
Conference: NeurIPS'25
Github: https://github.com/NYCU-EDgeAi/subspec
1. Motivation
大型语言模型(LLMs)模型体积巨大,超出常见消费级 GPU 的显存限制,导致两类常用处理方式:
- 模型压缩(Quantization 等):例如 INT8/INT4 等低精度表示,能显著压缩内存占用,但属于有损,可能影响输出质量。引用若干相关工作(GPTQ、AWQ、HQQ 等)。
- 参数分流 / Offloading:把不活跃层参数放到 CPU 主内存,需要时再传回 GPU,保证模型输出“无损”。但在 PCIe 带宽受限时,频繁的参数传输会大幅拉低吞吐与响应速度,导致单卡交互式生成速度可能只有每秒 1–2 token。
为缓解 offloading 的数据传输瓶颈,Speculative Decoding (SD) 提出使用“草稿模型”(draft model)先快速生成多个候选 token,然后由目标模型在单次前向中并行验证这些候选,从而减少昂贵的目标模型前向次数。但现有方法存在两大限制:
- 依赖与目标模型“同族”的预训练小模型(若无同族小模型,需做额外训练/蒸馏)。
- 训练过的草稿模型对定制 / fine-tuned 目标模型对齐不足,导致平均可接受 token 长度(average acceptance length,记作 $\tau$)较小,实际加速受限(常 < 7)。
论文提出 Substitute Speculative Decoding (SubSpec):一种无训练(training-free)、plug-and-play 的方法,通过在 GPU 上构造一个高度对齐的 draft 模型(使用低位宽 substitute 层 + 复用目标模型在 GPU 上的层与 KV-Cache)来大幅提升 $\tau$,从而在 offloading 场景下显著加速(例如在 8GB VRAM 下 Qwen2.5 7B 达到 ~25 token/s,超过 10× 加速)。
2. Contribution
- 分析表明在 offloading 场景中,对齐(alignment)与草稿深度(draft depth) 对 Speculative Decoding 的收益比草稿模型本身的速度更重要(因为目标模型的 $t_{Target}$ 被数据传输主导)。
- 提出一种trainning-free的方法:通过对被 offload 的层生成低位宽的 substitute 层,并与 GPU-resident 层以及 KV-Cache 共享,构建高度对齐的草稿模型,VRAM 开销可控。
- 引入对草稿树构建的改进(例如概率锐化/sharpening),允许使用更深的 token-tree,从而提升平均接受长度 $\tau$。
- 实现了高效系统优化(异步传输、chunked prefill 等),在不同模型与内存限制下获得 10× 〜 12.5× 的平均加速。
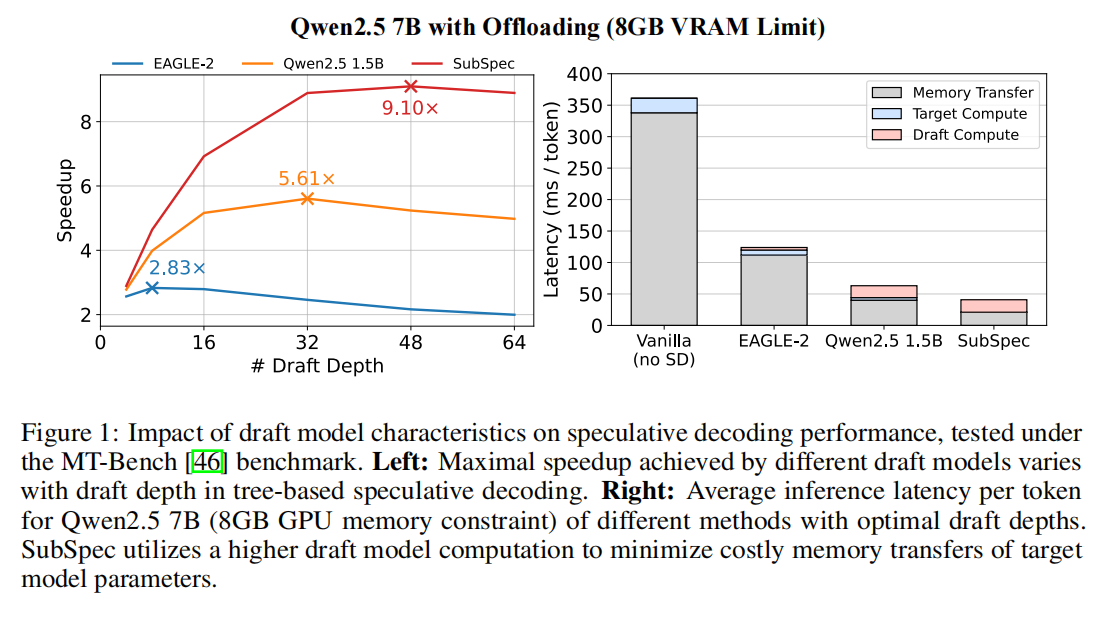
3. Analysis of Speculative Decoding Speedup in Offloading Scenarios
3.1 Theoretical Speedup Analysis
设目标模型以自回归(AR)方式生成 $N$ 个 token,则总时间:
$T^{AR}_N = N \cdot t_{Target}$
其中 $t_{Target}$ 是单次目标模型前向时延(offloading 下包括参数传输时间)。
对于 Speculative Decoding(树形或序列式),若草稿深度为 $D$,草稿模型一次迭代需 $D$ 次草稿前向(生成草稿树),随后目标模型进行一次并行验证(verification)。定义:
- $t_{Draft}$:草稿模型单次前向时延
- $\gamma$:验证的相对成本因子(相对于单次 $t_{Target}$),一般 $1 \le \gamma \le 2$
- $\tau$:平均接受长度(accepted draft tokens per iteration,包含可能的 bonus token),满足 $1 \le \tau \le D + 1$
则 SD 总时间:
$$ T^{SD}_N = N \cdot D \cdot t_{Draft} + \gamma \cdot t_{Target} \cdot \frac{N}{\tau} $$
注意第二项分母为 $\tau$ 表示每次验证可接受 $\tau$ 个 token,因此验证次数约为 $N/\tau$。
于是理论加速比:
$$ \text{speedup} = \frac{T^{AR} \cdot N}{T^{SD} \cdot N} = \frac{\tau \cdot t_{\text{Target}}}{D \cdot t_{\text{Draft}} + \gamma \cdot t_{\text{Target}}} = \frac{\tau}{D \cdot \frac{t_{\text{Draft}}}{t_{\text{Target}}} + \gamma}. $$
直观结论:
- 在常规(全部 GPU-resident)场景中,$t_{Target}$ 相对较小,分母中 $D\cdot t_{Draft}$ 的影响明显,因此倾向选择更快的草稿模型与中等深度 $D$。
- 在 offloading 场景中,$t_{Target}$ 大(受 PCIe/总线带宽拖累),分母的 $\gamma$ 项变得占优,此时提高 $\tau$(接受更多草稿 token)比减小 $t_{Draft}$ 更有效。因此更“对齐”的草稿模型(哪怕稍慢)在 offloading 情形下更值得选择。
3.2 Empirical Validation and Motivation for Efficient Draft Model Generation
论文用 Qwen2.5 7B 做示例,比较了:EAGLE-Qwen2.5*(更快但不够对齐)与 Qwen2.5 1.5B(更对齐但更慢),以及 SubSpec 的性能。结果表明:
- 在无 offloading的普通场景,较快的草稿模型(EAGLE)带来更好加速(因为 $t_{Draft}$ 决定分母)。
- 在offloading场景,较对齐的草稿模型(Qwen2.5 1.5B)获得更高的 $\tau$ 和更好总加速,表明对齐比草稿速度更关键。
- 这驱动出一个需求:如何在不训练/蒸馏的前提下高效获得高度对齐的草稿模型? SubSpec 的关键点即是:用目标模型的低位宽 substitute 层 + 共享 GPU 层与 KV-Cache 来直接在线构建一个高度对齐的草稿模型,避免额外训练成本。
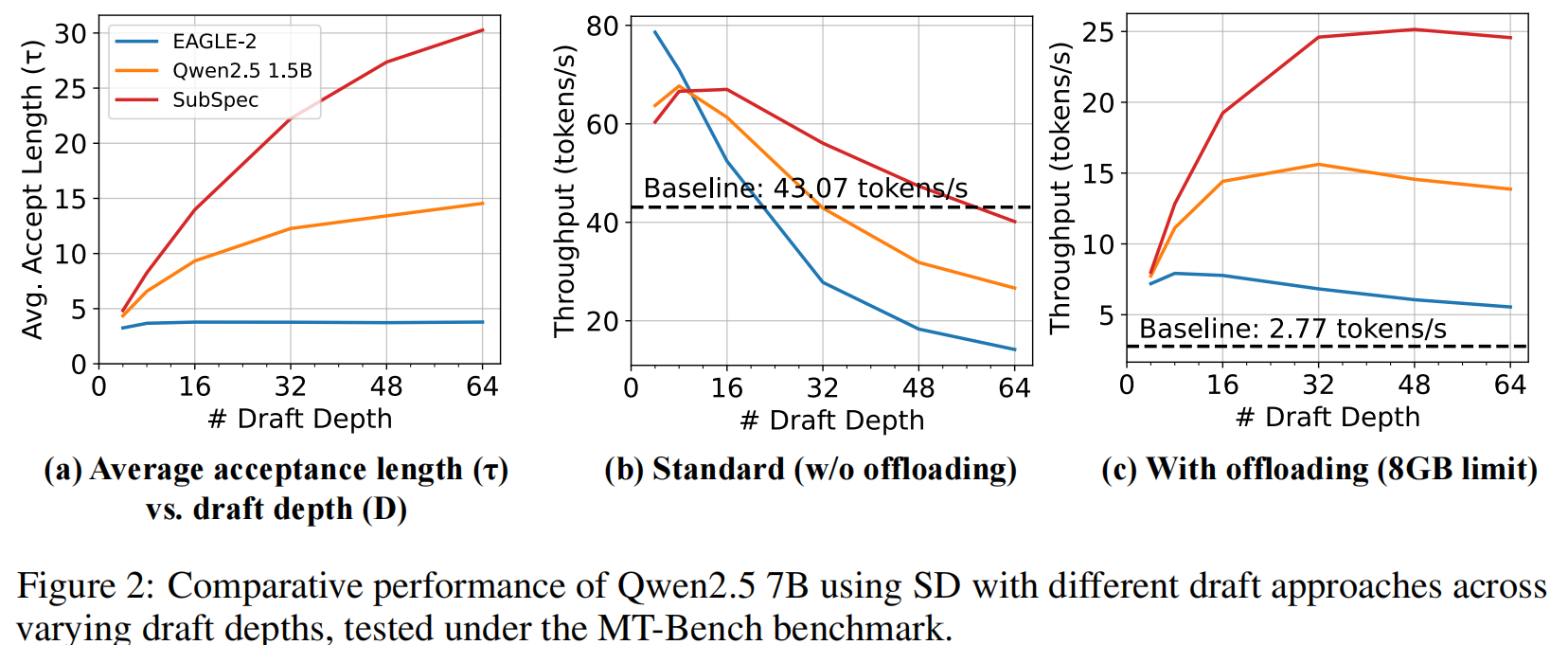
4. Method
SubSpec 的核心思路是:构建一个完全 GPU-resident 的草稿模型(draft model),该草稿模型在结构上与目标模型高度一致,但对被 offloaded 的层使用低位宽的 substitute 权重(quantized substitutes)。同时,复用目标模型在 GPU 上已驻留的层与同一 KV-Cache,从而提升对齐并降低额外显存开销。借助深度的树形 speculative decoding 和概率锐化等技术,获得极高的平均接受长度 $\tau$,减少昂贵的目标模型验证次数。
4.1 Draft Model Construction
SubSpec 通过三种协同策略保持草稿模型完全驻留 GPU:
-
Quantized Substitute Weights for Offloaded Layers(被 offloaded 层的低位宽替代权重)
-
对被放在 CPU 的目标模型层,使用数据无关(data-free)快速量化方法生成 4-bit substitute 权重(论文采用 HQQ,组大小 group-size=64),使这些替代层能放在 GPU。
-
生成流程(实现建议/工程细节):
- 从目标模型权重读取 float16/float32 权重片段(按 layer 划分)。
- 对每个权重块执行聚类或线性量化/半二次(HQQ)流程,输出索引表与查找表(LUT)或低位宽矩阵的压缩格式。
- 将量化后权重格式转换为适配高效 low-bit GEMM kernel 的内存布局(例如行优先或按 block 对齐),并上传至 GPU 全局内存。
- 这一过程数据无监督,速度快——文中指出 7B 到 70B 的模型在单张消费卡上耗时在几分钟级别。
-
运行时:使用已优化的 low-bit GEMM 运算(引用 [5,16])进行前向计算以尽量降低 $t_{Draft}$。
-
注意:Substitute 的精度与对齐影响 $\tau$,论文选择 4-bit(group=64)作为折中。更低位宽可以节省显存但会降低对齐;该取舍在实验与未来工作中可探索。
-
-
GPU-Resident Layer Sharing(共享 GPU 上的目标层)
-
在 offloading 策略中,框架通常尽可能将若干最关键的层常驻 GPU(embedding、head、部分 decoder 层)。SubSpec 将这些 GPU-resident 层同时作为目标模型和草稿模型使用——即共享同一份权重与计算路径。
-
好处:
- 完全保证共享层的完美对齐(identical computation);
- 减少草稿模型的额外显存需求(因为无需再复制这些层的权重);
- 节约了草稿生成时的预填(prefill)时间:由于共享 KV-Cache,草稿模型无需独立 prefilling。
-
工程实现细节:
- 维护单一权重句柄(pointer)供目标与草稿模型共享。
- 在实现上需注意 layer normalization、position embedding、token type embedding 等模块的一致性(确保接口/shape 完全匹配)。
-
-
Shared KV-Cache(共享 KV-Cache)
-
草稿模型与目标模型共享 KV-Cache(键/值的缓存),具有两类重要效果:
- 内存效率:避免为草稿与目标分别存储两份 KV,而是单份复用,KV 占用通常很大(尤其长上下文),因此此项能显著节省显存。
- 提高对齐:共享相同的上下文历史,草稿模型在相同条件下产生概率分布更接近目标模型,从而提升 $\tau$。
-
Prefill 流程:
- 由目标模型负责构建初始 KV(或在第一次迭代时用目标模型完成 prefill),随后草稿在 speculation 阶段以同一 KV 作为输入并“扩展”新的 KV;若最终验证通过,目标模型用验证结果覆盖草稿产生的 KV,以确保最终状态一致。
-
技术细节:
- KV 的内存布局须为草稿与目标的 attention kernel 所兼容(相同维度、相同 dtype)。
- 并发访问:当草稿在 GPU 中扩展叶节点时,需保证线程/流对 KV 的写入与随后的覆盖顺序一致(可使用 CUDA stream、事件或锁机制实现有序覆盖)。
-
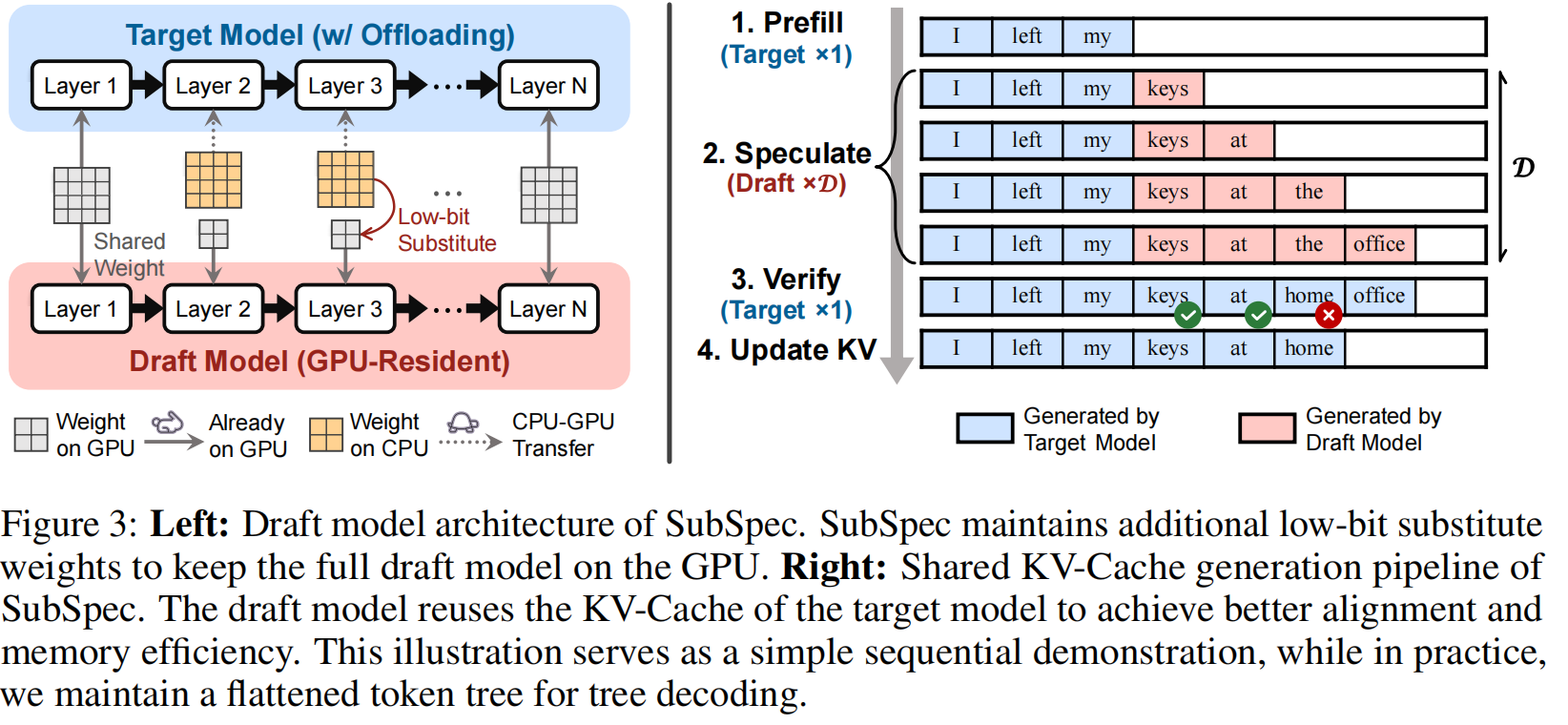
4.2 Optimized Draft Tree Construction
Constructing Deep Context-Aware Dynamic Draft Tree.
SubSpec 草稿模型的高度对齐性(详见第 4.1 节)使得可以探索更深的草稿树,从而获得更高的平均接受长度(τ)。因此,作者的采样方法扩展了已有的上下文感知动态草稿树方法,例如 EAGLE-2 [24] 和 SpecExec [35],以支持这些更大的深度。
一个上下文感知的动态草稿树通过在未来的 $D$ 个时间步上,使用草稿模型迭代生成草稿 token 来构建。在这 $D$ 次前向传递中的每一次,所有叶节点都会作为输入送入草稿模型,每个叶节点都会产生下一 token 的概率分布。每个潜在下一 token 的分数为其条件生成概率(来自草稿模型)与其父路径分数的累计乘积。具有最高分数的 top-k 个 token 会被选为新的 $k$ 个叶节点,供下一时间步使用。该迭代过程构建了一个深度为 $D$ 的草稿树,最终为目标模型验证提供 $k \times D$ 个草稿 token(不包括根 token)。
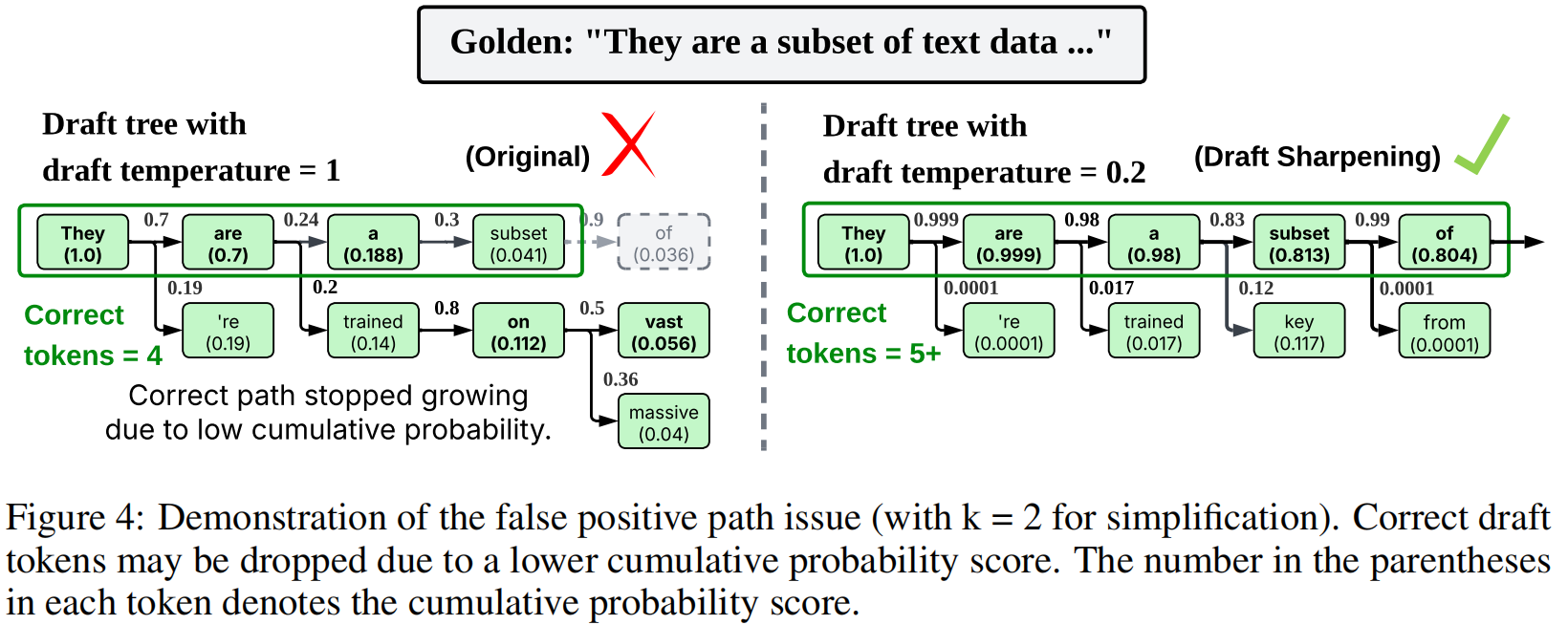
Addressing Cumulative Probability Divergence.
在探索远比以往工作(通常 $D ≤ 7$)更深的草稿树的过程中,作者发现其确实有提升 τ 的潜力,但在 greedy 解码(目标 temperature = 0)的构建阶段揭示了一个微妙的问题。作者观察到:那些以较低概率 token 开始的路径,可能通过随后的高概率选择而累积出异常高的整体概率。这种现象可能导致“伪阳性”路径,其累计概率超过真正最优路径(如图 4 所示)。这种发散(divergence)在 greedy 解码中尤其成问题,因为它会误导路径选择,可能导致正确序列的提前终止,从而限制可达到的 τ。
Draft Probability Sharpening.
为了在 greedy 解码下抵消这种发散,作者采用草稿概率锐化(draft probability sharpening)。该技术在计算用于树采样的累计概率之前,对草稿模型的输出分布施加一个较低的温度(= 0.2)。这种锐化会使概率分布更加尖锐,从而减少分配给那些初始概率较低 token 的概率质量。进一步分析见附录 D。
4.3 Complementary Performance Optimizations
-
Asynchronous Data Transfer(异步数据传输 / prefetch across layers)
-
目标:在目标模型执行某一层计算时,提前从主内存(CPU)并行预取下一个需要的 offloaded 层参数到 GPU,从而隐藏 PCIe 传输时间。
-
实现设计要点:
- 使用两个 CUDA streams:一个用于计算(compute stream),一个用于数据复制(transfer stream)。在 compute stream 执行当前层时,transfer stream 异步启动
cudaMemcpyAsync将下一层参数拷回 GPU。 - 要确保内存缓冲区(reused memory region)固定且大小足够,避免在预取时分配新内存导致内存碎片或 OOM。
- 使用 CUDA events / stream synchronization 在真正需要该层时才做 minimal sync(避免过早阻塞)。
- 当预取跨多个 decoder 层时,优先预取离当前最近但尚未使用的层(以减少带宽峰值)。
- 使用两个 CUDA streams:一个用于计算(compute stream),一个用于数据复制(transfer stream)。在 compute stream 执行当前层时,transfer stream 异步启动
-
在论文图 5(参见附录 E)中展示了时间线对比,异步传输显著缩短验证期间 GPU 的空闲等待时间。
-
-
Chunked Prefill for Long Contexts(长上下文的分块预填)
-
问题:长上下文预填时会产生巨大的中间 activation,占用 peak GPU memory,限制可以常驻 GPU 的模型层数。
-
方案:把输入 prompt 切成固定长度 chunk(例如 256 tokens),逐块构建 KV-Cache。
- 优点:降峰(reduce peak memory),让更多的 decoder 层有机会保留在 GPU 上,从而减少未来的 offloading 传输。
- 实现细节:在每个 chunk 的前向后,立即释放不再需要的中间 activation(或使用 activation checkpointing),只保留 KV。
-
对比 Sarathi-Serve 的方案,SubSpec 的 chunked prefill 专注于降低 prefill 阶段的峰值显存以增加系统可用的 GPU 层数。
-
-
内存重用与 kernel tuning
- 对于量化后的 substitute 权重,采用复用内存 region策略(reuse memory regions)以避免增加 peak memory。
- 通过
torch.compile+ max-autotune 使低位 GEMM 内核被编译并选用最优 schedule,从而在草稿与验证阶段都取得较低 $t_{Draft}$ 与 $t_{Target}$。
5. Evaluation
5.1 Evaluation Setup
基准任务(Benchmarks):论文在五类生成任务上评估,覆盖对话、多轮理解、代码生成、数学推理、摘要等:
- MT-Bench(multi-turn conversation)
- HumanEval(代码生成)
- GSM8K(数学推理)
- Alpaca(instruction-following)
- CNN/Daily Mail(摘要)
硬件与模拟环境:
- 评测机为 RTX 4090 + Intel i7-13700K + PCIe 4.0 x16 + 128GB DDR5 RAM;
- 为模拟不同消费级显存,程序将 GPU memory cap 为 8GB、12GB、24GB 三档(分别对应中低端到高端消费卡);
- 所有方法 batch size=1(以评估交互式延迟场景)。
比较方法:
- Baseline: vanilla offloading(无 SD)。
- EAGLE-2:已有的 tree-based SD 方法(作为对比)。
- 小/中/大预训练 draft 模型(例如 1B、1.5B、7B 等)——这些是“现成”草稿模型基线。
- SubSpec(本文方法)。
关键参数配置(论文中所用):
- Substitute layers:4-bit quantization, group size = 64(HQQ)。
- Tree construction:SubSpec 使用 $k=6$,预先 grid-search 得到 optimal depth $D$(SubSpec $D=48$,pretrained drafts $D=32$)。
- EAGLE-2 默认 $k=10$, $D=6$(论文用其默认发布参数)。
- Static KV-Cache 长度为 2048 tokens。
- 对所有草稿模型启用
torch.compile+ max-autotune。 - 为公平起见,各方法使用相同的 context-aware dynamic draft tree 基础算法(没有额外的 tree pruning)。
实验细节(额外补充便于复现):
- 每个方法在每个 benchmark 上评估 20 个随机抽样样本;baseline 仅运行部分样本(前 5 个),因为运行时间很长;
- 统计指标:tokens/s(throughput)与 $\tau$(average acceptance length);每项给出不同温度(target temperature = 0 与 0.6)下的结果。
- 为降低噪声,多次运行取均值并报告 std(论文提到在 MT-Bench 上 SubSpec 的 std = 0.101 tokens/s for 5 runs)。
5.2 End-to-end Performance
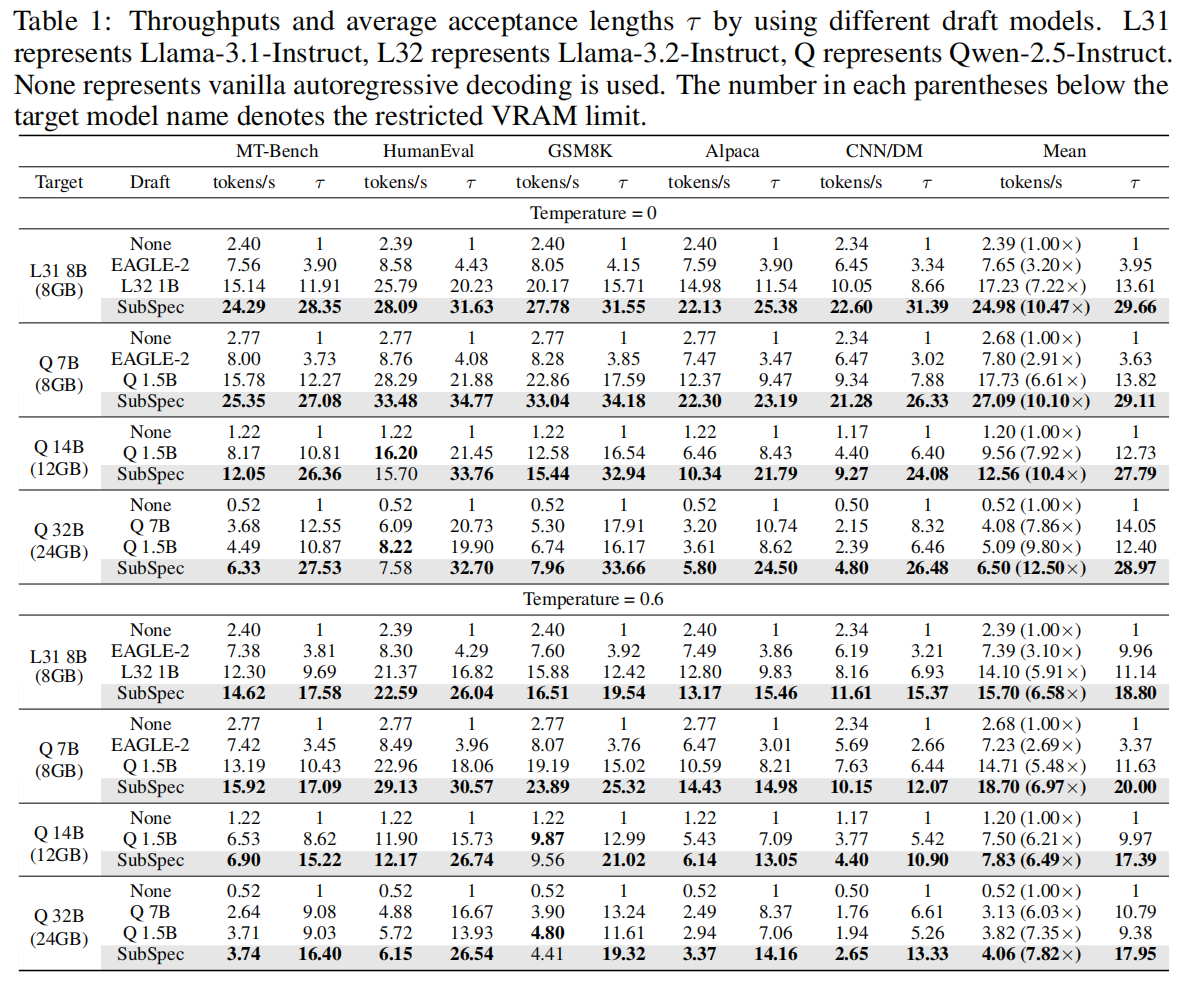
关键观察与解释:
-
总体趋势:
- Baseline offloading 在受限 VRAM 下吞吐非常低(≈ 1–2 tokens/s),不可交互。SubSpec 把这一吞吐提高到数十 tokens/s(8GB 下 Qwen2.5 7B 在 greedy 下约 25 tokens/s),带来 10× 左右的加速。
- SubSpec 在多数情况下能将 $\tau$ 提升到接近 30(greedy),这是通过深度树(D=48)+ 高对齐的草稿模型(substitute + shared layers + shared KV)实现的。
-
草稿深度 D 的作用:
- SubSpec 倾向于使用非常深的草稿树($D=48$),目的是尽量增加每次验证所能接受的 token 数 $\tau$,从而减少昂贵的目标验证次数。
- 论文的 Figure 6(Temporal Analysis)显示当 $D$ 达到 48 时,Speculation 与 Verification 的时间占比接近平衡,从而达到了最优 throughput。若继续增加 $D$,speculation 时间超过验证时间,收益递减甚至下降。
-
温度影响(greedy vs stochastic):
- 在 target temperature = 0(greedy)时,SubSpec 表现最佳(因为验证期望确定性更强,树结构发挥最大效用)。
- 在 stochastic(target temperature = 0.6),speedup 下降约 60%,因为验证不再以确定最优路径为目标,$\tau$ 自然下降。但 SubSpec 仍保持显著加速(约 5.8×–7.8×)。
-
不同目标模型规模对比:
- 在 8GB、12GB、24GB 等受限内存下,SubSpec 在各尺度模型上均显著优于基线与其他 SD 方法,表明方法的可扩展性。尤其是 32B 模型(24GB cap),SubSpec 能在不牺牲质量情况下实现 12.5× 加速。
-
与预训练草稿模型比较:
- SubSpec 通常优于相同家族中较小的预训练草稿(1.5B/7B 等),即使预训练草稿本身也是“in-family”,证明了 复用目标权重 + substitute 量化 在对齐性上的巨大优势。
-
消融(Ablation)说明:
- 一系列累进消融(表 2)显示:单纯 substitute + layer sharing 即能带来 ~7×,加入 shared KV 再提升到 ~7.94×,概率锐化再到 ~8.54×,最后异步数据传输到 ~9.15×(总 throughput 25.35 tokens/s)。每一项优化贡献约 7%–13% 的相对提升,表明这些设计不是单点“魔法”,而是协同增益。

进一步解读(建议性阐述以便复现/理解):
- substitute+layer sharing 的大幅提升源于:草稿模型与目标模型在大部分关键层上完全一致,从而使草稿 logits 与目标 logits 在 top-k 排名上高度一致,极大提高草稿 token 的“可接受率”。
- Shared KV 的好处不仅限内存:在自回归生成中,KV 决定上下文感知能力,复用 KV 最大限度减少草稿与目标之间的上下文差异。
- Draft probability sharpening 对 greedy 特别重要:它减少了低概率 token 在长链中“累积翻盘”的几率,从而让更深的树实际有效。
5.3 Ablation Study
(表见上方 Table 2)
逐步累加组件的消融结果重申:
- 基础(仅 substitute + layer sharing):tokens/s = 19.54(≈ 7.05×),$\tau$ ≈ 23.07
- 加入 shared KV-Cache:tokens/s = 21.99(≈ 7.94×),$\tau$ ≈ 25.14
- 加入 draft probability sharpening:tokens/s = 23.66(≈ 8.54×),$\tau$ ≈ 27.08
- 加入 async data transfer(最终完整系统):tokens/s = 25.35(≈ 9.15×),$\tau$ ≈ 27.08
解读:
- 第一项(substitute + sharing)是 SubSpec 的核心,带来了最显著的提升;
- Shared KV 与概率锐化对 $\tau$ 的提升十分明显(分别提升约 2–4 个 $\tau$ 单位);
- 异步传输主要改善了验证阶段的 wall-clock 时间,从而提升 tokens/s,但对 $\tau$ 本身无直接影响($\tau$ 在添加 async 后维持不变)。
6. Conclusion
- SubSpec 针对 offloading 场景给出了解决路径:构建一个高对齐、GPU-resident 的草稿模型(低位宽 substitute + 共享 GPU 层 + 共享 KV),并结合深度树形 speculative decoding 与概率锐化、异步传输等工程优化,实现无训练、lossless 的显著加速。
- 在多种模型规模与 benchmark 上,SubSpec 能在显存受限的消费级 GPU 上把不可交互的 baseline 推理速度提升到可用的交互范围(例如 Qwen2.5 7B 在 8GB 下 ~25 tokens/s),为本地无损部署带来实际可行方案。
- 论文实证表明,在 offloading 场景中,对齐(alignment) 与 草稿深度(D) 的取舍比草稿模型的纯速度更为关键。这一观察可能改变实践中对草稿模型选择的偏好:优先考虑“与目标模型结构/权重更接近”而非仅考虑参数量小或推理快。