
Conference: CVPR 2025
Github: https://github.com/hey-cjj/MoVE-KD
1. Motivation
视觉编码器(Visual Encoder)是视觉语言模型(VLM)的核心组件,每个编码器通常源自不同的视觉基础模型(Visual Foundation Model),因此具备不同的特长与感知能力。为了充分利用这些差异化优势,近年来许多研究在单一 VLM 中整合多个视觉编码器。然而,这种设计虽然能融合多源知识,却导致计算量大幅上升、模型复杂度增加,严重影响了效率与可扩展性。
核心问题:
是否可以将多个视觉编码器的特长“蒸馏”进一个单一编码器中,从而兼具多编码器的性能与单编码器的高效性?
MoVE-KD(Mixture-of-Visual-Encoder Knowledge Distillation)正是为了解决这一问题而提出的。
2. Challenge
现有方法(如 [24, 38, 42])通常通过特征拼接(feature concatenation)或注意力融合(attention fusion)等方式结合多个视觉编码器,但多编码器必然带来高计算开销和复杂模型结构,削弱了训练与推理效率。
此外,尽管知识蒸馏(Knowledge Distillation, KD)为知识压缩提供了思路,但传统 KD 主要是 一对一(one-to-one) 蒸馏,即单个教师到单个学生。而如何从多个来源、不同预训练目标的视觉教师模型中同时学习,是一个尚未充分探索的问题。
此前如 AM-RADIO [36] 虽引入多教师思路,但由于共享主干、学习冲突严重,性能受限。 MoVE-KD 的目标是建立一个统一框架,将多教师视觉知识高效压缩进单一学生模型中,同时解决知识冲突与效率问题。
3. Contribution
MoVE-KD 的提出灵感来自 ViT 的 token 扩展方法 [9],其核心思想是利用注意力机制引导多教师的知识蒸馏过程,通过 [CLS] token 判断视觉 token 的重要性,并分配动态权重,从而“选择性”吸收有价值的信息。
-
提出 MoVE-KD 框架
- 首个从知识蒸馏角度实现“多视觉编码器融合”的统一框架;
- 可在不增加模型复杂度的情况下,将不同视觉编码器的知识压缩进单模型。
-
提出 Attention-guided KD 机制
- 通过 [CLS] token 的注意力图,动态评估每个视觉 token 的重要性;
- 引入多教师权重自适应机制(Teacher Weighting),使更有价值的教师贡献更大;
- 使用 Mixture-of-LoRA-Experts (MoLE) 结构缓解教师间知识冲突。
-
在 LLaVA / LLaVA-NeXT 等主流 VLM 上取得 SOTA
- 显著提升性能与效率,证明方法在不同多模态任务上的通用性与稳定性。
4. Related Work
4.1 Vision Encoder Distillation
视觉编码器在 VLM 中负责提取视觉特征,其性能直接决定视觉理解能力。
- DINOv2 [34] 采用自蒸馏训练小模型;
- CLIP-based KD [44] 从单一 CLIP 教师蒸馏,但由于单教师能力有限,效果受限;
- AM-RADIO [36] 引入多个视觉专家蒸馏机制,但未在 VLM 框架中统一实现。
MoVE-KD 是首个在 统一的视觉语言模型框架 下实现多视觉教师蒸馏的方法。
4.2 Multi-Teacher KD
多教师 KD 在传统深度学习中已有探索,如 [49] 使用三元组损失(Triplet Loss)进行多教师学习; 在大语言模型领域,OneS [46] 是首个实现多教师知识整合的 LLM KD 方法。 而在 VLM 领域,MoVE-KD 是第一个实现多视觉教师协同蒸馏的工作。
明白了,我帮你把所有公式里的 \mathcal 去掉,同时保持原本内容和 LaTeX 公式格式不变。修改后的内容如下:
5. Method
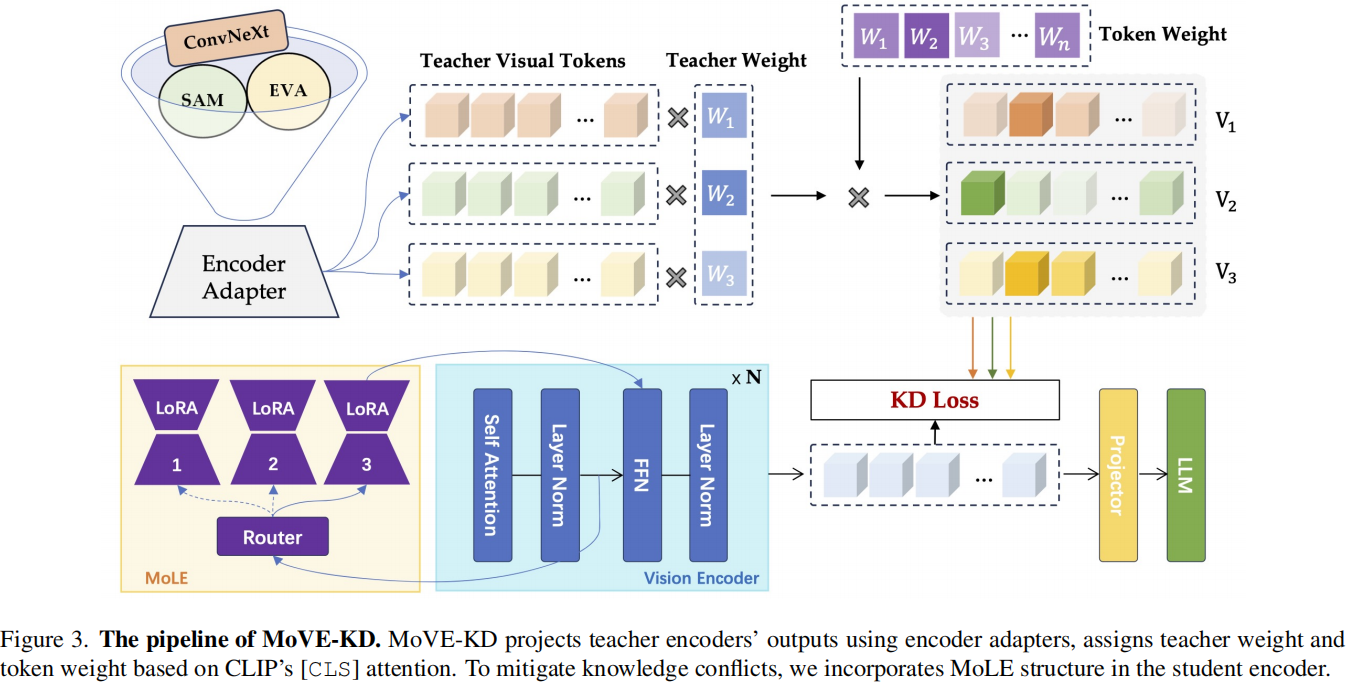
5.1 Overview
MoVE-KD 的总体流程如下:
-
多教师视觉编码器输出获取: 将输入图像送入多个预训练视觉编码器(如 CLIP、DINOv2、SAM 等),得到各自的视觉 token 表示。
-
编码器适配器(Encoder Adapter): 由于不同教师的特征空间不一致,直接蒸馏会导致分布偏移。MoVE-KD 为每个教师引入单独的 encoder adapter(两层 MLP),将输出映射到统一表征空间。
-
注意力引导的蒸馏(Attention-guided KD): 基于 CLIP 的 [CLS] token 注意力权重,计算:
* Token-level 权重:确定每个视觉 token 的重要程度; * Teacher-level 权重:根据教师模型对样本的平均注意力,确定每个教师的贡献比例。
-
学生端结构(Student Encoder with MoLE): 学生模型基于预训练 CLIP 编码器,加入 Mixture-of-LoRA-Experts (MoLE) 结构,使不同教师的知识通过不同专家通道流动,从而避免冲突、提升泛化。
-
损失函数(Loss Function): 整体损失为: $$ L_{total} = L_{text} + \lambda_{kd} \cdot L_{kd} $$ 其中 $L_{text}$ 为文本生成损失,$L_{kd}$ 为蒸馏损失。
5.2 Learning from Multiple Encoders
编码器适配器(Encoder Adapter)
由于各个视觉教师的特征维度和分布不同,MoVE-KD 为每个教师引入独立的 Adapter,用于:
- 特征对齐(Dimension Alignment);
- 空间映射(Feature Projection);
- 保证蒸馏目标空间统一。
每个适配器为一个两层 MLP,仅对该教师的输出进行调整,避免互相干扰。
MoLE(Mixture-of-LoRA-Experts)
在学生模型中,MoLE 结合了 MoE(Mixture of Experts)与 LoRA(Low-Rank Adaptation)的优点:
-
MoE 路由机制: 每一层的前馈网络(FFN)通过路由器函数 $f(x)$ 激活最相关的专家: $$ F_\star(x) = F(x) + E_i(x), \quad i = \arg\max(\text{Softmax}(f(x))) $$ 其中 $E_i$ 是第 $i$ 个专家。
-
LoRA 专家结构: 与传统 MoE 不同,MoVE-KD 不复制整个 FFN 模块,而是让每个专家仅由 LoRA 参数组成(即两个低秩矩阵 $A,B$ 替代完整参数矩阵)。这样可显著减少参数量,并提高泛化能力。
优势:
- 参数开销极小;
- 可根据输入动态选择专家,适应不同教师知识;
- 避免知识冲突与过拟合。
5.3 Attention-Guided KD Regularization
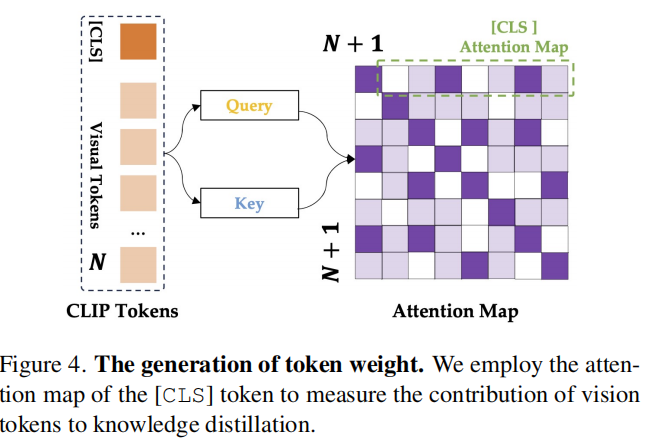
MoVE-KD 的核心创新之一是通过 CLIP 的 [CLS] 注意力权重来衡量视觉 token 的价值,从而在蒸馏时实现 “重要区域强化,冗余区域抑制”。
蒸馏损失函数
设有 $m$ 个教师模型,每个教师输出 $n$ 个视觉 token: $$ L_{kd} = \sum_{i=1}^{m} W_i^{(tea)} \sum_{j=1}^{n} \left(W_j^{(tok)} + \frac{1}{n}\right) \text{MSE}\left(V_{i,j}^{(t)}, V_j^{(s)}\right) $$ 其中:
- $V^{(t)}$、$V^{(s)}$ 分别为教师与学生视觉 token;
- $W^{(tok)}$ 为 token 级注意力权重;
- $W^{(tea)}$ 为教师级权重。
Token 权重计算
使用 CLIP 中 [CLS] token 与其他视觉 token 的注意力: $$ W^{(tok)} = \text{Softmax}\left(\frac{(V^{(cls)} W^{(Q)}) (V^{(res)} W^{(V)})^T}{\sqrt{d}}\right) $$
Teacher 权重计算
通过 [CLS] token 与每个教师输出的平均注意力确定教师重要性: $$ W^{(tea)} = \text{Softmax}\left(\text{mean}\left(\frac{V^{(cls)} (V_i^{(t)})^T}{\sqrt{d}}\right)\right) $$ 并且为防止学生遗忘自身知识,CLIP 自身也作为教师之一,赋予固定高权重(0.8)。
5.4 总体损失函数(Overall Loss)
$$ L_{total} = L_{text} + \lambda_{kd} \cdot L_{kd} $$
其中 $L_{text}$ 为语言生成损失,$\lambda_{kd}$ 控制蒸馏强度。
6. Evaluation
6.1 训练细节(Training Details)
训练过程分为两个阶段:
-
预训练阶段(Pre-training Stage)
- 训练模块:MoLE、Adapter、Projection;
- 冻结教师编码器和其他参数;
- 目标:最小化 $\mathcal{L}_{total}$。
-
微调阶段(Fine-tuning Stage)
- 解冻除教师外的所有参数;
- 继续优化 $\mathcal{L}_{total}$。
超参数:
- CLIP 教师权重:0.8;
- MoLE 专家数:3;
- LoRA rank:32;
- 蒸馏损失权重 $\lambda_{kd}$:0.5;
- 训练设备:16 × A800 GPU。
训练遵循 LLaVA 的两阶段指令微调流程。
6.2 Main Results
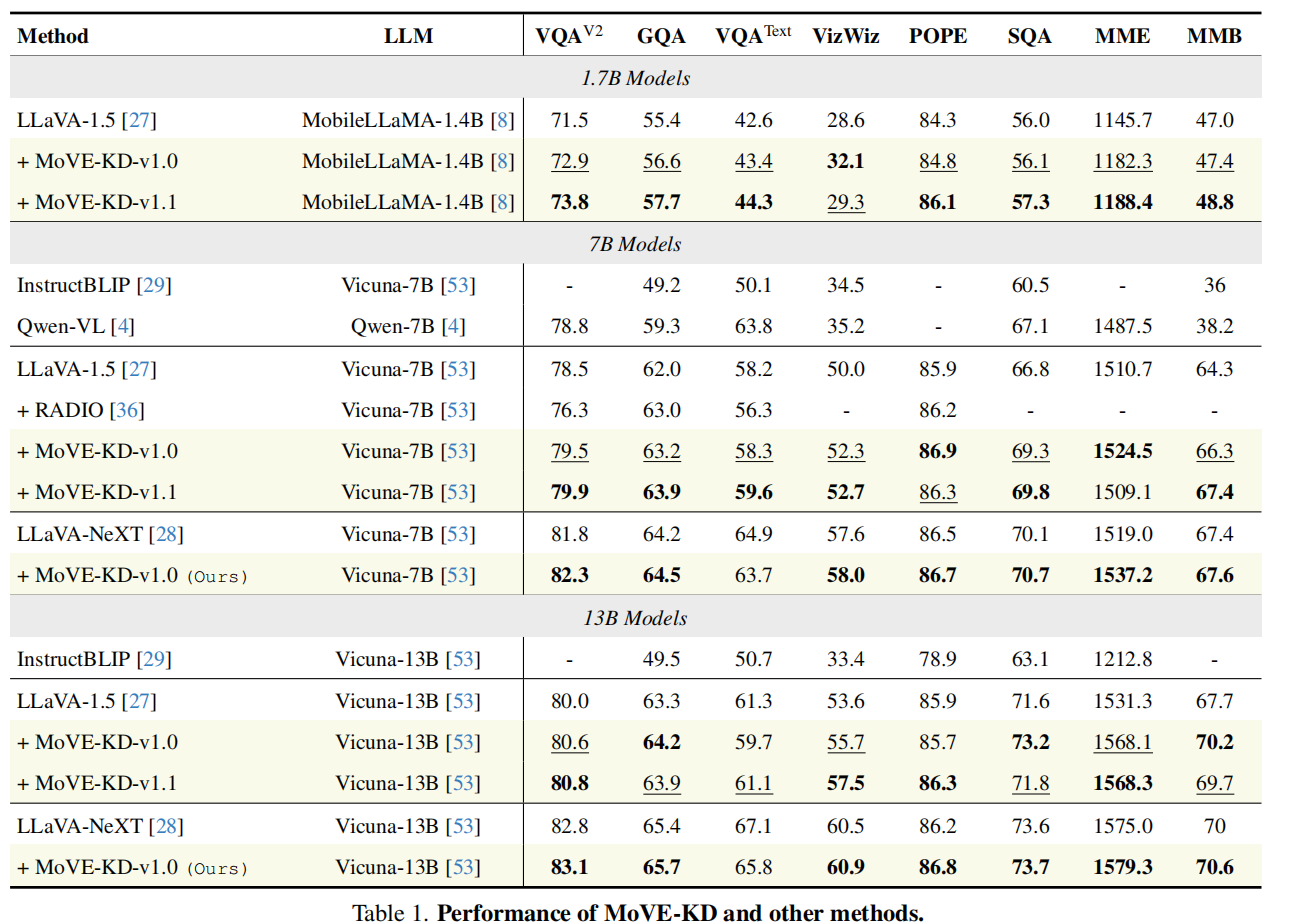
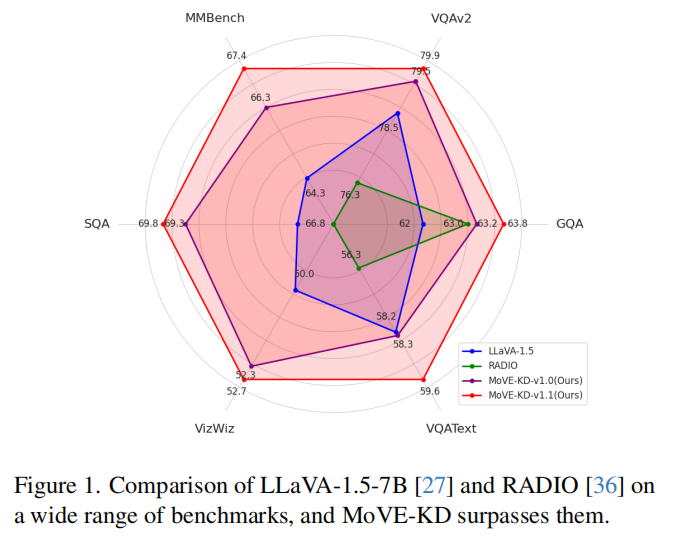
结果显示 MoVE-KD 在多个标准视觉语言任务(如 VQAv2、ScienceQA、GQA 等)上显著超越 LLaVA、LLaVA-NeXT 等基线模型,在保持推理效率的同时获得更高的性能。
6.3 Ablation Study
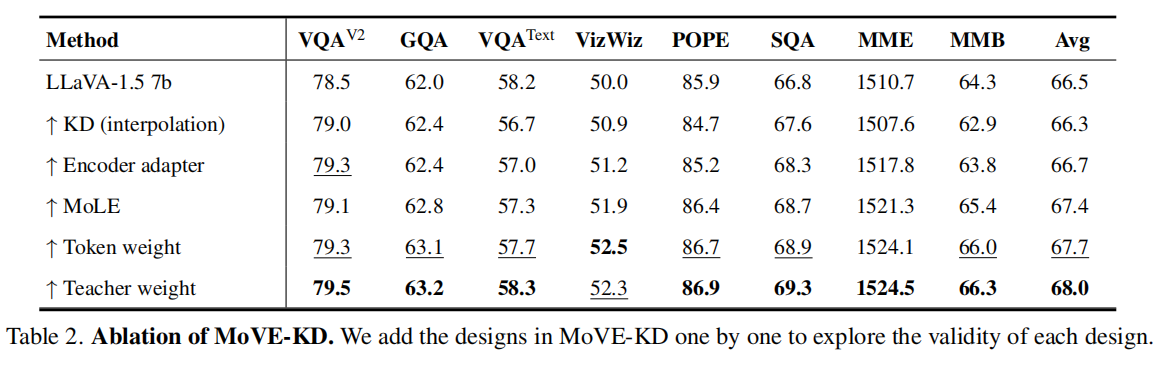
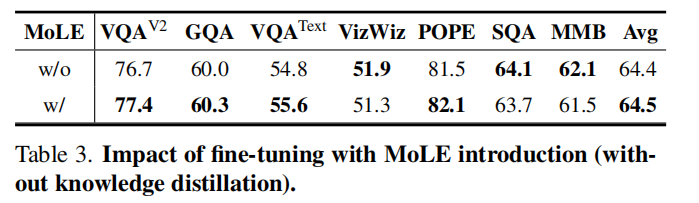
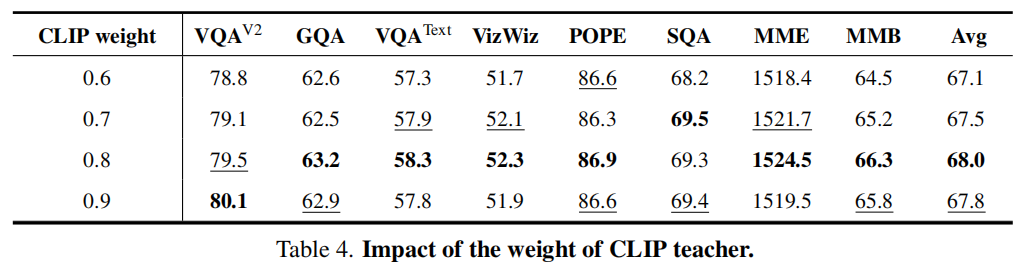
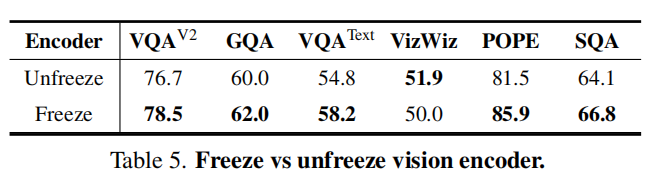
核心结论:
- 移除 MoLE 后性能明显下降 → 证明专家机制有效缓解知识冲突;
- 不使用注意力引导的 KD,模型难以聚焦关键区域;
- 减少教师数量,性能线性下降;
- CLIP 作为教师保留有助于防止遗忘并保持稳定表现。
6.4 可视化分析(Visualization)

MoVE-KD 的注意力热力图显示,学生模型成功学习到教师模型的聚焦模式,关注于语义关键区域,同时保留对背景的全局感知能力。
7. Conclusion
本文提出 MoVE-KD(Mixture-of-Visual-Encoder Knowledge Distillation),首次从知识蒸馏视角融合多个视觉编码器为单一模型。通过:
- Attention-guided 蒸馏策略;
- Mixture-of-LoRA-Experts 架构;
- 动态教师与 token 权重机制;
MoVE-KD 实现了多教师知识的高效融合,兼顾性能与推理效率。
在 LLaVA 与 LLaVA-NeXT 等框架上,MoVE-KD 均取得了显著性能提升。 作者指出,随着模型规模扩大,KD 的边际收益下降,瓶颈可能出现在视觉与语言投影模块上——未来研究应重点关注视觉-文本特征的高效无损对齐。