
1. Motivation
大型多模态模型(LMMs)通常采用编码模块将多模态数据输入转换为 Embedding,然后将其馈送给语言模型进行进一步处理。然而,由于其推理流程的固有复杂性,高效地服务 LMM 仍然极具挑战性。传统的服务引擎将编码模块和语言模型部署在一起,导致显著的资源干扰和紧密的数据依赖。最近的研究通过将编码模块从模型中解(Disaggregating),采用预填充-解码(Prefill-Decode)分离的设计风格来缓解这一问题。尽管如此,这些方法未能充分利用单个请求内(Intra-request)和多个请求间(Inter-request)的并行性。
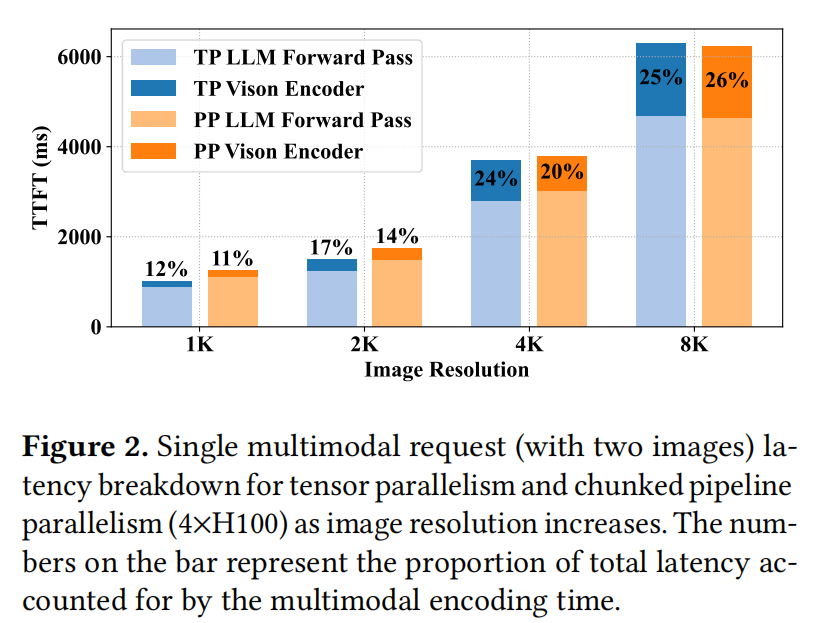
与纯语言模型相比,多模态模型推理通常依赖于更丰富的提示输入,如图 1 所示。当前的 LMM 依赖额外的编码器来生成与传统 LLM 兼容的多模态输入 Embedding。尽管如此,LMM 面临另一个挑战:在单个请求内编码所有多模态数据会引入显著的延迟(其比例可高达 26%,如图 2 所示),这会干扰 LLM 的前向计算。
随着模型规模的不断增长,LLM 或 LMM 的分布式部署已成为主流。最广泛使用的方法包括张量并行(Tensor Parallelism, TP)和流水线并行(Pipeline Parallelism, PP)。
- 张量并行 (TP): 通常用于具有高带宽互连的节点内,可有效降低推理延迟。
- 流水线并行 (PP): 通常用于带宽有限的节点间场景,可提高推理吞吐量。
最近提出的 分块流水线并行 (Chunked Pipeline Parallelism, CPP) 1改变了这一格局,使流水线并行能够实现与张量并行相当的延迟降低。具体而言,CPP 将整个输入 Embedding 分割成多个块(Chunks),并按原始输入顺序对预填充(Prefill)计算进行流水线处理,允许单个请求的不同块在流水线内同时处理。如图 2 所示,对于单个多模态请求,流水线并行和张量并行可以保持相当的推理延迟。
2. Contribution
为了实现交错和重叠执行,作者提出了 RServe,这是一个 LMM 推理系统,能够以全并行方式高效编排请求内(Intra-request)和请求间(Inter-request)的流水线。
-
请求内优化 (Intra-request Optimization): 对于具有丰富多模态输入(即大量图像)的请求,RServe 将多模态编码过程与 Prefill 执行重叠,构建请求内流水线。为实现这一点,RServe 将输入 Embedding 分为两类:
- 就绪 Embedding (Ready embeddings): 包括文本 Embedding 和已经编码完成的多模态 Embedding。
- 未就绪 Embedding (Not-ready embeddings): 指尚未被编码模块处理的那些数据。 RServe 以细粒度从左到右顺序编码多模态数据,允许 LLM 在部分 Embedding 生成后立即启动 Prefill 执行。
-
请求间优化 (Inter-request Optimization): 为了保持高吞吐量和低延迟,RServe 进一步对不同请求进行批处理执行,并利用 可调度 Token (Schedulable Tokens) 来平衡各个微批次(Micro-batches)之间的计算负载,构建请求间流水线。
-
系统设计: RServe 的请求内流水线是一种独立于并行方法的优化,而请求间流水线则将请求内流水线与流水线并行相结合。
本文的贡献如下:
- 作者强调了多模态编码和 LLM 前向传递之间的请求内并行性尚未被充分利用。
- 作者提出了 RServe,这是一个高效的 LMM 推理系统,它编排请求内和请求间流水线,在保持高吞吐量的同时降低延迟。
- 在代表性 LMM 上的实验结果表明,RServe 将延迟降低了高达 66%,并将吞吐量提高了高达 109%。
3. Background
3.1 模型推理过程 (Model Inference Procedure)
3.1.1 LLM 推理过程
- 预填充阶段 (Prefill phase): 处理整个输入提示,构建 KV 缓存,并生成第一个输出 Token,通常导致高 GPU 利用率。
- 解码阶段 (Decode phase): 通过重用 KV 缓存生成后续 Token;该阶段的 GPU 利用率相对较低,因此通常采用跨多个请求的批处理来提高效率。
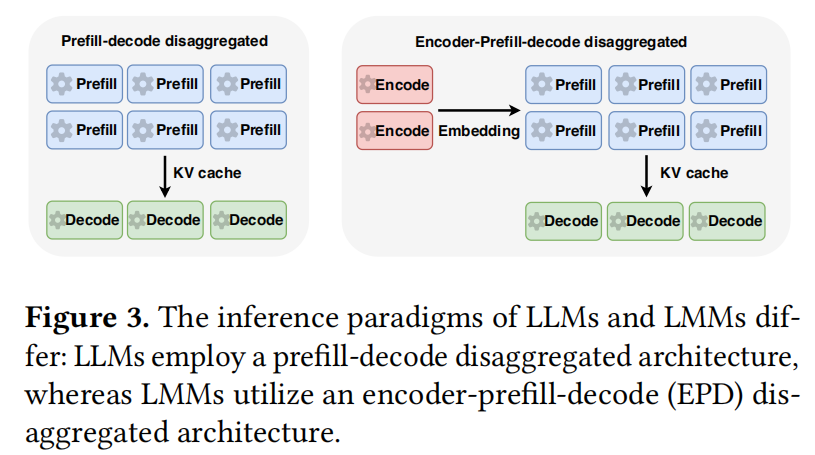
为了缓解 Prefill 引入的延迟瓶颈,最近的工作提出了 Chunked Prefill,它将 Prefill 计算划分为更小的段,并将它们的执行与批处理解码交错进行。虽然这种策略减少了解码的延迟,但它不能完全消除 Prefill 和解码之间的资源干扰。为了解决这个问题,提出了 预填充-解码分离 (Prefill-Decode Disaggregated) 架构(如图 3 所示),其中 Prefill 和解码操作被分配到单独的节点,通过在它们之间传输 KV 缓存来实现高效协作。
3.1.2 LMM 推理过程
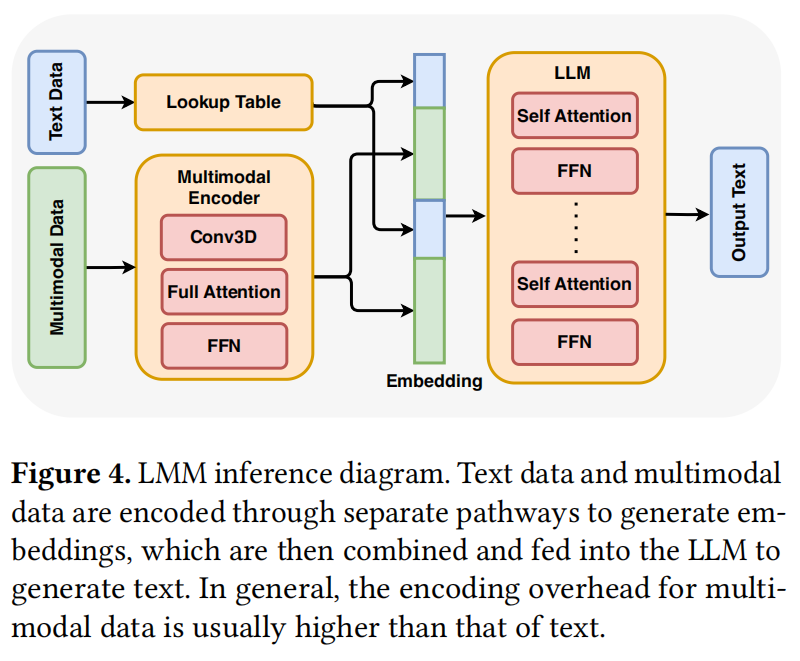
如图 4 所示,LMM 最初采用多模态编码器将多模态输入转换为 Embedding。该编码器通常包含 3D 卷积层、注意力机制和前馈网络(FFN)等组件,旨在捕获不同数据模态之间的空间和时间依赖性。相比之下,文本数据仅需通过词表查找即可获得 Token Embedding,计算量微乎其微。因此,多模态输入的编码引入了巨大的计算开销,特别是在处理高分辨率图像、长视频序列和复杂音频信号时。
源自多模态和文本输入的 Embedding 随后被整合并传入 LLM 以进行进一步的推理和生成任务。随着多模态数据量和复杂性的增加,编码阶段成为关键瓶颈,往往对整体推理延迟造成巨大影响。
最近的研究表明,将编码和 Prefill 操作放在一起会加剧它们之间的干扰,因为每个操作都必须等待另一个完成。为了解决这个问题,最近的一项研究提出了 编码器-预填充-解码 (Encoder-Prefill-Decode, EPD) 分离架构(图 3),其中编码器和 Prefill 计算在单独的设备或节点上执行。在该设计中,编码器 Worker 专门负责多模态数据编码,并将结果 Embedding 传输给 Prefill Worker。一旦 Prefill Worker 接收到这些 Embedding,它可以立即开始 Prefill 计算。这种分离消除了编码和 Prefill 操作之间的相互干扰。
3.2 模型推理并行性 (Model Inference Parallelism)
3.2.1 分块流水线并行 (Chunked Pipeline Parallelism, CPP)
当前的模型服务系统使用 Chunked Prefill 来处理超长上下文。具体来说,整个提示被分成多个块以便逐个处理。由于单个块的 Prefill 计算仅依赖于前面的块,作者可以对这些块的计算进行流水线处理,并重叠不同块的执行。一旦前一个块在一个阶段完成,下一个块就可以利用前一个块的 KV 缓存并开始 Prefill 计算。通过这种方式,CPP 可以大大降低 Prefill 计算的延迟。

图 5 展示了传统流水线并行(Vanilla PP)和 CPP 的对比。
- Vanilla PP: 下一个块的 Prefill 计算只能在前一个块完全完成所有阶段后才能开始。
- CPP: 允许下一个块的 Prefill 操作在前一个块完成给定阶段后立即开始。
3.3 LMM 中的请求内与请求间并行 (Intra- and Inter-request Parallelism in LMM)
CPP 利用了 LLM 推理中的请求内并行性。LMM 引入了额外的多模态数据编码操作,这可以自然地集成到 CPP 中。当前面的 Embedding 就绪时,作者可以立即开始就绪 Embedding 的 Prefill 计算,而不是等待请求中的所有多模态 Embedding 完成。在这种情况下,多模态编码可以与 Prefill 计算重叠,进一步缓解耗时的编码操作。
然而,编码和 CPP 之间存在 数据依赖性 。图像 Token 必须在 Prefill 操作之前被编码。因此,作者需要仔细地交错编码和 Prefill 操作。

图 7 展示了 LMM 推理过程中的请求内和请求间并行性:
- Vanilla 服务系统: 第一个 Worker 负责编码和 Prefill 操作,两者相互干扰。
- EPD 分离系统: 编码器 Worker 负责多模态编码计算,其余 Prefill Worker 以流水线方式执行语言模型。
- 请求间并行 (Inter-request parallelism): 请求 2 的编码与请求 1 的 Prefill 计算重叠时发生。
- 请求内并行 (Intra-request parallelism): 当同一请求内的编码或 Prefill 操作与其他 Prefill 计算并发执行时产生。
为了充分实现请求内和请求间并行,必须解决几个关键挑战:
- 确定 Embedding 的 Prefill 资格: 只有当相应的文本或多模态 Embedding 就绪时,Prefill 操作才能开始,这使得依赖管理至关重要。
- 管理 Embedding 存储: 鉴于 GPU 显存有限,需要高效的驱逐策略来移除未使用的 Embedding,同时保持计算效率。
- 细粒度编码多模态数据: 编码粒度越小,重叠计算的机会越大;然而,编码的计算效率会降低。
- 跨多个请求调度 Prefill 计算: 这不仅涉及优化请求内执行,还需要协调请求间流水线以提高吞吐量。
4. Design
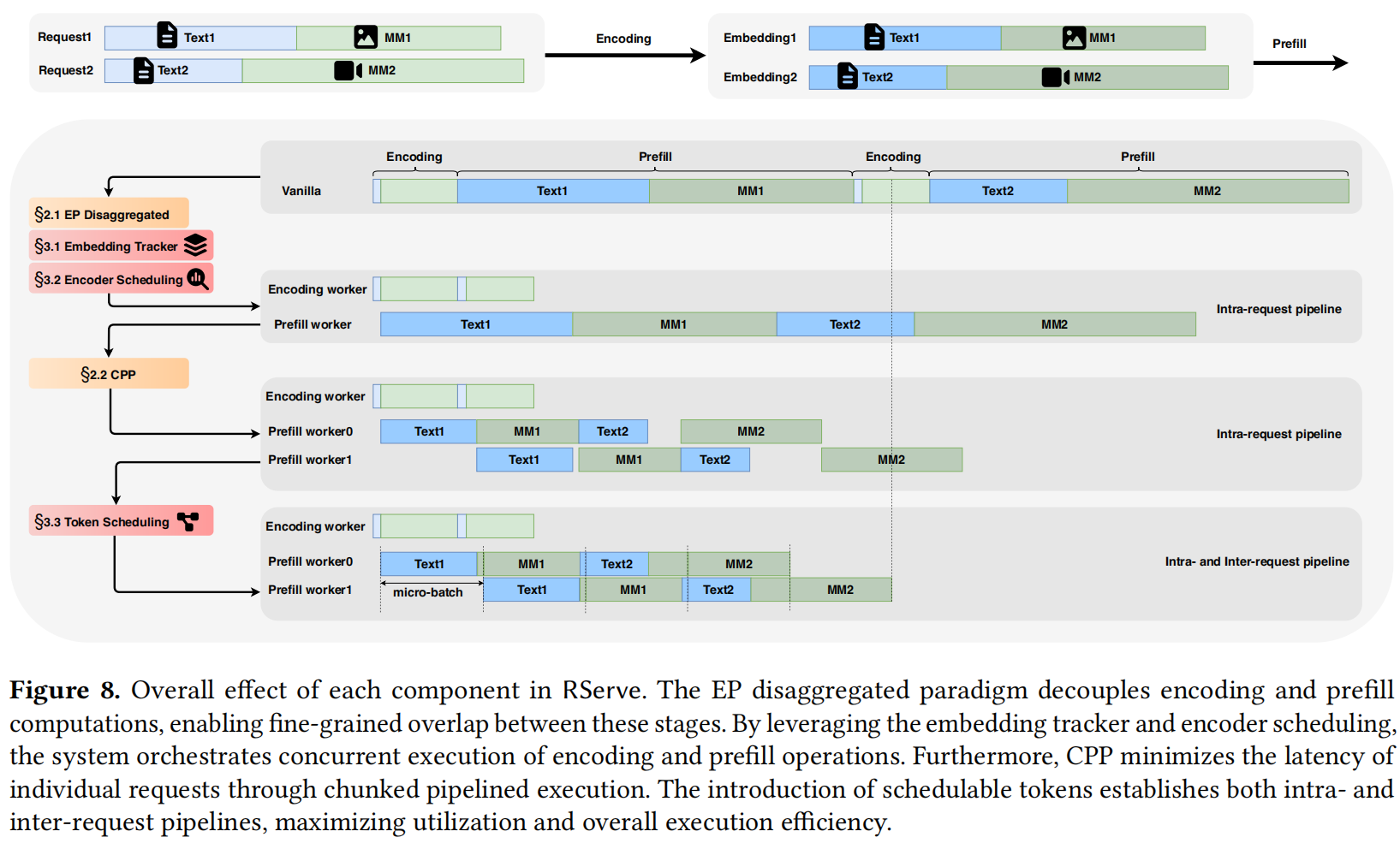
为了更好地编排请求内和请求间流水线,作者设计了 RServe,这是一个高效的 LMM 服务系统,旨在降低富多模态请求的延迟。RServe 建立在 EP 分离架构之上,通过维护每个请求的 Embedding 追踪器 (Embedding Tracker) 来精心组织多模态编码和 Prefill 计算的执行。Tracker 指示哪些 Embedding 已经就绪(Ready)可以进行 Prefill,并在相应的 Prefill 操作完成后负责释放它们。为了实现细粒度的重叠,作者以分块(Chunked)粒度调度编码计算。为了配合多请求调度,作者提出了一种 Token 调度 (Token Scheduling) 方法来管理不同请求的执行进度。图 8 展示了 RServe 各个模块对 LMM 推理延迟和调度的影响。
4.1 Embedding Tracker for Intra-request Pipeline
为了协调多模态编码和 Prefill 操作的执行,RServe 采用了一个 Per-request Embedding Tracker(每个请求独立的 Embedding 追踪器。
- 功能与初始化: 该 Tracker 维护从多模态数据生成的 Embedding,并管理它们对 Prefill 计算的就绪状态。当创建一个新请求时,Tracker 会初始化其元数据,包括 Embedding 的维度和 就绪标记 (Readiness Tags)。
- 维度记录: 记录文本和多模态 Token 的数量,以及每个 Token Embedding 的隐藏层大小。
- 就绪标记: 对于 Embedding 已就绪的文本 Token 设置为
true,对于 Embedding 需要进一步计算的多模态 Token 设置为false。 - 状态更新与存储: 随着多模态 Embedding 的生成,Tracker 会更新其就绪标记,并将新的 Embedding 存储在请求中的对应位置。
- 显存释放 (Memory Release): 一旦 Embedding 被送入 LLM 进行 Prefill,Tracker 会立即释放它们以避免显存泄漏(Memory Leaks)。这种机制确保了正确的执行顺序,并在 Embedding 可用时立即触发 Prefill 计算 。
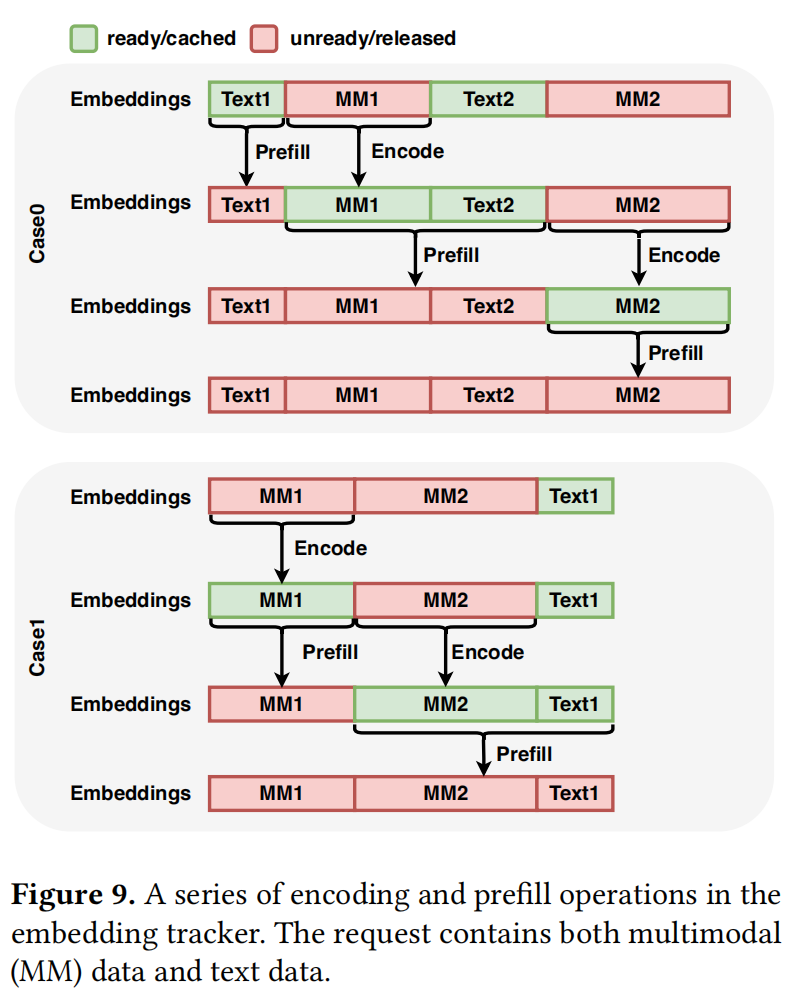
工作流详解 (如图 9 所示): 当请求创建时,RServe 首先获取所有文本 Embedding(开销可忽略),并为多模态 Embedding 预留位置。
- Case 0 (并行执行): RServe 首先调度 Text1 的 Prefill,同时并发执行 MM1 的编码。一旦 MM1 编码完成,它会触发 MM1 和 Text2 的 Prefill,同时开始 MM2 的编码。当 MM2 Embedding 就绪时,RServe 执行 MM2 的 Prefill。
- Case 1 (连续多模态项): 即使输入包含连续的多个多模态项(如 MM1 和 MM2),RServe 也能在 Prefill MM1 的同时编码 MM2。这表明 RServe 不要求输入遵循特定的模式(例如必须文本与图像交替),只要输入包含多个多模态元素,就能实现重叠计算。
4.2 Encoder Scheduling for Intra-request Pipeline
当前的 LMM 服务系统通常将请求内的所有多模态输入作为一个批次(Batch)一起处理。虽然这种策略简化了执行,但它严格强制了一种依赖关系,即 Prefill 阶段必须等到所有多模态数据完全编码后才能开始 。这种僵化的顺序不仅增加了端到端延迟,还阻碍了编码和 Prefill 计算之间的有效重叠。
为了解决这个瓶颈,理想情况下编码应以 流式 (Streaming) 方式进行,即一旦生成 Embedding 就立即转发给 LLM 进行 Prefill。这将实现编码器和 LLM Worker 之间的细粒度流水线并行。然而,在实践中,单个请求通常包含数十个多模态项(如多张图像、音频段或视频帧)。严格地逐个编码会导致执行效率极低,因为较小的 Batch Size 会严重低估 GPU 利用率,使编码计算变为内存受限(Memory-bound)。

为了平衡延迟和硬件效率,RServe 采用了一种针对 Embedding 的 批处理策略 (Batching Strategy)(Algorithm 1):
- 逻辑机制: 算法维护一个等待队列 $Q$ 和一个缓冲区 buffer 。
- 批量聚合: 多模态项(Multimodal items)被组织成包含至少 $C$ 个多模态 Token 的批次,每个批次一起编码。如果缓冲区内的数据量达到 $C$,则触发 Encode(buffer) 并重置缓冲区。
- 执行单元: 由于多模态编码无法在 Token 级别分割,RServe 将每个多模态项视为不可分割的执行单元并将它们聚合到批次中。
这种策略确保编码器在不等待整个请求就绪的情况下实现足够的并行性,既利用了与 Prefill 计算的重叠,又保持了较高的编码效率。
4.3 Token Scheduling for Inter-request Pipeline
除了请求内流水线,现代 LLM 服务系统还探索了请求间流水线,即多个请求在一个共享的 Token 预算(Token Budget)下被批处理在一起 98。然而,当扩展到 LMM 服务时,这种方法遇到了新的挑战。具体来说,Token 调度必须等到相应的多模态 Embedding 生成后才能进行,因为 Prefill 计算需要它们 。这在多模态编码和 Prefill 调度之间建立了紧密的数据依赖关系,因为在 Embedding 完全生成之前无法调度 Prefill,这使得高效调度策略的设计变得复杂。

为了解决这一挑战,RServe 引入了 可调度 Token (Schedulable Tokens) 的概念(Algorithm 2):
- 定义: 一个 Token 变为“可调度”当且仅当:
- 其对应的多模态 Embedding 已经就绪(Ready)。
- 其前序 Token 要么已经完成了 Prefill 计算,要么本身也已变为可调度。
- 全局预算管理: 基于此机制,RServe 动态维护一个可调度 Token 池,并使用全局 Token 预算 $B$ 来跨不同请求对它们进行批处理 。
- 调度流程: 在每次调度迭代中,Token 被取出队列,评估其资格,如果剩余 Token 预算允许,则将其放入执行批次 $S$ 。
- 未完成请求处理: 无法完全调度的请求被标记为“不完整”(Incomplete)并重新插入等待队列 $Q$ 的头部,并更新状态,确保它们将在下一轮调度中被及时重新访问。
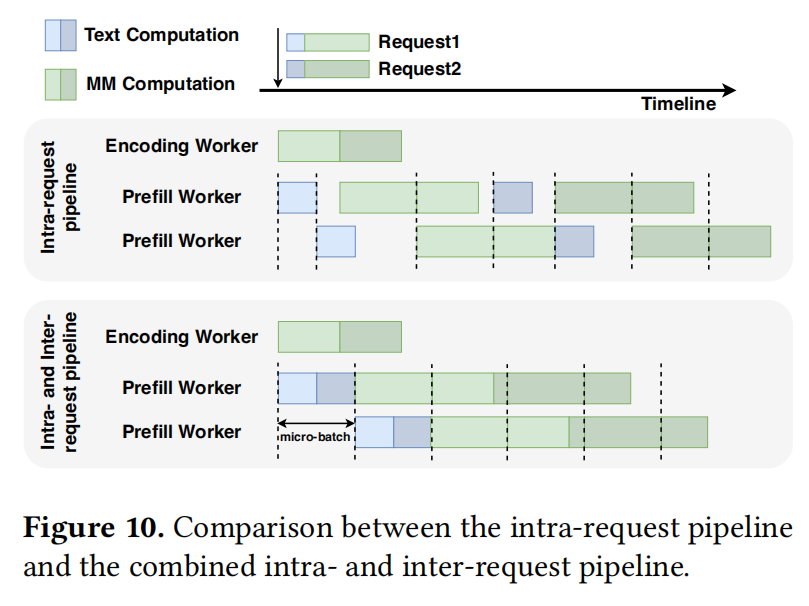
综合效果 (如图 10 所示): 通过一旦 Embedding 可用就增量更新 Token 状态,RServe 实现了跨异构多模态请求的高效 Prefill 批处理。这种机制不仅支持请求内流水线,还有效构建了请求间流水线,从而在 LMM 服务中同时实现了低延迟和高吞吐量。
图 10 展示了采用请求内和请求间流水线调度的优势。
- 仅依赖请求内流水线时,系统难以充分利用每个微批次内的可用 Token 预算,导致显著的流水线气泡(Pipeline Bubbles)和计算资源利用不足。
- 相比之下,通过结合请求内和请求间流水线,系统可以聚合来自多个请求的 Token 来填满微批次。这种策略不仅缓解了流水线中的空闲时间,还实现了延迟和吞吐量之间的平衡。
4.4 Implementation
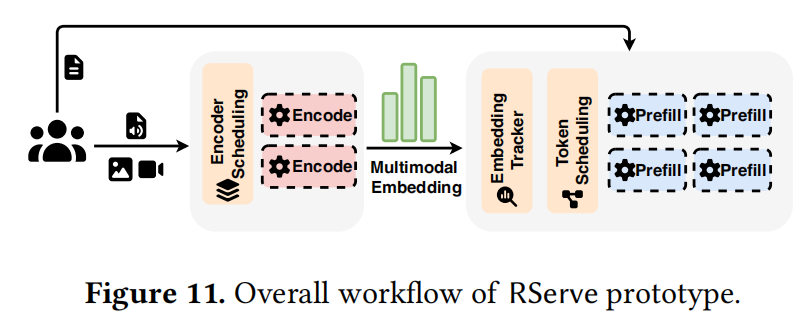
作者实现了 RServe,其组件图如图 11 所示。RServe 构建在 gLLM 之上,这是一个轻量级且高效的 LLM/LMM 服务框架,其性能与 vLLM 相当,同时保持了更简单和更灵活的架构。
- Embedding Tracker 实现: Tracker 基于字典数据结构,其中每个 Request ID 用作键,相应的 Embedding 缓存作为值存储。Driver Worker 负责维护此 Tracker 并编排 Prefill 调度。具体来说,Tracker 用于确定每个请求的可调度 Token 数量并准备模型输入 Embedding。
- 就地更新 (In-place Update): 当 Driver Worker 接收到模型生成的新 Embedding 时,它会就地更新相应的缓存条目,以便调度决策始终依赖于最新的 Embedding 状态。
- 调度器修改: 此外,作者修改了 gLLM 调度器以支持 Token 级调度。调度器不再调度整个请求,而是基于可用可调度 Token 的数量进行操作 120。
- 适用性: RServe 适用于多种场景。特别是,请求内流水线优化与现有的并行策略正交。它可以无缝集成到流水线并行和张量并行中,并且同样适用于单 GPU 模型部署 。相比之下,请求间流水线与流水线并行固有耦合;它充当一种混合机制,将 RServe 的请求内流水线优化与流水线并行执行融合,以进一步提高多请求工作负载下的系统吞吐量并降低端到端延迟 。
5. Evaluation
5.1 实验设置 (Experimental Setup)
- 架构: 作者的实验在 EPD 分离 (EPD disaggregated) 配置下进行。鉴于编码和 Prefill 操作主要影响首字延迟(TTFT),作者的评估重点关注首字延迟而非 Token 间延迟。
- 模型: 作者使用 Qwen2.5-VL 系列(7B, 32B 和 72B 变体)进行评估,考虑到其强大的多模态能力。
- 硬件:
- 主要实验:配备 140 核 Intel Xeon 处理器和 8 $\times$ H100 GPUs (NVLink) 的系统。
- 鲁棒性验证:配备 64 核 AMD EPYC 处理器和 4 $\times$ A100 GPUs (PCIe) 的系统。
- 工作负载: 使用 MMMU 数据集和 SGLang 中的开源基准。请求到达遵循泊松分布。作者改变图像分辨率以模拟多样化的多模态工作负载(1K 和 2K 分辨率)。
- 对比方案 (Schemes):
- vLLM (v0.10.1.1): 广泛采用的推理引擎,作为基准。
- gLLM (v0.0.4): 轻量级推理系统,作为性能基准和实现基础。
- gLLM-epd: 基于 gLLM 开发的 EP 分离版本。
- RServe: 提出的高效 LMM 服务系统。
- RServe-intra: 没有请求间流水线的 RServe。
- 指标: 首字延迟 (TTFT)、吞吐量 (Throughput)、SLO 达成率 (SLO Attainment)。
5.2 性能提升 (Performance Improvement)
5.2.1 延迟 (Latency - TTFT)
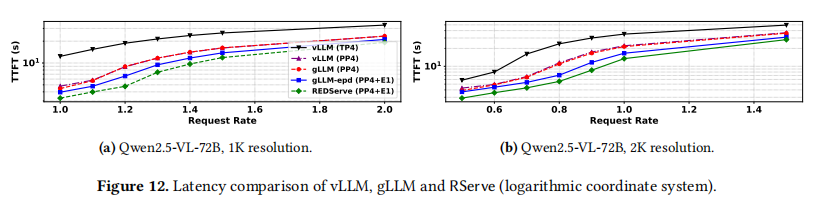
图 12 展示了对数坐标系下的延迟对比。
- TP vs PP: 采用张量并行的 vLLM (TP4) 相比基于流水线并行的系统遭受显著更高的延迟(高达 3.77倍)。这主要是由于张量并行中频繁的同步通信导致系统性能严重下降 。
- CPP 的优势: 流水线并行,特别是结合 CPP 时,不仅增加了吞吐量,还降低了单请求延迟。gLLM 的 TTFT 与 vLLM (PP4) 非常接近 。
- RServe 的效果:
- 通过采用 EP 分离架构,gLLM-epd 相比 gLLM 实现了额外的 16%/20% 的 TTFT 降低。
- 在此基础上,RServe 通过充分利用多模态编码和 LLM 前向传递之间的请求内并行性,相比 gLLM-epd 进一步降低了 18%/19% 的 TTFT 。
- 总体而言,RServe 在低请求率下特别有效,此时请求内并行占主导地位。随着请求率增加,RServe 的性能逐渐收敛于 gLLM-epd。
5.2.2 吞吐量 (Throughput)
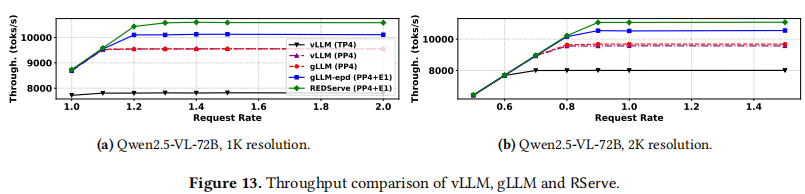
图 13 展示了输入 Token 处理吞吐量的对比。
- TP vs PP: vLLM (TP4) 的吞吐量显著低于(26%/28%)流水线并行系统,这一趋势与延迟结果一致,证实了 CPP 赋能流水线并行在性能上超越张量并行。
- RServe 的提升:
- gLLM 和 vLLM (PP4) 表现出几乎相同的吞吐量。
- 结合 EPD,gLLM-epd 实现了比 gLLM 高 6%/8.5% 的吞吐量提升。
- 通过利用请求内和请求间并行,RServe 进一步扩展了吞吐量限制,达到了约 10600/11100 tokens/s,相比基线提升高达 109% 。
5.2.3 SLO 达成率 (SLO Attainment)
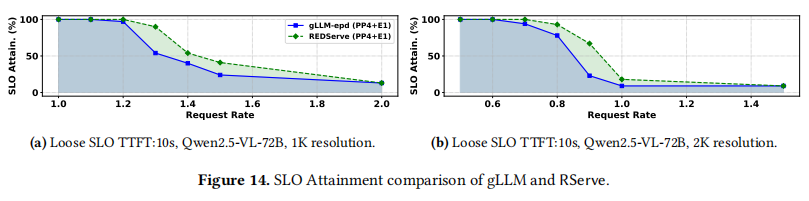
图 14 展示了服务指标的满足率。
- 随着请求率增加,排队时间增长,SLO 达成率从 100% 逐渐下降到不足 20%。
- 由于编码和 Prefill 操作之间的重叠计算,RServe 维持了比 gLLM-epd(平均 61%/59%)更高的 SLO 达成率(平均 71%/70%)。
- 在曲线下面积(Coverage Area)方面,RServe 比 gLLM-epd 大 23%/23%,进一步证明了 RServe 具有更强的调度性能 。
5.3 性能剖析 (Performance Dissecting)
5.3.1 Embedding 批次大小 (Embedding Batch Size)
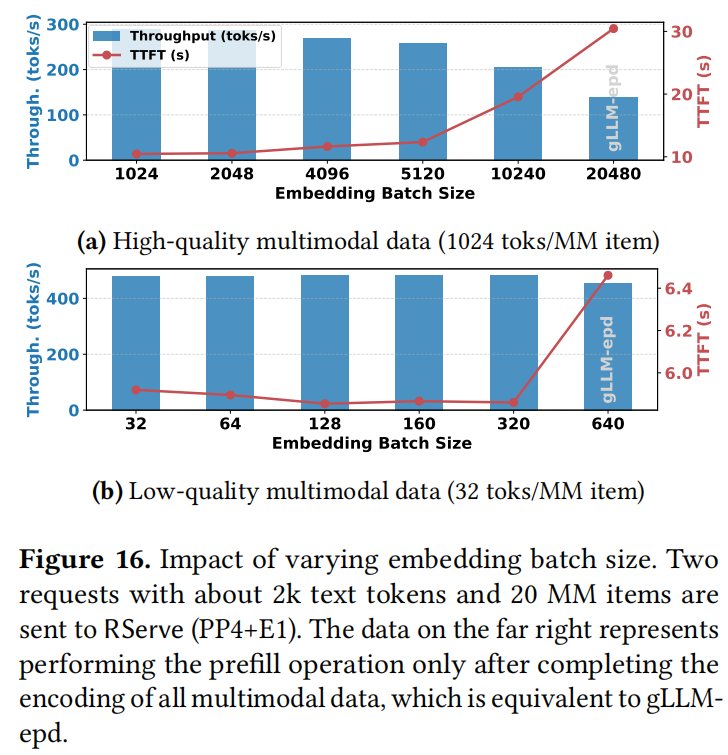
本节分析了不同 Embedding 批次大小在高质量和低质量多模态数据下的影响(图 16)。
- 高质量多模态数据 (1024 toks/MM item):
- 增加批次大小导致 TTFT 逐渐上升(高达 2.91倍),吞吐量稳步下降(高达 53%)。
- 结论: 对于高质量数据,即使单个多模态元素也足以充分利用编码计算能力 。因此,较小的批次大小通常更有利,因为它提供了更细粒度的重叠机会。
- 低质量多模态数据 (32 toks/MM item):
- TTFT 呈现“先降后升”的趋势 。
- 结论: 这反映了编码效率和重叠执行之间的权衡。批次太小,编码效率低;批次太大,重叠机会减少。实际部署应权衡两者。
5.3.2 请求间流水线 (Inter-request Pipeline)
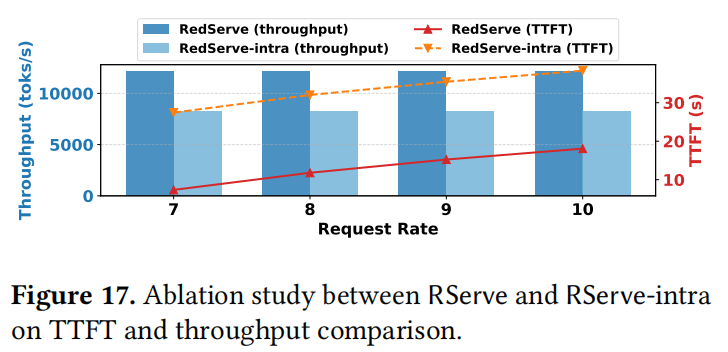
为了评估请求间流水线的影响,作者比较了 RServe 和 RServe-intra(仅包含请求内流水线)(图 17)。
- 随着请求率增加,RServe-intra 的吞吐量比 RServe 低 32%,延迟高 172% 。
- 缺乏请求间流水线显著降低了系统的处理速度,TTFT 的恶化主要归因于更长的等待时间。
5.4 扩展研究 (Extensive Studies)
5.4.1 RServe 结合张量并行 (RServe with Tensor Parallelism)
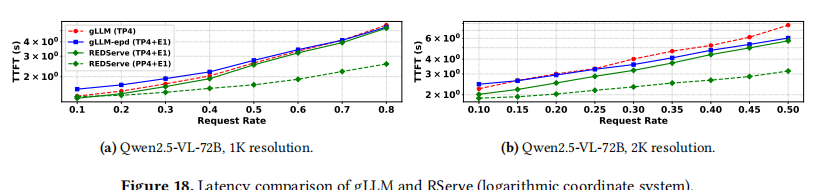
张量并行也可以与 RServe 集成。
- 延迟: 如图 18 所示,EPD 架构并不总是由益的:在低请求率下,额外的 Embedding 传输开销实际上可能增加延迟。然而,随着请求率增长,利用请求间并行,EPD 变得更加有效。RServe (TP4+E1) 始终优于 gLLM 和 gLLM-epd 。当结合流水线并行时,RServe (PP4+E1) 显示出明显的延迟优势。
- 吞吐量: 低请求率下各方案差异不大;随着请求率上升,不同方案的效率差异显现。
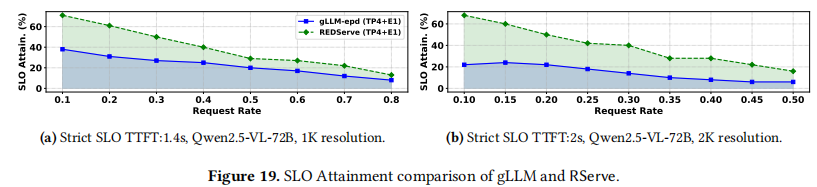
- SLO 达成率: 如图 19 所示,RServe 在严格 SLO 下始终优于 gLLM-epd 。
5.4.2 其他设置下的 RServe (RServe with Varied Settings)
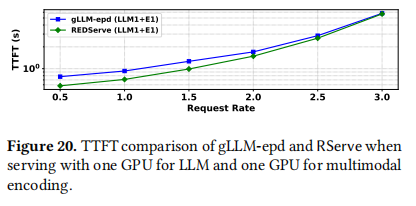
- LLM 单 GPU 部署: 如图 20 所示,RServe 也能提升 LLM 单 GPU 部署的性能(TTFT 降低高达 26%)。在低请求率下优势更明显。
- A100 GPU 评估: 在 A100 GPU 上,gLLM-epd 相比 gLLM 未显示出明显优势,但 RServe 进一步充分利用了并行潜力并实现了最佳性能 。
5.4.3 功能性研究 (Functional Study)
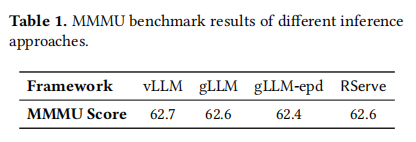
为了评估推理框架的功能可用性,作者在 MMMU 验证集上评估了每个系统的推理性能(表 1)。vLLM (62.7)、gLLM (62.6)、gLLM-epd (62.4) 和 RServe (62.6) 的得分非常接近(波动小于 0.5%),这表明 RServe 能够保持功能正确性 。
6. 结论 (Conclusion)
本文介绍了 RServe,这是一个 LMM 推理系统,它高效地编排请求内和请求间流水线以实现低延迟和高并行性。
- 在 请求内 层面,RServe 利用追踪器监控 Embedding 可用性,并采用基于 Embedding 块大小的流式调度策略,实现了编码与 Prefill 计算的细粒度重叠。
- 在 请求间 层面,RServe 引入了可调度 Token 来协调多个请求的执行并充分利用系统并行性。
在代表性 LMM 上的实验结果表明,RServe 将延迟降低了高达 66%,并将吞吐量提升了高达 109%,突显了其加速 LMM 推理的有效性。