Conference: ICLR'26
1. Abstract
现实世界中的视觉信号在分辨率上天然具有高度的多样性,因此,让多模态大语言模型(Multimodal Large Language Models, MLLMs)具备原生分辨率(native-resolution)感知能力是一个自然且必要的目标。原则上,对于一般且直观的多模态理解任务,低分辨率图像往往已经足够;但对于包含大量细节的信息密集型图像(如文档、表格、图表等),则必须保留高分辨率输入,否则简单的缩放操作会不可避免地导致关键信息丢失。
近期的研究通过 sequence packing 技术,使模型能够处理任意分辨率和任意宽高比的图像。然而,尽管这些方法在形式上支持 Any-Resolution(AnyRes)输入,模型在低分辨率和高分辨率下的性能仍然明显下降,同时高分辨率输入还会带来显著的计算开销。
本文提出一个核心观点:“单一固定 patch size”是导致上述问题的根本原因。当图像分辨率或信息密度发生变化时,固定 patch size 在建模上天然是次优的。
为此,论文提出 Adaptive Patching(AdaPatch):一种无需额外训练、可直接插入到现有固定 patch MLLMs 中的策略。AdaPatch 根据图像的原生分辨率和信息密度动态调整 patch size,从而在不同类型、不同分辨率的图像上取得更稳定、更优的性能。实验表明,该方法在不增加训练成本的前提下,显著提升了 AnyRes 场景下的准确率和稳定性;此外,论文还提出了一种训练版方法,进一步增强模型对动态 patch size 的适应能力。
2. Introduction
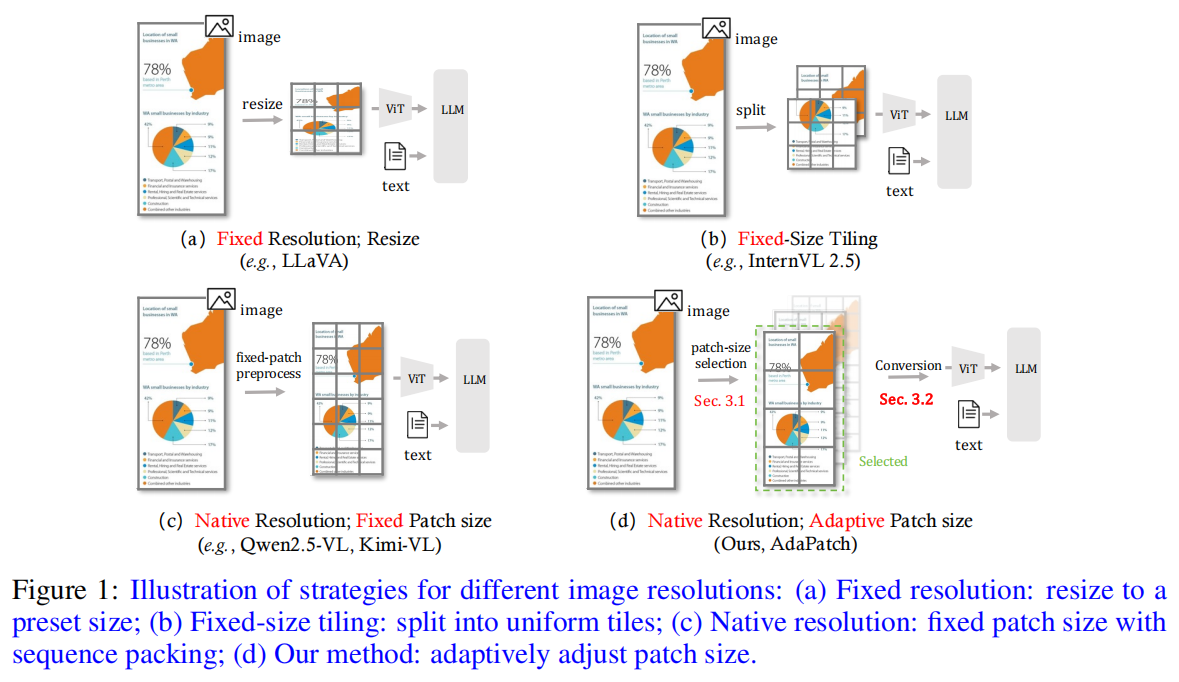
早期的多模态大模型(如 LLaVA、InternVL 系列)通常依赖固定分辨率的视觉编码器:要么将输入图像统一 resize 到某个标准尺寸,要么先切分成多个 tile 再分别处理。这类预处理不可避免地会改变原始视觉内容,对于需要保留细粒度细节或整体结构的任务(例如图表、示意图)尤其不利。
受 NaViT 启发,近期工作开始直接保留图像的原生分辨率,并将图像划分为固定大小的 non-overlapping patches,使 token 数量随分辨率线性增长。随后通过 sequence packing 将多张图像的 token 序列拼接为一个长序列,并通过 block-diagonal attention mask 保证不同图像之间不互相注意。Qwen2.5-VL、Ovis2.5、Kimi-VL 等 SOTA 模型均采用了这一范式,并宣称支持任意分辨率输入。
然而,本文通过系统性实验指出:当前 AnyRes 设计并未真正实现“原生分辨率鲁棒性”。在跨越大范围像素预算的测试中,模型性能在不同分辨率区间显著波动,且在极低或极高分辨率下普遍退化。
论文进一步分析发现,问题的根源在于:
- 在低分辨率或高信息密度图像中,大 patch 会过于粗糙,无法捕获细节;
- 在高分辨率或低信息密度图像中,小 patch 过于局部,导致全局上下文建模能力不足。
因此,patch size 与分辨率、信息密度之间的失配,是 AnyRes 性能不稳定的主要架构性原因。
为解决该问题,论文提出 Adaptive Patching,其核心思想是:
根据图像的分辨率 $r$ 和信息密度 $\rho$,自适应地选择 patch size $s$。
并进一步提出一种 weight-preserving conversion,使得预训练的固定-patch MLLMs 无需重新训练即可支持任意 patch size,同时完全兼容 sequence packing。实验结果显示,该方法在多个基准上显著提升了准确率与稳定性,并在高分辨率场景下降低了 token 数量,加速推理。
本文贡献总结如下:
- 从 pixel-range 视角,系统评估了 SOTA AnyRes MLLMs 的性能,揭示其在不同分辨率下的显著退化现象;
- 从架构层面指出 fixed patch size 是 AnyRes 不稳定性的主要原因;
- 提出 Adaptive Patching(训练免费 + 训练版),在不破坏现有模型结构的前提下显著提升性能与效率。
3. Background and Motivation
3.1 MLLM 推理流程(AnyRes Setting)
考虑一个因果式 MLLM,其目标是建模条件概率: $$ p(y_t \mid y_{<t}, x) $$ 其中 $x$ 为输入图像,$y_{1:T}$ 为文本 token 序列。
整个流程可拆解为以下关键步骤:
(1)AnyRes 预处理
输入图像 $x \in \mathbb{R}^{h \times w \times c}$,其原生分辨率为 $r=(h,w)$。AnyRes 预处理模块输出图像 $\tilde{x} \in \mathbb{R}^{\tilde{h} \times \tilde{w} \times c}$,目标分辨率 $\tilde{r}=(\tilde{h},\tilde{w})$ 满足:
- $\tilde{h}, \tilde{w}$ 可被 patch size $s$ 整除;
- 总像素数位于 $[P_{min}, P_{max}]$ 区间;
- 尽量保持宽高比与原始分辨率一致。
其选择通过如下优化问题给出: $$ \min_{\tilde{h}, \tilde{w}, \gamma} (h\tilde{w}-w\tilde{h})^2 + \varepsilon[(\tilde{h}-\gamma h)^2+(\tilde{w}-\gamma w)^2] + \varepsilon^2(\gamma-1)^2 $$
随后采用双线性插值等方式进行 resize,可视为一个线性算子: $$ \tilde{x}_i = B^{\tilde{r}}_r \cdot \text{vec}(x_i) $$
(2)Patch Embedding
将 $\tilde{x}$ 划分为 $s \times s$ 的 non-overlapping patches,总数为: $$ n = \left\lfloor \frac{\tilde{h}}{s} \right\rfloor \left\lfloor \frac{\tilde{w}}{s} \right\rfloor $$
Patch embedding 层 $g_\theta$ 本质是一个 stride=$s$ 的卷积: $$ g_\theta(\tilde{x}) = \text{Conv}_\theta(\tilde{x}; s) $$ 输出 $n$ 个 $d_v$ 维视觉 token。
(3)Vision Encoder + Projector + LLM
Patch tokens 经 Vision Encoder $E_\phi$ 编码,再通过 Projector $\Pi_\psi$ 映射到语言空间,最终与文本 token 一起送入 LLM $L_\xi$。
3.2 AnyRes 性能评估动机
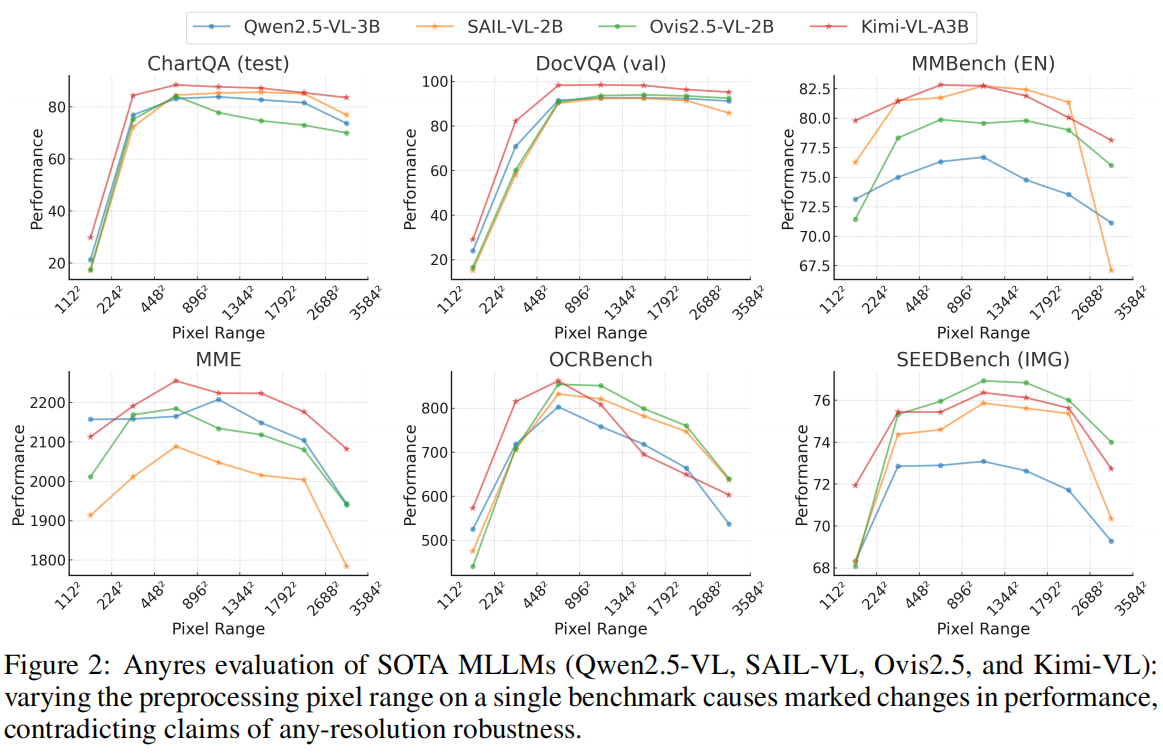
论文首次从 pixel-range 角度系统评估 AnyRes MLLMs:通过改变 $[P_{min},P_{max}]$,观察模型在不同像素预算下的性能变化。实验表明:
- 不同模型、不同任务存在明显的“偏好分辨率区间”;
- 在低像素预算下,信息密集型图像(文档、图表)性能急剧下降;
- 在高像素预算下,即使模型宣称支持高分辨率,性能仍然明显退化。
这说明:AnyRes ≠ Robust AnyRes。
3.3 固定 Patch Size 导致的不稳定性
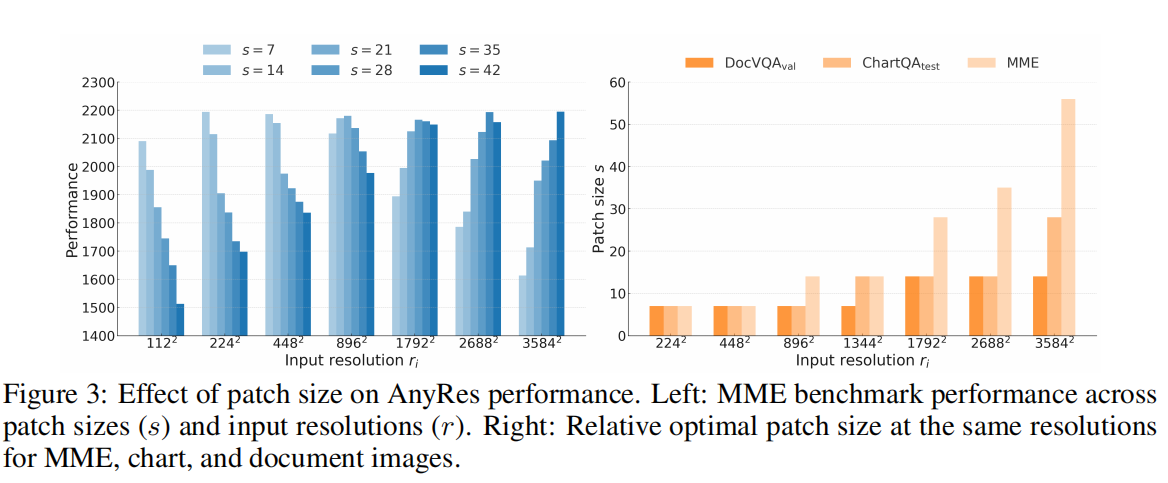
通过将 Qwen2.5-VL($s=14$)转换为多种 patch size($s \in {7,14,21,28,35,42}$),并在 MME 上跨分辨率评估,论文发现:
- 低分辨率更偏好小 patch;
- 高分辨率更偏好大 patch;
- 且最优 patch size 与信息密度强相关(文档 > 图表 > 自然图像)。
经验趋势: $$ s^* \propto \frac{r}{\rho} $$
4. Method
ADAPTIVE PATCHING
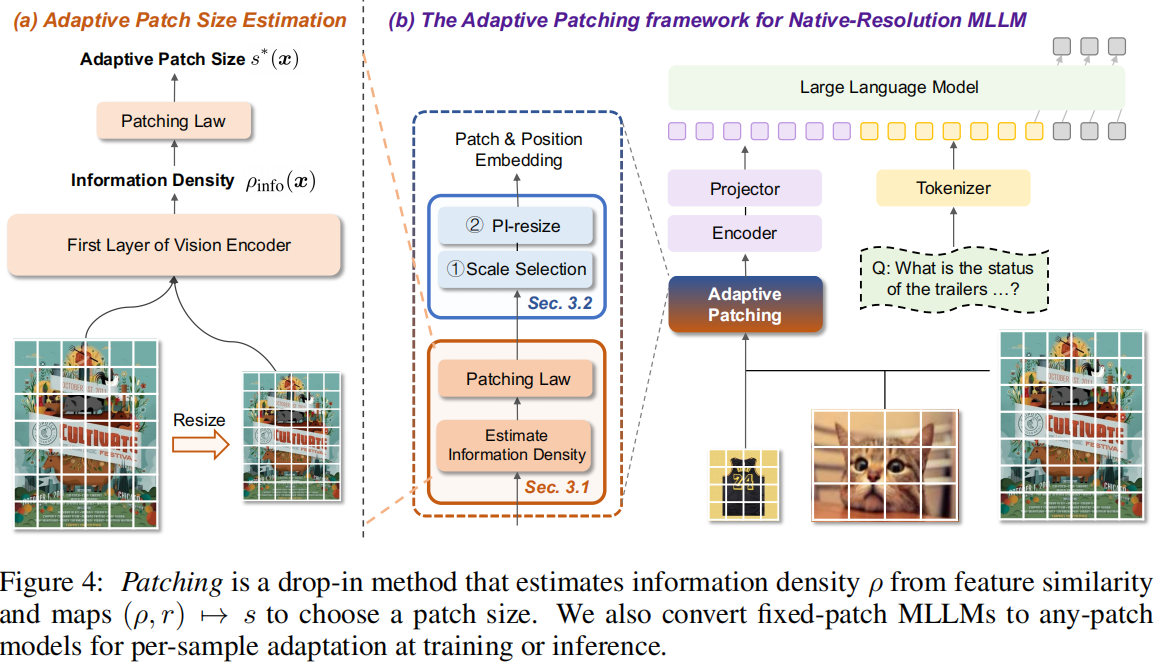
本节是全文最核心部分,提出 Adaptive Patching(AdaPatch),包括: 1)信息密度的定义与估计; 2)自适应 patch size 的计算规则; 3)如何将固定 patch 模型转换为 any-patch 模型。
4.1 信息密度估计(Information Density Estimation)
直觉:如果一张图像在下采样后,其高层语义特征变化很大,则说明该图像信息密度高。
论文形式化定义信息密度为:
$$ \rho_{info}(x) = 1 - \frac{1}{n} \sum_{i=1}^n \frac{\langle E^{[k,i]} \ast \phi(\text{conv} \ast \theta(\tilde{x}; s)), E^{[k,i]} \ast \phi(\text{conv}^* \ast \theta(B^{r/2} \text{vec}(\tilde{x}); s/2)) \rangle}{| E^{[k,i]} \ast \phi(\text{conv} \ast \theta(\tilde{x}; s)) | \cdot | E^{[k,i]} \ast \phi(\text{conv}^* \ast \theta(B^{r/2} \text{vec}(\tilde{x}); s/2)) |} $$
解释:
- 同一图像,分别在原分辨率与 $r/2$ 分辨率下提取特征;
- 比较对应 token 在 vision encoder 第 $k$ 层的 cosine similarity;
- 相似度越低,说明下采样损失越大,信息密度越高。
$\rho(x) \in [0,1]$,值越大表示越“细节密集”。
4.2 自适应 Patch Size 法则(Adaptive Patching Law)
基于经验规律 $s^* \propto r/\rho$,论文提出如下 power-law 映射: $$ s^*(x) = \text{Quantize}\Big( \text{clip}\big( \tilde{s} \cdot (\kappa(r_x)/r_0)^\alpha \cdot (\tilde{\rho}/ (\rho(x)+\varepsilon))^\beta,; s_{min}, s_{max} \big) \Big) $$
各参数含义:
- $\kappa(r)$:分辨率标量(如 $\min(h,w)$);
- $r_0=896$、$\tilde{s}=14$、$\tilde{\rho}=0.2$:预训练模型基准值;
- $\alpha, \beta$:控制分辨率 / 密度敏感度;
- Quantize:映射到离散 patch size 集合;
- clip:限制 patch size 范围。
该规则同时满足:
- 分辨率越高,patch 越大;
- 信息密度越高,patch 越小。
4.3 固定 Patch → Any-Patch 转换
(1)Pseudo-Inverse Resize(训练免费)
目标: 为每个 patch size $s_i$ 构造对应的卷积核 $\theta_i$,使得:
$$ conv_{\theta_i}(x_{r_i}; s_i) \approx conv_{\theta}(x_r; s) $$
核心思想:
- Resize 是线性算子 $B$:图像的缩放过程可以看作矩阵运算。
- 卷积也是线性算子:通过线性代数的性质,可以将两者的变换对齐。
- 伪逆对齐:通过伪逆(Pseudo-inverse)运算,在不改变原始卷积权重 $\theta$ 的情况下,推导出适应新尺寸 $s_i$ 的权重 $\theta_i$。
该方法无需重新训练 Vision Encoder 和 LLM,仅需在推理前通过数学计算调整 patch embedding 的权重。
(2)Multi-Scale Patch Embedding(训练版)
直接维护多尺度 patch embedding,在训练过程中随机采样不同的 $s_i$,并进行联合优化:
$$ \min_{\theta_i, \phi, \psi, \xi} ; E_{(x,y), s_i} , L_\xi(x, y; s_i) $$
对比分析: 相比于“训练免费”方案,该方法通过端到端的学习,能够让模型更好地适应多尺度特征,进一步提升性能,但需要投入额外的计算资源进行训练。
5. Evaluation
5.1 Main Results
实验覆盖:
- 多种 MLLMs(Qwen2.5-VL, Ovis2.5, Kimi-VL 等);
- 多个任务(MME、Doc、Chart 等);
- 大范围像素预算。
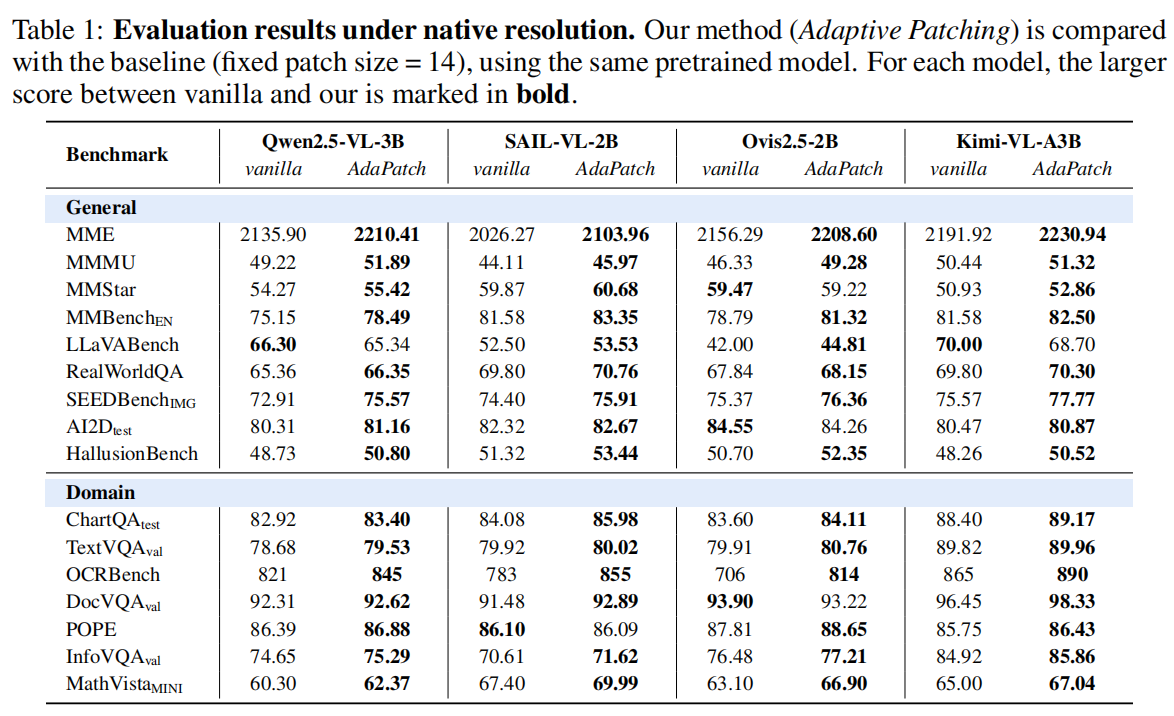
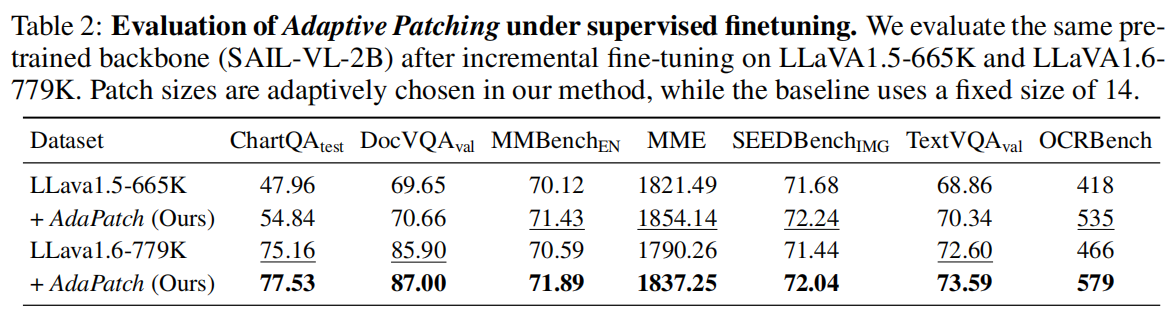
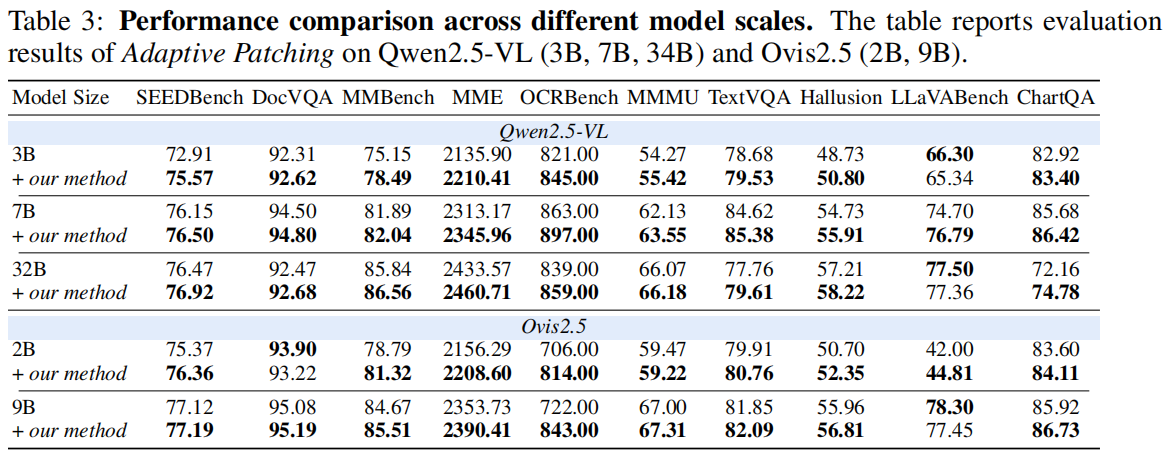
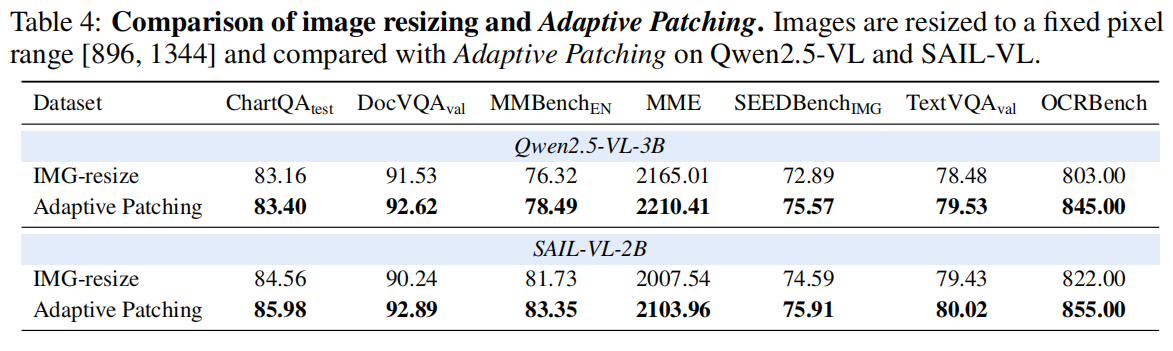
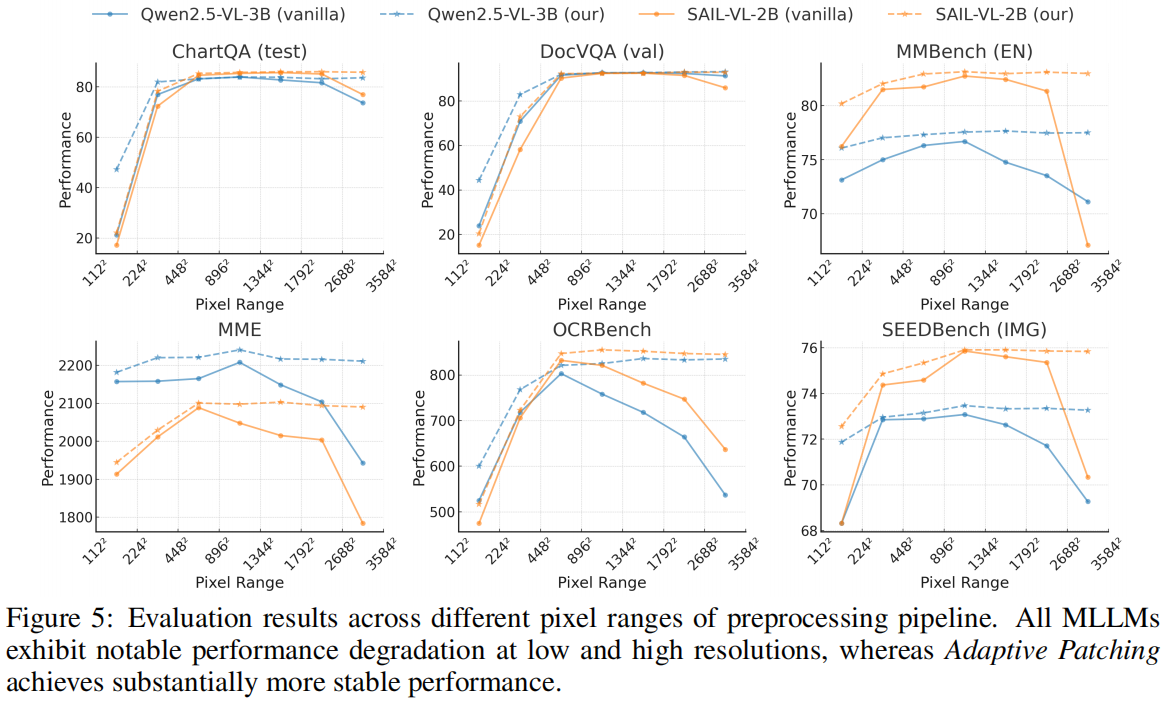
结论:
- AdaPatch 在几乎所有分辨率区间都优于 fixed-patch;
- 显著降低性能波动;
- 在高分辨率下减少 token 数量,加速推理。
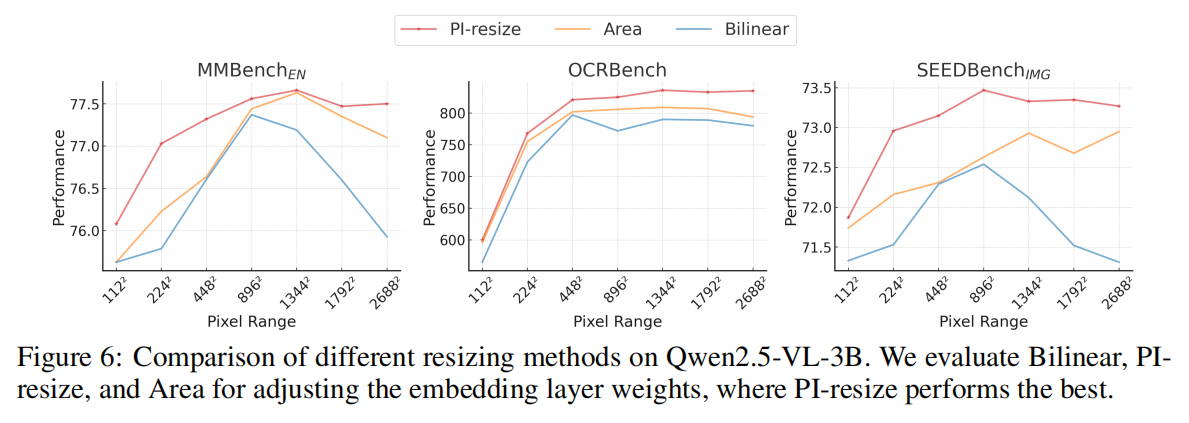
5.2 Ablation Study and Analysis
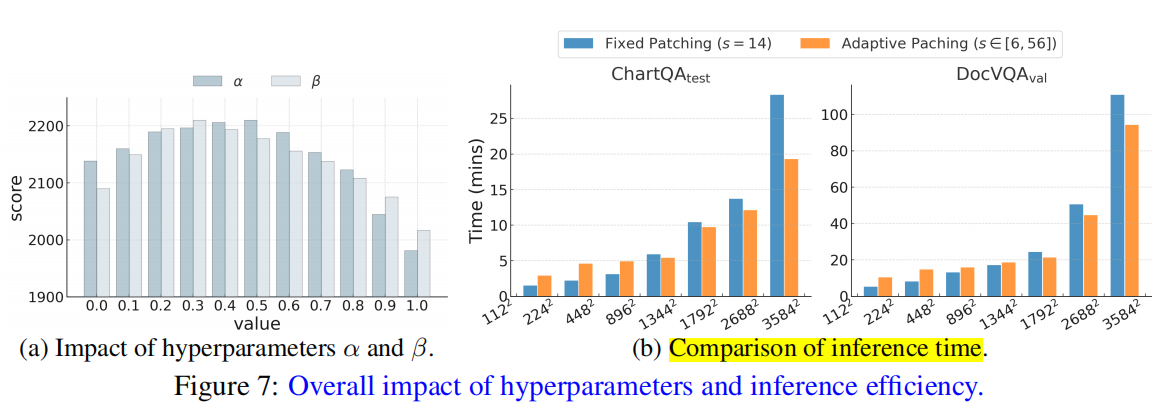
- 不同 $\alpha,\beta$ 的影响;
- 仅使用分辨率 / 仅使用密度的对比;
- PI-resize vs MSPE;
- 信息密度估计层数 $k$ 的影响。
所有实验均验证:patch size 自适应是性能提升的关键因素。
6 Conclusion
论文系统性地揭示了 AnyRes MLLMs 的核心瓶颈:固定 patch size。通过提出 Adaptive Patching,作者给出了一种简单、通用、可插拔的解决方案,在不破坏现有模型结构的前提下,实现了真正意义上的原生分辨率鲁棒性。
该工作强调:patch size 是视觉-语言建模中一个被长期忽视、但极其关键的自由度。
Limitations and Future Work
- 当前方法仍依赖启发式密度估计;
- 未来可引入更高质量多分辨率数据;
- AdaPatch 有潜力增强 thinking-with-images 模型的多尺度推理能力。