
1. Introduction
投机采样(Speculative decoding, SD)已成为在不牺牲输出质量的前提下加速大语言模型(LLM)推理的标准技术。最近的进展已从序列链式草稿(chain-based drafting)转向树状结构生成(tree-structured generation),即草稿模型(draft model)构建候选标记树,以并行探索多种可能的草稿。
然而,现有的基于树的 SD 方法(如 EAGLE, Sequoia)通常构建固定宽度、固定深度的草稿树,无法适应标记和上下文不断变化的难度。这导致草稿模型无法动态调整树结构,无法在遇到困难标记(difficult tokens)时及早停止,也无法在简单标记上扩展生成。
为了解决这些挑战,作者提出了 TALON:一种无需训练(training-free)、预算驱动(budget-driven) 的自适应树扩展框架,可以无缝集成到现有的基于树的方法中。与静态方法不同,TALON 迭代构建草稿树,直到达到预设的标记预算(Token Budget),并采用混合扩展策略,根据各层节点动态分配预算。
- 核心理念:将草稿树塑造成“深而窄”(deep-and-narrow)的形式以应对确定性上下文,以及“浅而宽”(shallow-and-wide)的形式以应对不确定的分支,从而在给定预算下优化探索宽度与生成深度之间的权衡。
- 实验表现:在 5 个模型和 6 个数据集上的广泛实验表明,TALON 一致优于最先进的 EAGLE-3,相比于自回归解码(auto-regressive decoding)实现了高达 5.16× 的端到端加速。
2. Motivated Experiments
为了从经验上调查静态树结构的局限性,作者使用 EAGLE 作为代表性基线进行了试点分析。作者在 MT-Bench 上使用 Qwen3-8B,设置固定树拓扑为宽度 、深度 。
4.1 The “Acceptance Funnel” Phenomenon (接受漏斗现象)
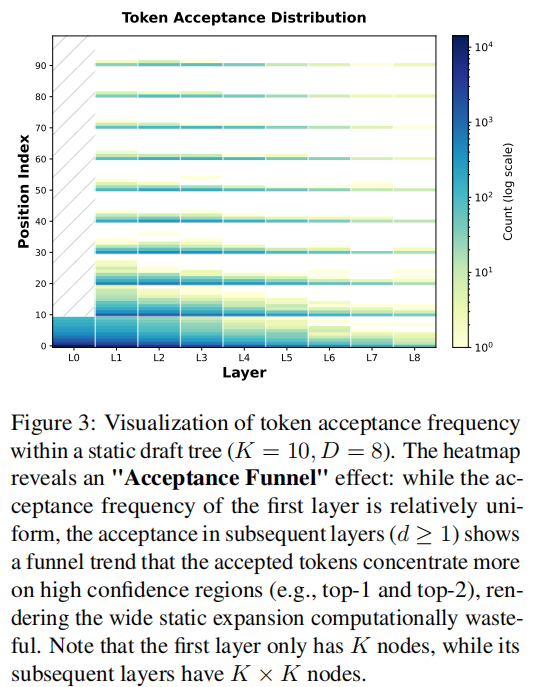
作者首先研究了草稿树中每个位置的接受频率。Figure 3 展示了静态树结构中各层各位置标记的接受频率分布。关于有效投机的分布,出现了两个关键观察结果:
- 深层宽度的边际收益递减:如图 3 所示,接受分布呈现出漏斗状模式。在初始层(),接受概率在 Top-K 候选者中相对均匀,这表明由于草稿模型 与目标模型 之间的初始随机性和分布差异,需要较宽的搜索宽度。
- 误差累积放大:随着树的加深(),接受质量迅速集中在高置信度区域(如 top-1 和 top-2)。对于深层节点,草稿模型要么(1)与目标模型自信地对齐(预测正确),要么(2)由于自回归草拟过程中的误差累积,产生即便 top-K 候选也无法覆盖的幻觉路径。
- 结论:在深层维持 的固定宽度会产生巨大的冗余。当模型自信时,极小的 即可;当模型高度不确定时,应当停止生成以避免浪费计算资源。
4.2 Variance in Real-World Accepted Length (实际接受长度的方差)

虽然 4.1 揭示了固定宽度的结构冗余,作者进一步研究了固定深度的弱点。
- The Static Depth Dilemma (静态深度困境):如图 4 所示,即使在同一任务类别(如数学或代码)中,平均接受标记(MAT)也会剧烈波动。
- 低熵(简单)上下文:草稿模型与目标模型高度一致,潜在接受长度往往超过预定义的深度 。静态深度限制了 生成更多标记的能力,限制了加速上限。
- 高熵(复杂)上下文:预测变得模糊,草稿模型倾向于在注定被拒绝的分支上生成深度幻觉。固定深度强迫计算资源分配给这些无效标记,增加了延迟开销,边际效用为零。
3. Method
作者引入 TALON,这是一个预算驱动的框架,通过根据实时模型置信度动态分配资源来优化草稿树的构建。
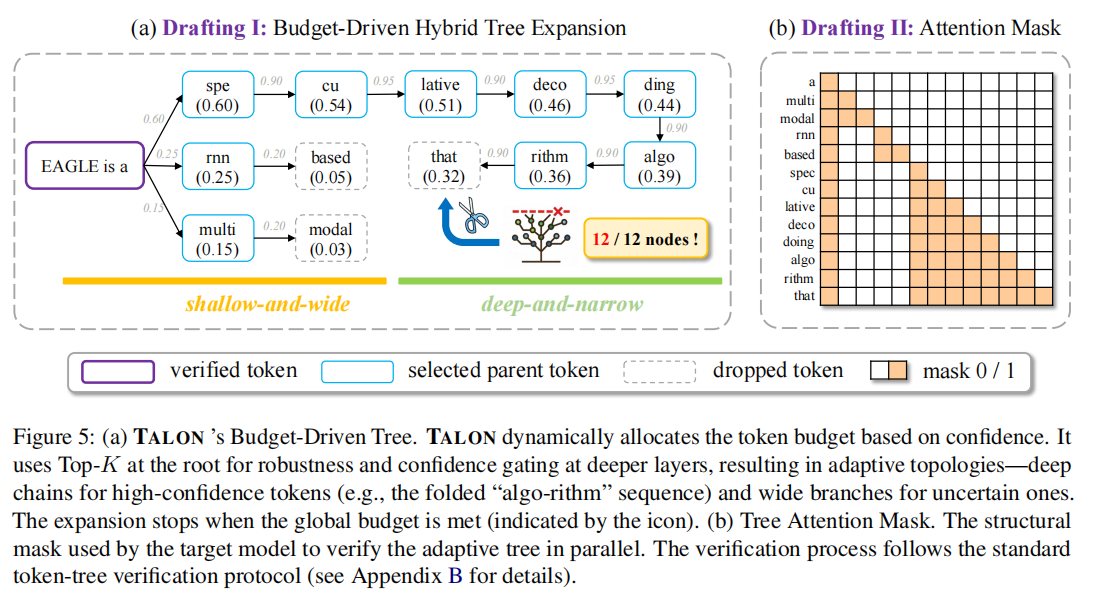
5.1 From Static Grids to Dynamic Budgets
为了克服静态拓扑与标记难度不匹配导致的效率低下,TALON 将约束从“形状”转变为“容量”。
-
全局标记预算 (Global Token Budget, $B$):定义为草稿树 $\mathcal{T}$ 中允许的最大节点数。
-
目标:迭代地“投资”此预算以生长草稿树。
-
确定性上下文:分配为深而窄的链。
-
不确定性分支:分配为浅而宽的层。
5.2 Hybrid Tree Expansion Strategy (混合树扩展策略)
TALON 逐层构建树,采用混合策略:在根节点(第 0 层)进行鲁棒初始化,随后在后续层()进行置信度门控扩展。
5.2.1 Confidence-Gated Expansion (置信度门控扩展)
对于深度 ,作者采用全局过滤机制,根据候选者的相对置信度进行门控。 设 为父节点集合,候选池 为所有子节点扩展的并集:
$$ \mathcal{C}l = \bigcup{v \in \mathcal{P}_{l-1}} \text{Expand}(v) $$
每个候选节点 被分配一个路径累计概率:
$$ s(c) = \prod_{t=1}^{l} p_d(x_t \mid x_{<t}) $$
为了识别当前层的“最优潜力”,作者首先找到锚点置信度 (anchor confidence) :
$$ s_{\text{anchor}} = \max_{c \in \mathcal{C}_l} s(c) $$
然后,作者仅保留置信度落在锚点动态裕度 范围内的候选者:
$$ \mathcal{C}_l’ = \left{, c \in \mathcal{C}l ;\middle|; s(c) \ge \alpha \cdot s{\text{anchor}} ,\right} $$
其中 是超参数(TALON 默认取 )。
- 预算尊重机制:如果 超过剩余预算 ,作者仅保留路径分数最高的 top 候选者。
- 直觉原理:
- 在确定性上下文中(如“The capital of France is…”),锚点 ,会施加严苛阈值,自动剪枝形成深层单链。
- 在高熵上下文中(如“Quantum computing can…”), 较低,阈值随之放松,允许更多样化的候选者进入下一层,形成浅宽结构以提高覆盖率。
5.2.2 Robust Tree Initialization (鲁棒树初始化)
虽然置信度门控在深层有效,但在根节点()直接应用会因为草稿模型过度自信(Over-confidence) 而损害鲁棒性。
- 过度自信陷阱:小草稿模型往往校准不准,可能在错误的分支上给出 的概率。如果此时使用相对门控,树会过早塌缩为单一的错误分支。
- 灾难性后果:根节点的失败会导致整个草稿序列被拒绝。
- 解决方案:在第一层采用标准的 Top-K 初始化。无论置信度分布如何,显式扩展 Top-K 个标记:
$$ \mathcal{C}_1 = \text{TopK}\left(p_d(x_1 \mid x_0), K\right) $$
这确保了在切换到预算高效的门控策略之前,在最关键的连接处覆盖了多样化的方向。
5.3 Evaluating TALON with Draft Efficiency (草稿效率评估)
为了量化 TALON 的成本效益,作者通过分解质量和成本因子来分析墙钟时间加速比(wall-time speedup)。
-
$N_v$:目标模型执行的正向传播总次数(验证步骤)。
-
$N_d$:草稿模型生成的总步数。
-
$L$:输出序列长度。
-
$\gamma$:草稿模型相对于目标模型的计算成本比例。
作者引入新指标 草稿效率 (Draft Efficiency, ):
$$ \eta = \frac{N_d}{N_v} $$
代表系统为了获得一次验证机会所投入的平均草稿步数。墙钟加速比 可以表示为平均接受标记数 和 的函数:
$$ \text{Speedup} \approx \frac{\mathbb{E}[A]}{1 + \gamma \cdot \eta} $$
理论解释 TALON 的优越性:
- 高熵上下文(难例):接受奖励 下降。EAGLE 等静态方法仍支付固定高昂成本 ,导致 骤降。TALON 通过及早停止减少投资(),补偿了低奖励。
- 低熵上下文(易例):静态方法将奖励 限制在深度 。TALON 允许树向深处无限延伸,显著增加 。由于 , 的增长远慢于 的增长,确保了总加速比 的持续提升。
4. Evaluation
4.1 Experimental Setup
-
基础模型 (Target Models):涵盖不同规模和架构,包括 Llama-3-8B-Instruct, Llama-2-7B/13B/70B-Chat, Vicuna-7B/13B, 以及 Qwen2-7B。
-
草稿模型 (Draft Models):采用 EAGLE 结构的轻量级回归头(EAGLE-style)。
-
数据集:
-
MT-Bench:通用多轮对话。
-
GSM8K:数学推理。
-
HumanEval:代码生成。
-
MBPP:入门级 Python 编程。
-
Spider:文本转 SQL。
-
ShareGPT:真实用户指令。
-
超参数设置:全局预算 ,门控阈值 ,根节点初始化 (对应 EAGLE-2 默认设置)。
4.2 Main Results (主要实验结果)
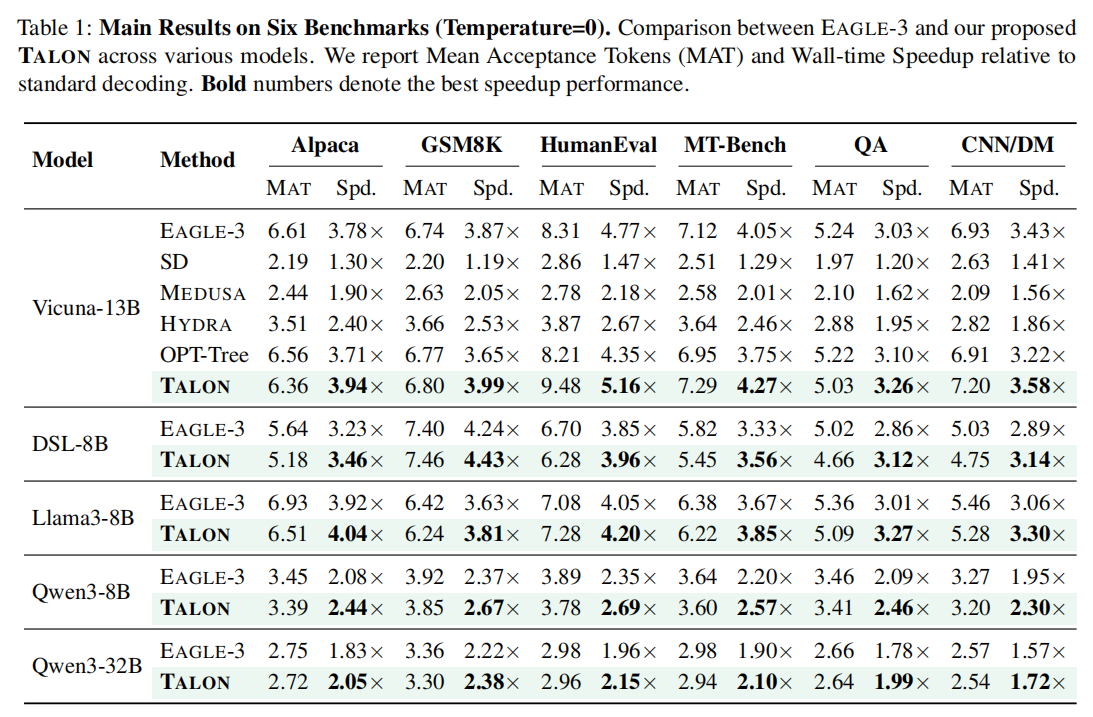
TALON 在所有测试场景中均表现出显著优势:
- 超越 SOTA:TALON 在所有模型上均超过了 EAGLE-3(尽管 EAGLE-3 宣称通过更复杂的离线策略优化了静态树结构)。
- 加速比峰值:在 Llama-3-8B 结合 GSM8K 数据集上,TALON 实现了 5.16× 的端到端加速,而 EAGLE-2 为 4.11×,EAGLE-3 为 4.35×。
- 各任务表现:
- 在 数学和代码任务(如 GSM8K, HumanEval)中,由于逻辑推导具有很强的确定性路径,TALON 生成了极深的树, 显著提高。
- 在 对话任务(MT-Bench)中,TALON 通过在不确定处变宽,提高了接受率的稳定性。
4.3 Evaluating TALON with Draft Efficiency (草稿效率分析)
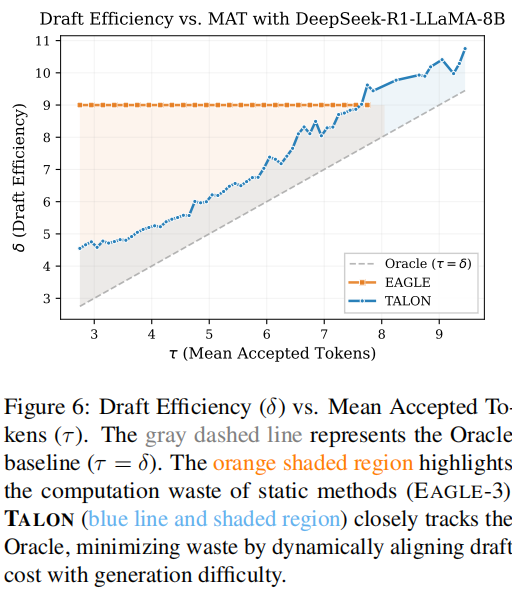
实验验证了 Section 5.3 的理论模型:
- 动态:观察到 TALON 的草稿效率 会根据任务难度自动调整。在 MT-Bench 上 较低(约 15-20),而在 GSM8K 上 会为了追求高奖励 而增加到 30 以上。
- 收益曲线:加速比 与 呈正相关,且 TALON 总是能找到比固定树更好的 平衡点。
4.4 Ablation Study (消融研究)
-
预算 的影响:随着预算 从 20 增加到 120,加速比呈现先快速上升后平缓的趋势。 被证明是性能与 GPU 显存限制之间的良好折中点。
-
阈值 的敏感性:
-
太小(如 0.001):树变得太宽,浪费资源在无效分支。
-
太大(如 0.5):树变得太窄,容易因草稿模型微小偏离而导致整条路径失败。
-
结论: 范围内性能稳定。
-
初始化策略:对比实验显示,去掉第一层的 Top-K 初始化会导致在某些任务上性能下降 10% 以上,验证了处理草稿模型过度自信的重要性。
5. Limitations
尽管 TALON 表现优异,但仍存在以下局限:
- 大 Batch Size 的可扩展性:目前主要针对 Batch Size = 1(延迟敏感型交互)进行了优化。在高吞吐量场景下,为每个请求维护不同的动态树结构会带来非平凡的 GPU 计算饱和及内存管理开销。
- 超参数泛化:虽然默认值 表现健壮,但在极端专业领域可能需要微调。开发根据接受历史实时自动调节 和 的机制是未来方向。
6. Conclusion
本文提出了 TALON,一个将投机解码从僵化的几何约束转向灵活的、预算驱动范式的训练免框架。通过结合鲁棒初始化与置信度门控的混合扩展策略,TALON 动态调整草稿树形状:在确定性上下文中进化为深窄链,在不确定分支中演化为浅宽结构。 在 5 个 LLM 和 6 个基准测试中的广泛评估证明,TALON 持续优于 EAGLE-3 等最先进方法,实现了高达 5.16× 的加速,为自适应推理优化提供了新的视角。