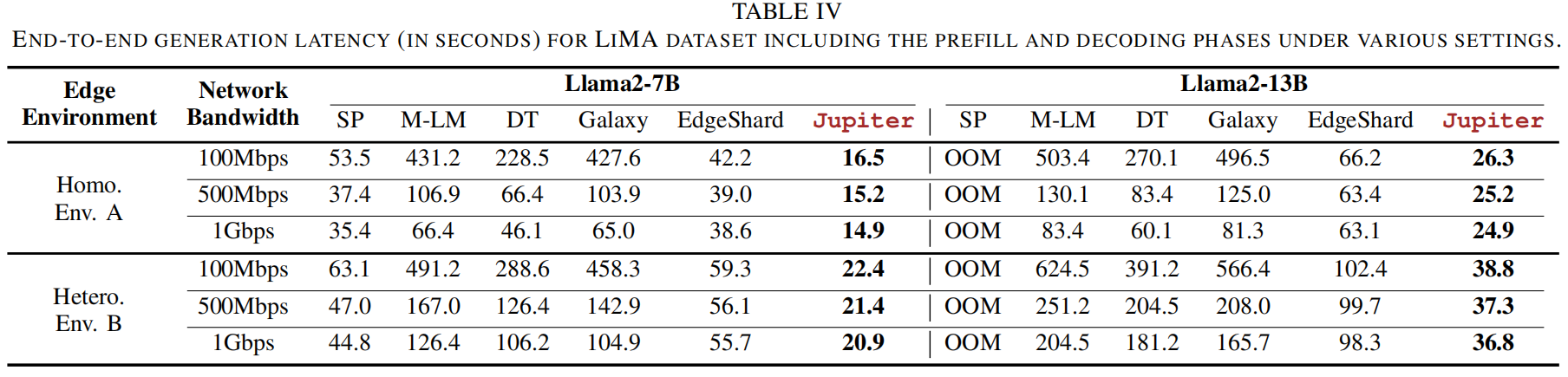
关键结果与解读:
- 在多种带宽与设备拓扑上,Jupiter 恒显著优于所有基线。
- 对比 TP-based baselines(M-LM、DT、Galaxy),Jupiter 在某些设置下可达 26.1× 的延迟缩减(主要在带宽受限、模型较大时通信成为瓶颈的场景)。
- 与 SP(sequence-parallel)对比,Jupiter 最多可达 3.3× 的提升;SP 在 decoding 阶段退化为单设备执行,导致资源浪费且在 13B 下出现 OOM。
- 与纯 pipeline 方法(EdgeShard)相比,Jupiter 凭借 intra-sequence 并行与 decoding 的两项加速技术(speculative + outline)可实现至多 2.7× 的优势。
- Heterogeneous 环境下(Env B),Jupiter 依然稳健,原因在于 parallelism planning 能考虑设备异构并做到负载均衡。
图形观察(Fig.10/11)
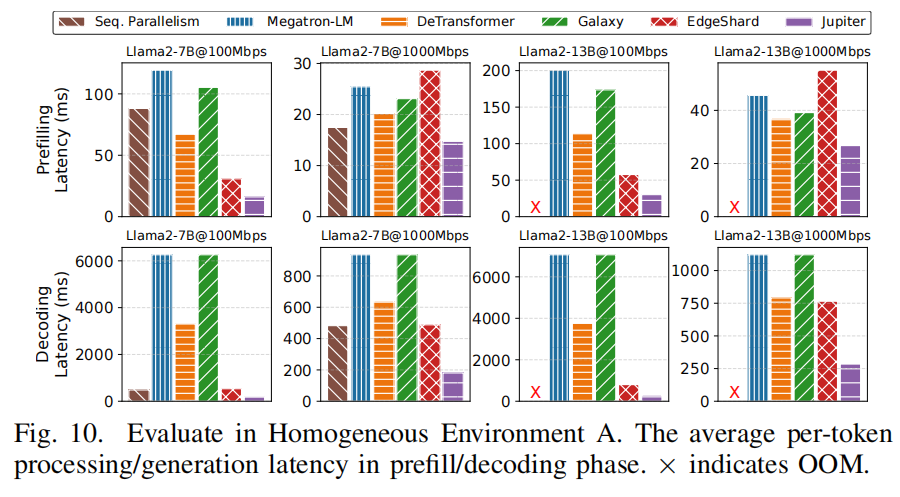
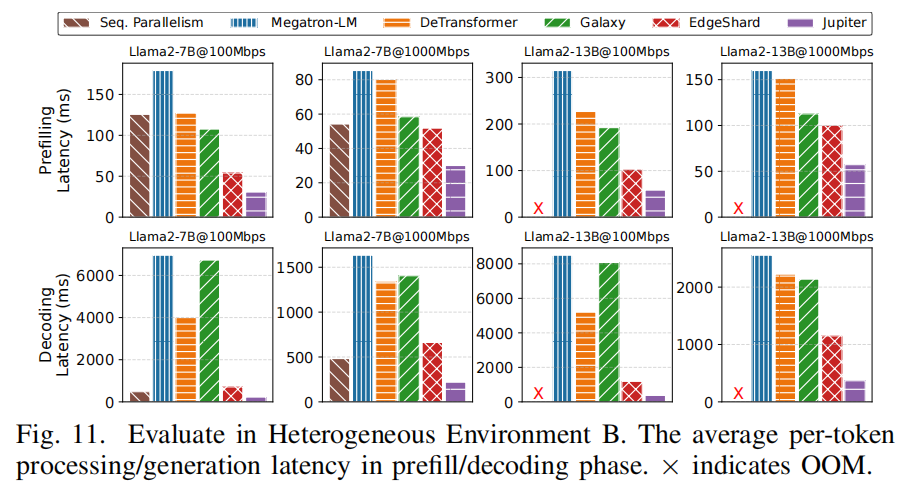
- Fig.10(Homogeneous)与 Fig.11(Heterogeneous)分别展示 prefill 与 decoding 阶段的 per-token 延迟:Jupiter 在 prefill 上有稳定的 1.4×–7.4× 提速,而在 decoding 阶段提升更为显著(2.9×–33.2×),表明 decoding 部分的优化(speculative + outline)为本方法带来最大收益。
C. Phase-Wise Analysis
论文把 prefill 与 decoding 分开分析,具体观察如下(并补充更细的解析):
Prefill Phase(逐 token prefill 延迟)
- 由于 intra-sequence pipeline 的子序列并发注入,prefill 的 time-to-first-token 能被显著缩短;但子序列划分策略需要平衡段长以避免 GPU/NPU under-utilization。Jupiter 的动态规划方案根据 profiling 自动选择切分数与每段长度,从而在不同 prompt 长度下均有较佳表现(见 Fig.10 左侧图)。
Decoding Phase(逐 token 生成延迟)
- decoding 优化是 Jupiter 的强项:speculative decoding 能减少 LLM 必须进行的严格验证步骤次数,而 outline 并行能将多个“点扩展”并发送入流水线。综合使 per-token generation latency 大幅下降(Fig.10/11 右侧)。
- 对于 TP/SP 等方法,decoding 时通信/同步频次高导致通信占比放大,从而在带宽受限时表现更糟。Pipeline-only 方法无法并行利用多台设备来扩展 decoding(单序列下),因此收益有限。Jupiter 则能同时兼顾流水线内存拼装与并行化生成。
D. Scalability
4-node homogeneous NX 集群实验(Fig.12):
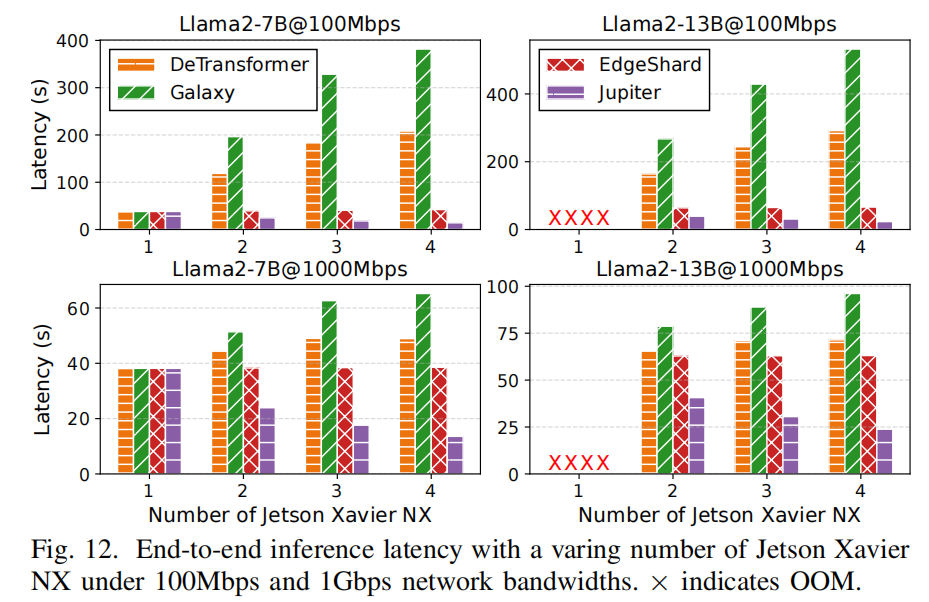
- 在节点数量增加时,Jupiter 的端到端延迟显著下降,且即使在 100Mbps(带宽受限)下也展示良好可扩展性(论文报告最高达 23.7× 缩减相对某些基线)。这体现了采用 pipeline(邻居激活传输)策略相对于 TP/SP 的通信优势,以及并结合 intra-sequence 并行与 decoding 并行化的设计,能让更多设备实际参与到并行工作中而非空闲等待。
E. Decoding Speedup and Generation Quality Assessment
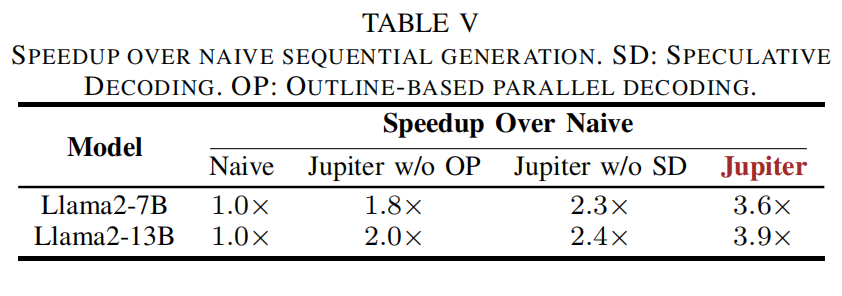
1) Decoding Speedup Analysis(消融)
- 论文做了 ablation:分别禁用 Outline-based Parallelism(OP)或 Speculative Decoding(SD),比较速度提升(见 Table V)。结果显示二者均贡献明显:整体 speedup 可达 3.6×(7B)到 3.9×(13B),其中 SD 和 OP 各自能单独带来 1.8–2.4× 级别的 speedup。表格如下(简述):
| Model | Naive | Jupiter w/o OP | Jupiter w/o SD | Jupiter |
|---|---|---|---|---|
| Llama2-7B | 1.0× | 1.8× | 2.3× | 3.6× |
| Llama2-13B | 1.0× | 2.0× | 2.4× | 3.9× |
这说明 SD 与 OP 有互补性:SD 在加速 token 数量上直接降步数,OP 在并行扩展多个输出点上提升设备并行利用。
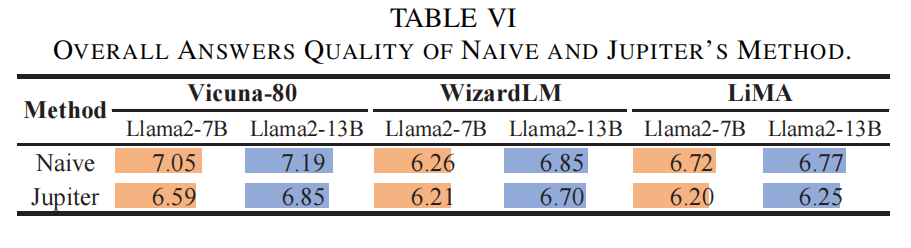
2) Generation Quality Assessment(质量评估)
-
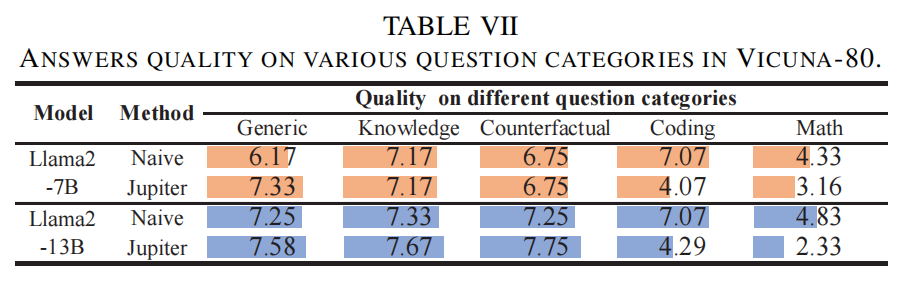
采用 FastChat(以 GPT-4o 作为评分器)对 Naive(逐token)与 Jupiter 的 outline-based parallel generation 在 Vicuna-80、WizardLM、LiMA 三数据集上做质量评分(1–10)。总体上,outline 法在多数任务维持接近的质量,但整体略低于 Naive(表 VI)。论文进一步对 Vicuna-80 做了分类评估(Generic, Knowledge, Counterfactual, Coding, Math),发现:
- Generic/Knowledge/Counterfactual:outline 方法表现可比甚至优于 naive(说明在自由文本或事实类任务中先生成大纲并行扩展不影响质量,可能反而提升结构性)。
- Coding/Math(需要逐步链式推理):outline 方法明显劣于 naive(在这些任务中点之间有强依赖,分点并行破坏了链式上下文连续性)。
-
因此论文建议将 outline-based decoding 作为可插拔模块:在适合的任务类型自动启用或由用户决定,否则回退到 speculative-only 或 naive 策略以避免质量损失。
6. Conclusion
- Jupiter 提出并实现了一个以 pipeline 为原则的协同边缘 LLM 推理系统,系统化地解决了 prefill 与 decoding 两大阶段的并行化瓶颈。
- 通过 intra-sequence pipeline parallelism + resource-aware dynamic programming planning(解决层划分与序列划分)+ speculative decoding + outline-based pipeline decoding 的组合,Jupiter 在现实边缘设置下显著降低端到端延迟(最高 26.1×),且在带宽受限、设备异构场景中仍保持鲁棒性。
- 文章同时指出 outline 并行在某些类任务上会牺牲质量,因此把该模块做成可插拔并提供判别机制。总的来说,Jupiter 为边缘场景下生成式 LLM 的实用化部署提供了明确且可复现的系统设计与工程实现路线。