
Conference: NeurIPS'25 Spotlight
Github: https://github.com/snowflakedb/ArcticInference
My Thoughts
这篇 paper 针对 AI 应用中大量推理请求呈现 高度重复、模式化且可预测 的特性,提出了一个我觉得非常优秀的推测解码方法。起初我以为它的思路类似于 prefix cache,但实际阅读后发现:SuffixDecoding 基于 suffix tree 的方法对于 speculative decoding 的约束要小得多。 Prefix cache 需要所有 token 完全一致才能命中,而 SuffixDecoding 只需满足 speculative decoding 的验证条件即可,大大提升了复用空间和适用范围。
我原本担心 suffix tree 在实际部署中会因 规模过大 或 查询速度过慢 而成为瓶颈,但论文中的实验数据基本消除了这些顾虑。根据文中的测量,suffix tree 的内存效率非常高:即使缓存 572M tokens(约 20K 请求),也只占用 6.15GB CPU 内存,平均下来每个 token 仅需 10.75 bytes。在一台常见的 144GB CPU 内存的 A100 系统上,SuffixDecoding 甚至能够缓存 31 天连续生成的数据 而无需 eviction。
更重要的是,即便在如此大规模的 suffix tree 下,其性能依然稳定:
- 更新耗时约 4μs/ token
- 查询耗时约 12μs/ token
构建速度同样令人放心,构建 10 万条示例输出 的 suffix tree 仅需 ~62 秒,且这是整个系统启动时的一次性成本,后续更新增量极小。
1. Motivation
与基础聊天机器人不同,智能体驱动的AI应用会发出高度重复且可预测的推理请求。例如,多智能体系统会反复执行类似子任务,而推理循环[Wang et al., 2023a, Madaan et al., 2023]会不断生成结构相似的token序列。尽管这些工作负载展现出明显的模式重复性,现有推理优化方法仍未充分利用这些特性,导致延迟成为实际部署的关键瓶颈。
为了高效处理智能体驱动应用中常见的长重复序列,推测解码(speculative decoding)方法必须满足两个关键要求。首先,它们需要以极低开销快速生成草稿token,从而最大化对长推测序列的利用效率。其次,它们必须具备自适应性——仅在接收可能性高时生成更多草稿token,而在接收可能性低时生成较少token,以避免验证过程成为计算瓶颈。
虽然推测解码已被广泛应用于降低大语言模型(LLM)推理延迟,但其传统实现主要针对多样化用户任务设计。新兴的AI智能体应用呈现出截然不同的工作负载特征:它们不像传统场景那样提交多样化且相互独立的请求,而是倾向于提交高度重复的推理请求,例如执行相似子任务的多智能体流水线,或迭代优化输出的自我精炼循环。这些工作负载会产生长且高度可预测的序列,而当前的推测解码方法并未有效利用这些特性。
2. Challenge
现有的推测解码方法在满足上述双重要求方面存在明显不足。基于模型的方法(如EAGLE、Medusa等)在推测长序列时会消耗大量GPU计算资源,并可能引发内存竞争和内核级切换[Chen et al., 2024b, Li et al., 2024],需要复杂的工程优化。相反,现有的无模型方法(如Prompt-Lookup Decoding (PLD) [Saxena, 2023])虽然实现了低开销和快速的token生成,但通常缺乏自适应性,无论接收可能性如何,都会推测固定数量的token,导致在验证长且可能性低的序列时浪费大量计算资源。
3. Related Work
现有推测解码方法主要分为两类:
- 基于模型的方法:包括Medusa[Cai et al., 2024]、SpecInfer[Miao et al., 2024](引入了基于树的推测架构)、多token预测[Gloeckle et al., 2024]和块级并行解码[Stern et al., 18, Kim et al., 2024]。
- 无模型方法:包括Prompt Lookup Decoding[Saxena, 2023]、Token Recycling[Luo et al., 2024]、LLMA[Yang et al., 2023]和ANPD[Ou et al., 2024]。这些方法依赖于小规模参考文本,缺乏上下文自适应能力。
SuffixDecoding是首个专为具有长重复序列的智能体应用而设计的无模型推测方法。
智能体AI算法特性:智能体应用将任务结构化为多次LLM调用,生成长且重复的token序列。Self-consistency[Wang et al., 2023a]从同一提示中采样多个推理路径,这些路径共享相似的思维链步骤。Self-refinement[Madaan et al., 2023]迭代修正错误,在修改小部分内容的同时保留周围内容。多智能体工作流[Khot et al., 2023]使用具有特定功能的专用智能体,产生结构化的重复输出。这些模式为利用历史序列中的重复模式创造了独特机会。
加速LLM智能体的方法:近期工作聚焦于降低智能体应用中的延迟。ALTO[Santhanam et al., 2024]通过流水线和调度优化多智能体工作流。Dynasor[Fu et al., 2024]提前终止可能性低的推理路径。SuffixDecoding采取正交的推测解码方法,可与上述方法无缝结合使用。
4. Method
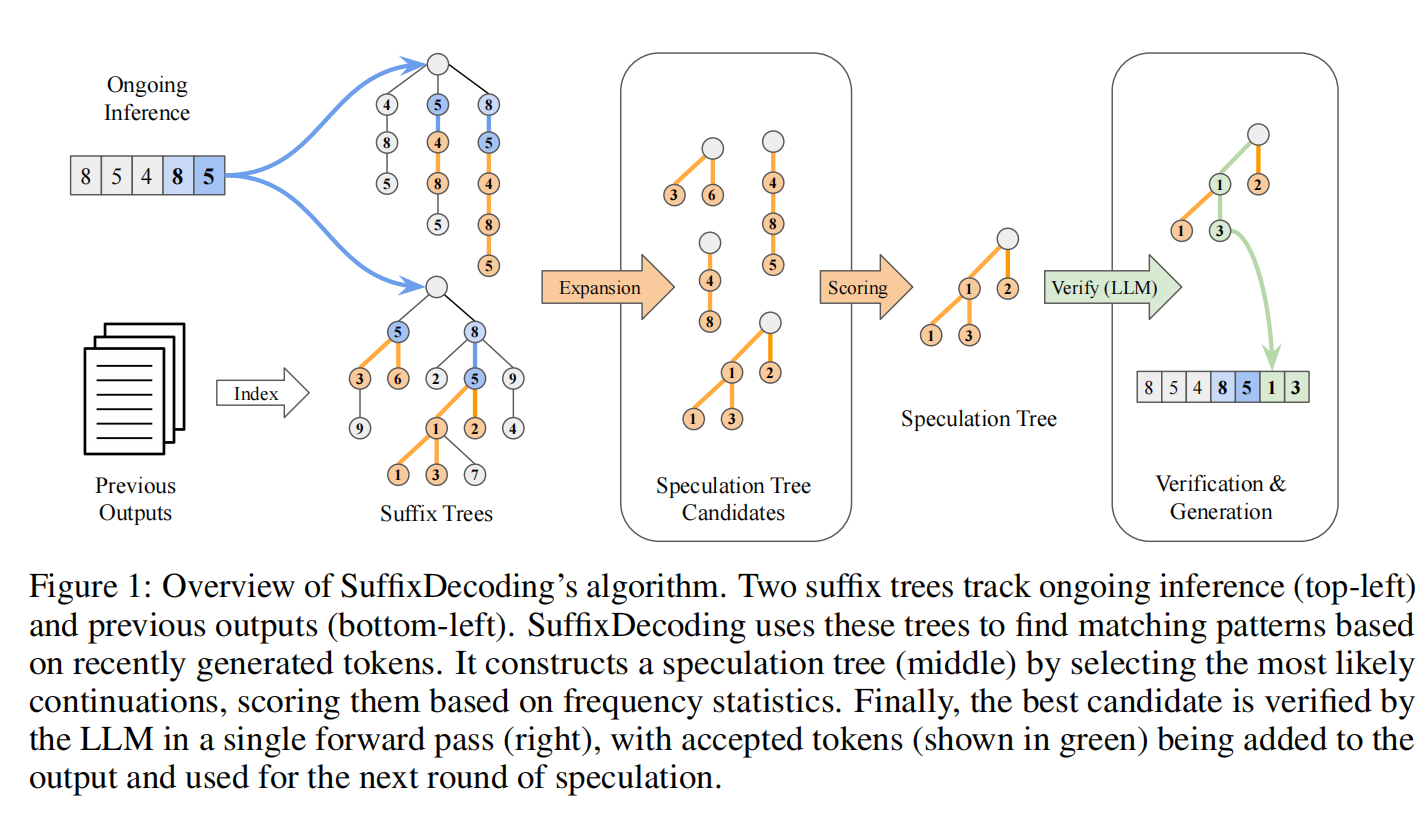 SuffixDecoding的核心目标是在长序列上实现快速、自适应的推测解码,尤其适用于智能体应用。在这些场景中,重复的推理调用通常包含高度可预测且重叠的token序列,使得输出的长片段可以从先前和当前请求中准确预测。
SuffixDecoding的核心目标是在长序列上实现快速、自适应的推测解码,尤其适用于智能体应用。在这些场景中,重复的推理调用通常包含高度可预测且重叠的token序列,使得输出的长片段可以从先前和当前请求中准确预测。
为实现这一目标,SuffixDecoding必须应对两个关键挑战:
- 高效生成:支持快速生成长推测序列,无需依赖草稿模型或逐token计算
- 上下文自适应:根据当前预测置信度动态调整推测长度
4.1 后缀树构造:构建历史模式记忆
SuffixDecoding使用高效的后缀树(suffix trees)[Weiner, 1973]作为核心数据结构,缓存来自提示和先前输出的长token序列。在后缀树中:
- 树的根节点表示任意序列后缀的起始点
- 每个节点表示一个token
- 从根到叶节点的路径编码了先前观察到的token子序列
- 每个节点存储访问频率统计,用于预测后续token概率
对于每个请求,SuffixDecoding考虑从两个来源推测token序列:
- 当前请求的提示和已生成输出
- 先前请求的历史输出
这种双源策略有效捕捉了多种智能体算法(self-consistency, self-refinement, 多智能体流水线)中的输出重复模式。
后缀树实现细节:
- 双树架构:维护两种不同的后缀树
- 全局树(Global Tree):存储所有先前请求的输出,可离线预构建,时间复杂度O(n)
- 每请求树(Per-request Tree):存储当前请求的提示和已生成token,支持在线增量更新[Ukkonen, 1995]
- 内存效率:尽管后缀树在最坏情况下需要O(n)空间,但实际应用中非常高效
- AWS p5.48xlarge实例(2TB内存)可缓存数月的生成内容
- 典型A100系统(144GB CPU内存)可缓存31天的连续生成输出
- 更新机制:全局树从历史日志批量构建,每请求树在推理过程中实时更新
4.2 推测树扩展:从模式匹配到候选生成
给定当前序列$x_{1:t}$和模式长度$p$,SuffixDecoding首先在后缀树中定位匹配节点$N_p$,该节点代表序列$x_{t-p+1:t}$。然后,通过以下步骤构建推测树:
-
概率估计:定义两个关键指标
- $C(N) = \frac{COUNT(N)}{\sum_{M\in CHILDREN(PARENT(N))} COUNT(M)}$ 表示在已知父节点历史的情况下,节点N被访问的条件概率
- $D(N) = \begin{cases} 1, & \text{if } N = N_p \ D(PARENT(N)) \times C(N), & \text{otherwise} \end{cases}$ 表示从根到节点N的完整路径被接受的概率估计
-
贪婪扩展:从匹配节点$N_p$开始,迭代扩展最有希望的路径
- 每次选择具有最高$D(N)$值的子节点
- 持续扩展直到达到最大推测大小$MAX_SPEC$
- 保证在有限计算预算内选择最可能被接受的序列
这种机制使SuffixDecoding能够从后缀树中提取复杂的历史模式,例如JSON结构中的键值对序列或SQL查询中的表连接模式,而无需任何模型计算。
4.3 自适应推测长度:动态调整置信度
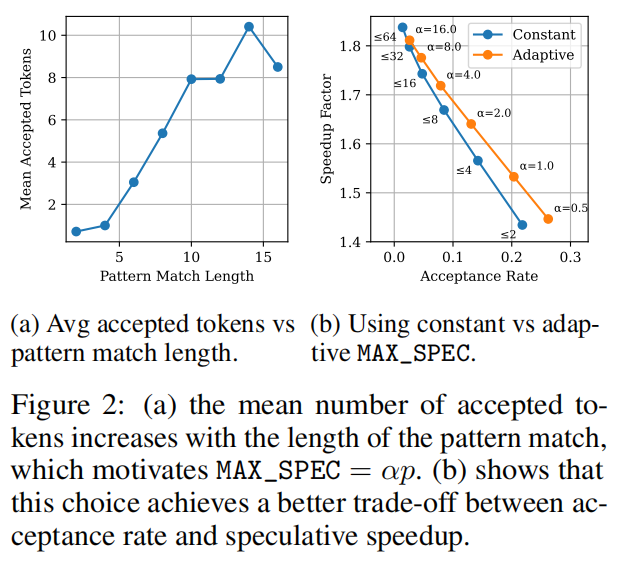
SuffixDecoding通过智能调整$MAX_SPEC$参数实现推测长度的自适应控制:
- 低值:选择少量高置信度token,减少验证浪费
- 高值:推测更多token,最大化加速潜力
关键观察:实验发现接受的token数量随模式匹配长度$p$显著增加(图2a)。基于此,SuffixDecoding定义: $$MAX_SPEC(p) = \alpha p$$ 其中$\alpha$是用户定义的最大推测因子(通常在1-4之间)。
自适应优势:
- 长模式匹配(高置信度)→ 增加推测长度 → 最大化加速
- 短模式匹配(低置信度)→ 减少推测长度 → 避免计算浪费
图2b证明这种自适应策略在接收率和速度提升之间实现了最佳平衡,优于固定推测长度的方法。
4.4 推测树评分:多源信息融合

由于SuffixDecoding维护两个后缀树(全局和每请求)并考虑多种模式长度$p$,它会生成多个候选推测树。为选择最佳候选,定义评分函数: $$SCORE(T_{spec}) = \sum_{N \in T_{spec}} D(N)$$
该评分直观地估计了推测树$T_{spec}$中预期被接受的token总数。SuffixDecoding执行以下步骤:
- 为全局树和每请求树分别生成候选树
- 对每个树尝试多种模式长度$p$(1到P)
- 为每个候选树计算SCORE
- 选择具有最高SCORE的树作为最终推测树
算法1详细描述了这一端到端的候选生成和选择过程。
4.5 混合推测解码:通用工作负载支持
为适应混合工作负载(既有重复性智能体任务又有开放式对话),SuffixDecoding支持动态切换到基于模型的推测方法:
- 置信度过滤:计算$SCORE(T_{spec})$作为模式匹配质量的指标
- 阈值决策:设定阈值$\tau$
- 若$SCORE(T_{spec}) > \tau$:使用SuffixDecoding的推测结果
- 否则:回退到EAGLE-3等基于模型的推测器
- 阈值指导:
- 混合工作负载:$\tau$设为接近回退推测器的平均接受token数
- 高度重复任务:$\tau=0$(始终使用SuffixDecoding)
- 完全开放式任务:较高的$\tau$值(更多使用模型推测)
这种混合方法在保留SuffixDecoding在重复任务上优势的同时,确保了在多样化任务上的鲁棒性。
5. Evaluation
5.1 Evaluation Methodology
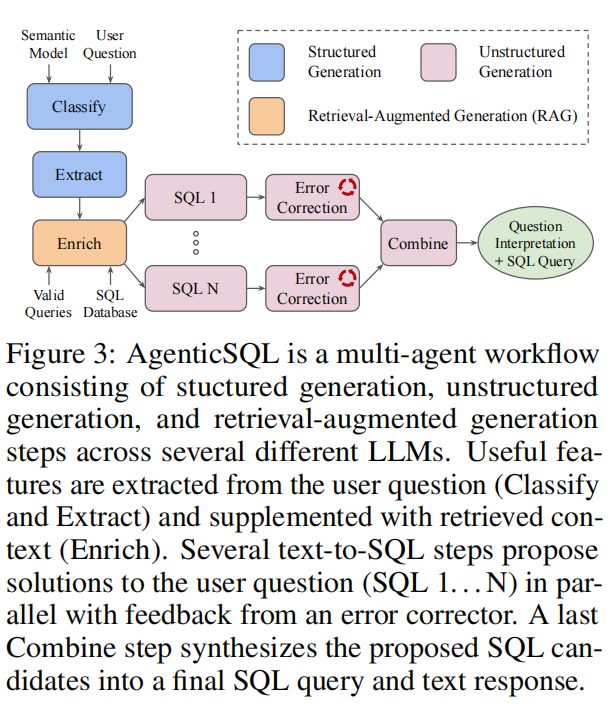
Baseline Comparisons:使用Spec-Bench[Xia et al., 2024]与先进推测方法比较:
- 基于模型方法:EAGLE-2和EAGLE-3[Li et al., 2025a]
- 无模型方法:Prompt-Lookup Decoding(PLD)[Saxena, 2023]和Token Recycling[Luo et al., 2024]
Datasets and Applications:
- 智能体应用:OpenHands[Wang et al., 2024c]在SWE-Bench[Jimenez et al., 2024]上;专有应用AgenticSQL(图3)
- 非智能体工作负载:Spec-Bench(13类别,含8个MT-Bench类别)
系统实现:在vLLM[Kwon et al., 2023]中实现,实测端到端加速效果。
硬件配置:单个AWS p5.48xlarge实例(8×NVIDIA H100 80G GPU,2TB内存)。
5.2 Baseline Comparisons
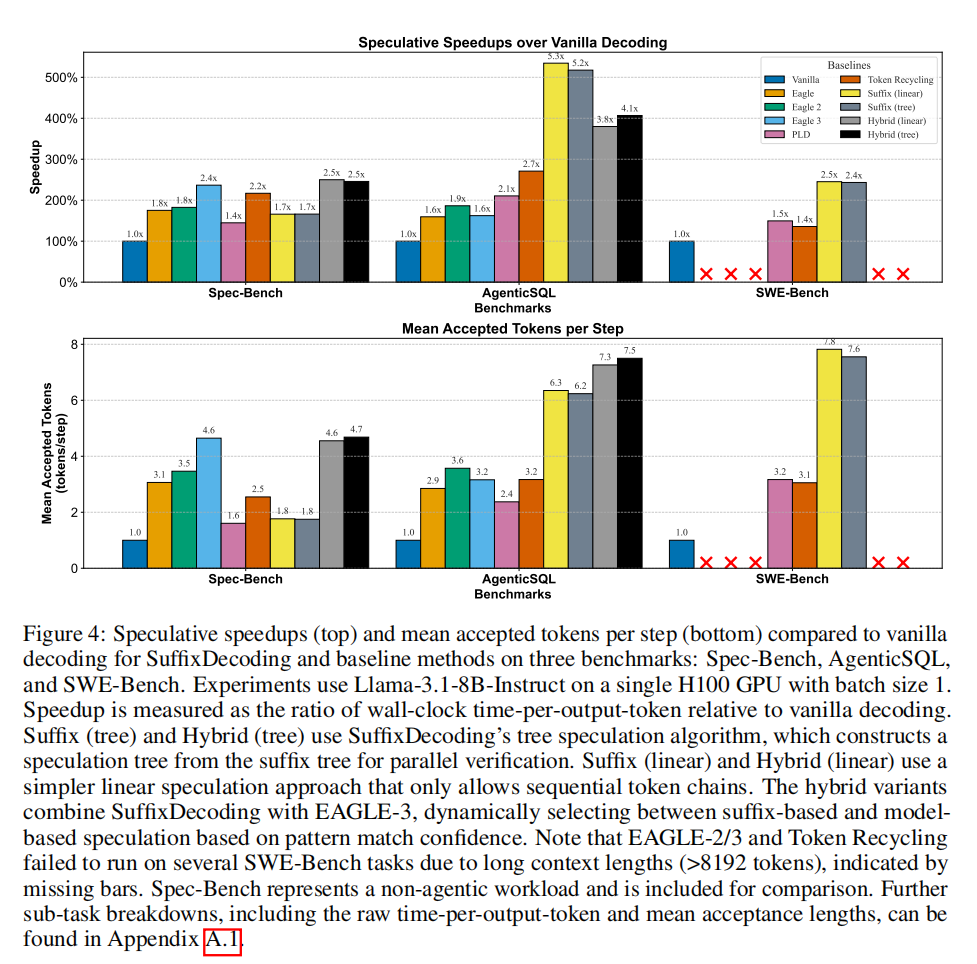
智能体工作负载性能:
- AgenticSQL:SuffixDecoding获得5.3×平均加速,比EAGLE-2/3快2.8×,比Token Recycling快1.9×
- SWE-Bench:获得2.5×平均加速,比PLD快1.7×
关键指标分析:
- AgenticSQL:SuffixDecoding实现6.3个平均接受token/步,远高于EAGLE-3(3.6)和Token Recycling(3.2)
- SWE-Bench:实现7.8个平均接受token/步,而PLD仅3.2个
非智能体工作负载:
- 单独SuffixDecoding在开放任务上表现一般
- 混合方法(SuffixDecoding+EAGLE-3)在Spec-Bench上获得2.5×加速,优于单独EAGLE-3(2.4×)和Token Recycling(2.2×)
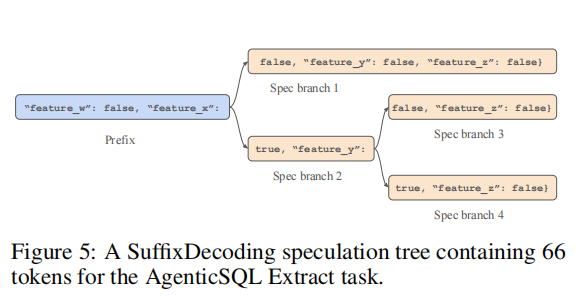
推测树分析:图5展示了AgenticSQL Extract任务的推测树实例。该任务输出JSON文档,具有固定结构和布尔值特征。SuffixDecoding成功捕获了这些模式,构建了一个包含66个token的推测树,其中每个布尔值分支都对应一种可能的输出路径。在实际验证中,正确路径往往能一次性接受数十个token,显著加速生成过程。
5.3 End-to-End SWE-Bench on vLLM
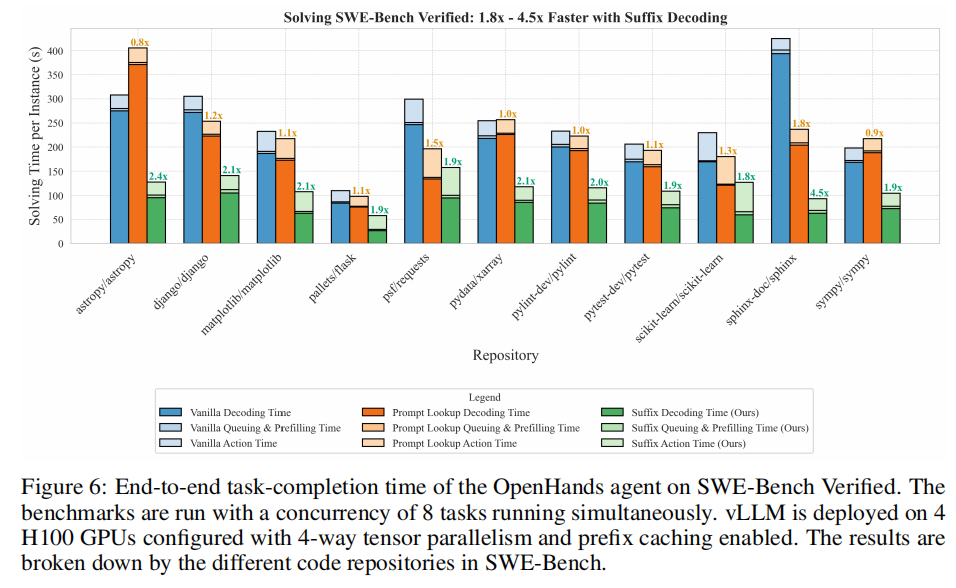
在真实vLLM部署中,SuffixDecoding显著加速了OpenHands智能体在SWE-Bench上的端到端性能:
- 解码时间(输出生成)占总任务时间的大部分
- 相比PLD,SuffixDecoding提速1.3-3×
- 相比普通解码,获得1.8-4.5×的推测加速
- 保持100%的输出质量,维持37.2%的SWE-Bench Verified得分
5.4 Ablation Experiments
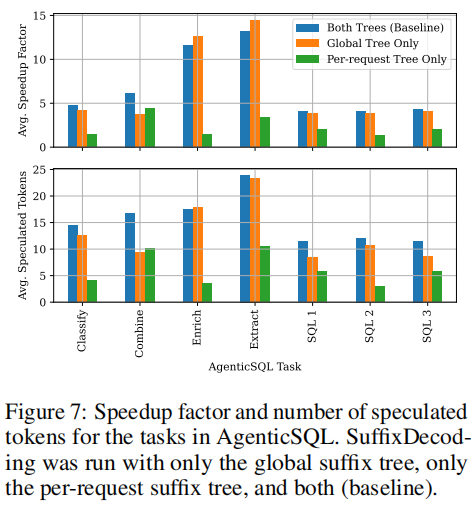
全局树vs每请求树:图7显示两种后缀树的互补价值:
- 大多数任务中,结合两棵树效果最佳
- 全局树在多数任务上优于每请求树
- Combine任务例外:高度依赖当前请求上下文,每请求树更有效
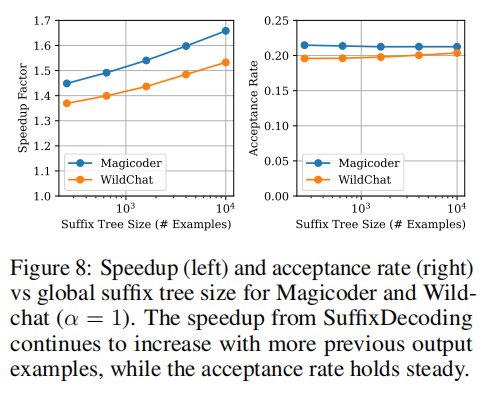
开放场景适应性:尽管专为智能体设计,SuffixDecoding在WildChat和Magicoder上也展现潜力:
- 加速效果随后缀树大小增加而持续提升
- 接受率保持稳定,不受树大小显著影响
- 证明了方法在多样工作负载上的适应性
6. Conclusion
本文提出的SuffixDecoding是一种创新的无模型推测解码方法,专为新兴智能体应用设计。通过高效后缀树数据结构,它能够充分利用智能体工作负载中的重复模式,实现极端长度的推测解码。在SWE-Bench和专有AgenticSQL工作流上的实验表明,SuffixDecoding显著降低了推理延迟,比现有最佳方法快1.9-2.8倍,并在端到端任务中实现高达4.5倍的加速。这种性能提升无需牺牲输出质量,且能无缝集成到现有推理系统(vLLM)中。
7. Frequently Asked Questions
How much memory does SuffixDecoding require?
SuffixDecoding is highly memory efficient. The suffix trees scale linearly with the number of cached tokens:
-
20K requests (~572M tokens): ~6.15 GB of CPU memory
-
Per-token memory: ~10.75 bytes/token
-
Typical capacity: Can cache 31 days of continuous generation on a standard A100 system (144GB CPU memory) before requiring cache eviction
-
Lookup/update speed:
- Updates: ~4 microseconds/token
- Lookups: ~12 microseconds/token
- Even at large tree scale
What happens when the input distribution shifts?
SuffixDecoding adapts online to distribution shifts.
-
In experiments switching from WildChat → SpiderSQL (large shift):
- Initially: 1.5× speedup
- Quickly adapts by inserting new outputs
- After ~500 requests, performance becomes almost indistinguishable from training on that distribution offline
This demonstrates strong online adaptation capabilities.
What is AgentSQL and why does SuffixDecoding work so well on it?
AgenticSQL is a proprietary multi-agent workflow designed for complex SQL generation. It contains multiple LLM-powered stages that convert natural language into SQL.
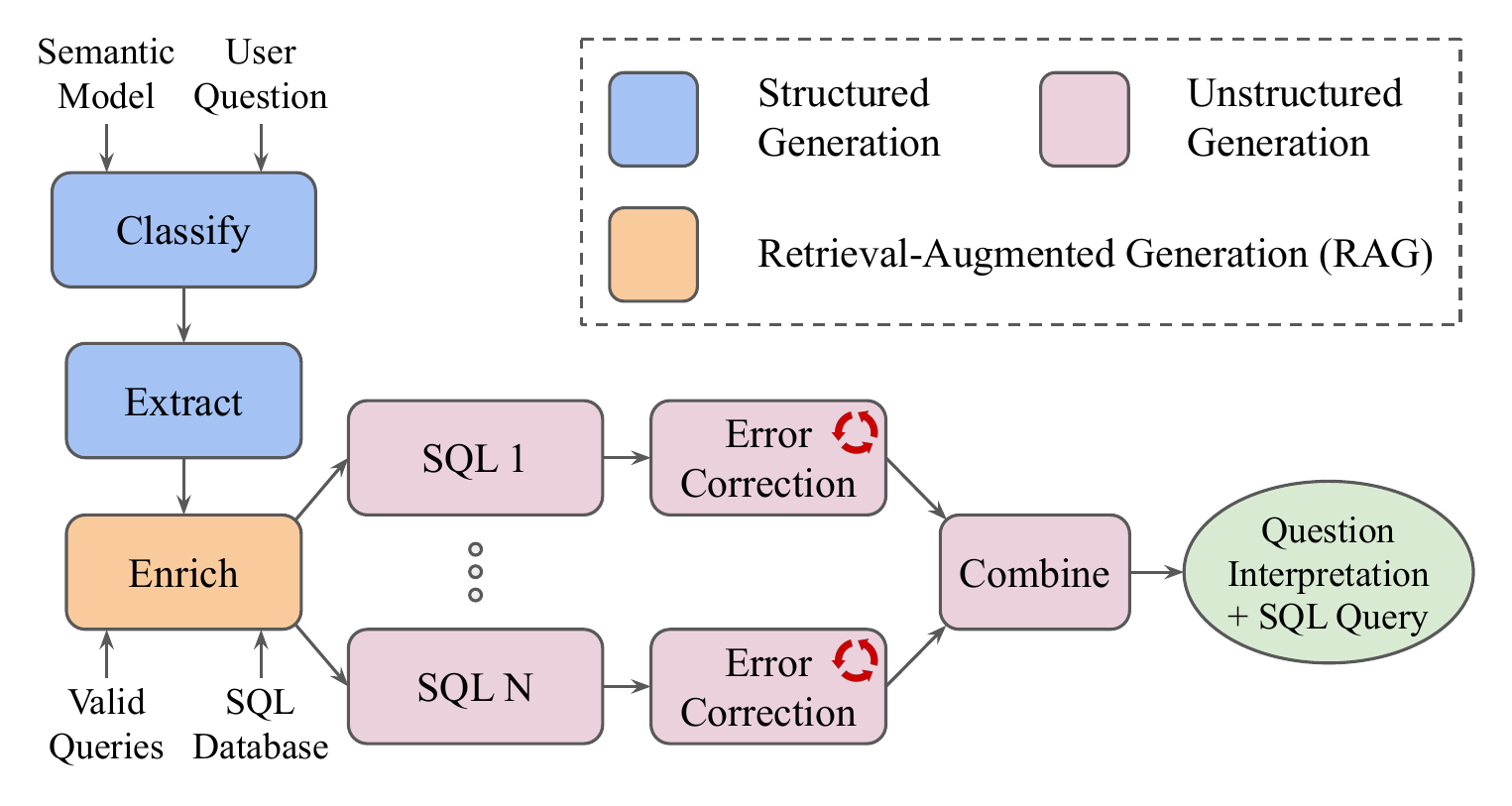
Workflow stages include:
- Classify & Extract: Extract metadata and features
- Enrich: RAG-based context enrichment
- SQL Generation (SQL 1…N): Several text-to-SQL agents produce candidates, assisted by error correction
- Combine: Merge SQL candidates + generate final answer
SuffixDecoding achieves excellent performance (e.g., 10.41× speedup on Enrich, 9.85× on Extract) because:
- Structured outputs (JSON, SQL) with high consistency
- Repetitive patterns across similar queries
- Schema consistency across tasks
- Multi-stage reuse of intermediate outputs
This shows SuffixDecoding’s strength for production agentic workflows with structured, repetitive output patterns.
How can I predict if SuffixDecoding will work well for my application?
Measure “structuredness” via empirical entropy using only 100 output samples:
- Build a suffix tree from outputs
- Compute each node’s entropy from child access frequencies
- Take a weighted average across nodes
- Lower entropy → output tokens more predictable → SuffixDecoding performs better
Reference entropy values:
| Task | Entropy |
|---|---|
| AgenticSQL (Enrich) | 0.171 |
| AgenticSQL (Classify) | 0.738 |
| AgenticSQL (Extract) | 0.0862 |
| AgenticSQL (SQL1) | 1.52 |
| AgenticSQL (SQL2) | 1.49 |
| AgenticSQL (SQL3) | 1.51 |
| AgenticSQL (Combine) | 1.49 |
| Spider | 2.50 |
| WildChat | 3.43 |
| Magicoder | 2.95 |
This metric correlates well with actual performance, allowing practitioners to predict suitability.
Should I use SuffixDecoding alone or in hybrid mode?
Depends on workload:
-
Highly repetitive agentic tasks → Use SuffixDecoding alone with τ = 0
- On AgenticSQL: 5.35× speedup
-
Mixed or open-ended workloads → Hybrid mode with τ ≈ mean accepted tokens of fallback speculator
- For example, with EAGLE-3 (MAT ≈ 4.65) → set τ = 5–7 → 2.5× speedup on Spec-Bench
Can SuffixDecoding work with batch serving?
Yes. It is compatible with batch-level speculation control like:
- TurboSpec
- AdaServe
SuffixDecoding’s statistical scores help:
- Dynamically allocate speculation budgets per request
- Maximize batch goodput
- Meet SLO constraints
How long does it take to build the suffix tree?
Tree construction is fast and done once at startup:
- 1,000 examples: 0.30s, 137MB
- 10,000 examples: 4.82s, 1.4GB
- 100,000 examples: 61.95s, 14.7GB
The tree is incrementally updatable with minimal overhead.
Does SuffixDecoding preserve the output distribution?
Yes. As a speculative decoding method, SuffixDecoding is mathematically guaranteed to preserve the exact output distribution of the target LLM.
Example:
-
On SWE-Bench Verified with vLLM:
- Achieved 37.2% task completion (same as vanilla decoding)
- Delivered 1.8–4.5× speedup