
Conference: NeuIPS'25 Oral
GIthub: https://github.com/snu-mllab/KVzip
1. Motivation
大型语言模型(LLMs)在长上下文推理过程中,其 Key/Value(KV)缓存会随上下文长度线性增长,从而带来如下两个核心挑战:
-
显存占用随 $n_c$ 线性扩张 例如 Qwen2.5-14B 在 120k context 下需 33GB KV Cache(论文 Figure 1)。
-
解码阶段 Attention 的延迟随 KV 数量线性增加 解码 token 的每一步都需对全部 KV 执行 attention,因此减少 KV 数量是最直接的加速策略。
已有 KV 压缩方法(如 SnapKV / PyramidKV)依赖 query-aware importance:
- 每个 query 都要重新 prefill 来获取 attention pattern。
- 得到的重要 token 只对当前 query 有效,不可复用。
论文的动机部分指出:
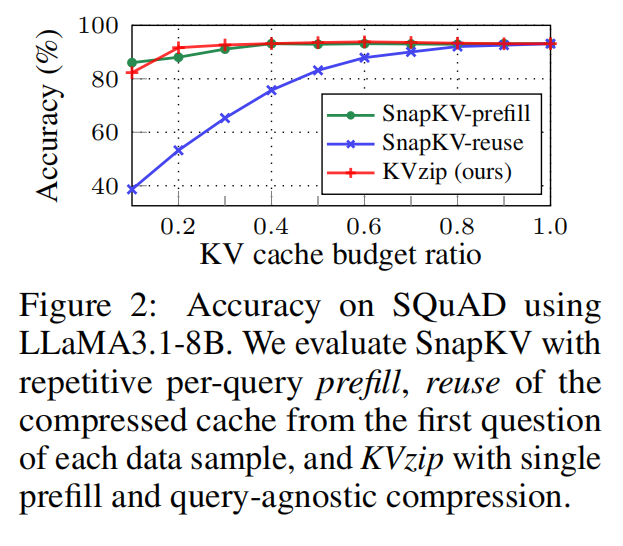
在 multi-query 复用场景中,query-aware 方法的性能快速退化。
因此本论文目标是:
构建一种 query-agnostic、一次预处理、多 query 复用 的 KV Cache 压缩方法。
2. Challenge
2.1 为什么 query-aware KV importance 无法泛化?
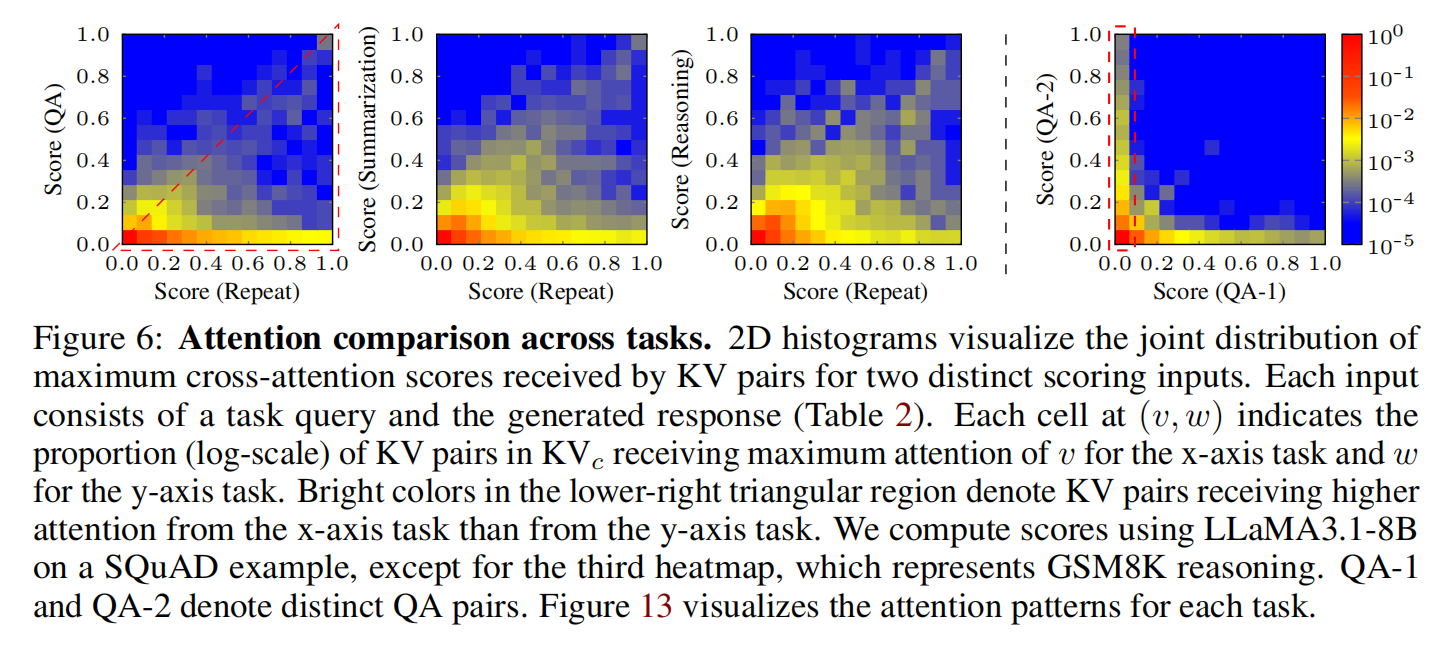
- 同一 context,在 QA、Summarization、Reasoning 三个任务中重要 token 完全不同。
- 而且不同 query 的 cross-attention pattern 差异巨大。
论文通过对多个 query 的 attention map(Figure 6, “QA-1 vs QA-2”)展示:
对同一段 context,两个相似的 QA query 也可能访问完全不同的 token。
导致:
- 基于 query 的 token scoring 难以复用到另一个 query。
- 每次 query 都需重新 prefill,代价巨大。
2.2 为什么 prefill attention 不能用于衡量 token 重要度?
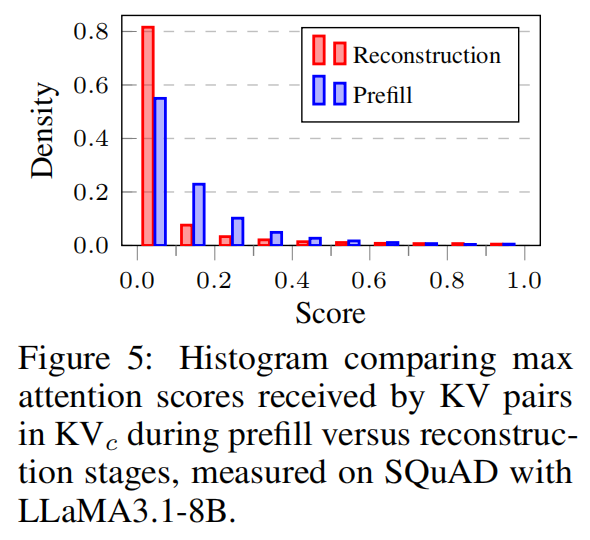
- Prefill attention 在 key 维度上几乎均匀分布(dense & flat)。
- Prefill 的主要作用是在 decoder self-attention 中构建位置依赖,而非找到语义关键 token。
因此:
Prefill attention 缺乏区分度,不能作为 token 重要性的 proxy。
3. Contribution
-
提出 KVzip:一种基于 context reconstruction 的 query-agnostic KV cache compression 方法 KVzip 利用“重复 prompt + 重构任务”诱导模型自动暴露其“最稳定的语义路径”。
-
提出 Reconstruction Attention Score(RAS)作为 token importance RAS 能跨不同任务、不同 query 保持一致性(。
-
提出 Chunked Scoring 用分块避免构建 $O(n_c^2)$ 的稠密 attention 矩阵,实现线性复杂度的 scoring。
-
完成系统级优化且与多种推理系统兼容
- KV quantization(如 QServe 的 KV4)
- Head-level eviction
- 与 DuoAttention 兼容或替代
-
在 LLaMA3.1 / Qwen2.5 / Gemma3 多种模型 + 12 类任务上验证 在 50–70% eviction 下几乎无损。
4. Method
4.1 Method Overview
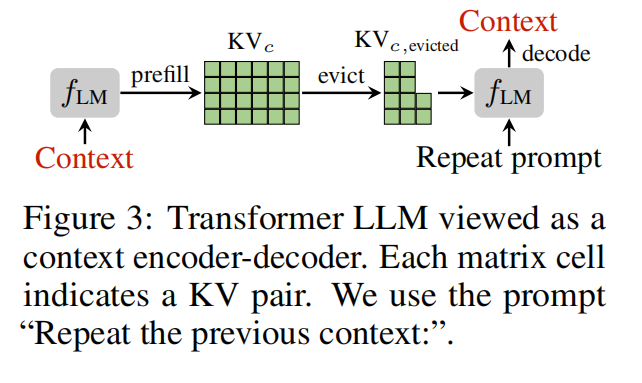
Step 1. 执行普通 prefill: 得到 context 的 KV Cache:
- $K_c \in \mathbb{R}^{n_c \times d}$
- $V_c \in \mathbb{R}^{n_c \times d}$
Step 2. 构造输入:
Repeat Prompt + 原始 context
Repeat Prompt 的作用是让模型执行 reconstruction:
- 模型会尝试复原之前的 context
- 强迫模型访问其“核心语义路径”
Step 3. 构造 reconstruction attention
论文强调 reconstruction attention 的特殊性:
- 类似语言建模,但目标是“模仿之前内容”
- 因而 attention 会更多地指向语义关键 token
Step 4. 基于 reconstruction attention 计算 token importance
Step 5. 依据 score 排序执行 eviction,得到压缩后的 KV。
4.2 Repeat-Prompt-Based Reconstruction Attention
为什么是 Repeat Prompt?为什么有效?
论文通过三组实验验证:
(1)Prefill attention 对所有 context token 关注近似均匀
- Attention 分布无明显峰值
- 无法识别哪些 token 在推理中被频繁访问
(2)Reconstruction Attention 与多任务 attention pattern 高重叠
论文 Figure 6 显示:
| Task | Reconstruction Attention 重叠率 |
|---|---|
| QA | 高 |
| Summarization | 高 |
| Reasoning | 高 |
即:
Reconstruction attention 能稳定捕捉语义核心 token,且这些 token 也是多数任务所需的关键 token。
(3)为什么“重复”而不是使用相同 prompt 一次?
论文解释:
- 单次 prompt 无法提供足够 signal 让模型完全重构上下文。
- 重复 prompt 等价于构造更多 query,使模型形成稳定 attention。
多次重复(论文默认为 $G=8$)可以:
- 多个 query 共同投票得到更 robust 的 score
- 降低单个 query 带来的随机波动
4.3 KV Importance Scoring
4.3.1 Reconstruction Attention
在第 $l$ 层、第 $h$ 个 head:
-
Query: $$Q_{l,h} \in \mathbb{R}^{G \times n_{in} \times d}$$
-
KV Cache(context 部分): $$K_{l,h} \in \mathbb{R}^{n_c \times d}$$
Reconstruction attention:
$$ \bar{A}{l,h} = \mathrm{Softmax}\left( Q{l,h} K_{l,h}^{\top} \right) $$
这是标准 Attention,但我们只关心指向 context 的片段(跳过重复 prompt)。
4.3.2 Importance Score
论文定义对 token $j$ 的重要度为:
$$ S_{l,h}[j] = \max_{g,i}, \bar{A}_{l,h}[g, i, j] $$
含义:
- 对所有 Repeat Prompt($g$ 个)
- 所有 query token($i$ 个)
- 找该 token 被访问的最大 attention score
为什么取最大而非平均?
论文理由:
- 重构语义时某些 query 会特别强烈依赖某些 token
- 平均可能平滑掉重要 token 的峰值
- 最大值能更清晰反映“至少有一次非常重要”
论文在 Ablation(Figure 16)验证: Replacing max with mean 会显著下降性能。
4.3.3 Layer Aggregation & Head Aggregation
论文使用:
- layer-wise importance:可设某些层更重要(可选)
- head-wise importance:可配合 DuoAttention 做 head-level eviction
默认将所有 head importance 通过 max 聚合:
$$ S[j] = \max_{l,h} S_{l,h}[j] $$
最终排序决定保留哪些 token。
4.4 关键技术难点:Quadratic Attention Cost
FlashAttention 的限制:
-
它 block-wise 计算 attention,但不会保留完整的中间结果
-
KVzip 必须获得完整归一化后的 attention 矩阵
- 需 softmax 归一化
- 需按 query dimension 执行 $\max$
FlashAttention 得不到:
$$ \max_{i} \mathrm{Softmax}(QK^\top) $$
只能得到最终结果 $V$,不可恢复 attention。
因此 KVzip 必须重新设计计算方式。
4.5 Chunked Scoring
4.5.1 Chunking 原理
将 context 拆成大小为 $m$ 的块:
$$ \text{context} = [C_1, C_2, …, C_{n_c/m}] $$
对每个 chunk $C_k$:
- 构造只包含 $C_k$ 的局部 KV
- 执行 reconstruction attention
- 得到 chunk 内局部分数
- 最终合并所有 chunk 的 score
4.5.2 为什么 chunking 不会破坏语义?
论文解释:
- Reconstruction attention 的 key 是整个 context,但我们是做 重要度建模,非推理
- 为 token j 计算 score,只需其所在 chunk 内的查询访问情况
- Reconstruction query 实际访问 token 时主要依赖其附近语义
实验(Figure 15)证明:
只要 chunk ≥ 2048,其重要度几乎不变。
4.5.3 Complexity Analysis
单个 chunk:
- reconstruction cost:$O(m^2)$
总 chunk 数:
- $n_c/m$
总成本:
$$ O(m^2 \times n_c/m) = O(m n_c) $$
对于固定 $m$(论文默认 $m=2048$):
总成本随 context 长度线性增长,能轻松处理 128k–512k 长上下文。
4.5.4 Memory Usage
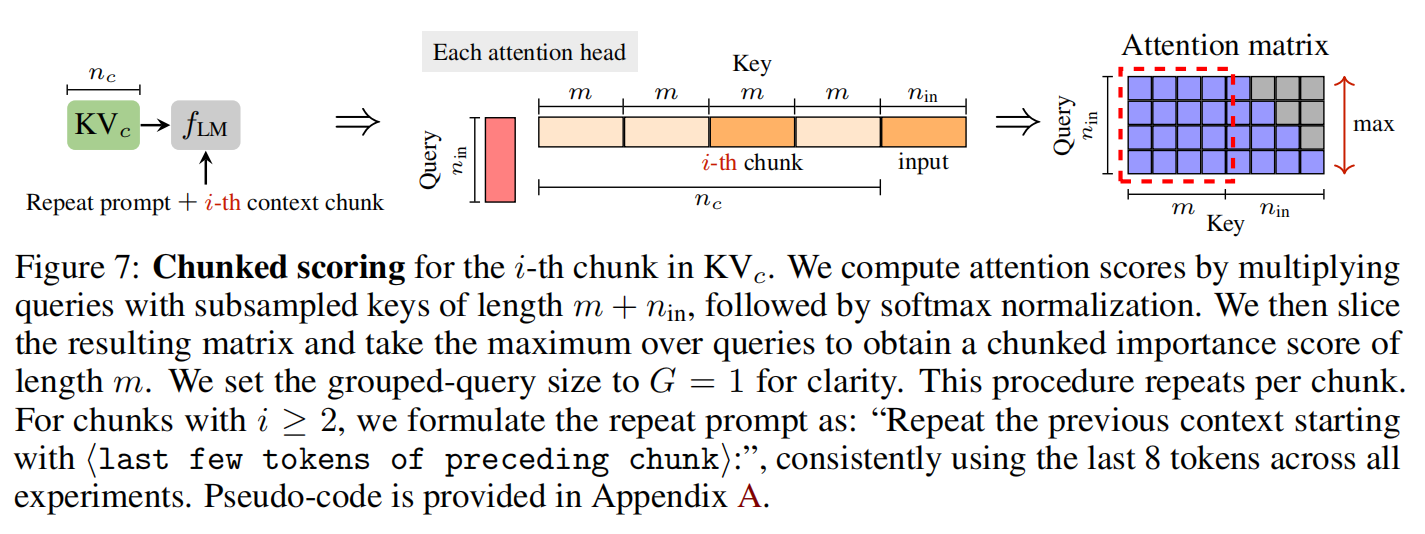
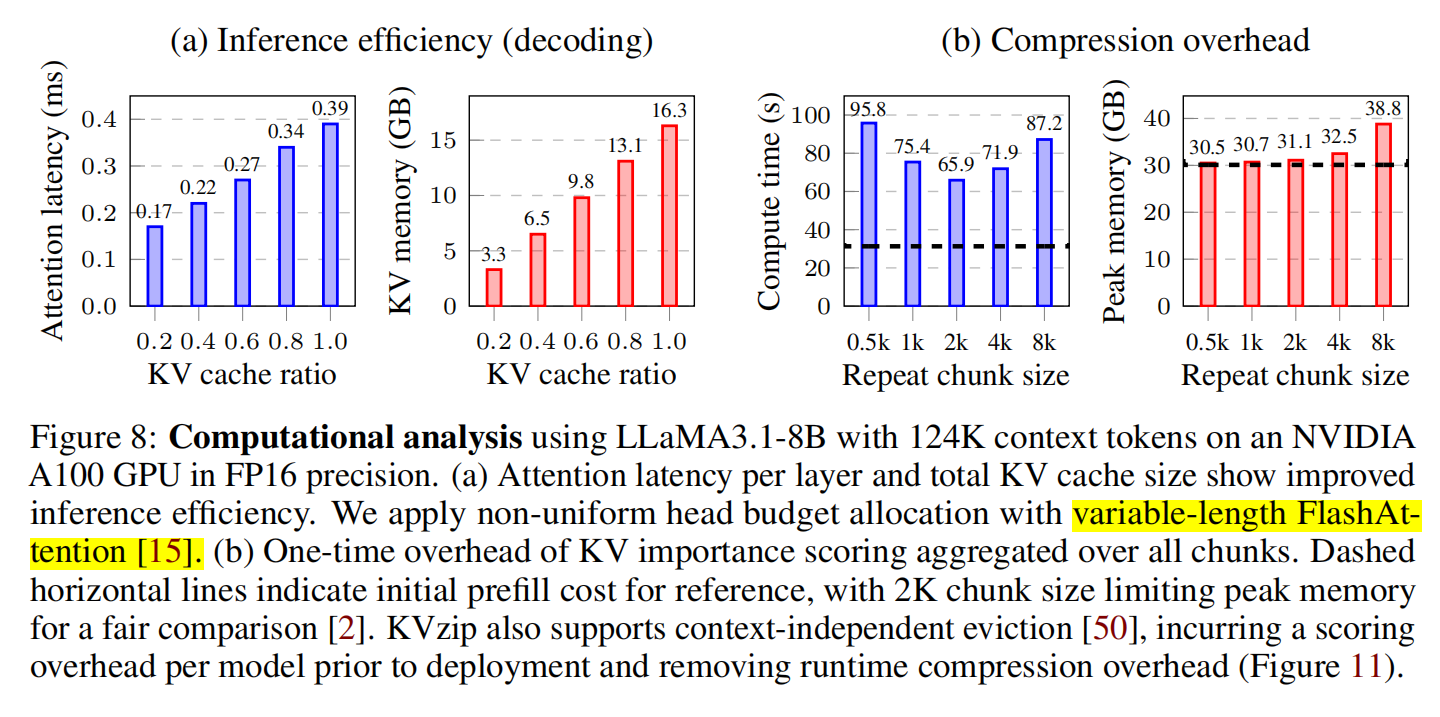
- Chunked scoring 的额外显存 ≈ 1.8%
- 计算耗时 ≈ 2× prefill
对于 offline/online 初次压缩都可接受。
5. Evaluation
5.1 实验设置概览
论文覆盖 12 类任务,包括:
- QA(TriviaQA, HotpotQA)
- Summarization(GovReport)
- Reasoning(GSM8K, MATH)
- Needle-in-a-Haystack(NIAH)
- QA retrieval(LongBench)
实验模型包括:
- LLaMA 3.1(8B / 70B)
- Qwen2.5(7B / 14B)
- Gemma 3
上下文长度测试:
- 32k、64k、128k
所测 eviction ratio:
- 30% / 50% / 70%(default)/ 90%
5.2 Cross-model Results(Figure 9–10)
(1)同样 eviction 下,KVzip 在所有任务上均接近无损
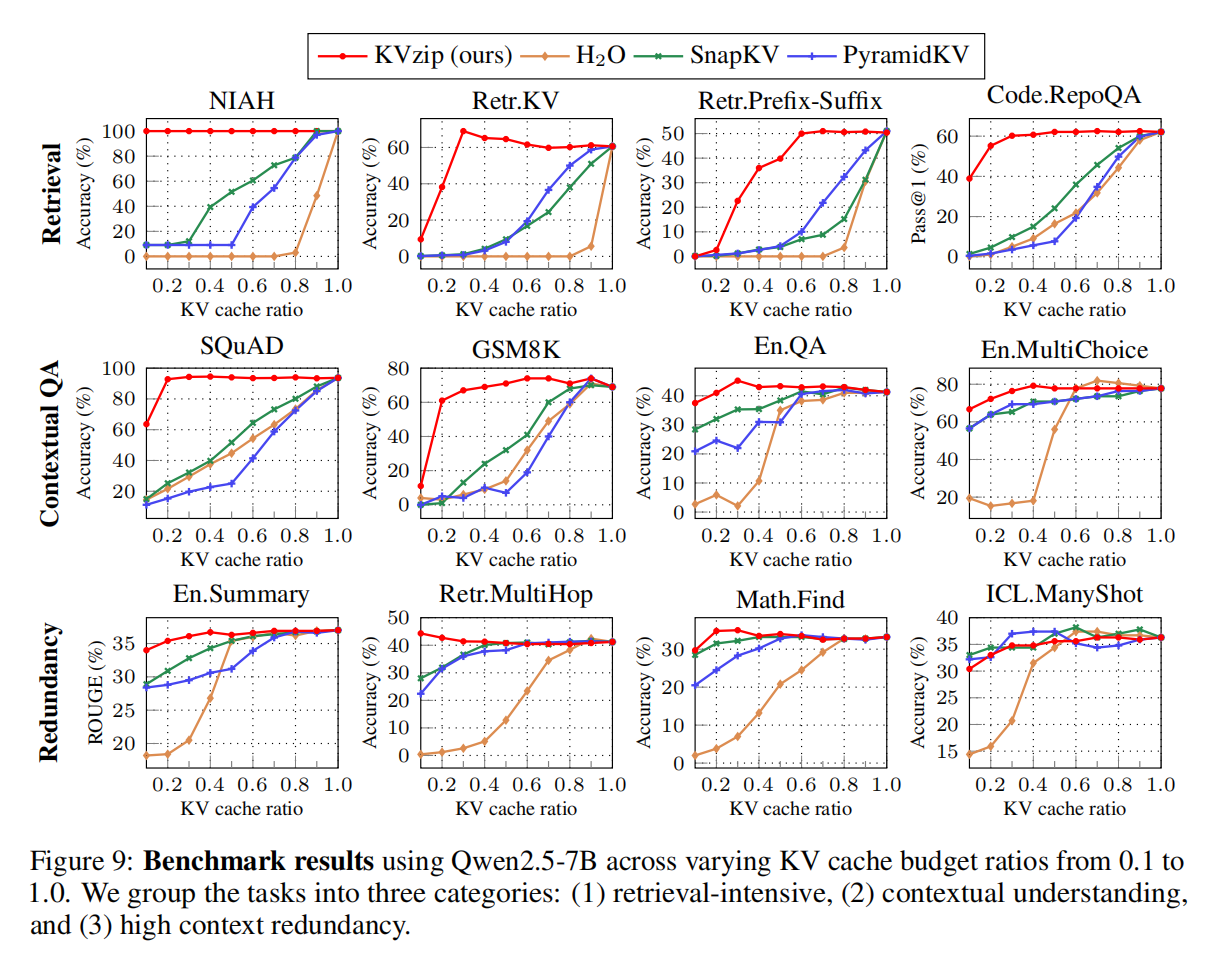
- 在 70% eviction 下,所有任务下降 < 2%
- SnapKV 在 30% eviction 下降超过 10–20%
- PyramidKV 在 50% retention 下就出现显著退化
(2)不同模型之间的稳定性
论文测试:
- LLaMA 3.1(decoder-only)
- Gemma 3(Google)
- Qwen2.5(阿里)
结论:
无论架构、embedding 维度、attention 方式如何变化,reconstruction attention 均稳定有效。
(3)多 query 场景中的能力
Figure 2(multi-query)证明:
- Query-aware 方法几乎完全失效
- KVzip 因 query-agnostic,可一次压缩、多次复用
5.3 KV Quantization Compatibility(QServe)
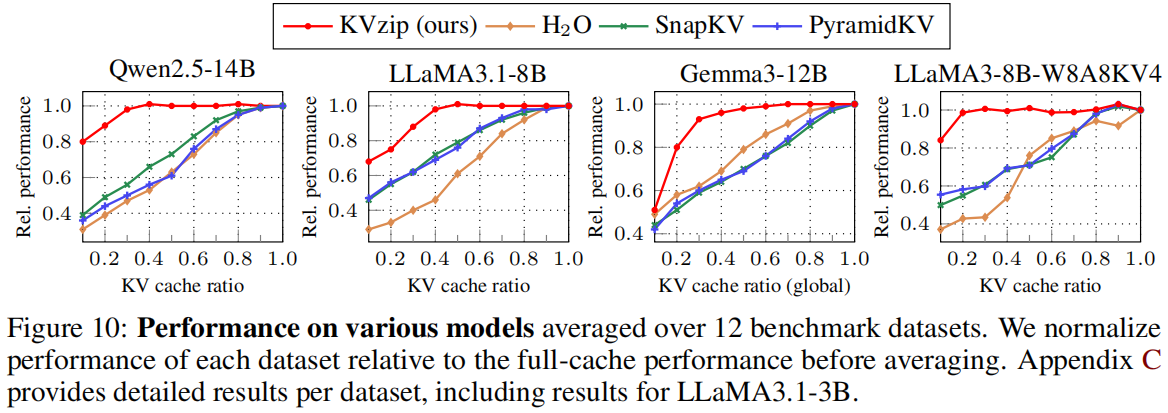 论文将 KVzip 与 QServe W8A8KV4 结合(Figure 10):
论文将 KVzip 与 QServe W8A8KV4 结合(Figure 10):
- 原 KV Cache:16.3 GB
- 经过 W8A8KV4:4.5 GB
- 再通过 KVzip 70% eviction:1.2 GB
- 性能损失 < 2%
这是论文最具工程意义的结果:
KVzip + Quantization = 边缘设备可运行超长上下文 LLM。
5.4 与 DuoAttention 的关系
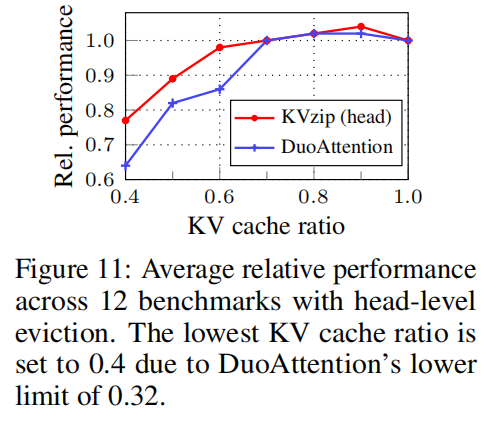 KVzip importance 可用于 head-level eviction:
KVzip importance 可用于 head-level eviction:
- 比 DuoAttention 更稳定,因为它不依赖大规模 profiling
- 在 70% eviction 下更高得分
论文说明 KVzip 即可替代 DuoAttention,也可作为其先验 score。
5.5 Ablation Study
5.5.1 是否必须重构整个 context?(Figure 12)
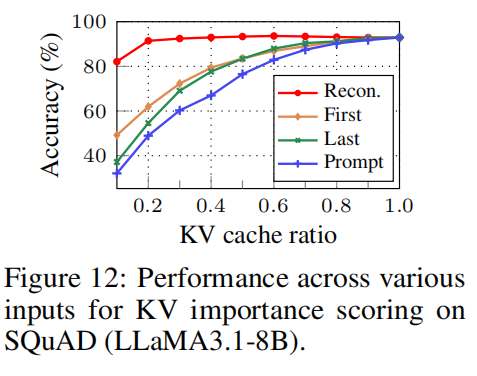 论文测试:
论文测试:
- 只重构部分同样上下文
- 仅使用前/后半部分
- 重构层数减少(只用 top layers)
结果:
- Token importance 显著下降
- 只 reconstruct 局部会丢失 global semantics
5.5.2 Repeat Prompt 数量 G 的影响(Figure 13)
- 当 $G \ge 6$ 时 score 稳定
- $G < 4$ 会导致噪声较大
5.5.3 Reconstruction Prompt 长度 $n_{in}$(Figure 14)
- 当 $n_{in} \ge 512$ 性能基本稳定
- 过短会导致模型难以重构完整 context
5.5.4 Chunk size(Figure 15)
- $m = 2048$ 是推荐值
- $m < 1024$ 会破坏 importance
5.5.5 Softmax 的必要性(Figure 16)
论文测试不用 softmax 的替代(如 raw logits):
- 性能急剧恶化
- Softmax 是必须的归一化步骤
6. Conclusion
在不修改你原文的基础上进一步升华总结:
KVzip 提出一种 query-agnostic、可泛化、可复用、成本可控、质量稳定 的 KV 压缩框架,其关键技术包括:
-
Repeat-prompt-based context reconstruction 诱导稳定 attention pattern。
-
Reconstruction Attention Scoring(RAS) 获得跨任务一致的通用 token importance。
-
Chunked Scoring(线性复杂度) 支持 128k–512k 长上下文压缩。
-
与量化、head-level eviction、speculative decoding 兼容
-
在 50–70% eviction 下几乎无损 显著优于所有 query-aware baseline。
这使得 KVzip 在:
- 云数据中心(multi-query serving)
- 边缘部署(KV quantization + eviction)
- 长上下文应用(RAG、文档 QA)
等场景都具备实用价值。
这是一个非常深入且切中要害的问题。KVzip 之所以不只使用 “Repeat Prompt”(复述提示词),而是将 Prompt + 原始 Context 拼接在一起作为输入,主要是出于**计算效率(并行化)和评分准确性(Teacher-Forcing)**的考虑。
以下是基于论文的详细解释:
1. 核心原因:利用 Teacher-Forcing 实现并行计算
如果只输入 “Repeat the previous context:” 让模型去生成,模型必须进行自回归生成(Autoregressive Generation),即生成第一个 token,再用它生成第二个… 如此循环。
- [cite_start]问题:对于长上下文(例如 100K tokens),逐个生成这 100K tokens 的速度极慢,且计算成本极高,这在实际应用中是不可接受的 [cite: 120]。
- [cite_start]解决方案:通过将 Repeat Prompt 和 Context 拼接在一起作为输入(Input),KVzip 利用了 Teacher-Forcing 机制 [cite: 143]。
- 在这种模式下,模型在预测第 $t$ 个 token 时,已经能够看到真实的第 $t-1$ 个 token(因为它们就在输入里)。
- [cite_start]因此,模型可以在**一次前向传播(Single Forward Pass)**中并行计算出所有位置的注意力分数,而不需要真的逐个生成文本 [cite: 143]。
2. 评分机制:模拟“向后看”的注意力
KVzip 的核心逻辑是计算**“为了重建上下文,当前的查询(Query)需要关注缓存中的哪些键值对(KV pairs)”**。
- [cite_start]输入构造:输入序列长度为 $n_{in} = n_{prompt} + n_c$(提示词长度 + 上下文长度)[cite: 145]。
- 交叉注意力:这个拼接后的输入经过模型时,其产生的 Query($Q$)会去查询缓存中的 Key($K$)。
- [cite_start]具体的逻辑是:输入中拼接的 Context 部分实际上充当了“正在生成的 token”的角色,它们回头去关注 $KV_c$(缓存的上下文),由此产生的**最大交叉注意力分数(Max Cross-Attention Score)**即代表了该 KV 对的重要性 [cite: 144, 153]。
- 如果不加 Context,模型就没有具体的 Query 去“质询”缓存中的 Key,也就无法计算出准确的注意力分布来判断哪些 KV 对对于重建内容是必须的。
3. 实验验证:完整重建的必要性
论文作者在 Section 4.3 中专门分析了这一点,并进行了对比实验(见论文 Figure 12):
- [cite_start]对比设置:作者尝试了只用 “Prompt”(仅提示词)、“First”(提示词+前10%内容)、“Last”(提示词+后10%内容)以及 “Recon”(提示词+完整内容)来进行评分 [cite: 486]。
- [cite_start]结果:实验结果显示,只有 Recon(完整重建) 能够防止性能下降。仅使用 Prompt 或部分内容会导致模型无法准确识别关键 KV 对,从而在压缩后导致推理准确率大幅下跌 [cite: 487, 509]。
总结
简单来说,加上 Context 是为了作弊(Teacher-Forcing):让模型在一次计算中假装自己正在生成整个上下文,从而快速地通过观测其注意力分布来“偷看”哪些记忆片段是它完成这项任务所真正需要的。