
Conference: ICLR'26
Github: https://github.com/ZhengyaoFang/PruneSID
1. Abstract
视觉-语言模型(VLMs)因产生大量视觉 token 导致计算效率低下。先前研究指出大比例 visual tokens 存在冗余,但现有压缩方法难以在“重要性(importance)保存”和“信息多样性(diversity)保留”之间取得良好平衡。为了解决该问题,论文提出 PRUNESID:一种无训练(training-free)、协同重要性—多样性(Synergistic Importance–Diversity) 的 two-stage 框架,包含:
- PSCA(Principal Semantic Components Analysis):将 tokens 按语义主方向聚类成多个语义相干组(semantic groups),确保概念覆盖。
- 组内 NMS(Intra-group Non-Maximum Suppression):在每组内按相似度动态阈值去重,保留最具代表性的 token。
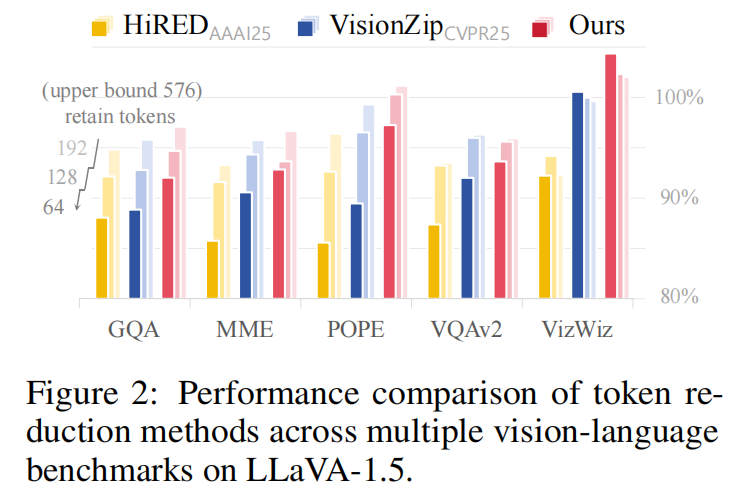
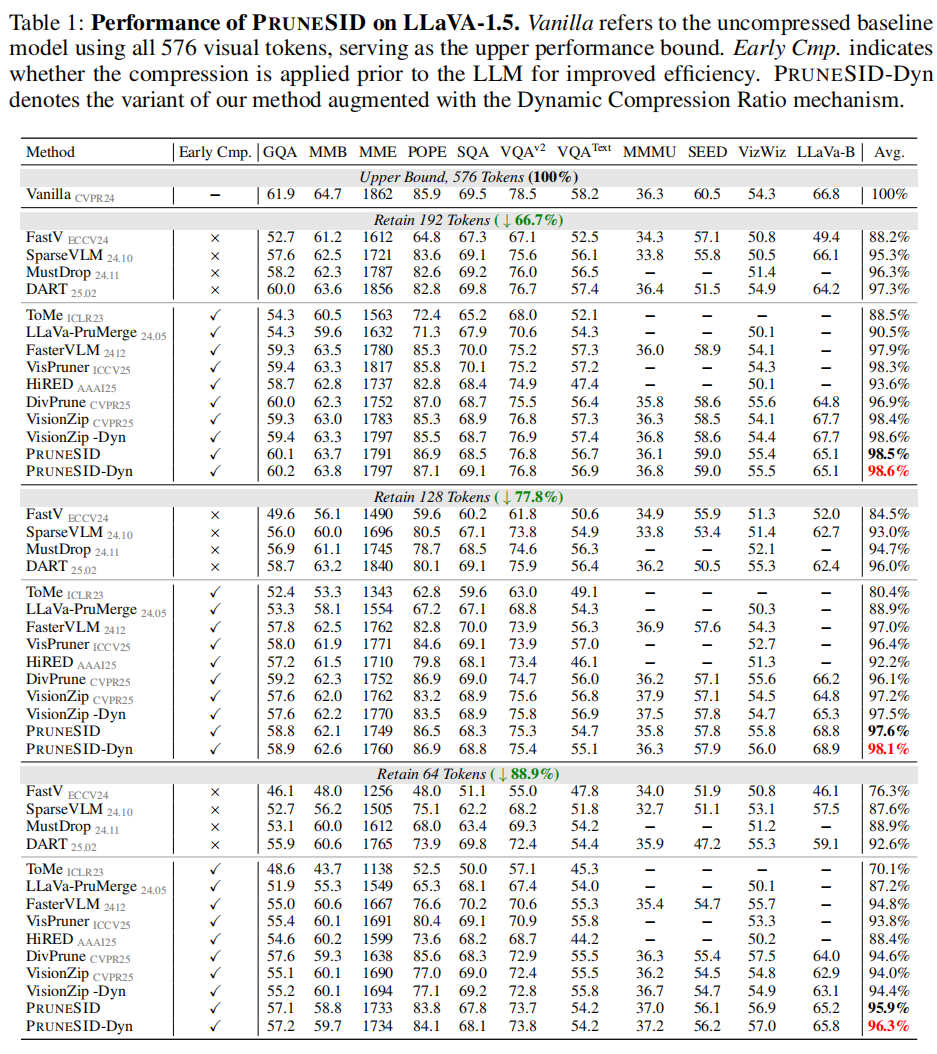
此外,PRUNESID 引入 信息感知动态压缩率(information-aware dynamic compression ratio),根据图像复杂度动态分配 token 预算,从而在多样化场景上实现更优的平均信息保留。大量实验表明:在 LLaVA-1.5 上仅保留 $11.1%$ token(64 tokens)时可达 $96.3%$ 精度;在极端压缩($5.6%$)下在 LLaVA-NeXT 仍达 $92.8%$,相较此前方法有显著提升,并在 prefilling 时间上有 $7.8\times$ 的加速。
2. Introduction

-
现状:主流 VLM(如 LLaVA-1.5 与 LLaVA-NeXT)通常为每张图像产生数百到几千 visual tokens(例如 576 或 2880),远超捕捉图像语义所需。相关研究表明约 $70%$ tokens 可丢弃而对准确率影响甚微。
-
两类现有方案:
- Attention-guided selection:依据 attention score 保留高 attention token(优点:保留局部显著性;缺点:忽视背景与多样性,可能重保重复区域)。
- Duplication-aware(相似性/去重)方法:依据相似性去重,提升多样性,但可能丢弃语义重要但相似的高 attention token。
-
本文关键观点:设计一个 组引导(group-guided) 的训练免费方法,使得“重要性”和“多样性”得到协同优化。通过 PSCA 先将 tokens 按语义方向分组,再在组内用 NMS 去冗余,同时用信息感知机制在图像间自动分配 token 预算,从而在极端压缩下仍保留丰富语义。
3. Contribution
- 提出一种无训练的视觉 token 压缩框架 PRUNESID,通过 PSCA(语义聚类)+ 组内 NMS(冗余剪枝)解决 importance–diversity 的折衷问题。
- 引入信息感知动态压缩率:基于全局 token 相似性分布计算图像信息得分 $\phi$,按其分配保留 token 数 $N’$,从而在数据集上提高平均信息保留。
- 在多个 VLM 与图像 / 视频基准上进行大规模评估,展示在极端压缩下仍能达到 SOTA,并同时保持高效的 prefilling latency。
4. Method
4.1 Overview
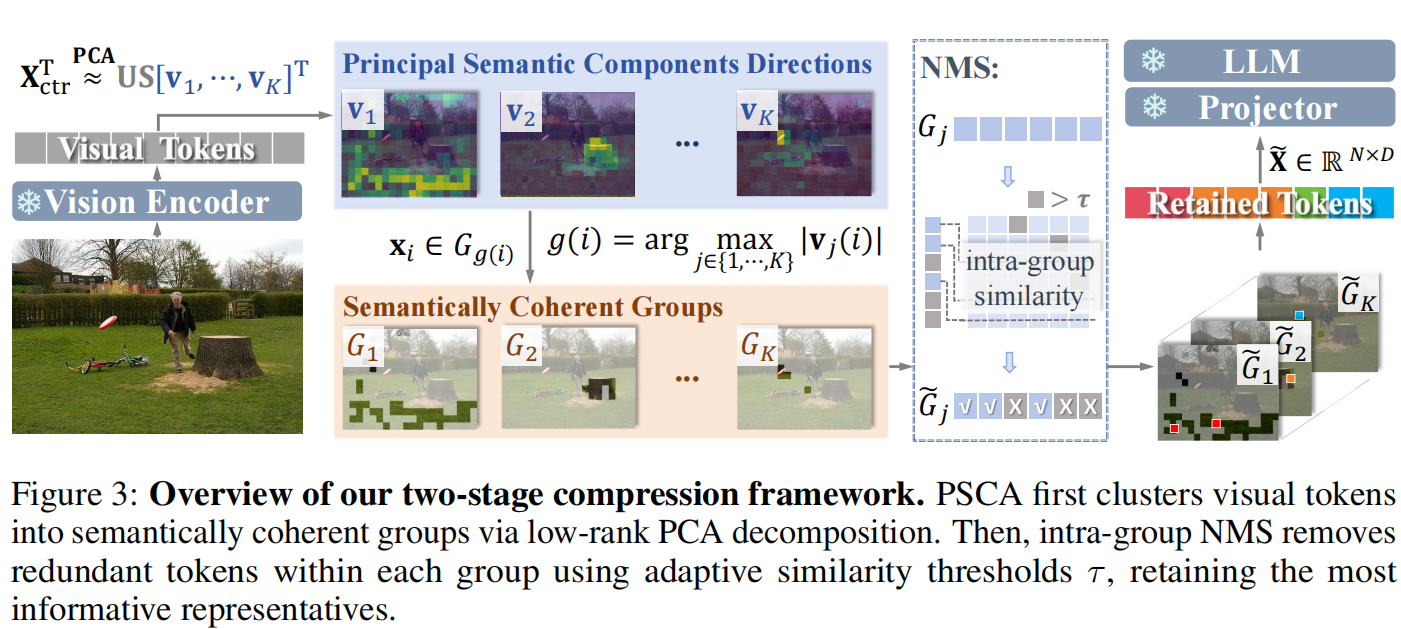
输入:视觉编码器(如 CLIP 或 ConvNeXt-L)输出的 token embedding 矩阵 $X=[x_1,\dots,x_T]\in\mathbb{R}^{T\times D}$($T$ tokens,$D$ 维)。目标:压缩为 $ \tilde X\in\mathbb R^{N\times D},\ N\ll T$,同时尽量保持语义重要性与信息多样性,以便交给 LLM 做下游推理。
整体两阶段流程(见 Fig.3):
- PSCA(Principal Semantic Components Analysis):把 token 维度作为语义轴,做低秩分解并计算 token 在 K 个主语义分量上的贡献,依据最大投影值将 token 指派到语义组 $G_k$($k=1..K$)。
- 组内 NMS(Intra-group NMS):组内按选择分数 $s_i$ 排序,贪心地使用相似度阈值 $\tau$ 做去重(若与已选 token 最大相似度 < $\tau$ 才保留),最后按组内配额取 top-$n_k$ 并拼接为最终 $\tilde X$。阈值 $\tau$ 由图像级冗余度 $\rho$ 调整。
4.2 SEMANTIC-AWARE TOKEN GROUPING VIA PSCA
论文公式与核心步骤:
先对 token 矩阵做逐 token 的 sigmoid 重缩放并跨 token 中心化:
$$ X_{ctr} = \sigma(X) - \mu,\quad \mu = \frac{1}{T}\sum_{i=1}^{T}\sigma(x_i), $$
其中 $\sigma(\cdot)$ 是逐元素 sigmoid,用于将 feature 缩放到 $[0,1]$,并使特征尺度可比。随后对 $X_{ctr}^\top$ 做低秩 PCA(SVD)分解:
$$ X_{ctr}^\top \approx U S V^\top, $$
$V\in\mathbb R^{T\times K}$ 是对 token 维度的右奇异向量矩阵,列向量 ${v_1,\dots,v_K}$ 表示 token 空间上的主语义方向。令 token 对第 $j$ 个分量的贡献为 $|V_{i,j}|$,token 指派为:
$$ g(i)=\arg\max_j |V_{i,j}|. $$
这样 $T$ 个 token 被划分为 $K$ 个语义相干组 ${G_1,\dots,G_K}$。
设计动机解析(为什么这样行得通):
- 传统 PCA 沿 feature 维度寻找方差大方向以做降维;PSCA 把“token 维”当作变量维度去分解,意在发现“哪些 token 在同一语义主方向上具有类似贡献”——本质是用线性代数在 token 间建立语义相似性(而不是直接用 spatial 相似),这对捕获全局概念(object / background / texture)有效。
4.3 INTRA-GROUP REDUNDANCY REMOVAL VIA NMS
核心要点(论文定义):
- 每个 token $x_i$ 被赋予选择分数 $s_i = |V_{i,g(i)}|$(即其在所属组主方向的绝对投影强度)。在组 $G_k$ 内按 $s_i$ 从大到小排序,然后按贪心 NMS 保留 token:若当前 token 与已保留 token 的最大相似度小于阈值 $\tau$,则保留。相似度定义为 $L_2$ 归一化后的内积:
$$ \text{sim}(x_i,x_j) = \frac{x_i^\top x_j}{|x_i||x_j|}. $$
- 全图冗余度 $\rho$ 定义为平均两两相似度:
$$ \rho = \frac{2}{T(T-1)}\sum_{i=1}^T \sum_{j=i+1}^T \text{sim}(x_i,x_j). $$
- 阈值设为 $\tau = \lambda\cdot \rho$, 其中经验设定 $\lambda = \frac{N}{32}$。
为什么要按组做 NMS:
- 按组 NMS 可以保证每个语义方向(组)都有代表 token 被保留,从而兼顾概念覆盖;在组内再进行去重可防止多个 token 重复表达同一语义细节(例如同一物体的相邻 patch),提升每个保留 token 的信息增益。
4.4 INFORMATION-AWARE DYNAMIC COMPRESSION RATIO ACROSS IMAGES
核心公式:
- 冗余度 $\rho$ 已由 Eq.(4) 定义(见上);定义图像信息得分为
$$ \phi = 1 - \rho, $$
$\phi$ 越大说明图像 token 间相似度越低(语义多样性高)。论文按 $\phi$ 为权重线性或比例地分配每张图片的保留 token 数 $N’$(写成 $N’ \propto \phi$)。
为什么有效:对于复杂(多物体/密集)场景,固定小 N 会造成信息丢失;dynamic 分配能把有限预算更合理地分配给信息量大的图像,从而提升总体表现。论文的分析(Fig.5)表明 benchmark 间 $\phi$ 分布差异会影响动态策略的收益。
4.5 THEORETICAL OVERVIEW OF PSCA–NMS PRUNING
- 定义 token 的语义信息 $I(s_i)$ 与冗余 $R(s_i,s_j)$,目标是寻找大小为 $N$ 的子集 $S’$ 使得:
$$ \max_{|S’|=N} \sum_{s_i\in S’} I(s_i) \quad \text{s.t.}\quad R(s_i,s_j)\le \varepsilon. $$
- 通过 Inclusion–Exclusion,可得信息的下界(论文 Eq.(9)-(15))解释:PSCA 增强第一项 $\sum I(s_i)$,NMS 通过约束相似度最小化 $\sum R(s_i,s_j)$,两者合力近似解原优化问题并保证冗余上界。
5. Evaluation
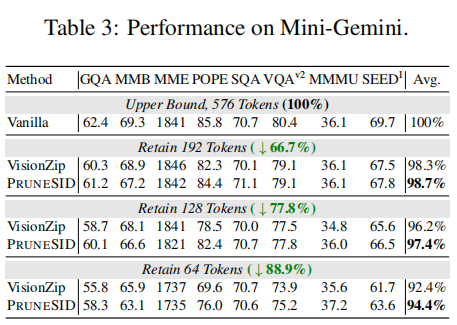
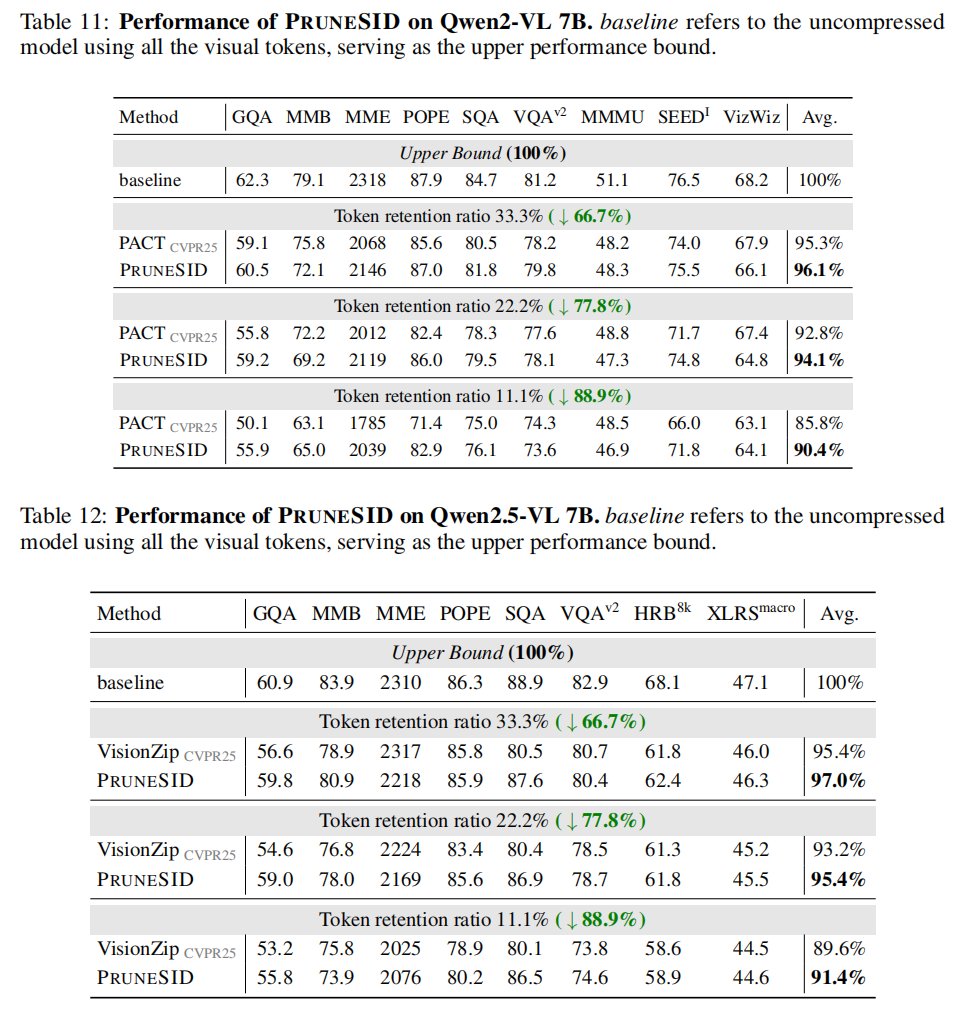
5.1 MAIN RESULTS ON IMAGE UNDERSTANDING TASKS
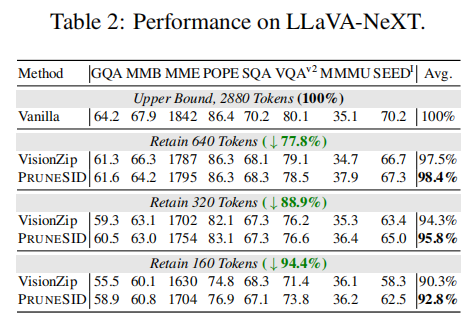
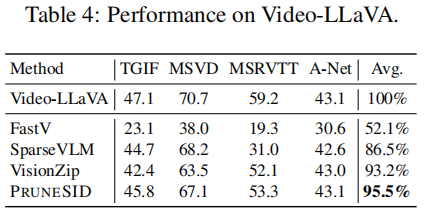
5.2 MAIN RESULTS ON VIDEO UNDERSTANDING TASKS
5.3 ABLATION STUDY
- Token Grouping Strategy(PSCA vs random vs kmeans):
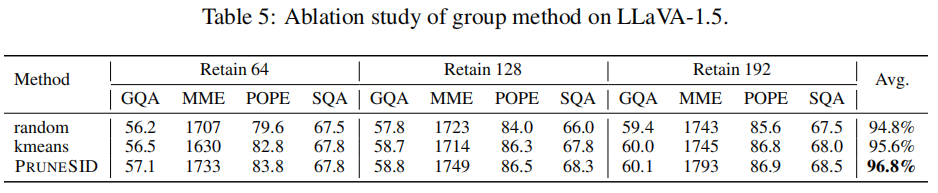
- PSCA 优于 random grouping 与直接在 token features 上做 KMeans(Table 5),解释是 PSCA 能发现 token 维上的主语义方向,比浅层聚类更能保持语义连续性。
- Group Count $K$ 的影响:
- 性能随 $K$ 呈钟形:$K$ 太小导致组过粗,无法区分细粒度语义;$K$ 太大导致组内样本过少且 pruning 不稳定。论文经验值 $K\approx N/4$ 在多种 N 下表现良好(Table 6)。
- 使用哪层 ViT 特征:
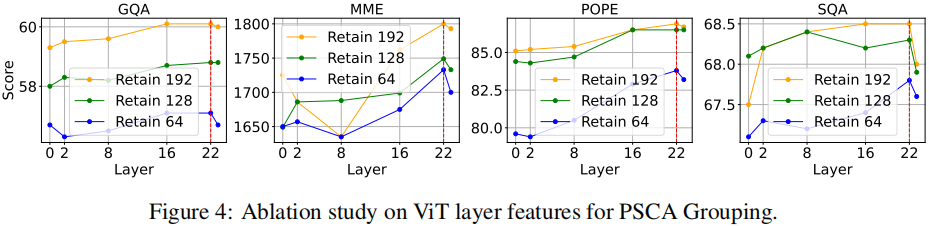
- 中后层(例如 layer 16/22)最好;最终层(23)表现在某些配置下会小幅下降(可能被 fine-tuned 或 specialized)。因此建议提取中后层作为 PSCA 的输入。
- Dynamic Compression Ratio 的消融:
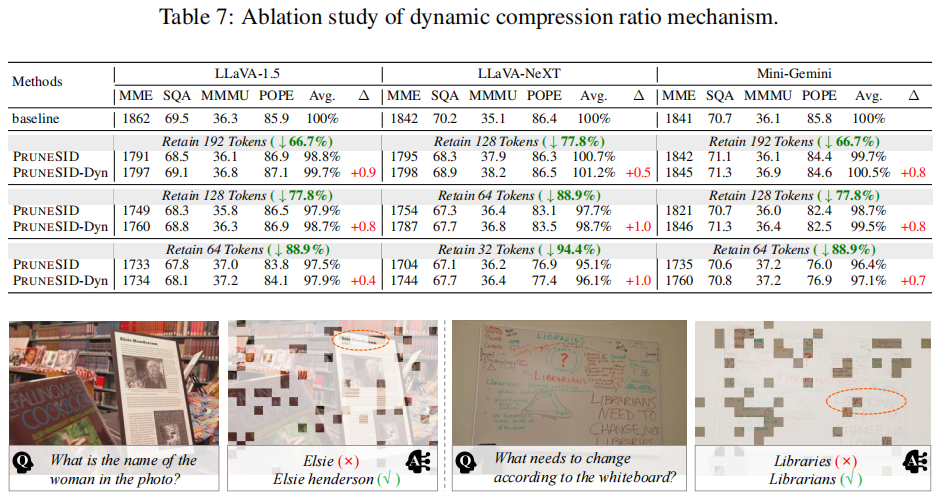
- Dynamic(PRUNESID-Dyn)在多 benchmark(尤其是信息得分变异大的如 MMMU)上带来最多到 1.0% 的提升(Table 7)。这验证了在跨图像信息分布不均时动态分配的价值。
-
组件贡献(w/o PSCA / w/o NMS):
- 移除 PSCA 或 NMS 都会使性能显著下降,表明两部分在重要性/多样性平衡上是互补的(A.3.1)。
5.4 EFFICIENCY ANALYSIS
-
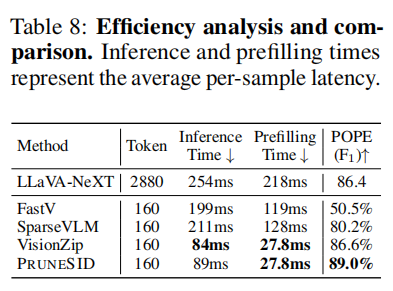
总体观察:PRUNESID 的目标不仅是维持高性能,也要在实际延迟上有显著收益。论文在 LLaVA-NeXT/POPE 上的效率测量如下(Table 8):
- 原始 LLaVA-NeXT(2880 tokens)prefilling 占总延迟 86%(254 ms/sample 总延迟,prefilling 218 ms)。
- 在 5.6% 压缩(保留 160 tokens)下,PRUNESID 将 prefilling 从 218ms 降到 27.8ms($7.8\times$ 加速),总体 inference time 降到 89ms/sample(与 VisionZip 相似),同时在 POPE 上 F1 从 86.6% 提升到 89.0%。
5.5 VISUALIZATION ABOUT LIMITATION

论文给出 Fig.6 的典型 failure case:当问题要求极细粒度信息(例如图片中某人的全名或白板上非常小的文本)时,在极端压缩率下(例如只保留 11.1%)方法可能把相关小区域 token 视为冗余而被删掉,导致 VLM 回答不完整或错误。论文建议未来引入任务/指令感知过滤来针对这类情形补偿(例如在存在 OCR/细粒度 query 时优先保留 OCR 相关 token)。
6. Conclusion
PRUNESID 提供了一个训练免费、任务不可知的视觉 token 压缩方法:通过 PSCA 做语义分组、通过组内 NMS 去冗余,并配合信息感知动态压缩率实现图像间自适应 token 分配。大量实证证明该方法在多 VLM、图像与视频任务上能在极端压缩下仍接近全精度并保持显著 prefilling 加速。论文同时指出方法在极细粒度任务上的局限与未来可扩展方向(加入任务/指令提示,使压缩带“感知”性)。