
Conference: ICLR'26 Submitted
1. Motivation
核心痛点:投机解码(Speculative Decoding, SD)中的串行瓶颈与回滚代价
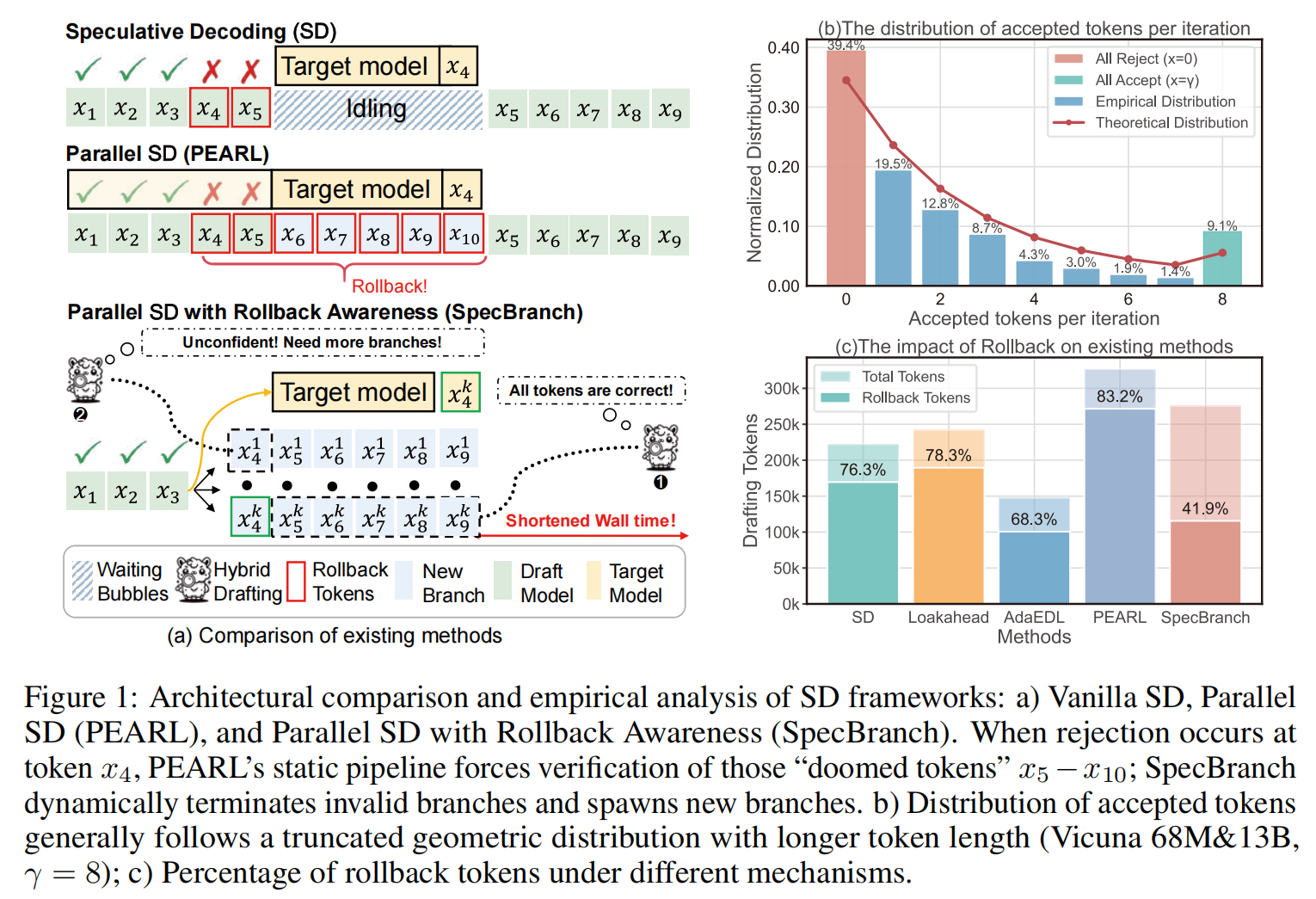
受到现代处理器分支预测技术的启发 ,作者允许 Draft Model(草稿模型)在 Target Model(目标模型)进行验证的同时,主动生成推测性的分支。这种并行 SD 范式创建了一个两阶段流水线,使得 Draft Model 的 token 生成与 Target Model 的验证在时间上重叠,从而有效地填补了传统 SD 中固有的流水线气泡(Pipeline Bubbles)。
先前的研究(如 PEARL )尝试在 Drafting 阶段利用 Target Model 预验证第一个 token,并在验证阶段让 Draft Model 继续生成。然而,与传统 SD 仅面临局部惩罚(即丢弃部分 token)不同,并行 SD 面临全局失效的风险 。如果并行生成的某个关键 token 被拒绝,会导致后续所有并行计算的 token 全部失效(Global Invalidation),从而严重阻碍并行效率。这种现象在生成长度较长时尤为严重,因为被接受的 token 数量通常服从截断几何分布(Truncated Geometric Distribution),这在并行性和回滚代价之间制造了一个艰难的权衡(Trade-off)。
遗憾的是,PEARL 并未充分解决这些挑战:
-
Pre-verify Rollback(预验证回滚): PEARL 忽视了并行加速的一个关键条件:验证期间生成的 token 必须被 “全部接受(All-Accepted)” 。否则,PEARL 会退化为串行执行并失去并行能力。它仅验证第一个 token,而系统对序列中间发生的拒绝(例如 Fig. 1(b) 中 被拒绝)一无所知,直到并行验证结束才发现,导致大量浪费 。
-
Post-verify Rollback(后验证回滚): 其静态的 Draft 长度缺乏对回滚和被拒绝 token 的感知能力 。这导致了对那些 “注定失败的 token(doomed tokens)” 的冗余计算,使得 Target Model 即使在不可避免的回滚面前,仍需处理来自无效分支的不必要 token,成为系统瓶颈。这种现象在参数比例不平衡的模型对(如 68M Draft & 13B Target)中尤为严重 。
现有动态 Drafting 方法的局限性

虽然近期的动态 Drafting 方法(分为 隐式/Implicit 和 显式/Explicit)试图缓解回滚问题,但仍存在实际困难 :
-
隐式方法(Implicit): 依赖置信度(Confidence)或熵(Entropy)进行早停。由于需要针对每个任务手动调整阈值,且逐 token 的预测会导致 误差累积(Error Compounding),难以在灵活性和计算开销之间取得平衡 。
-
显式方法(Explicit): 利用 Target Model 特征直接预测 Draft 长度(如 AdaEAGLE)。但随着预测序列长度的增加,特征的判别力下降,导致长序列的 预测准确率较低 。
-
共同缺陷: 现有的这些工作都没有从根本上解决 回滚(Rollback) 问题,即 Draft 生成了无效 token 从而阻碍并行性的核心瓶颈 。
因此,本文提出了 SpecBranch,旨在通过混合框架结合隐式置信度终止与显式序列建模,大幅减少回滚并提升并行效率 。
2. Contribution
本文提出了 SpecBranch,主要贡献如下:
-
Branch-Parallel Architecture(分支并行架构): 作者首先建立了理论模型来量化理想的并行推测,并将其扩展以考虑实际中的回滚惩罚 。基于这些理论洞察,作者提出了一种新颖的 分支重采样机制(Branch Resampling),它引入并行推测分支来抢先对冲(Hedge)可能的拒绝风险,同时保证生成分布与原模型一致(Lossless)。这是首个具有混合 Drafting 结构且无需额外训练 Draft Model 的并行框架 。
-
Hybrid Adaptive Drafting(混合自适应 Drafting): 基于对自适应 Draft 结构的广泛实证分析,作者首次将 隐式方法(Draft Model 置信度) 和 显式方法(Target Model 特征) 统一到一个混合框架中(H-RAD),以动态优化 Draft 长度 。这种方法有效地利用了 Target Model 特征对 “全接受/全拒绝” 的高判别力,以及置信度对中间状态的细粒度控制,从而大幅降低回滚率并提升并行效率 。
-
Extensive Evaluation and Discussion(广泛的评估与讨论): 作者在多种模型和任务上进行了广泛实验,证明 SpecBranch 在无需训练 Draft Model 的情况下,一致地实现了 1.8× 到 4.5× 的加速,并且对于对齐较差的模型对,将回滚 token 减少了 50% 。
3. Analysis of Parallel Decoding
本节通过深入的理论推导和实证数据分析,剖析了并行解码中加速潜力与回滚代价之间的核心矛盾,并论证了为何需要一种混合的自适应策略。
3.1 Theoretical Speedup(理论加速比)

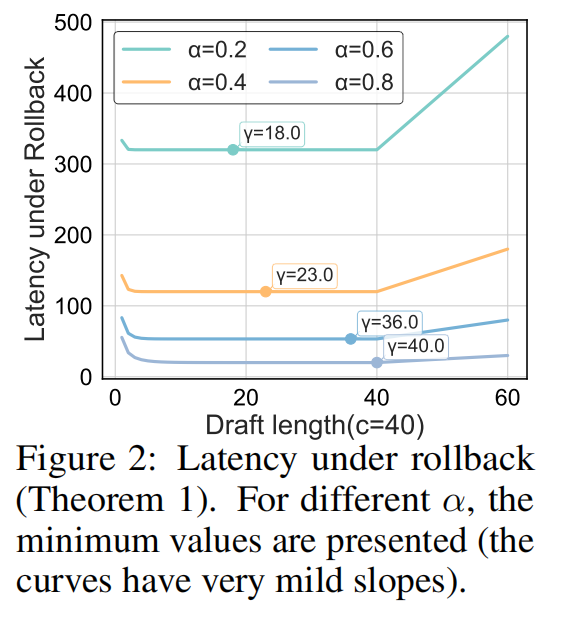
3.2 Parallel SD with Rollback(带回滚的并行 SD 分析)


3.3 Analysis of Adaptive Draft Structures(自适应 Draft 结构的实证分析)
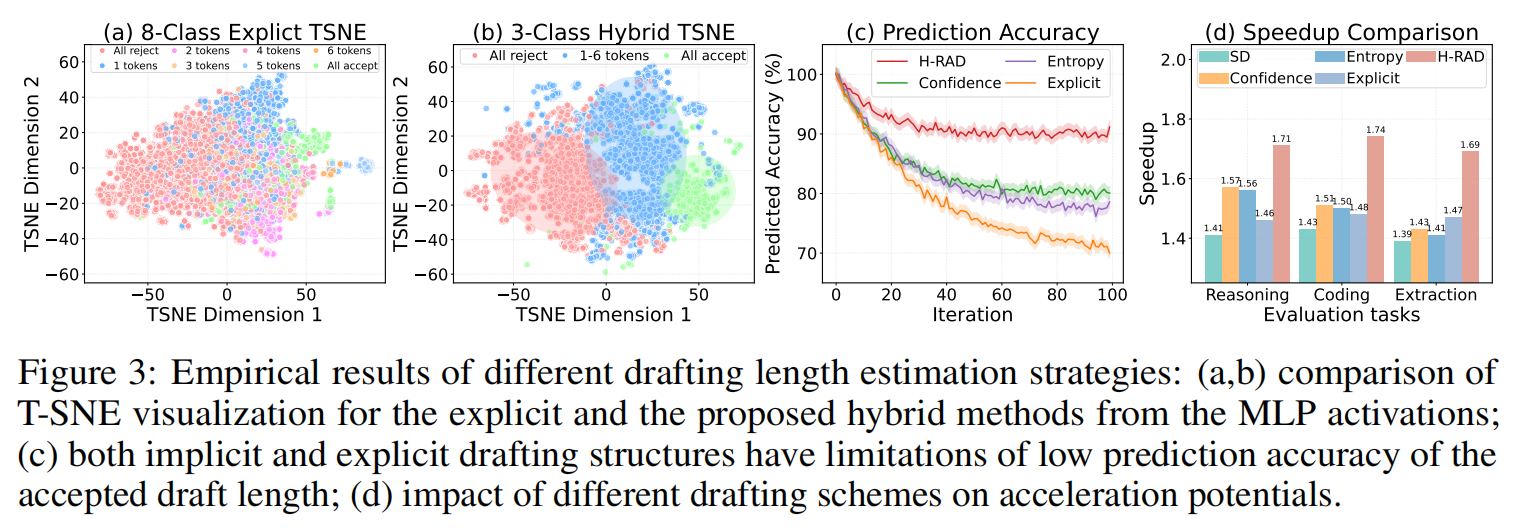
为了解决上述权衡,作者深入对比了隐式和显式 Draft 长度预测方法的优劣:
- Implicit Methods(隐式方法): 依赖 Draft Model 的输出分布(如置信度 Confidence 或熵 Entropy)。
- 缺点: 阈值 难以确定,随任务、模型、温度变化敏感(见 Fig. 14, 15, 16)。且逐 token 预测会导致 误差累积,不同任务间的不稳定性高 。
- Explicit Methods(显式方法): 直接利用 Target Model 的特征预测长度(如 AdaEAGLE)。
- 缺点: 如图 3(a) t-SNE 可视化所示,随着接受长度增加,Target Model 特征的簇重叠严重,判别力下降。这导致长序列的预测准确率甚至低于隐式方法(Fig. 3(c))。
双峰现象与混合策略的动机:
作者发现了一个有趣的 双峰现象(Bimodal Phenomenon):Target Model 的特征对于 “全接受(All Accept)” 和 “全拒绝(All Reject)” 这两种极端情况具有很强的可分性(Fig. 3(b)),而中间状态则很难通过特征区分,但可以通过隐式置信度来有效处理 。这直接启发了 SpecBranch 的混合设计。
4. Method
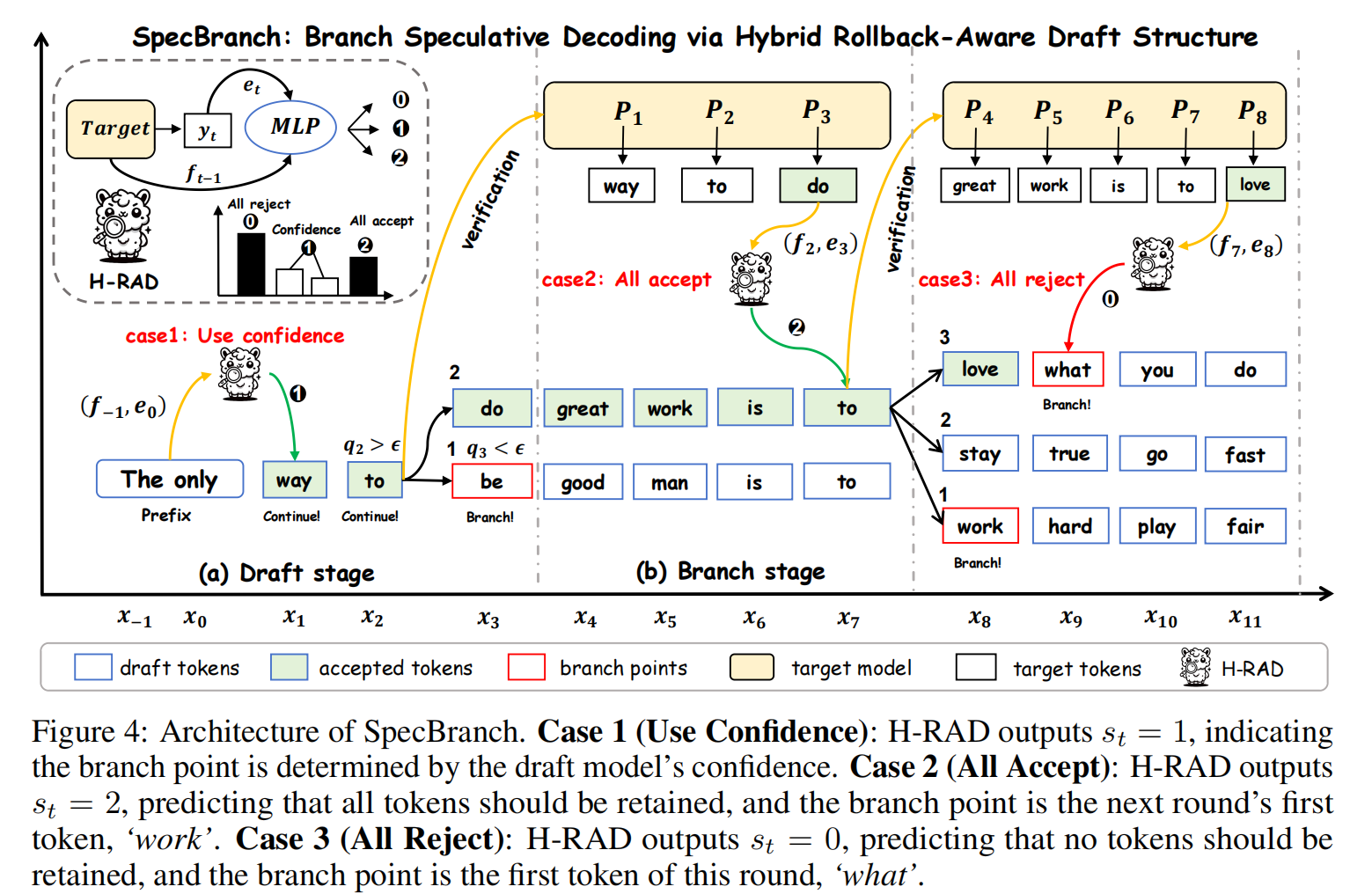
SpecBranch 是一个包含 H-RAD(混合回滚感知 Draft 结构) 和 Branch Resampling(分支重采样) 的并行 SD 框架,旨在解决流水线气泡和回滚代价放大的双重挑战 。
4.1 H-RAD: Hybrid Rollback-aware Draft Structure
H-RAD 的核心目标是在 Drafting 阶段,利用 Target Model 的特征提前预测最佳 Draft 长度和策略,以最大程度减少回滚。
混合长度预测机制(Hybrid Drafting Length Prediction) H-RAD 将复杂的长度回归问题简化为一个 3分类问题。

基于 的混合决策策略 :
- (Hard Signal: All Reject): 预测当前 token 极大概率被拒绝。
- 策略: 仅生成该 token,Branch Point(分支点) 设为当前 token。这对应于 Fig. 4 中的 Case 3。
- (Soft Signal: Confidence): 处于中间状态,特征无法确信。
- 策略: 这是一个“软信号”,退回使用 Draft Model 的 **置信度 ** 进行判断。当 时继续生成。Branch Point 由第一个置信度不足的 token 决定。这对应于 Fig. 4 中的 Case 1。
- (Hard Signal: All Accept): 预测接下来的序列全被接受。
- 策略: 继续生成直到最大长度。Branch Point 设为下一轮的第一个 token。这对应于 Fig. 4 中的 Case 2。
优势: 这种混合方法利用了“全接受/全拒绝”的高特征可分性,同时用置信度处理模糊地带,既提高了显式方法的预测准确率,又减少了隐式方法的误差累积 。
4.2 Branch Resampling: Parallel Drafting During Verification
一旦 H-RAD 确定了 Branch Point(通常是置信度不足的 token ),SpecBranch 启动并行分支机制,以消除串行瓶颈。
Top-k 分支生成(Top-k Branching)

分支验证(Branch Verification)

4.3 Posterior Drafting (Handling Temporal Mismatch)

4.4 SpecBranch 算法流程概览
SpecBranch 的执行是一个闭环状态机:
- Draft Stage(草稿阶段): 如果有 Target 特征,H-RAD 预测策略 Draft Model 生成直到遇到 Branch Point(由 决定是 Confidence 还是 Hard Signal)。
- Transition(转换): 启动并行。Target Model 验证前缀;Draft Model 并行生成 Top-k 分支。
- Verification Stage(验证阶段): Target 完成验证,确定保留哪个分支(或触发 Rollback 回到 Draft Stage)。
- Posterior Decision(后验决策): 利用验证后的最新特征再次调用 H-RAD,决定保留分支中的哪些 token 用于下一轮 回到 Draft Stage。
整个过程通过 Branch Speculative Sampling (Algorithm 2) 保证了生成的分布与 Target Model 严格一致(Lossless),即温度为 0 时结果一致,其他温度下分布一致 。
5. Evaluation
5.1 实验设置
-
Benchmarks: HumanEval (代码生成), GSM8K (数学推理), CNN/DM (摘要), Spec-Bench (综合任务) 。
-
Models: 覆盖了不同参数量和对齐程度的模型对 :
- Poorly Aligned(对齐较差): LLaMA (68M/7B), Vicuna (68M/13B)。
- Well Aligned(对齐较好): DeepSeek-Coder (1.3B/33B), LLaMA-3.1 (8B/70B)。
-
Baselines: Autoregressive, SpS , AdaEDL , Lookahead , PEARL 。
-
Metrics: Mean Accepted Length (M), Wall-Time Speedup, Speed (tokens/s), Rollback Rate (RB) 。
5.2 主要结果 (Main Results)
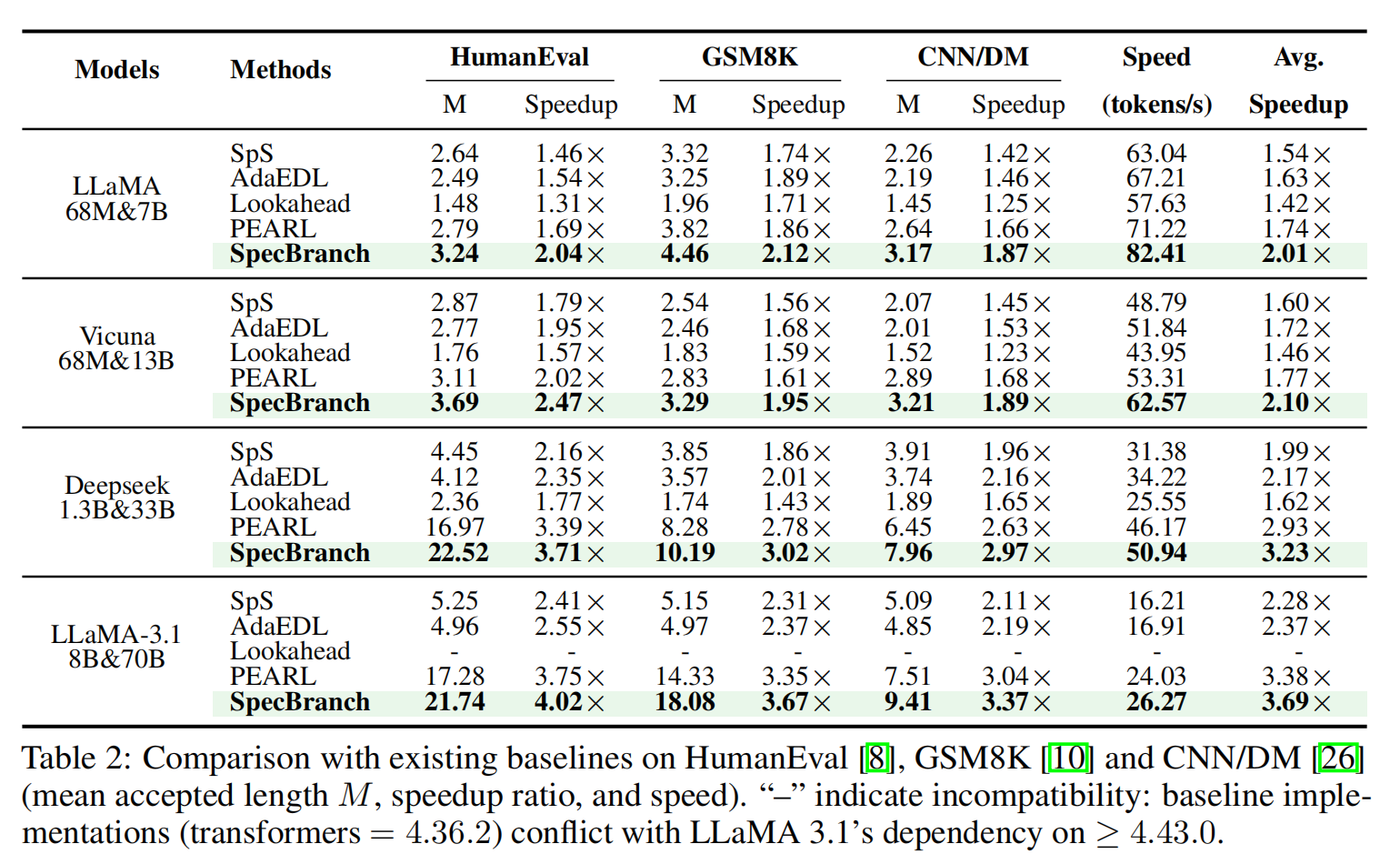
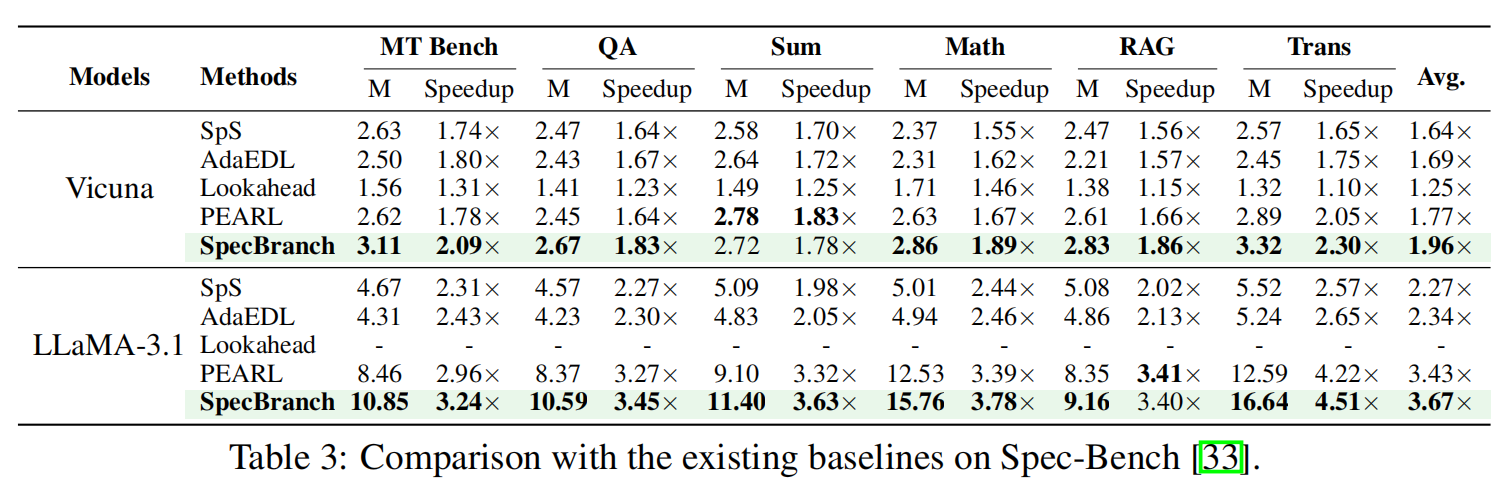
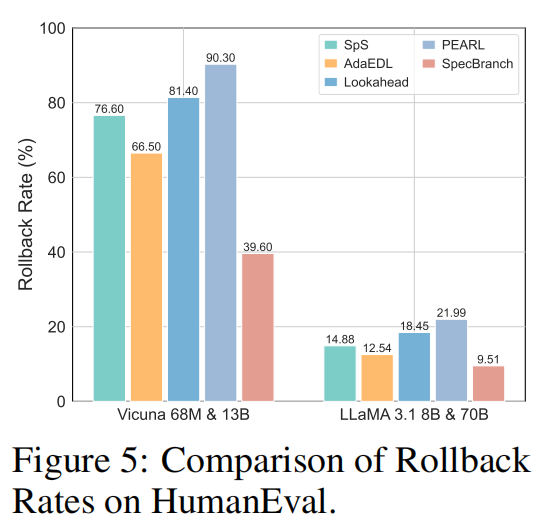
Table 2 & 3 结果总结 :
- 显著加速(Speedup): SpecBranch 在 HumanEval, GSM8K, CNN/DM 上实现了 1.9× 到 4.0× 的加速。在 Spec-Bench 的六个子任务上实现了 1.8× 到 4.5× 的加速,全面超越 Baseline。
- 对齐差的模型 (Poorly Aligned - Vicuna/LLaMA):
-
Rollback 降低: 对于这些模型,回滚是并行效率的杀手。SpecBranch 将 Rollback Rate 从 PEARL 的 66-90% 大幅降低到了 40% 以下 (见 Fig. 5) 。
-
性能提升: 相比 PEARL 提升了约 15% 的性能。这验证了 H-RAD 能够准确识别 “All Reject” 并提前终止无效路径的能力 。
- 对齐好的模型 (Well Aligned - DeepSeek/LLaMA-3.1):
- 并行效率提升: 此时回滚不再是主导因素,SpecBranch 利用 Branch Resampling 进一步提升了并行度。
数据: 在代码生成任务上,相比 SpS 提升了平均接受长度 M (4.14×);相比 PEARL 速度提升了 10.2%,回滚率降低了 10% 。
5.3 消融实验 (Ablation Studies)
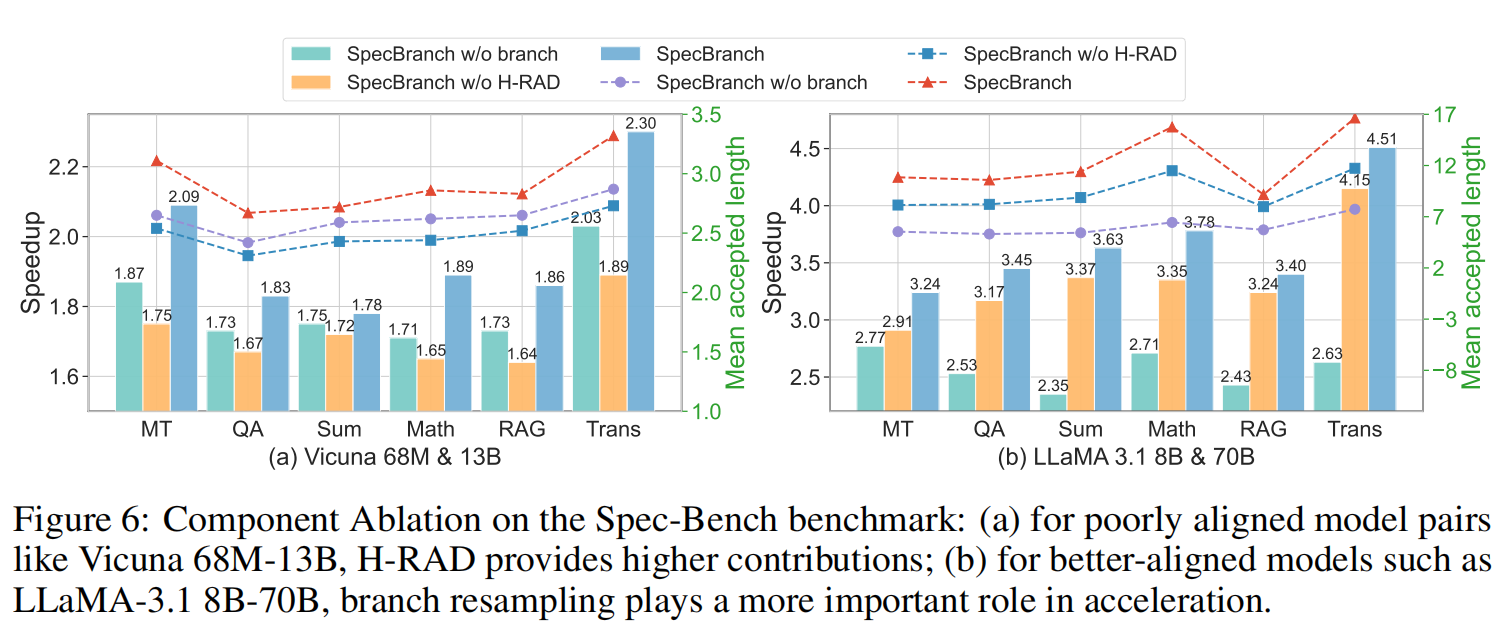
通过分别移除 Branch Resampling 或 H-RAD 组件进行分析 (Fig. 6) :
- H-RAD 的贡献: 在 对齐差的模型(如 Vicuna 68M-13B)中起主导作用。移除 H-RAD 后,加速比从 1.95× 显著降至 1.72×。说明此时遏制 Rollback 是关键。
- Branch Resampling 的贡献: 在 对齐好的模型(如 LLaMA-3.1 8B-70B)中起主导作用。移除分支机制会导致显著性能下降。说明在模型能力强时,利用并行分支探索更多可能性更能带来收益。
- 结论: 两个组件互补,分别解决了 Rollback(防守)和 Parallelism 利用率(进攻)的问题 。
5.4 资源消耗 (Resource Consumption)
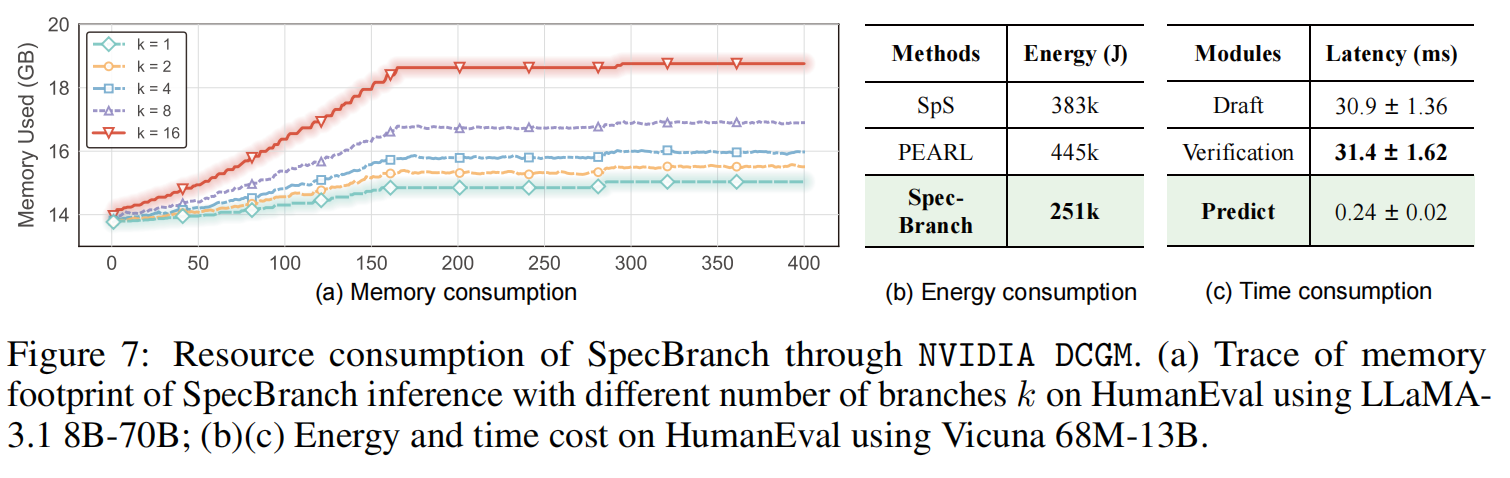
-
显存占用 (Memory - Fig. 7a): 由于使用了共享前缀 KV-Cache 和 稀疏分支(Sparse Branching),SpecBranch 的显存占用极低。即使分支数 ,显存增加也仅为 Baseline 的 28%。这与呈指数级增长的 Dense Tree 方法形成鲜明对比 。
-
能耗 (Energy - Fig. 7b, Table 10/11): 相比 PEARL,SpecBranch 显著降低了能耗(减少约 43%)。这是因为 H-RAD 减少了大量无效的 Draft token 生成和 Target Model 对无效分支的 Forward 计算 。
-
延迟开销 (Latency - Fig. 7c): H-RAD 的预测开销极小(单步仅 0.24ms),相对于整个推理步骤(~30ms)不足 1%,几乎可以忽略不计 。
6. Conclusion
本文提出了 SpecBranch,这是一个具有回滚感知能力的并行 LLM 加速框架。通过 分支重采样(Branch Resampling) 和 混合 Draft 结构(H-RAD) 两项关键创新,SpecBranch 成功实现了 Drafting 和 Verification 的并行化,打破了串行执行的瓶颈 。
实验结果表明,SpecBranch 实现了 1.8× ~ 4.5× 的加速比,特别是对于对齐较差的模型,它能减少高达 50% 的计算浪费 。虽然相比自回归解码,它在资源消耗上仍有增加,但相比同类并行方法(如 PEARL),它在能耗和效率上都取得了显著的优化,为大模型的实时应用提供了更高效的解决方案 。