
Conference: ICLR'25
Github: https://github.com/mu-cai/matryoshka-mm
1. Introduction

Large Multimodal Models (LMMs) such as LLaVA have shown strong performance in visual-linguistic reasoning. These models first embed images into a fixed large number of visual tokens and then feed them into a Large Language Model (LLM). However, this design causes an excessive number of tokens for dense visual scenarios such as high-resolution images and videos, leading to great inefficiency.
While token pruning and merging methods exist, they produce a single-length output for each image and cannot afford flexibility in trading off information density v.s. efficiency. 受到俄罗斯套娃(Matryoshka Dolls)概念的启发,本文提出 Matryoshka Multimodal Models (M³)。该模型学习将视觉内容表示为嵌套的视觉 Token 集合(nested sets of visual tokens),从而捕捉从粗糙到精细(coarse-to-fine)的多尺度粒度信息。
为 LMM 带来了几个独特的优势:
-
显式粒度控制 (Explicit Granularity Control): 推理时可以根据任务复杂度或计算预算,动态调整代表图像的 Token 数量。例如,简单场景用少量 Token,复杂场景用多量 Token。
-
数据集粒度分析框架: 研究发现 COCO 风格的基准测试仅需约 9 个视觉 Token 即可达到与使用全部 576 个 Token 相当的准确率。
-
性能与效率的最佳权衡: 揭示了当前固定尺度表示与“神谕(Oracle)”上限(即针对每个样本自动选择最佳尺度)之间存在巨大差距。
2. M3: Matryoshka Multimodal Models
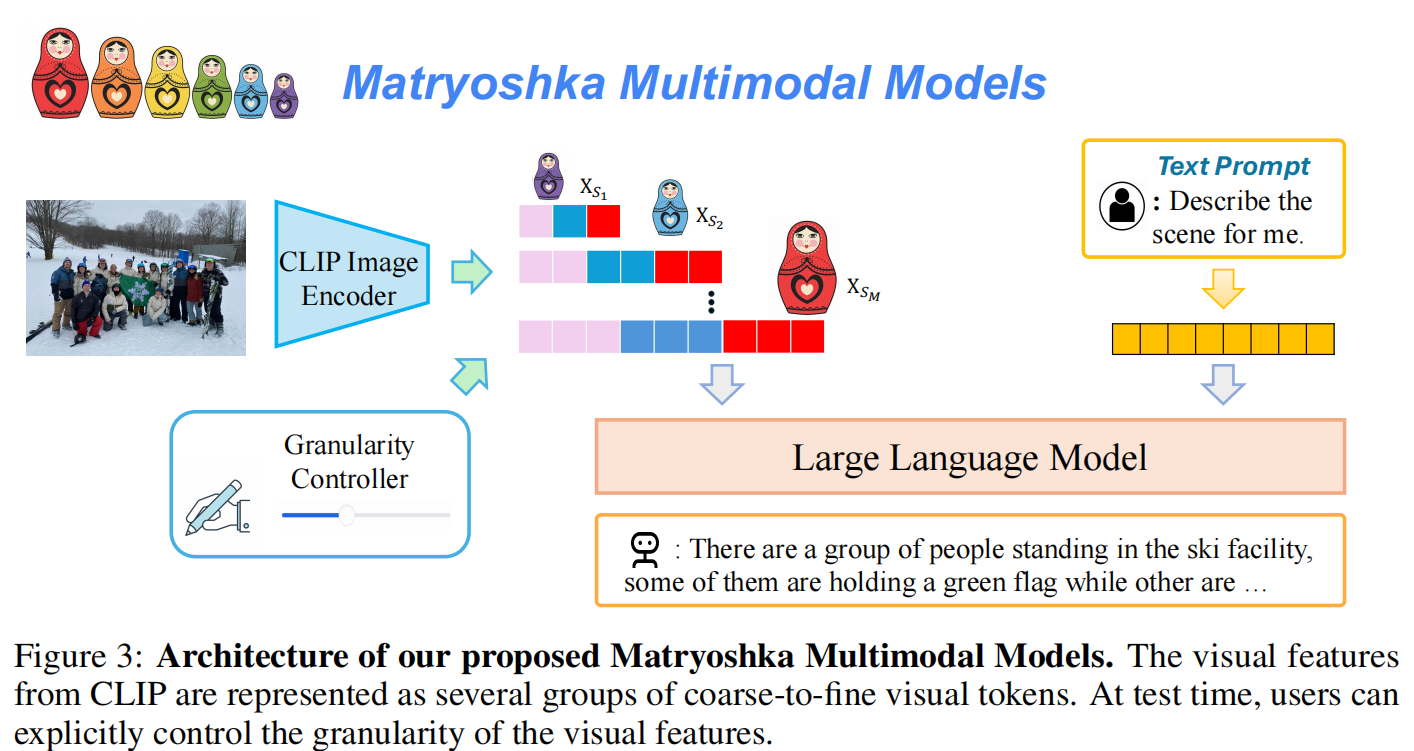
本节详细介绍如何构建和训练具有“套娃”结构的视觉 Token 序列。
2.1 嵌套视觉表示的设计 (Nested Visual Representation)
M³ 的核心目标是学习一组嵌套的视觉 Token 集合 $$ \mathcal{V}^{(1)} \subset \mathcal{V}^{(2)} \subset \cdots \subset \mathcal{V}^{(S)} $$ 并满足 $$ |\mathcal{V}^{(1)}| < |\mathcal{V}^{(2)}| < \cdots < |\mathcal{V}^{(S)}| $$
与传统的 Matryoshka Representation Learning (MRL) 不同(MRL 侧重于特征维度的嵌套),M³ 侧重于 Token 序列长度维度 的嵌套。
具体的池化层次结构 (Pooling Hierarchy):
模型采用预训练的视觉编码器(如 CLIP-ViT-L-336)将输入图像 $I$ 投影为一个二维视觉 Token 网格: $$ \mathbf{X}^{(0)} = f_{\text{vision}}(I) \in \mathbb{R}^{H \times W \times d} $$ 其中 $H=W=24$,因此初始 Token 数为 $24 \times 24 = 576$。
-
基础分辨率: 初始输入为 $$ |\mathcal{V}^{(0)}| = 576 $$ 个 Token。
-
多尺度下采样: 为了构建嵌套结构且不引入新的参数,模型在原始视觉 Token 上序列化地应用 平均池化 (Average Pooling):
-
应用 $2 \times 2$ 的平均池化(stride = 2): $$ \mathbf{X}^{(1)} = \text{AvgPool}_{2 \times 2}(\mathbf{X}^{(0)}) \Rightarrow |\mathcal{V}^{(1)}| = 12 \times 12 = 144 $$
-
再次应用 $2 \times 2$ 池化: $$ \mathbf{X}^{(2)} = \text{AvgPool}_{2 \times 2}(\mathbf{X}^{(1)}) \Rightarrow |\mathcal{V}^{(2)}| = 6 \times 6 = 36 $$
-
再次应用 $2 \times 2$ 池化: $$ \mathbf{X}^{(3)} = \text{AvgPool}_{2 \times 2}(\mathbf{X}^{(2)}) \Rightarrow |\mathcal{V}^{(3)}| = 3 \times 3 = 9 $$
-
最后应用全局平均池化: $$ \mathbf{X}^{(4)} = \text{AvgPool}_{3 \times 3}(\mathbf{X}^{(3)}) \Rightarrow |\mathcal{V}^{(4)}| = 1 $$
最终形成的 5 个 Token 尺度为: $$ |\mathcal{V}| \in {576,\ 144,\ 36,\ 9,\ 1} $$
这种方法不仅保留了空间结构,还确保了粗粒度 Token 直接由细粒度 Token 计算而来,实现了真正的“嵌套”。
Refer to Figure 3: Architecture of M³. CLIP 特征被表示为多组由粗到精的 Token。
2.2 训练目标 (Training Objective)
M³ 的训练通过在每个尺度 $s$ 上平均自回归下一个 Token 预测损失(next token prediction loss)来实现。
对于特定尺度 $s$,给定视觉表示 $\mathcal{V}^{(s)}$ 和文本问题 $Q$,模型最大化生成正确答案 $A = {a_1, \dots, a_T}$ 的似然函数: $$ \log p(A \mid Q, \mathcal{V}^{(s)}; \theta) = \sum_{t=1}^{T} \log p(a_t \mid a_{<t}, Q, \mathcal{V}^{(s)}; \theta) $$ 其中 $\theta$ 表示模型的所有可训练参数(包括视觉编码器和 LLM)。
最终的总损失函数定义为所有 $S=5$ 个尺度的平均负对数似然:
$$ \mathcal{L} = \frac{1}{S} \sum_{s=1}^{S} \left(- \sum_{t=1}^{T} \log p(a_t \mid a_{<t}, Q, \mathcal{V}^{(s)}; \theta) \right) $$
通过这一目标函数,M³ 能够在同一套权重下,学习让 LLM 同时适应从极简($1$ token)到极细($576$ tokens)的各种视觉输入。
3. Experiments
3.1 Experiment Settings
-
模型基座: 使用 LLaVA-1.5 和 LLaVA-NeXT 作为基础,LLM 骨干网络均为 Vicuna-7B。
-
训练细节:
- LLM 学习率:$\eta_{\text{LLM}} = 2 \times 10^{-5}$
- 视觉编码器学习率:$\eta_{\text{vision}} = 2 \times 10^{-6}$
-
硬件: 在 8 张 NVIDIA H100 GPU 上训练 1 个 epoch。
-
初始化: 从预训练好的 LLaVA 权重初始化,效果显著优于从零训练。
-
评价指标:
- 图像理解: POPE, GQA, MMBench, VizWiz, SEEDBench, ScienceQA, MMMU
- OCR: DocVQA, ChartQA, AI2D, TextVQA
-
视频理解:
- 开放式:MSVD-QA, MSRVTT-QA, ActivityNet-QA
- 多选题:NEXT-QA, IntentQA, EgoSchema
3.2 Image Understanding
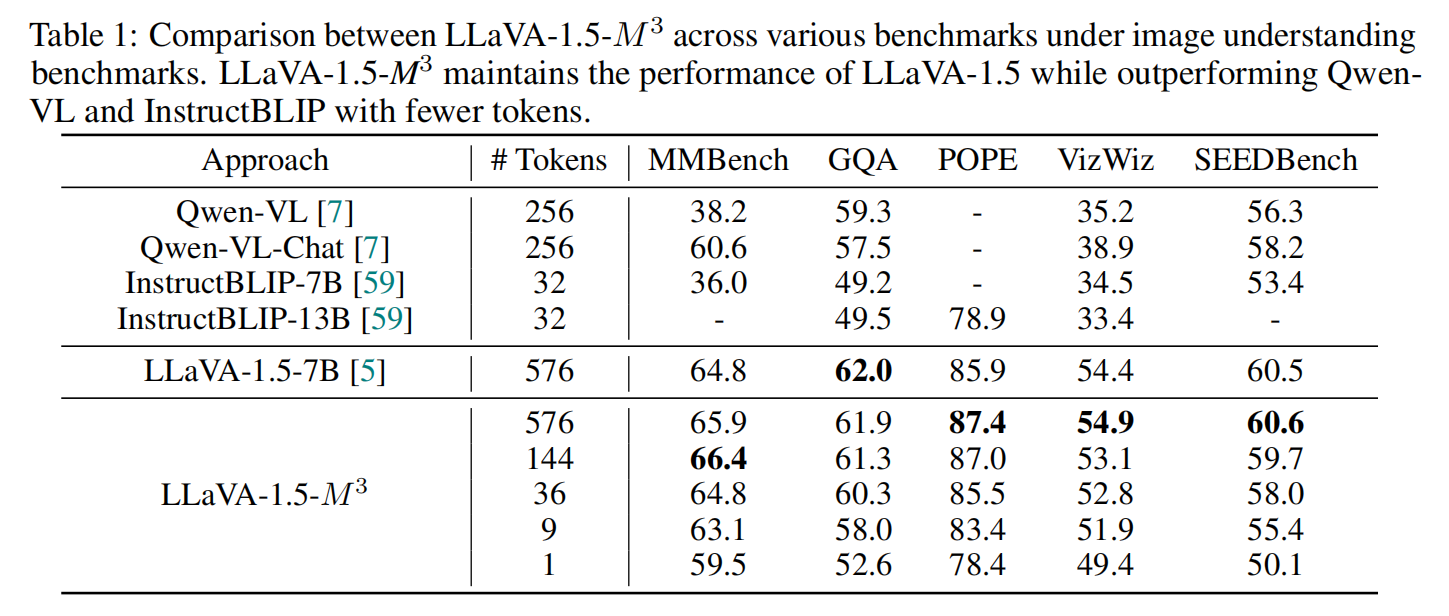
 在图像理解任务中,LLaVA-1.5-M³ 展示了极强的灵活性和性能:
在图像理解任务中,LLaVA-1.5-M³ 展示了极强的灵活性和性能:
-
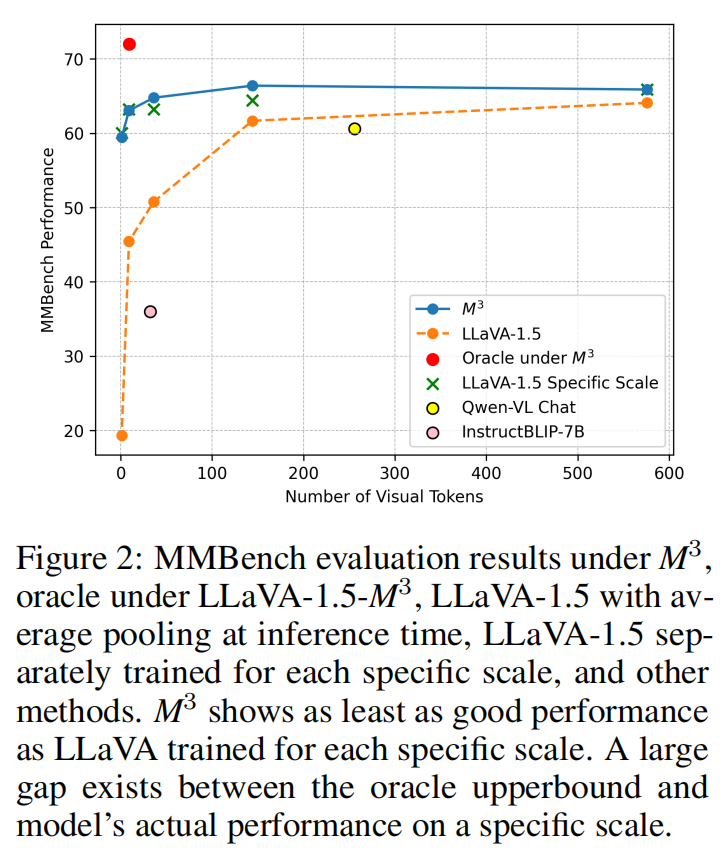
极简 Token 的强大性能: 在 MMBench 上,仅使用 $$ |\mathcal{V}| = 9 $$ 个 Token 的 LLaVA-1.5-M³ 即超过使用 $256$ Token 的 Qwen-VL-Chat;甚至在 $$ |\mathcal{V}| = 1 $$ 时也能达到相当性能。
-
全尺度覆盖: 如 Table 1 所示,在所有测试尺度上,M³ 均优于 InstructBLIP。
3.3 Video Understanding
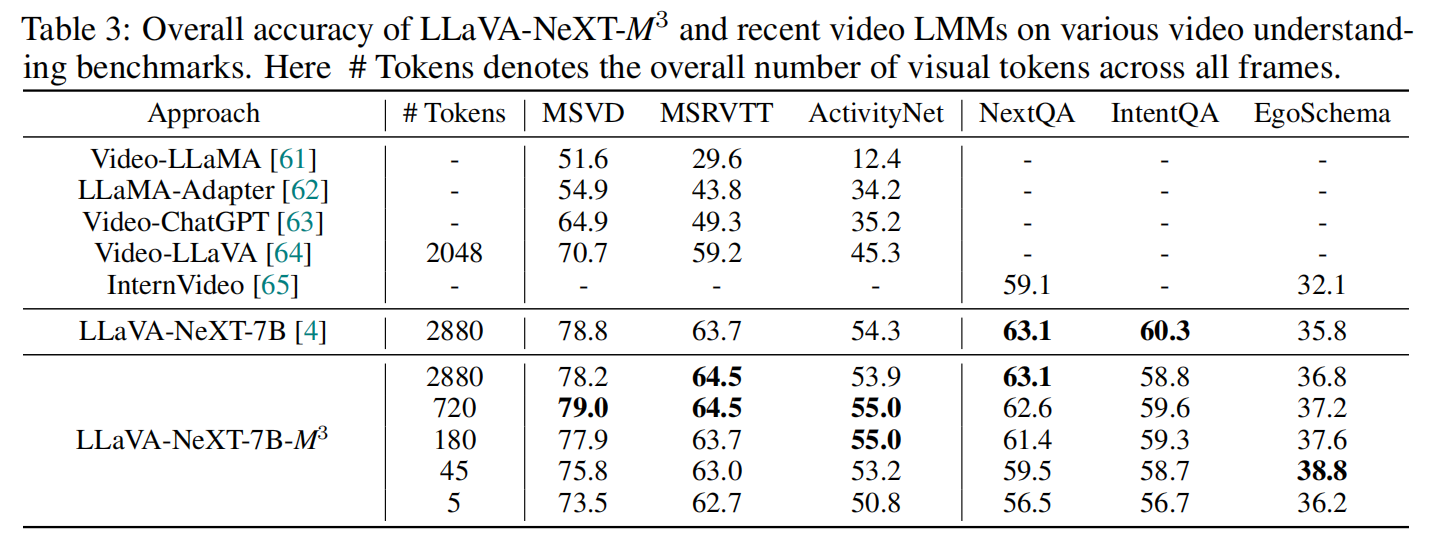 对于视频任务,Token 数量通常是效率瓶颈。M³ 能显著减少视频帧的 Token 需求:
对于视频任务,Token 数量通常是效率瓶颈。M³ 能显著减少视频帧的 Token 需求:
-
在多个视频 QA 基准测试中,使用较少 Token 的 M³ 达到了与全量模型相当的准确率。
-
在相同 Token 预算 $B$ 下: $$ \text{frames} \propto \frac{B}{|\mathcal{V}_{\text{per-frame}}|} $$ 例如:
- $1$ token / frame $\Rightarrow 2880$ frames
- $576$ tokens / frame $\Rightarrow 5$ frames
极大提升了长视频理解能力。
3.4 In-depth Analysis
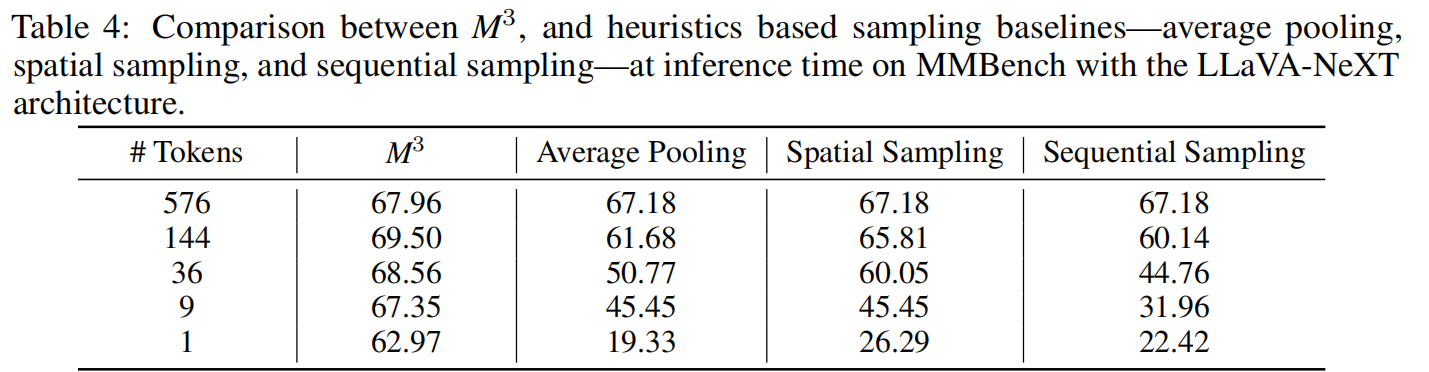
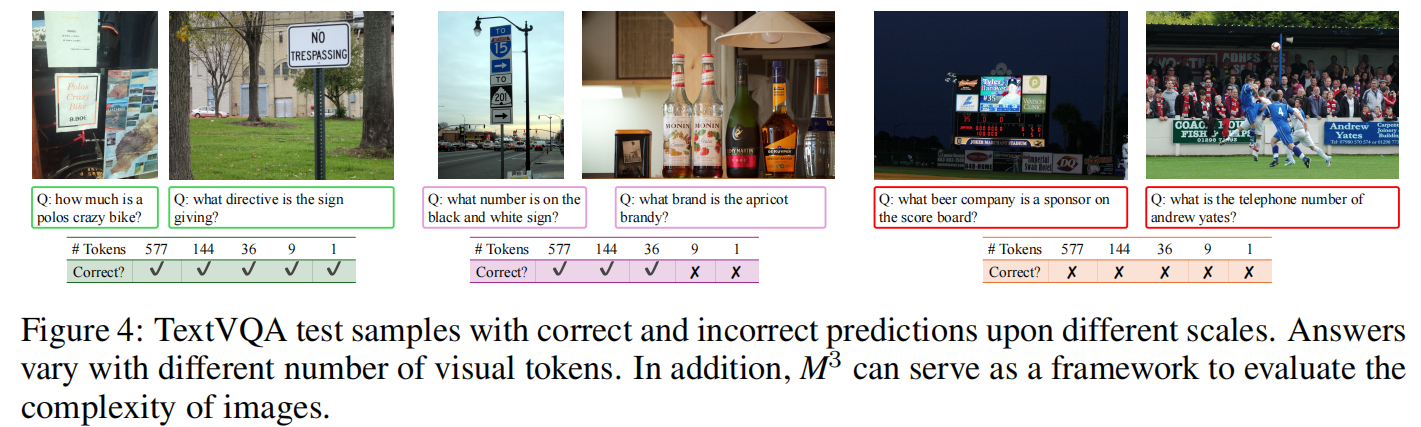
-
与启发式采样(Heuristics)对比: M³ 显著优于测试时直接进行平均池化、空间采样(Spatial Sampling)或序列采样(Sequential Sampling)。当 Token 数减少时,M³ 的性能退化非常缓慢。
-
上限 (Oracle Performance): 定义 Oracle 为: $$ s^\star = \arg\min_s {|\mathcal{V}^{(s)}| \mid \text{answer correct}} $$
-
惊人的发现: Oracle 模型平均仅使用 $$ \mathbb{E}[|\mathcal{V}|] = 8.9 $$ 个 Token,其性能比 $576$ Token 的 LLaVA-NeXT 高 8 个百分点。
-
零样本泛化 (Zero-shot generalization): 训练于 $24 \times 24$ 网格,推理扩展至 $48 \times 48$ 网格: $$ \mathbf{X} \in \mathbb{R}^{48 \times 48 \times d} $$
-
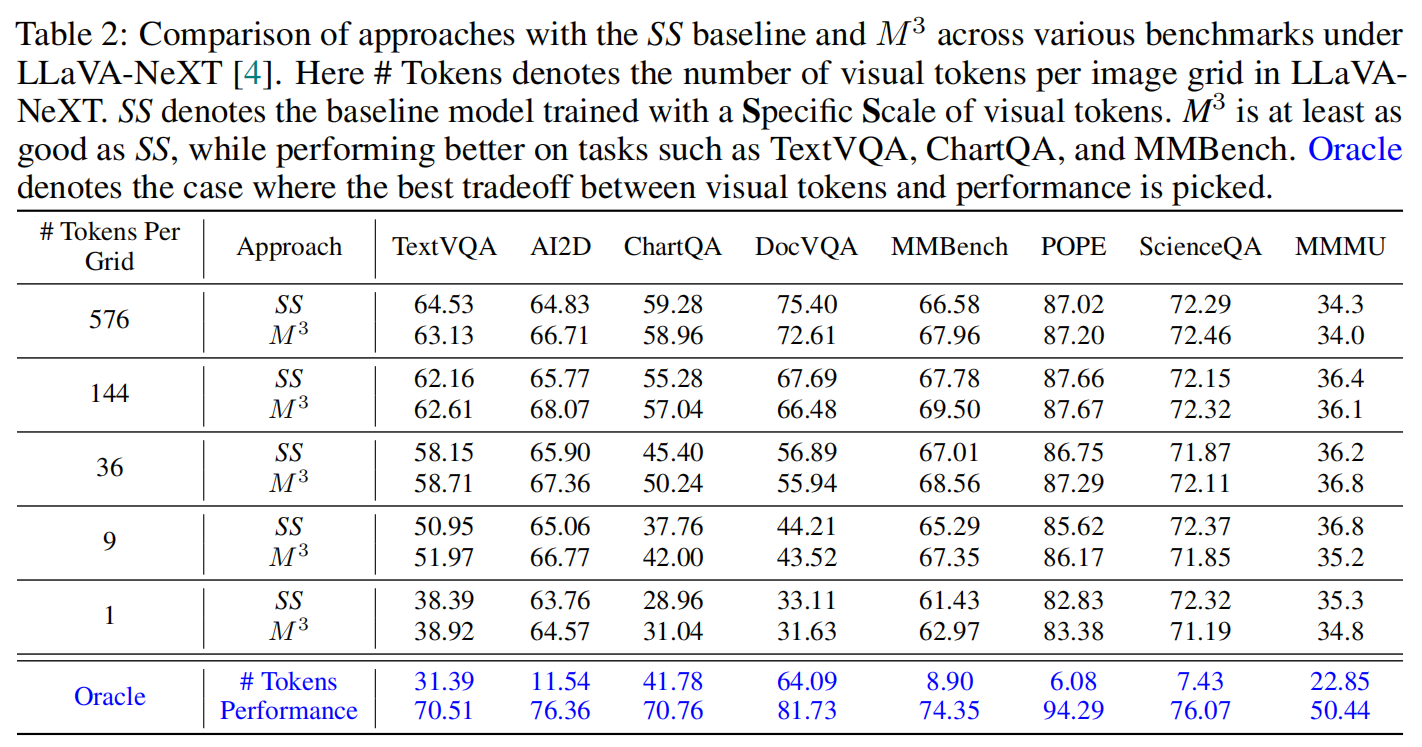
OCR 性能提升: TextVQA、ChartQA、DocVQA 分别提升 $+2.12,\ +1.80,\ +4.11$。
3.5 Ablation Studies

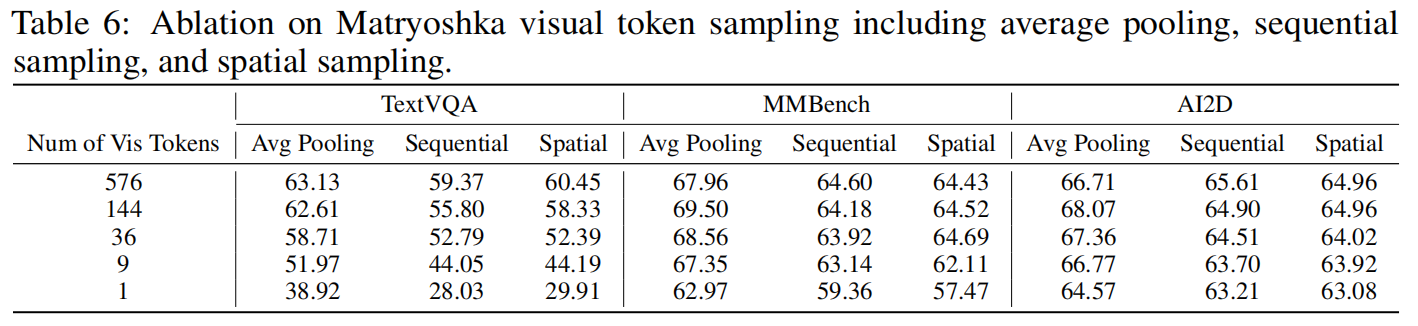
消融实验验证了:
-
训练尺度的影响: 联合训练所有尺度 $$ {\mathcal{V}^{(s)}}_{s=1}^{S} $$ 优于仅训练特定尺度(SS)。
-
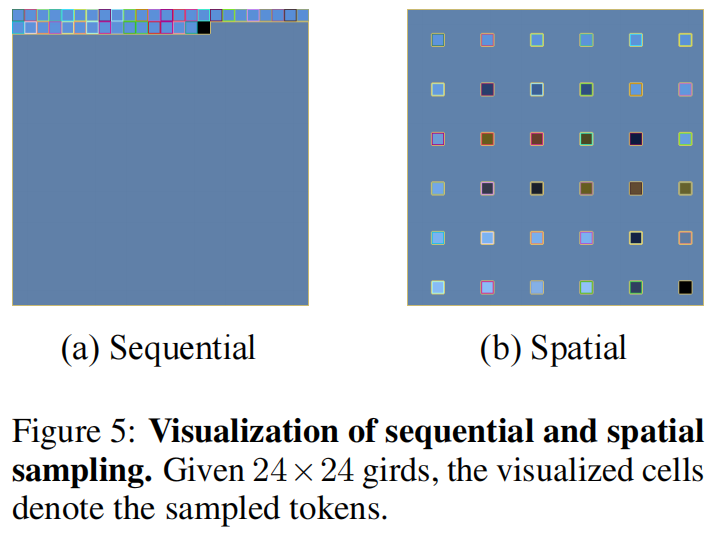
池化策略: 空间平均池化保留二维位置先验 $$ (i,j) \in \mathbb{Z}^2 $$ 显著优于序列重排方案。
4. Conclusion and Future Work
我们提出了 Matryoshka Multimodal Models (M³),学习将视觉内容表示为嵌套的视觉 Token 集合,实现推理时对视觉粒度的显式控制。
核心贡献总结:
-
效率提升: 通过减少 Token 数 $|\mathcal{V}|$,显著降低 FLOPs 与 KV-cache 内存开销。
-
复杂度度量: M³ 可作为评估数据集视觉复杂度的框架: COCO 类自然场景 $\Rightarrow |\mathcal{V}| \approx 9$ OCR / 文档任务 $\Rightarrow |\mathcal{V}| \in [144, 576]$
-
揭示瓶颈: Oracle 上限与固定尺度模型之间存在巨大性能鸿沟。
未来工作:
-
自动尺度预测器: 学习函数 $$ g(I, Q) \rightarrow s^\star $$ 自动选择最优 Token 尺度。
-
多模态扩展: 将嵌套思想推广至纯文本 LLM 的长上下文建模与其他高密度感知任务。