
Conference: EMNLP'25
Github: https://github.com/ZichenWen1/DART
1. Motivation
Vision tokens 在多模态大模型(MLLMs)中因数量巨大而成为主要计算瓶颈,尤其是高分辨率图像或多帧视频,会将图像编码为成千上万的视觉 token,使得模型推理的时间和内存成本迅速上升。为此,许多近期工作提出了训练免费(training-free)的 token pruning 方法,通常采用“先度量每个 token 的importance,再删除importance低的 token”的范式来加速推理。论文指出并实证了:以 attention-score 作为 importance 的方式存在严重缺陷,在某些场景下竟然比随机丢弃(random pruning)更差,并且与硬件加速(如 FlashAttention)不兼容,从而无法在实际部署时取得理想的速度-性能折中。
直觉动机:论文提出另一种思路——把重复(duplication)作为 token reduction 的主要考虑因素。当多个视觉 token 表示高度相似时,保留其中一个便足以维持信息完整度;相反,删除“重复”token 不但能大幅削减计算,也更不容易损害下游性能。基于该想法,作者提出了 DART(Duplication-Aware Reduction of Tokens)这一简单、训练免费、对硬件友好的 token 削减 Pipeline。
2. Challenge
论文系统性地列举并分析了当前 importance-based token pruning 的问题:
-
(I) 忽略 token 间的交互(dynamic interaction):importance-based 方法往往把每个 token 的分数当作对全集 $X$ 的函数 $s_i=F(x_i\mid X)$ 并进行静态选择,但当某些 token 被移除后,剩下 token 的“重要性”应发生改变(例如两近似 token 存在互补性,移除其中之一会提高另一个的相对重要性),而静态评分忽略了这一点。论文通过形式化说明和实证展示了该偏差来源(见式 (4)-(6))。
-
(II) 与高效注意力算子(FlashAttention)不兼容:许多 importance-based 方法需要访问 attention scores,但高效实现(FlashAttention / FlashAttention-2)在内部并不暴露中间 attention map,这就迫使要么禁用高效实现(带来速度和内存损失),要么放弃这些方法。论文强调在保持 FlashAttention 的同时设计 pruning 方法的重要性。

- (III) 位置偏差(positional bias):attention-score 存在位置偏差(靠近序列末端的 token 更容易获得高 attention),因此用 attention 直接作为 importance 测度会产生空间偏差(例如经常保留同一区域的 token),影响视觉上下文的均衡感知(见 Fig.1 的可视化说明)。
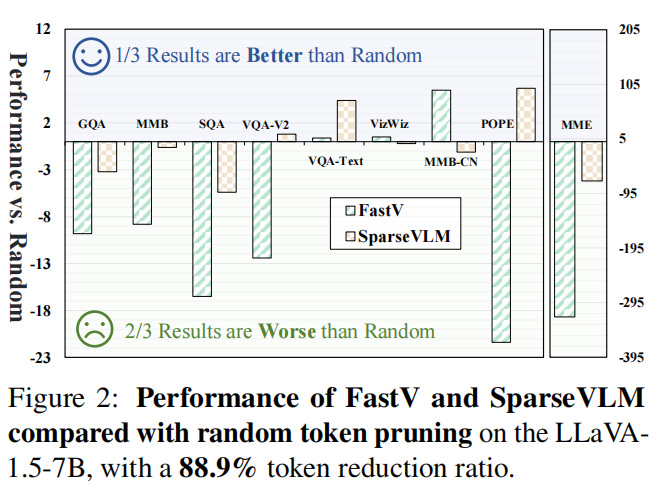
- (IV) 精度显著下降:令人惊讶的是,部分被广泛引用的方法在高压缩率下表现比随机选择还低(论文用实验展示了 FastV、SparseVLM 等在极端压缩时的劣化),这进一步提示 importance-based 指标可能根本不是理想的 pruning 导向。图 2 给出了对比。
因此理想方法应满足:同时考虑 token 个体价值与与其他 token 的交互、计算开销小、与硬件友好(可兼容 FlashAttention)、无明显位置偏差。
3. Contribution
-
Rethink Token Importance:通过实证分析证明 attention score 作为 token importance 的不足,揭示 importance-paradigm 的固有问题(包括比随机更差的情况)。
-
Token Duplication as a Key Factor:提出基于 token 重复性的训练免费、即插即用的 token 削减方法 DART,方法简单且兼容 FlashAttention(不依赖 attention map)。
-
Superior Performance with Extreme Compression:在多个 MLLM 与超过十个基准上展示 DART 的优秀性能(例如:在 LLaVA-1.5-7B、保留 64 token 时,DART 达到 93.7%,比第二名高 2.2%),并在极端压缩率(↓88.9%)下仍保持较高准确率与显著加速。相关实验结果见表格与表 1、2、3。
4. Method

4.1 概览(Pipeline)
尽管“基于重要性(importance-based)”的 token 剪枝范式在提升多模态大语言模型(MLLMs)推理效率方面取得了初步成功,但这种方法本身存在一些难以克服的结构性局限。 论文在此小节中从形式化角度揭示了其核心问题:忽视了 token 重要性的动态性(dynamic nature)。
对于一个 token 序列 ${x_1, x_2, \dots, x_n}$,传统的剪枝方法会通过一个静态打分函数来计算每个 token 的重要性:
$$ s_i = F(x_i \mid X), $$
其中 $X$ 表示完整的 token 集合。接着,它们会选择得分最高的前 $k$ 个 token 进行保留:
$$ X_{\text{pruned}} = \arg\max_{X’ \subseteq X,,|X’| = k} \sum_{x_j \in X’} s_j \tag{4} $$
这种做法隐含了一个独立性假设(independence assumption): 即每个 token 的得分 $s_j$ 不会因为其他 token 的增删而发生变化,认为 token 的重要性是静态且互不影响的。
然而,这与 Transformer 架构中 token 之间复杂的交互关系相矛盾。 举例来说,若两个 token $x_p$ 与 $x_q$ 语义上高度相似(即 $s_p \approx s_q$),那么当我们删除其中一个(例如 $x_q$)后,剩下的那个 $x_p$ 的重要性理应提升,因为它现在唯一保留了这部分语义信息:
$$ s’_p = F(x_p \mid X’ \setminus {x_q}) > s_p \tag{5} $$
这就导致了一个重要性估计偏差(bias in importance estimation):
$$ \Delta = s’_p - s_p $$
也就是说,当剪枝发生时,原本的静态重要性分数 $s_p$ 已不再准确,它没有反映 token 间的动态补偿效应。
为了形式化描述这种“静态评分与动态交互之间的矛盾”,论文进一步定义了在所有随机子集 $X’ \subset X$ 上的期望偏差:
$$ \mathbb{E}{X’ \subset X} \left[ \sum{x_i \in X’} \Delta_i \right] $$
这个表达式表明,在随机采样的子集上,静态重要性分数与真实的交互式重要性之间存在系统性偏差,而这种偏差在期望意义下是非零的。 这正是许多基于重要性剪枝方法在实践中出现“保留错误 token”或“性能不稳定”的根本原因:它们假设每个 token 的价值是固定的,但实际上 token 之间存在着动态的相互依赖与补偿关系。
DART 的核心思想与流程可分为两步(图示见 Figure 3):
-
选择少量 pivot tokens $P={p_1,\dots,p_k}$($k \ll n$,通常不超过全部 token 的 2%):这些 pivot token 通过简单且计算量极小的策略选取(例如按 K-norm 最大,或 V-norm,或直接随机),目的是用少量代表性 token 覆盖整个 token 空间。
-
基于 pivot 计算 duplication(余弦相似)并筛除重复 token:对每个视觉 token $x_j$ 计算其与所有 pivot 的 cosine similarity(定义为 ϵ-duplicate score),然后以预定的 token 保留比例(reduction ratio)动态确定阈值 $\epsilon$,保留那些与 pivot 最不相似的 token(即低重复),删除与 pivot 重复度高的 token。由于 pivot 数量极少,这一步计算开销很小(论文报告整个过程 overhead ≤ 0.08s)。
整体思路的直观理由:保留与 pivot “最不同”的 token,可以最大化 retained set 的覆盖性(即尽量保留多样性信息),同时删除那些与其它 token 高度重复、信息冗余的 token,从而以极低的计算成本实现信息保留。
4.2 关键定义与公式(来自论文)
- Transformer 中的注意力(复述):
$$ \text{Attention}(Q,K,V) = \text{softmax}\left(\frac{QK^\top}{\sqrt{d_k}}\right)V. $$
(论文在 §3.2 展示了这一经典公式以引入基于 attention 的 importance 流派。)
-
Pivot token(定义 1):$P={p_1,\dots,p_k}\subset X$,$k\ll n$,代表性子集(用于代表整个视觉 token 集合)。
-
ϵ-duplicate Score(定义 2):对 pivot $p_i$ 与视觉 token $x_j$:
$$ \text{dup}(p_i, x_j) = \frac{p_i^\top x_j}{|p_i| |x_j|}, $$
若 $\text{dup}(p_i,x_j) > \epsilon$,则称 $p_i$ 与 $x_j$ 为 $\epsilon$-duplicates。基于此,为每个 pivot 定义:
$$ R_i = { x_j \mid \text{dup}(p_i, x_j) \le \epsilon } $$
最终 retained set:
$$ R = P \cup \left( \bigcup_{p_i \in P} R_i \right). $$
阈值 $\epsilon$ 针对每个 pivot 动态设定以满足总体的 reduction ratio(即确保最终保留 token 数等于目标)。
4.3 Pivot tokens 的选择策略(实践细节)
论文中实验了多种 pivot 选取策略并发现 对最终效果不敏感(即 DART 对 pivot 的选择具有鲁棒性)——常用策略包括:
-
按 K-norm 最大(K-norm♠):即计算 attention 中 $K$ 矩阵对应 token 的 L1-norm(或某种 norm 度量),选择 top-k。论文在大多数主实验中采用了 K-norm 最大选择作为默认设置。
-
按 V-norm:类似的用 $V$ 矩阵的 norm。
-
按 attention score(A-Score):使用 attention-based 排序(注意:这种策略会牺牲对 FlashAttention 的兼容性,如果需要暴力访问 attention map)。
-
随机选择(Random):完全随机抽取 pivot。令人惊讶的是,随机策略的性能仅比最优策略低约 1.2%(在某些实验中与基于 importance 的方法相比仍有明显优势),这说明 duplication-driven 的设计比选 pivot 的“重要性”更关键。
4.4 理论分析(性能保证)
论文给出基于 Hausdorff 距离的理论界(Theorem 1),在若干假设下(Transformer property:Lipschitz 连续性相对于 Hausdorff 距离,以及 token embedding 有界 $|x| \le B$),证明了 retained set $R$ 与原始集合 $X$ 在模型输出上的差异是可控的:
-
结论(Lemma / Theorem 的关键信息):
- 若 token 对 pivot 的重复度不超过 $\epsilon$,则任一被删除的 $x$ 与其最接近 pivot 的距离有界: $$ \min_{p_i\in P} |p_i - x_j| \le \sqrt{2(1-\epsilon)} B. $$
- 从而 Hausdorff 距离有界: $$ d_H(X,R) \le \sqrt{2(1-\epsilon)} B. $$
- 结合 Lipschitz 假设 $K$,得到输出误差上界: $$ | f(X) - f(R) | \le K \sqrt{2(1-\epsilon)} B. $$
该界表明,通过控制 $\epsilon$(即允许的重复阈值),可以在可控误差范围内删减重复 token,从而提供理论上的可信度保证(论文的证明详见 §3.4)。
4.5 实现与复杂度/兼容性
-
计算复杂度:由于 pivot 数量 $k$ 很小(论文实验常用 $k=8$,且 pivot 比例 ≤ 2%),计算 pivot 与所有 token 的余弦相似度复杂度为 $O(nk)$,显著低于 $O(n^2)$。因此总体 overhead 很小(论文报告 ≤ 0.08 秒的额外开销),并且该过程可以在预填充(prefill)阶段完成,从而与 FlashAttention 等高效实现兼容,不必暴露 attention map。
-
与 FlashAttention 的兼容性:DART 不需要访问 attention matrix——只在 token embedding 空间做余弦相似度计算,因此能在保留 FlashAttention 加速的同时实现 token pruning,从而在真实部署中既能保证速度也能保持性能。论文在效率对比(表 2)中给出了 DART 与 FastV、SparseVLM 在总时间、prefill 时间、FLOPs、KV cache 等方面的比较,显示 DART 在速度上具有明显优势并兼顾精度。
5. Evaluation
5.0 实验设置(Experiment Setting)
-
模型与基准:在超过 4 个不同的 MLLMs(例如 LLaVA-1.5-7B、LLaVA-Next-7B、Qwen2-VL-72B、MiniCPM 等)和 10+ 图像基准 + 4 个视频基准上评估 DART。详细数据集(GQA、MMB、MME、POPE、SQA、VQAv2、VQA-Text、VizWiz、OCRBench 等)以及视频基准(MSVD、TGIF、MSRVT 等)在附录 C 中给出。
-
剪枝配置:常见设置是在第二层后(after layer 2)进行 token pruning(论文的大量实验采用这一点),pivot token 数量常用为 8,默认 pivot 选取方式为 K-norm 最大(除非做消融对比)。在不同的保留 token 数(例如保留 192、128、64)下进行横向对比。
5.1 Main Results
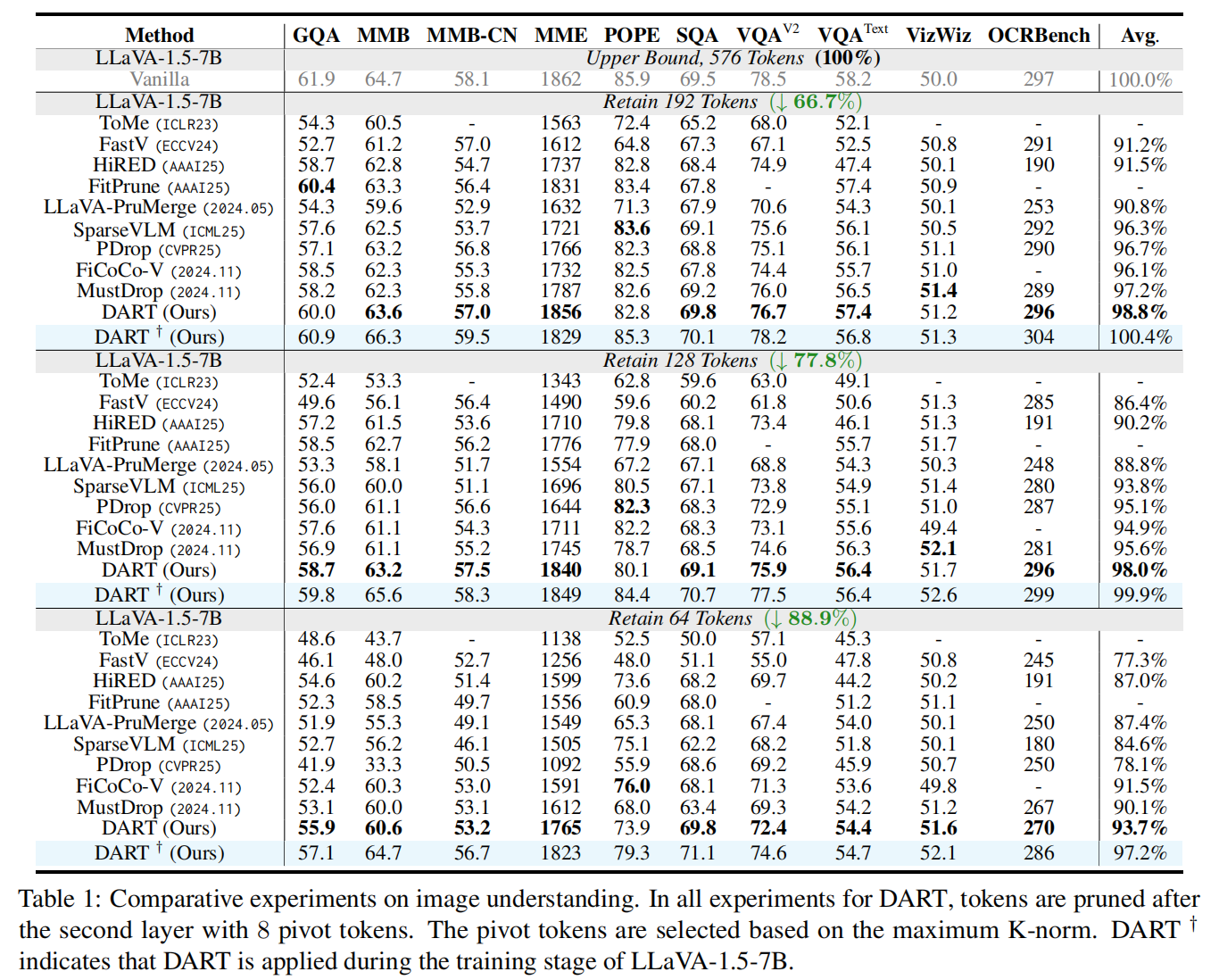 表 1(LLaVA-1.5-7B 不同保留 token 配置):论文在 LLaVA-1.5-7B 上展示了多种 baseline(ToMe, FastV, SparseVLM, HiRED, FitPrune, PDrop, MustDrop 等)与 DART 的对比,在三种主要保留量下(192 tokens ↓66.7%,128 tokens ↓77.8%,64 tokens ↓88.9%):
表 1(LLaVA-1.5-7B 不同保留 token 配置):论文在 LLaVA-1.5-7B 上展示了多种 baseline(ToMe, FastV, SparseVLM, HiRED, FitPrune, PDrop, MustDrop 等)与 DART 的对比,在三种主要保留量下(192 tokens ↓66.7%,128 tokens ↓77.8%,64 tokens ↓88.9%):
-
当保留 192 tokens(↓66.7%) 时,DART 达到 98.8% 的平均表现(接近 Vanilla),并且 DART †(在训练阶段加入 DART)甚至超过 100%(微超 vanilla),表明将 DART 纳入训练阶段能进一步提升 trade-off。
-
当保留 128 tokens(↓77.8%) 时,DART 仍显著优于大部分 baselines(98.0%/99.9% for DART/DART†)。
-
在极端压缩 64 tokens(↓88.9%) 时,DART 仍能取得 93.7%(DART)与 97.2%(DART†),并明显领先 FastV 与多数方法(许多方法在该压缩率下表现急剧下滑)。这正是论文强调 DART 在“极端压缩”场景下的优势。
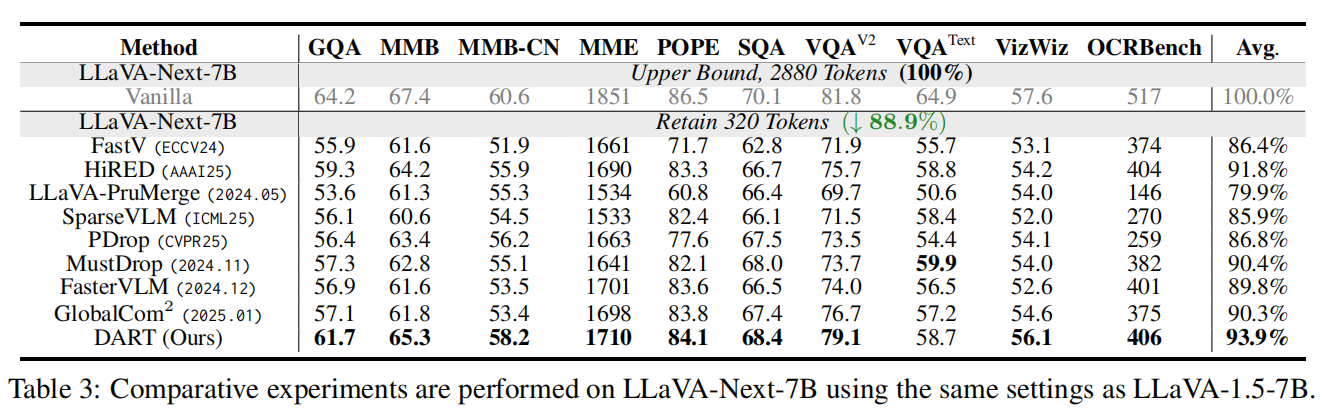
表 3(LLaVA-Next-7B,保留 320 tokens ↓88.9%):在更大/不同架构上,DART 也能保持强鲁棒性(在 LLaVA-Next-7B 上 DART 平均 93.9%),显示方法能够 scale 到大型模型与更高 token 基数场景。
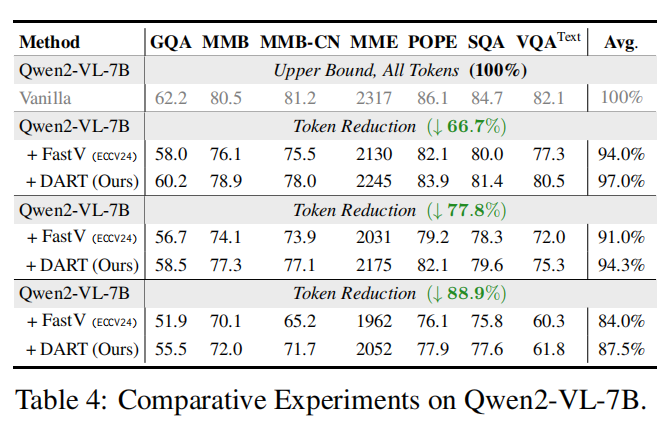
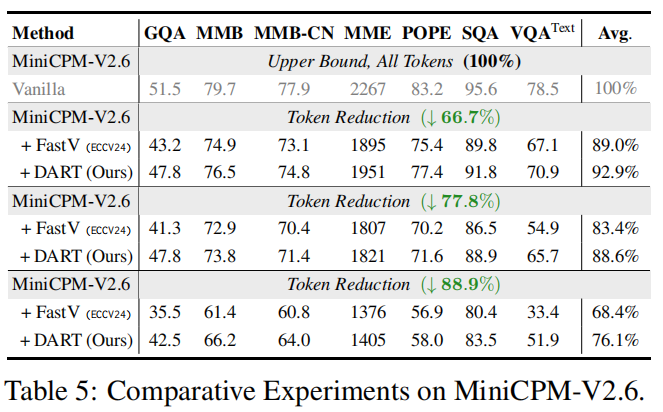
表 4 / 表 5(Qwen2-VL-7B、MiniCPM):DART 在不同模型与不同尺度下都显著优于 FastV,并在多任务(GQA、MMB、MME、POPE 等)上取得稳健提升,表明方法不依赖特定模型结构或训练细节即可发挥效果。
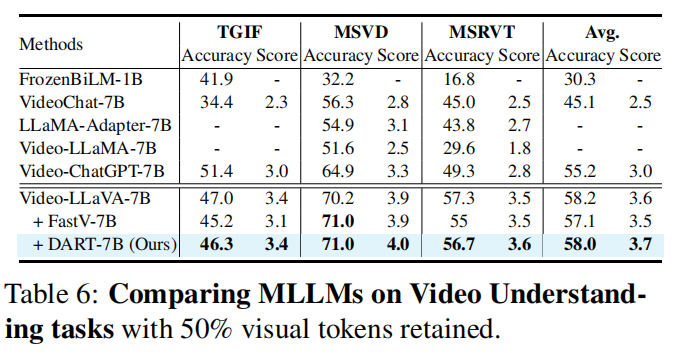
视频理解任务(Table 6):将 DART 集成到 Video-LLaVA,按标准协议对视频抽帧(8 帧,2048 vision tokens,保留 50%)进行评估,DART 在 MSVD、TGIF、MSRVT 等指标上均优于 FastV,平均精度与评分也更好,说明 DART 对时序/多帧冗余也有效。
5.2 Efficiency Analysis(效率分析)
论文不仅报告准确率变化,也在真实推理时间上进行衡量(比仅报 FLOPs 更有说服力):

-
表 2(Inference costs):对比 Vanilla(2880 tokens)与 FastV、SparseVLM、DART(token 减至 320):
- Vanilla 总时间 36:16(min:sec),prefill 22:51;
- +FastV 总时间降到 18:17,prefill 7:41,speedup 1.98×(总)与 2.97×(prefill);
- +DART 总时间 18:13,prefill 7:38,speedup 1.99×(总)与 2.99×(prefill)。
- 注意:FLOPs 与 KV Cache 的相对变化也列出(DART 与 FastV 在 FLOPs 降幅近似时,DART 在实际 wall-clock 上略优,这说明 FLOPs 并非预测实测加速的充分指标,工程实现、内存访问、并行化等实现细节也很重要)。
-
要点总结:
- DART 在不暴露 attention maps 的前提下仍能保持 FlashAttention,加速效果真实(实测 latency 降低)。
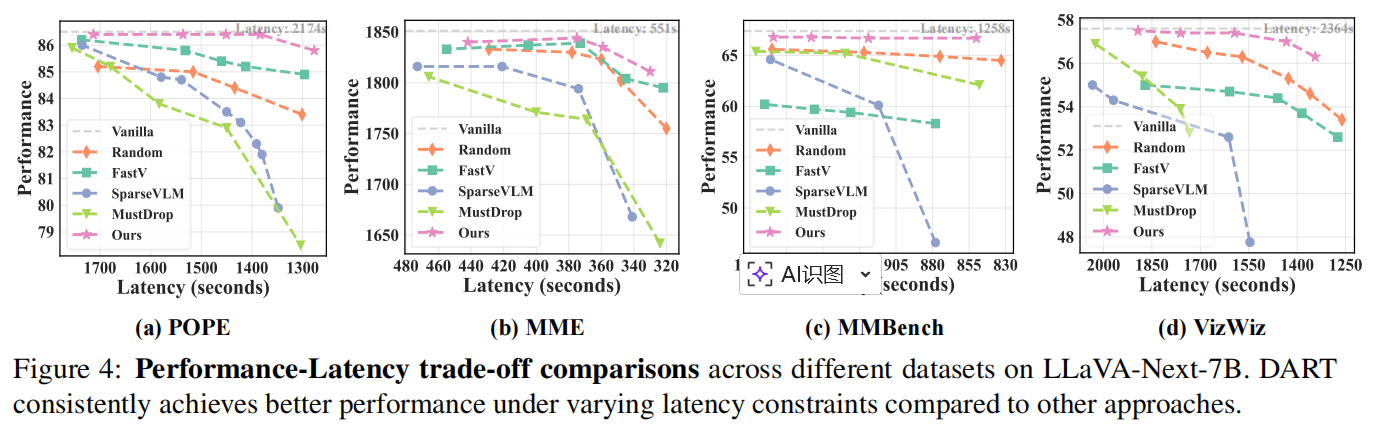
- 与其它方法(如 SparseVLM)相比,即使 FLOPs 接近,实际 speedup 可能不同——因为并行性、内存占用、KV cache 大小与实现细节会影响实测性能。论文对此做了细致讨论并用 Figure 4 展示了 performance-latency tradeoff。
(Figure 4: latency-vs-performance 曲线)
5.3 关于 Pivot Selection、Prune Layer 与 Pivot 数量的消融
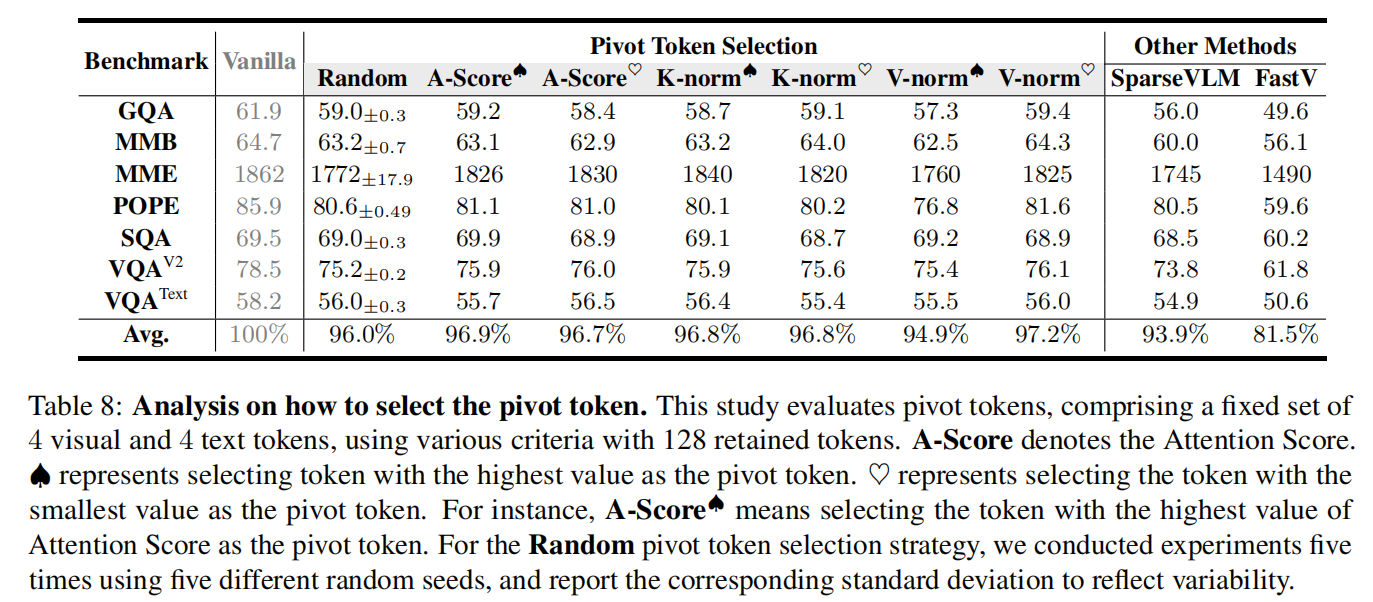 Pivot selection(§5.2):论文在 Appendix A.1 展示了 Table 8,比较了 Random、A-Score、K-norm、V-norm 等策略(在 LLaVA-1.5-7B,保留 128 tokens 的设置),结果显示各种策略均能达到很高的保真度(多数策略 >94.9%),随机策略仅比最优策略差约 1.2%,从统计上说明 DART 对 pivot 的选择并不敏感,强调 duplication 而非 importance 的中心地位。表格摘录见下(论文原 Table 8 的 summary)。
Pivot selection(§5.2):论文在 Appendix A.1 展示了 Table 8,比较了 Random、A-Score、K-norm、V-norm 等策略(在 LLaVA-1.5-7B,保留 128 tokens 的设置),结果显示各种策略均能达到很高的保真度(多数策略 >94.9%),随机策略仅比最优策略差约 1.2%,从统计上说明 DART 对 pivot 的选择并不敏感,强调 duplication 而非 importance 的中心地位。表格摘录见下(论文原 Table 8 的 summary)。
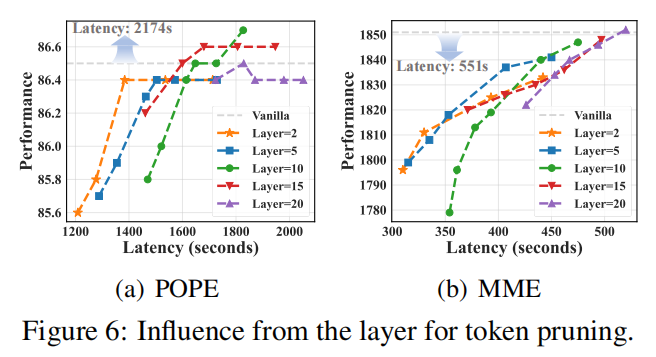
Pruned layer 的影响(§5.3):
- 在较浅层(例如 layer 2)进行剪枝带来最大速度收益,但可能在极端压缩下轻微影响性能;
- 在更深层剪枝(如 layer 10、15、20)通常能接近或超过 vanilla(论文发现某些深层剪枝竟然略优于 vanilla,可能是去除 duplicate token 同时减少 hallucination 的副作用);同时更深层剪枝会减少加速收益(因为早期层的计算仍需执行)。论文以 Figure 6 展示了各层剪枝对性能与 latency 的 trade-off。
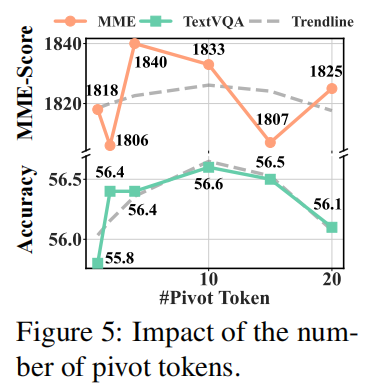
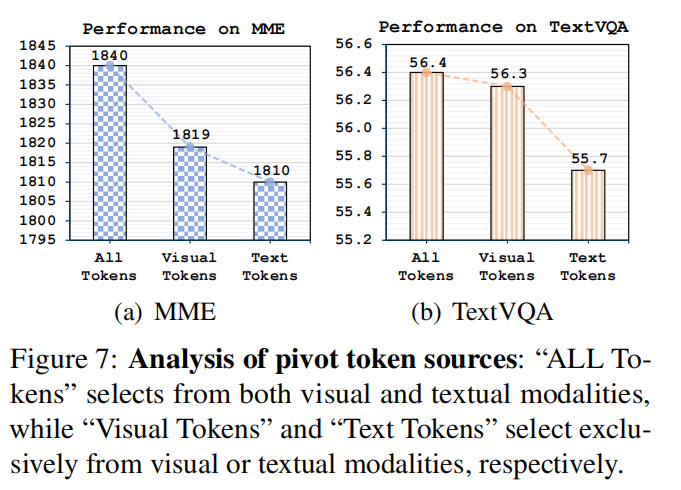
Pivot 数量的影响(Figure 5 与 Appendix A.2):
- Pivot 太少(例如 1-2)会导致代表性不足(覆盖面差),而 pivot 太多(例如 ≥20)会导致多数保留下来的成为 pivot,自身退化成 importance-based 的行为;
- 论文发现中等数量(如 8)能取得稳健表现(这是作者主实验常用值)。
6. Conclusion
-
DART 提出了一条不同于 importance-based 的 token 削减范式:关注重复性(duplication)而非仅仅关注 attention-based importance,并通过选择少量 pivot + 余弦相似度筛除重复 token 的简单机制实现训练免费、对硬件友好且极高效的加速策略。
-
实验表明 DART 在多模型、多数据集与多模态(图像/视频/音频/VLA)上均有竞争力:在极端压缩下仍保持较高精度并实现实测 speedup,且 DART †(训练时使用 DART)还能进一步提升表现。
-
论文的额外 insight 包括:不同保留 token 集合(overlap < 50%)仍可给出类似性能,表明存在多个互补且有效的 token 子集;去除重复 token 甚至能减少 hallucination(在某些基准上 pruned 模型反而优于 vanilla)。