 Conference: SoCC'25
Conference: SoCC'25
1. 动机(Motivation)
大型多模态模型(LMMs)需要处理本质上不同的输入类型,每种类型都需要独特的处理流程。这种固有的异构性为服务带来了特殊的复杂性,呼唤新的分析和服务策略。以图像-文本到文本模型[25]为例,推理流程包括多个专业阶段:
- 图像预处理: 将原始图像转换为张量表示。
- 图像编码: 将这些张量转换为图像标记(tokens)。
- 语言模型后端: 结合文本提示和图像标记生成文本输出。
当前,这些阶段通常以单体系统[5, 27, 62]形式提供服务,所有组件集成在单个实例中并作为一个统一实体进行扩展。虽然最新的LLM服务系统已采用预填充-解码(PD)分解[46, 65]来减轻LLM后端性能干扰,但这些优化仍以文本为中心,忽略了上游的多模态预处理和编码阶段。这些上游阶段在单体服务实例中依然紧密耦合。
这种缺乏模态-aware解耦的设计,限制了现有系统在处理非文本工作负载时的效率和可扩展性。由于多模态输入预处理和编码位于关键路径上,这些系统难以满足首令牌时间(TTFT)的服务水平目标(SLOs)。 清晰地展示了,在每个请求的图像数量增加(这在多图像或视频工作负载中很常见)时,单体部署所面临的扩展挑战,这会导致TTFT急剧恶化。因此,图像密集型请求可能引发队头(HoL)阻塞,进而降低系统响应能力并导致资源过度配置。
清晰地展示了,在每个请求的图像数量增加(这在多图像或视频工作负载中很常见)时,单体部署所面临的扩展挑战,这会导致TTFT急剧恶化。因此,图像密集型请求可能引发队头(HoL)阻塞,进而降低系统响应能力并导致资源过度配置。
2. 贡献(Contribution)
作者的工作: 本文首次对两种主流LMM架构——交叉注意力(CroAttn)和仅解码器(DecOnly)——进行了全面的系统分析。分析对象包括六个代表性的开源LMMs以及来自Azure数据中心的真实生产LMM推理轨迹。作者深入剖析了它们的多阶段推理流程、性能与资源之间的权衡,以及生产工作负载模式(包括可变的请求率、多样化的多模态输入和突发流量)。为促进研究,作者发布了来自生产集群的首个开源多模态轨迹,以供社区研究真实世界的部署模式。
关键洞察(Insights): 作者的分析确定了三个优化LMM推理的关键洞察:
- Insight 1: 不同的LMM推理阶段(如预处理、编码、预填充、解码)表现出不同的性能特征,并且对资源和模型配置(如批处理、模型分片)具有不同的敏感性,因此需要解耦执行。
- Insight 2: 图像编码是影响TTFT的主要瓶颈,因此需要高效的编码器并行化来减少延迟和队头(HoL)阻塞。
- Insight 3: 生产多模态流量展现出独特的突发模式,主要由每个请求的图像数量增加所驱动,这强调了需要模态感知路由策略来管理突发流量并减轻尾部延迟峰值。
ModServe架构: 基于上述洞察,作者提出了ModServe,一种新型的模块化架构,专为可扩展和资源高效的LMM服务而设计,旨在直接解决分析中发现的挑战。以图像-文本到文本任务为例,ModServe将图像和文本特定的推理阶段分离到不同的实例中进行解耦执行:
- 图像实例: 处理图像预处理和编码。
- 文本实例: 管理LLM的预填充和解码(见)。
- 请求流: 纯文本请求绕过图像实例直接由文本实例服务;图像-文本请求则先通过图像实例将图像转换为标记,再转发给文本实例进行文本生成。
ModServe的优化能力: 这种模块化架构实现了阶段特定的优化:
- 独立资源管理: ModServe独立地使用阶段感知自动扩展、模型分片和批处理来管理图像和文本实例。通过单独扩展各个阶段,它最大程度地减少了资源过度配置。例如,在生产流量中观察到的图像驱动突发期间,图像实例可以独立扩展,从而比单体推理系统更具资源效率。
- 并行化编码: 为解决图像编码瓶颈,ModServe在多个图像实例上并行化单个请求的编码()。这是基于一个关键发现:请求中的图像在编码期间不进行相互注意力计算,因此请求可以在图像级别并行化。
- 模态感知路由: 为管理图像驱动的突发,ModServe为图像和文本实例实现了模态感知请求路由。例如,图像-文本请求中的图像被路由到具有最少待处理图像标记的图像实例,以减少HoL阻塞和尾部延迟峰值。
性能表现: 作者在高性能推理系统vLLM[27]之上实现了ModServe,并通过在运行Azure生产LMM推理轨迹的16服务器(128 GPU)集群上进行广泛评估,验证了ModServe的有效性。与最先进的基线相比,ModServe在静态资源分配下实现了3.3至5.5倍更高的吞吐量,同时在满足P99 TTFT SLOs的前提下,将LMM服务成本降低了25%至41.3%。
互补性: 虽然现有的PD分解技术[46, 65]有助于优化LLM推理(通过分离预填充和解码),但它们对于处理多模态工作负载来说是不够的。生产环境中异构且突发的多模态流量性质,使得在以文本为中心背景下研究的PD分解难以扩展;模态特定的优化(如并行化编码、模态感知路由和阶段自动扩展)对于在保持资源效率的同时满足SLOs至关重要。作者在第5节中证明,ModServe可以与LLM后端的两种配置(共置LLM后端/混合PD批处理,以及文本节点的PD分解)结合,且提出的模态感知技术在两种配置下都能改善服务延迟。
适用范围: 作者重点研究了图像-文本到文本和视频-文本到文本(视频被视为图像帧序列处理[31])任务,但其洞察可推广到其他多模态场景,例如音频-文本到文本任务[23],因为它们与研究所用的模型具有相似的模型架构和推理阶段。
3. 基础知识(Preliminary)
LMMs通过整合多模态理解能力,将以文本为中心的LLMs扩展到视觉问答[52]、计算机使用代理[42, 45]等任务。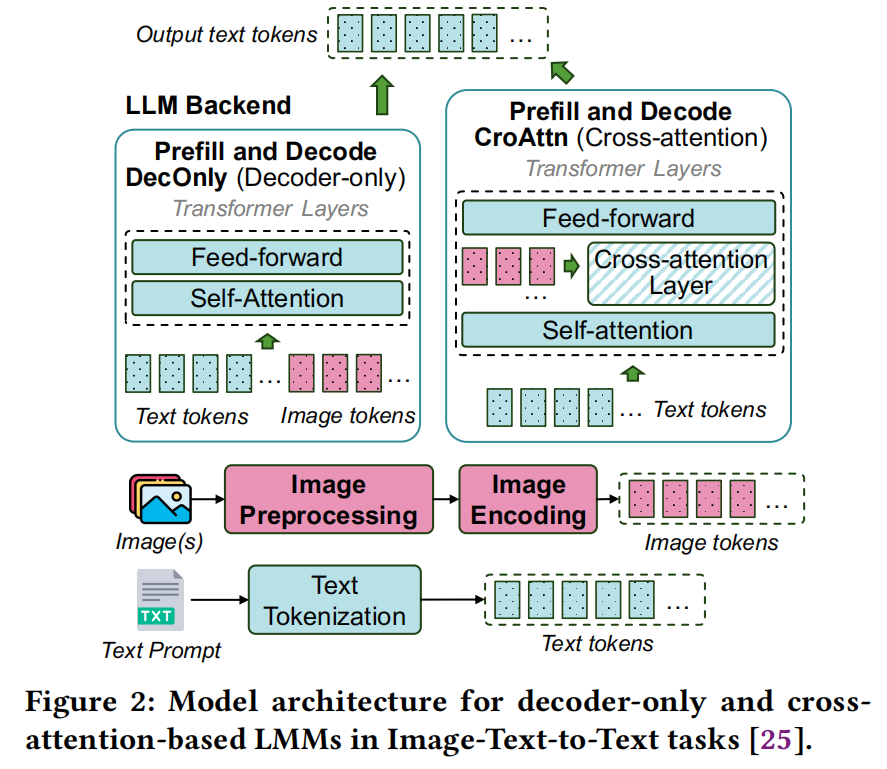 描绘了视觉理解任务中LMM推理的典型流程[25],它涉及三个关键阶段:
描绘了视觉理解任务中LMM推理的典型流程[25],它涉及三个关键阶段:
- 图像预处理: 将原始图像转换为统一大小的图块。
- 图像编码: 编码器提取视觉特征并生成一系列图像标记。
- 文本生成: LLM后端处理图像和文本标记以生成输出文本标记。
LMM主流架构: 主流LMM架构在LLM后端处理图像标记和文本标记的方式上存在差异:
- 仅解码器(DecOnly): 用于DeepSeek的Janus[7]、LLaVA-OneVision[31]、InternVL[9]和NVLM-D[12]等模型。它重用未经修改的LLM后端(例如,LLaVA-OV重用Qwen2 LLM[31]),通过附加连接器[66]或模态对齐模块将图像编码器输出映射到LLM的标记空间,统一处理文本和图像标记(如中的“DecOnly”框)。虽然简单,但通常需要处理高分辨率图像带来的长序列,导致推理时的计算效率低下。
- 交叉注意力(CroAttn): 见于Llama-3.2 Vision[11]。它集成交叉注意力层来处理图像标记,将视觉输入视为LLM后端中的“外语”。自注意力作用于文本标记,而交叉注意力层同时关注文本和图像标记(中的“CroAttn”框)。通过避免在LLM解码器中完全展开图像标记,它提高了推理效率,使其成为处理高分辨率输入的理想选择。
- (自注意力在[图像+文本]上:需要交互:图像->图像,图像->文本,文本->图像,文本->文本)
- (交叉注意力:仅文本->图像(单向))
图像预处理: LMMs通常在CPU上执行调整大小、分割成图块[9, 11, 12]或补丁[31]以及应用转换等步骤。更高的图像尺寸会产生更多的图块,最终增加图像标记的数量(例如,896×896像素的图像在六种开源LMMs预处理后会生成4、5或10个不同大小的图块,见 )。
)。
图像编码: 图像编码器(主要使用视觉变换器架构[4])接收处理后的图像图块作为输入,并生成传递给语言模型后端的图像标记。不同的LMMs使用不同的编码器[4, 9, 31, 64],这导致在相同的ShareGPT-4o数据集[8]上运行时,生成的图像标记数量也有所不同(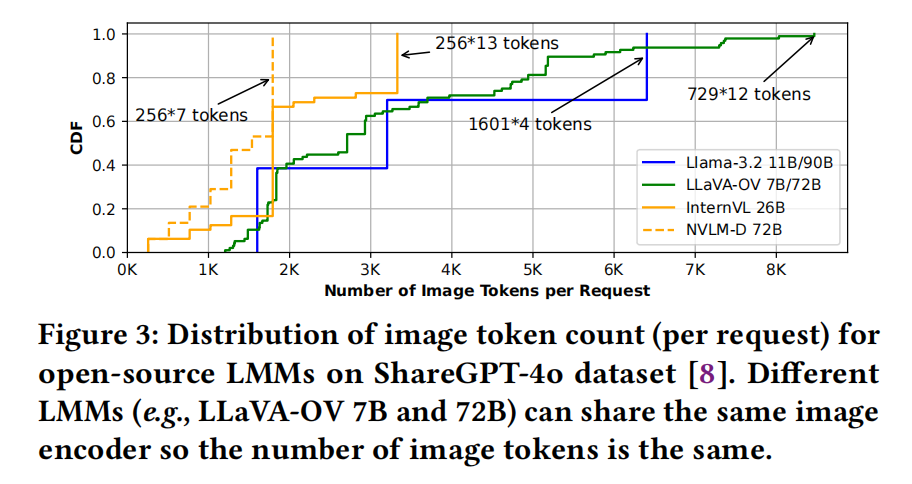 )。
)。
LMM推理的SLO指标:
- 首令牌时间(TTFT): 测量从查询到第一个响应标记的延迟,包括:(1)图像预处理,(2)编码,(3)语言模型预填充时间。多模态预处理和编码主要影响TTFT。
- 令牌间时间(TBT): 捕获解码期间连续标记生成之间的延迟。
当今的LMM部署: 最先进的服务框架[5, 27, 62]将LMMs部署为单体系统,所有组件在同一硬件服务器上共置。即使应用了PD分解,多模态组件仍与预填充实例耦合[27],无法根据不同资源需求和性能特征进行独立优化,限制了灵活性,并在图像密集型工作负载下遭受TTFT的急剧恶化()。
4. LMM特性分析(LMM Characterization)
4.1 开源LMMs的特性分析
各阶段延迟分解: 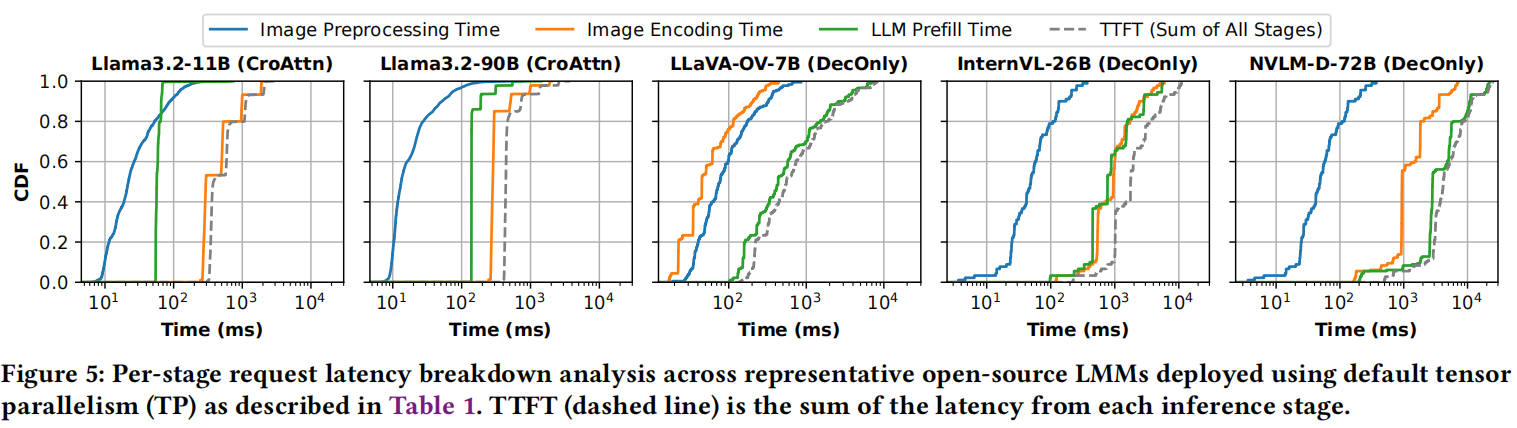 展示了TTFT在图像预处理、图像编码和LLM预填充上的分布。
展示了TTFT在图像预处理、图像编码和LLM预填充上的分布。
- 图像编码是TTFT的主要瓶颈: 发生在CPU上的图像预处理贡献微乎其微。图像编码时间贡献巨大,尤其在CroAttn模型中(Llama3.2-11B和Llama3.2-90B中79%和65%的TTFT来自图像编码)。即使在DecOnly模型(如InternVL-26B和NVLM-D-72B)中,图像编码延迟也占TTFT的25%和54%。
- 原因: 每个请求的图像数量可能很大,且CroAttn模型通过减少LLM中图像-文本交互,将计算负载转移并集中到图像编码器。
- Insight 1:TTFT的大部分时间消耗在图像编码上,特别是对于CroAttn模型,使图像编码优化对满足TTFT SLOs至关重要。
LMM阶段的计算特征:
- 计算密集型: CPU上的图像预处理(可从核心间并行化获益,
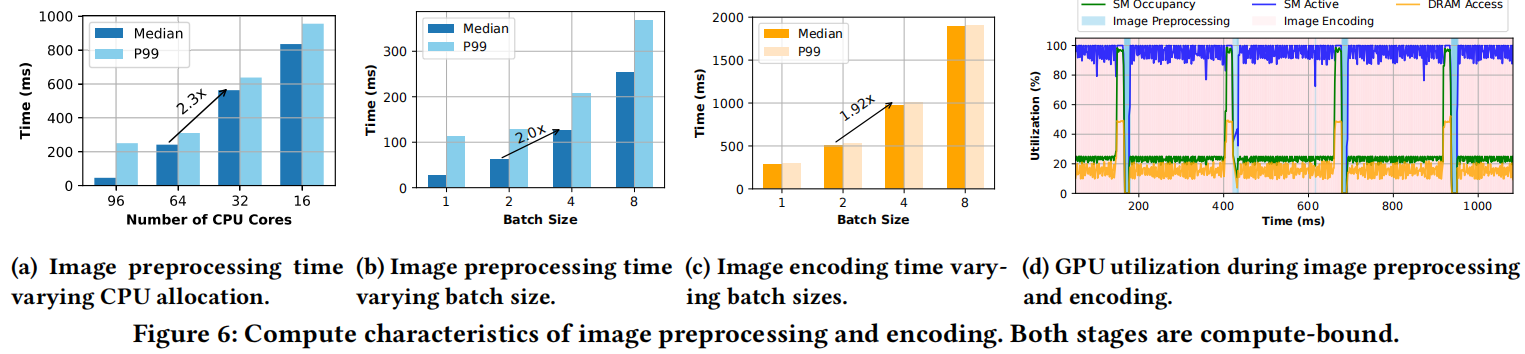 )和GPU上的图像编码(SM核心活动接近100%,DRAM利用率低于30%,)都是计算密集型过程,类似于LLM预填充阶段。
)和GPU上的图像编码(SM核心活动接近100%,DRAM利用率低于30%,)都是计算密集型过程,类似于LLM预填充阶段。 - 线性延迟扩展: 图像预处理和编码的延迟都随批大小呈线性增长,且计算在没有显著吞吐量增益的情况下饱和(和)。
- 并行化潜力: 多模态请求中图像的计算是独立的,因此图像预处理和编码可以在多个编码器上并行化。
- Insight 2:图像预处理和编码都是计算密集型的,类似于LLM预填充阶段。多模态请求中图像计算的独立性使得图像预处理和编码可以在多个实例上并行化。
不同LMMs的延迟-准确性配置文件: 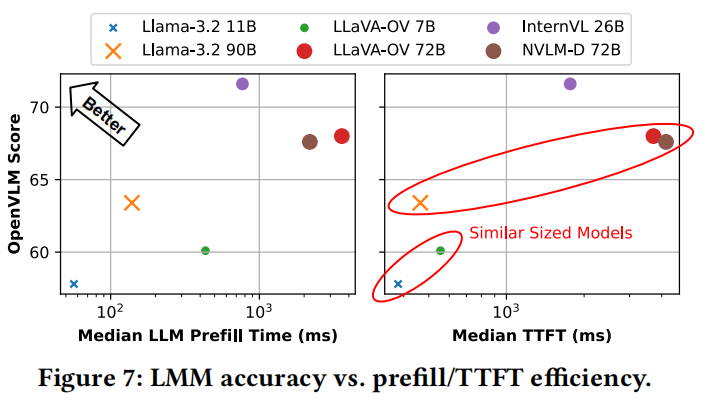 显示了不同模型的准确性和预填充/TTFT效率的权衡。
显示了不同模型的准确性和预填充/TTFT效率的权衡。
- CroAttn效率 vs. 准确性: 相似大小的CroAttn模型(例如Llama3.2-11B)的LLM预填充时间通常比DecOnly模型(例如LLaVA-OV-7B)低一个数量级,导致更低的TTFT。然而,CroAttn模型的准确性通常比DecOnly对应物低5分(例如Llama3.2-90B得分为63.4,而LLaVA-OV-72B得分为68)。
- Insight 3:DecOnly模型表现出比类似大小的CroAttn模型差10倍的LLM预填充延迟,导致图像编码的TTFT SLO余量较少,因此需要对图像工作负载具有更高的可扩展性。
批处理的影响: 在单体部署中,单个批大小应用于所有LMM阶段,难以在延迟和吞吐量之间取得平衡(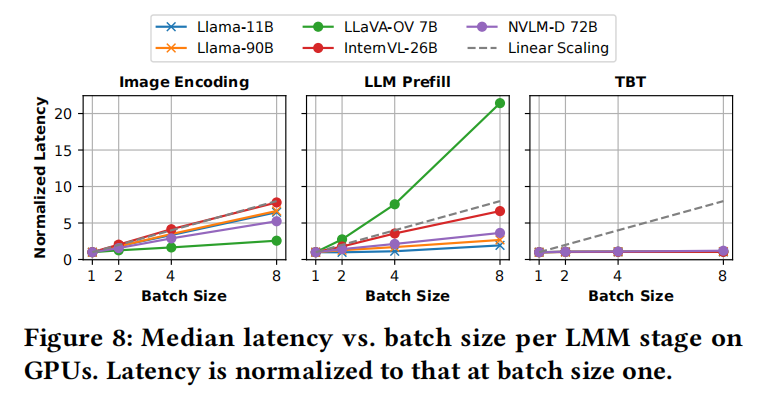 )。
)。
- 异构敏感性: 延迟随批大小增加的速率不同,反映了每个阶段的不同敏感性。计算密集型阶段(如图像编码和DecOnly中的LLM预填充)吞吐量增益有限且延迟上升。内存受限的解码阶段则受益于线性吞吐量扩展。
- CroAttn优势: CroAttn模型因文本标记数量较少而从预填充批处理中受益。
- Insight 4:批处理对每个LMM组件的有效性因模型而异。因此,LMM请求批处理应针对每个阶段定制。
并行性的影响: 单体部署限制了模型分片(TP[59])的灵活性(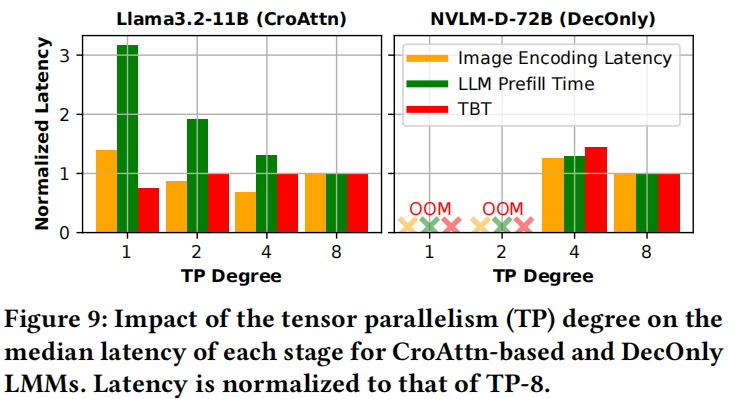 )。
)。
- 最佳TP度不同: Llama3.2-11B中,最低LLM预填充延迟在TP-8,图像编码在TP-4,TBT在TP-1。大编码器(如NVLM-D-72B的6B编码器)在TP从4增加到8时延迟减少1.3倍,但收益递减。
- Insight 5:将图像编码器和LLM后端视为单体限制了并行性灵活性并降低性能。解耦它们可以通过流水线实现独立扩展和优化效率。
4.2 生产LMM轨迹分析
时间模式和突发性:
- 图像驱动的突发: 图像-文本请求具有比纯文本高5倍的提示标记率,且其峰谷出现时间相互独立。它们经历显著的突发性,不仅因为请求到达率更高,还因为每个请求的图像数量增加(
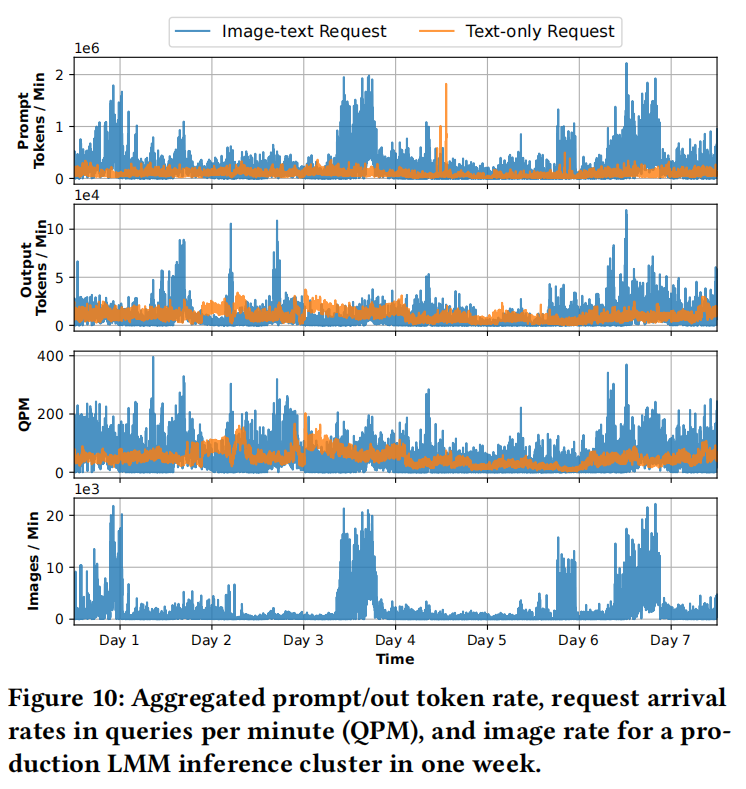 )。现有LLM流量预测方法[56]的平均预测错误率高达79%。
)。现有LLM流量预测方法[56]的平均预测错误率高达79%。 - Insight 6:生产LMM图像流量表现出与文本请求流量模式无关的突发行为,这是由于不同服务的性质。服务系统必须动态扩展资源以高效处理模态特定的突发。
请求异构性:
- 提示长度:
 显示提示长度在模态之间显著变化,都遵循重尾幂律分布(图像-文本 $\alpha=4.4$,纯文本 $\alpha=2.9$)。图像-文本请求中位提示更长,但尾部比纯文本请求短。
显示提示长度在模态之间显著变化,都遵循重尾幂律分布(图像-文本 $\alpha=4.4$,纯文本 $\alpha=2.9$)。图像-文本请求中位提示更长,但尾部比纯文本请求短。 - 图像数量: 显示每个请求的图像数量显著变化且尾部较重。不同服务之间的每个请求图像数量变异性很高(可相差16倍)。
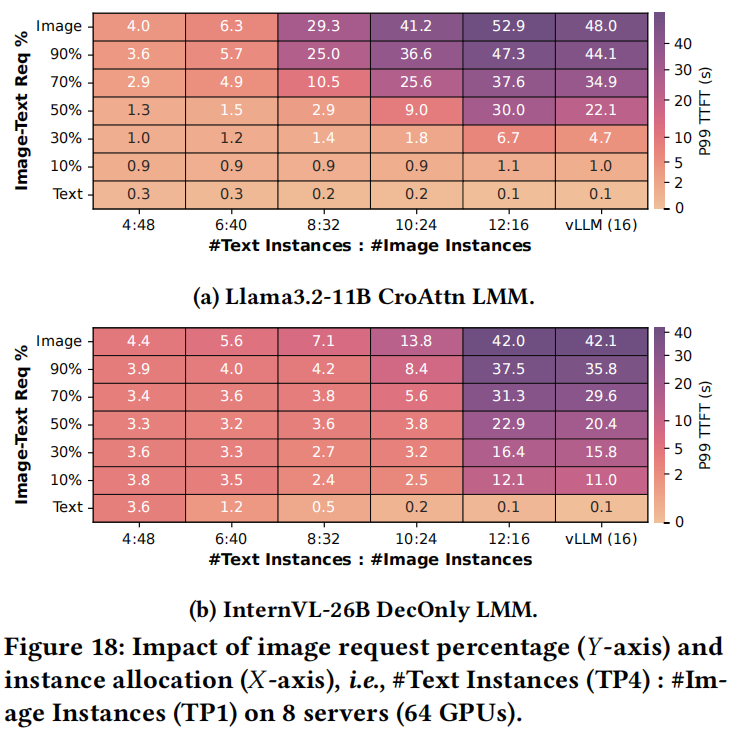
混合模态的影响: 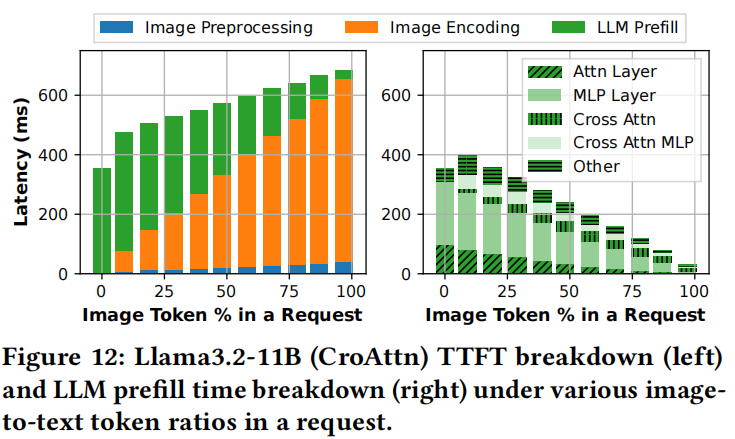 显示了在单个请求中改变图像标记百分比对CroAttn模型Llama3.2-11B中TTFT和LLM预填充时间的影响。
显示了在单个请求中改变图像标记百分比对CroAttn模型Llama3.2-11B中TTFT和LLM预填充时间的影响。
- CroAttn模型: TTFT随着图像标记百分比增加而增加(由于图像编码计算),但LLM预填充时间减少(绿色显示),部分抵消了图像编码开销。这是因为图像标记仅在少量CroAttn层中被关注(右侧显示自注意力计算减少)。
- DecOnly模型: 预填充时间不随标记比率变化,因为图像和文本标记以相同方式处理。
- Insight 7:DecOnly模型无论标记模态如何都保持一致的预填充时间,使总标记计数成为请求路由的关键因素。相比之下,CroAttn模型随着图像标记百分比的增加而经历预填充延迟减少,需要一种模态感知请求路由策略,在多模态流量中平衡文本和图像标记负载。
5. ModServe方法(Method)
ModServe是一种新型模块化架构,它将推理阶段分离到图像实例(处理图像预处理和编码)和文本实例(LLM预填充和解码)中,以实现独立优化(Insight 1和3),并在满足SLOs的同时提高资源效率。它采用分层架构,由图像池管理器和文本池管理器管理。
5.1 离线LMM配置文件生成
- 过程: 在引入新LMM时,ModServe通过独立表征图像编码器和LLM后端,在受控负载、不同TP和批大小下运行,以生成资源-性能配置文件。
- 输出: 配置文件预测关键性能指标(图像实例的编码延迟、文本实例的预填充时间和TBT)。
- 用途: 池管理器使用配置文件指导:(1)池自动扩展、(2)选择最佳TP度的模型分片、(3)每个阶段的最大批大小配置。
5.2 解耦的资源管理
ModServe定期重新配置资源(每五分钟)以适应工作负载需求,其方法基于对阶段特定性能差异(Insight 4)、独立扩展优势(Insight 5)和模态特定流量模式(Insight 6)的洞察。
- 连接器共置: 连接器与LLM后端共置,以避免为小组件分配单独GPU导致的资源利用率不足。
- 令牌感知池自动扩展: 池管理器根据实时令牌吞吐量(令牌/秒)(而非请求率)动态扩展图像和文本实例数量,以捕获请求率和请求大小的变化(Insight 6和)。
- 副本数量: $\lceil M_L / M_C \rceil$,其中 $M_L$ 是特定于模态的负载,$M_C$ 是最大容量。
- 文本实例: CroAttn模型基于文本标记负载扩展;DecOnly模型基于总标记扩展(Insight 7)。
- 模型分片: 池管理器独立确定图像编码器和LLM后端的最佳张量并行(TP)度,以针对最大吞吐量配置每个实例,同时满足TTFT和TBT SLOs。图像编码器通常在比LLM更低的TP下实现峰值吞吐量(Insight 5)。
- 最大批大小: 配置为在满足延迟SLOs的同时最大化吞吐量(Insight 4)。图像实例可能放弃批处理;文本实例(尤其是CroAttn LMMs)根据TTFT和TBT SLOs优化批处理。
5.3 模态感知LMM请求服务
ModServe采用动态路由和调度来平衡图像和文本实例之间的负载,以最小化排队延迟并改善TTFT延迟。
- 跨实例请求路由(模态感知): 采用模态感知路由策略平衡负载,以缓解模态特定突发引起的尾部延迟激增。
- 图像-文本请求: 路由到具有最少待处理图像标记负载的图像实例,实现大型请求中图像的并行处理和编码(Insight 2),防止HoL阻塞。
- 文本实例路由: 纯文本和已完成图像标记的请求:DecOnly模型路由到最少总待处理标记的实例;CroAttn模型路由到最少总待处理文本标记的实例(Insight 7)。
- 实例请求调度(SLO驱动): 在文本实例中,用SLO驱动的调度策略替换了传统FIFO调度[47, 50],优先处理较短请求或具有严格SLOs的请求以保持低延迟,从而最小化资源争用和HoL阻塞。
- 图像标记传输: 一旦编码完成,ModServe通过基于拉取(pull-based)的RDMA机制将图像标记从图像实例传输到文本实例,使得调度器能够基于完整信息(队列大小、有效载荷等)选择最佳目标文本实例,避免次优路由。
5.4 实现细节
ModServe在vLLM[27](v0.7.2)之上实现文本实例,图像实例基于HuggingFace Transformers[24]。使用带有NCCL后端和GPU Direct RDMA的PyTorch分布式通信进行高效GPU到GPU内存传输。池管理器作为轻量级gRPC服务器(受DynamoLLM[56]启发)实现,用于故障检测和恢复。支持在同一服务器中并置独立配置的图像和文本实例。
6. 评估(Evaluation)
6.1 实验设置
- 模型: Llama3.2-11B (CroAttn) 和 InternVL-26B (DecOnly)。
- 工作负载: 采用生产LMM推理轨迹(第3.2节)中的请求到达时间戳和图像数量(0到16)。
- 硬件: 16台DGX-A100服务器(128 GPU),服务器内NVLINK 3.0,跨服务器InfiniBand。
- 基线: vLLM[27](单体)和ModServe的消融变体(ModServe-Decoup、ModServe-Sched)。
- SLO定义: 基于单体基线的单个纯文本/图像-文本请求的TTFT/TBT,并使用常数因子进行缩放,定义在P99尾部延迟上。
6.2 端到端性能(End-to-end Performance)
静态资源分配(16台服务器,128 GPU):
- TTFT改进:
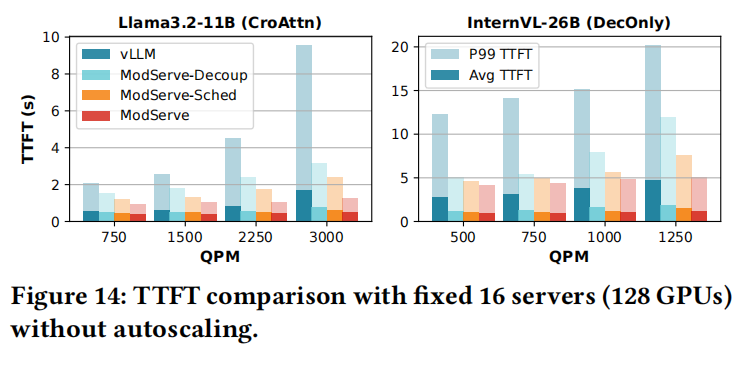 显示,与vLLM(单体)相比,静态解耦(ModServe-Decoup)将Llama3.2的P99 TTFT提高了42%,InternVL的P99 TTFT提高了47%。ModServe通过模态感知调度和路由进一步将P99 TTFT减少14%和32%。
显示,与vLLM(单体)相比,静态解耦(ModServe-Decoup)将Llama3.2的P99 TTFT提高了42%,InternVL的P99 TTFT提高了47%。ModServe通过模态感知调度和路由进一步将P99 TTFT减少14%和32%。 - 吞吐量:
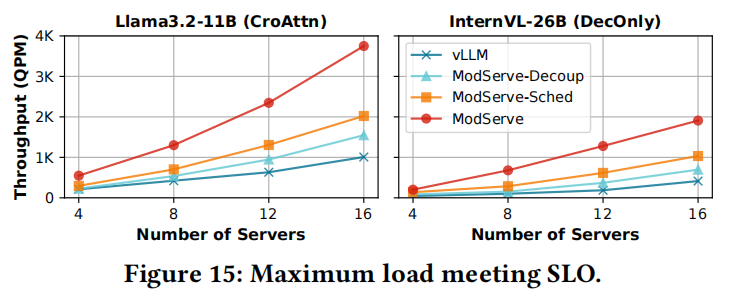 显示,在满足SLOs下,ModServe的吞吐量比vLLM(单体)高出3.3倍(Llama3.2)和5.5倍(InternVL),证实DecOnly模型从解耦中受益更多。
显示,在满足SLOs下,ModServe的吞吐量比vLLM(单体)高出3.3倍(Llama3.2)和5.5倍(InternVL),证实DecOnly模型从解耦中受益更多。
具有自动扩展的资源分配: 评估服务包含图像驱动突发()的生产轨迹。
- 成本节约:
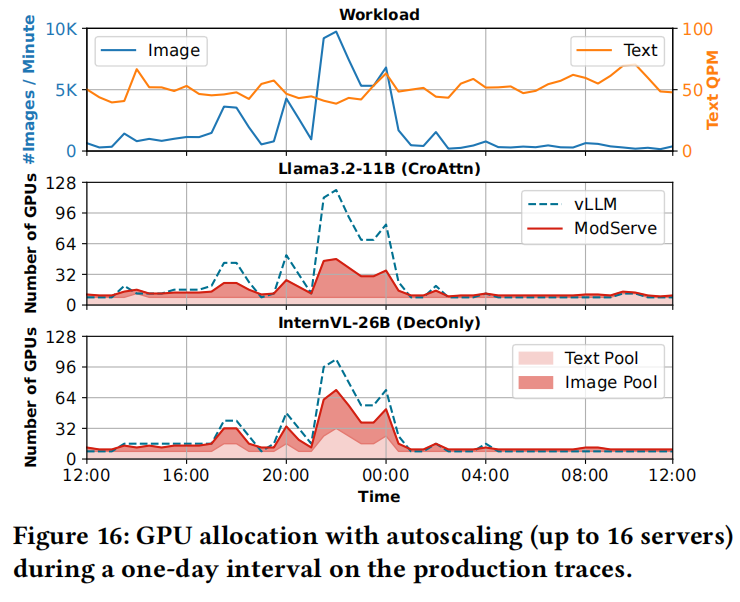 比较了服务轨迹所需的GPU数量。与vLLM(单体)相比,ModServe在满足尾部延迟SLOs的同时,服务Llama-3.2(CroAttn)和InternVL(DecOnly)模型的GPU使用量分别减少了41.3%和25%。这证明ModServe的阶段感知自动扩展防止了在图像驱动突发期间不必要地扩展LLM后端,避免了资源过度配置。
比较了服务轨迹所需的GPU数量。与vLLM(单体)相比,ModServe在满足尾部延迟SLOs的同时,服务Llama-3.2(CroAttn)和InternVL(DecOnly)模型的GPU使用量分别减少了41.3%和25%。这证明ModServe的阶段感知自动扩展防止了在图像驱动突发期间不必要地扩展LLM后端,避免了资源过度配置。
6.3 敏感性研究(Sensitivity Study)
- SLO缩放的影响:
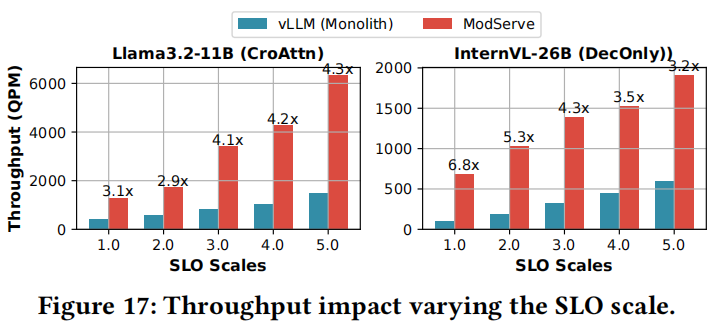 显示,随着SLO缩放增加,ModServe持续优于vLLM,在Llama-3.2上实现高达4.3倍,在InternVL上实现6.8倍的吞吐量提升。
显示,随着SLO缩放增加,ModServe持续优于vLLM,在Llama-3.2上实现高达4.3倍,在InternVL上实现6.8倍的吞吐量提升。 - 图像与文本实例比率的影响:
 显示,当图像:文本实例比率超过2.4时,ModServe持续优于单体基线(Llama3.2最高18.4倍,InternVL最高9.2倍),展示了其处理多模态工作负载的效率。
显示,当图像:文本实例比率超过2.4时,ModServe持续优于单体基线(Llama3.2最高18.4倍,InternVL最高9.2倍),展示了其处理多模态工作负载的效率。
6.4 预填充-解码分解支持(Prefill-Decode Disaggregation Support)
ModServe兼容预填充/解码(PD)分解[46, 65],可实现完整的EPD分解。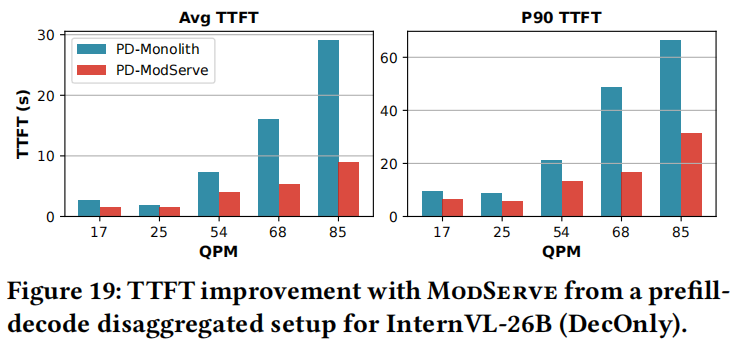 比较了PD-Monolith和PD-ModServe配置(部署InternVL-26B,总共32个GPU用于编码和预填充)。
比较了PD-Monolith和PD-ModServe配置(部署InternVL-26B,总共32个GPU用于编码和预填充)。
- 结果: ModServe(PD-ModServe,蓝色)提供了额外的TTFT减少(平均TTFT最高2.8倍,P90 TTFT最高3.2倍),超出了单独PD分解(红色)所能提供的。这归因于ModServe减少了图像编码和LLM预填充阶段之间的资源争用,并利用编码器并行化(Insight 2)。
6.5 标记传输开销(Token Transfer Overhead)
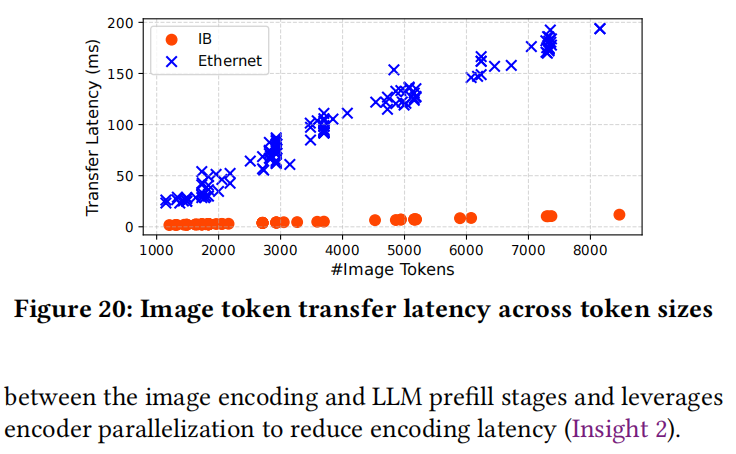 比较了图像标记在Infiniband (RDMA) 和以太网 (TCP) 上的传输开销。
比较了图像标记在Infiniband (RDMA) 和以太网 (TCP) 上的传输开销。
- 开销: 使用Infiniband上的RDMA,P99传输延迟仅为5毫秒,占TTFT的<0.5%。以太网上的TCP开销显著更高(P99为180毫秒)。
- 影响: 即使在TCP上评估,ModServe在InternVL-26B的高负载下仍实现了35%的TTFT减少,证明了阶段解耦的价值。
7. 结论与相关工作(Conclusion and Related Work)
LMM表征: 作者对开源模型和生产轨迹上的LMMs进行了首次全面系统分析,突显了它们独特的执行和工作负载模式,与Lee等人[28](专注于生成模型)和Hou等人[19](专注于传统模型)的工作形成对比。
LMM服务优化: 现有优化(如Inf-MLLM[41]、弹性缓存[36]、Dynamic-LLaVA[22])主要在模型级别操作,涉及准确性与计算开销的权衡。ModServe的系统级设计不影响模型准确性,并与这些模型级优化(例如通过子采样实现更快的图像编码[29])正交,可以互补。
并发工作: 其他并发工作(如EPD[54]和HydraInfer[14])采用了类似的阶段解耦和并行编码思想。然而,ModServe的工作超越了简单的阶段解耦,结合了基于系统分析的Insight:阶段感知模型配置、模态感知路由和自动扩展。此外,作者的分析更细致地研究了CroAttn和DecOnly两种代表性LMM架构。
以文本为中心的LLM服务: ModServe与Splitwise[46]、DistServe[65]等用于纯文本LLM服务的预填充/解码解耦技术兼容,但其核心在于解决多模态模型的独特特征。
总结: 作者基于对开源模型和生产LMM推理轨迹的全面系统分析,设计了ModServe。这是一个可扩展和资源高效的LMM服务框架,通过解耦推理阶段实现了动态重新配置、自适应扩展和模态感知调度。评估表明,与最先进的技术相比,ModServe在高效服务生产规模LMM推理工作负载的同时,实现了**25%至41%**的成本节约。