
Conference: ASPLOS'26
Github: https://github.com/mit-han-lab/fastrl
1. Motivation
强化学习(RL)已成为赋予大语言模型(LLMs)强大推理能力(如OpenAI-o1, DeepSeek-R1)的标准方法。然而,这种RL方法面临独特的效率挑战。通过分析自收集的轨迹和来自字节跳动(ByteDance)的生产环境轨迹,作者确定了推理RL过程中的关键特征:
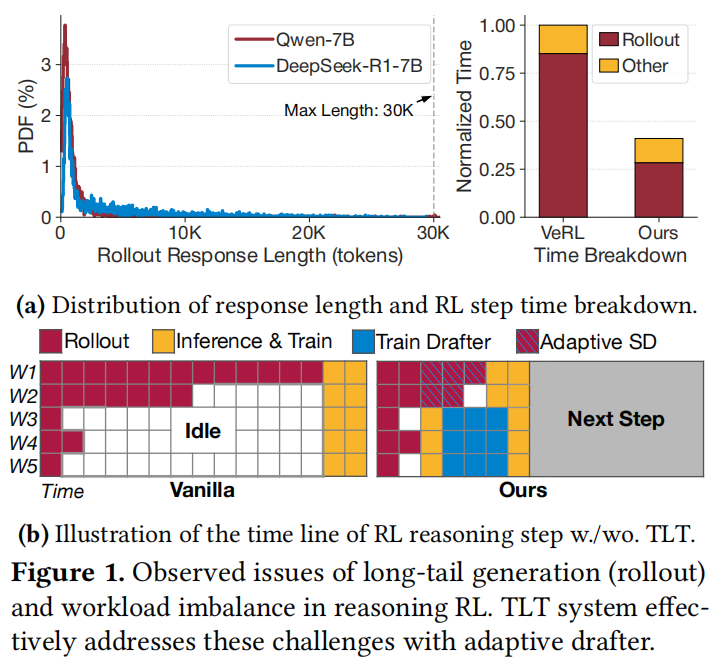
(Figure 1展示了推理RL中的长尾生成问题和工作负载不平衡)
- (1) 极不平衡的Rollout(采样)与训练时间 (Unbalanced Rollout and Training Time):
在RL过程中,最耗时的阶段是Rollout(模型生成大量候选回答)。这一阶段占据了总步长时间的绝大部分(约 85%),成为主要的瓶颈。 - (2) 持续的长尾分布 (Persistent Long-Tail Distribution):
Rollout响应长度呈现长尾分布是导致效率低下的主要原因。虽然大多数生成的序列相对较短,但一小部分序列会达到极长的长度(例如达到最大上下文限制)。这种长尾模式并非偶发,而是贯穿整个长期训练过程的持续模式。在大多数RL步骤中,少数响应达到最大配置长度,而绝大多数则短得多,导致显着的资源未充分利用(即GPU在等待最长序列完成时处于闲置状态)。 - (3)巨大的时间和资源需求 (Substantial Time and Resource Demands):
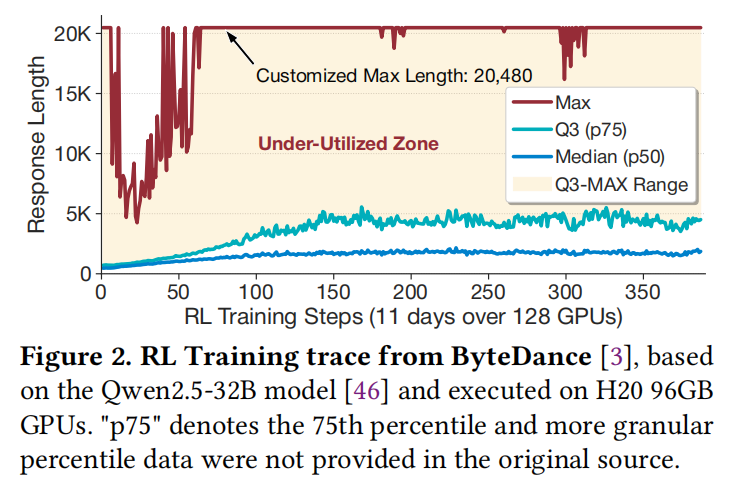
ByteDance的生产轨迹显示,使用128个GPU训练一个32B模型,仅完成385步就需要11天。单步训练平均耗时约40分钟,极度消耗资源。
为什么选择投机解码 (Why Speculative Decoding - SD)?
作者认为投机解码(SD)是非常适合解决此问题的方法。SD利用轻量级草稿模型(Draft Model)快速生成token序列,然后由目标模型并行验证。SD适合RL训练主要基于两个优点:
- 数学上的无损性 (Mathematically Lossless): 输出分布与目标模型的原始分布完全一致。这对RL至关重要,因为近似方法可能会改变策略优化轨迹。
- 对长尾效率高 (Efficient for Long-Tail): SD通过将过程从**内存受限(Memory-Bound)转变为计算受限(Compute-Bound)**来提高吞吐量。这对于RL Rollout的长尾阶段特别有效,因为此时有效批大小(Batch Size)通常很小,标准解码无法充分利用GPU计算能力。
在RL中应用SD的挑战 (Challenges in Reasoning RL):
现有的SD技术主要针对静态推理场景设计,应用于动态推理RL训练面临三大挑战:
- C1. 演进的目标模型 (Evolving Target Model): RL训练期间目标模型权重不断更新。固定的草稿模型会迅速变得“过时”(Stale),导致投机接受率下降,严重削弱SD效果。
- C2. 草稿模型训练成本 (Draft Model Training Costs): 高效的SD通常依赖专门的草稿模型(如EAGLE等),这需要额外的训练来与目标模型对齐,引入了额外的开销和复杂性。
- C3. 波动的批大小 (Fluctuating Batch Sizes): 现有SD通常针对小批次优化。然而,RL Rollout的特征是有效批大小动态剧烈波动(开始时很大,随着短响应完成迅速减小)。如果不进行管理,在大批次下性能可能会下降甚至发生显存溢出(OOM)。
2. Contribution
为了解决上述挑战,论文提出了 TLT,这是一个具有自适应投机解码的高效推理RL训练系统。
TLT的核心设计基于两个洞察:
- 利用Rollout的气泡 (Exploiting Rollout Bubbles): RL Rollout的长尾特性导致大量GPU资源逐渐空闲。这些释放的资源可以被重新用于草稿模型训练等任务,而无需额外成本。
- 非阻塞的草稿器训练 (Non-Blocking Drafter Training): 草稿模型训练可以与Rollout解耦。利用部分数据或已完成的数据进行异步训练,可以有效地与正在进行的Rollout重叠。
TLT包含两个协同组件:
- (1) 自适应草稿器 (Adaptive Drafter - §4): 采用轻量级草稿模型,通过Spot Trainer持续调整。Spot Trainer利用长尾Rollout期间的闲置GPU资源进行机会性、可抢占的更新,确保草稿器在不增加额外成本的情况下与不断演进的目标模型保持对齐。
- (2) 自适应Rollout引擎 (Adaptive Rollout Engine - §5): 维护一个内存高效的预捕获 CUDAGraphs 池,并利用 BEG-MAB 调优器 为每个输入批次自适应地选择合适的SD策略。
主要成果:
评估表明,TLT在端到端RL训练速度上比最先进的系统(如VeRL)快 1.7倍 以上,同时保持模型准确性(无损),并免费产生一个高质量的、适合未来部署的草稿模型。
3. Background
3.1 Reasoning and Reinforcement Learning
推理大模型与测试时扩展 (Reasoning LLMs & Test-Time Scaling):
OpenAI-o1和DeepSeek-R1等模型在复杂推理任务中表现出色,这得益于测试时扩展(Test-Time Scaling)。
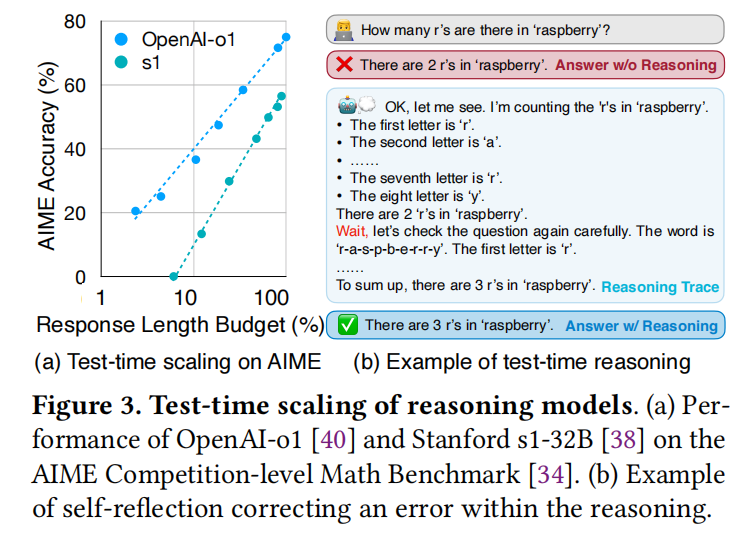
- 这些模型具有长思维链(Long Chain-of-Thought),在得出最终答案前生成大量中间步骤。
- 它们具备**自我反思(Self-Reflection)**能力,即在推理过程中评估、修正自己的错误(如图3(b)所示)。
- 这种延长的生成时间使模型能够探索更深更广的思维路径,但显著加剧了长尾问题。
GRPO算法 (Group Relative Policy Optimization):
论文主要关注DeepSeek使用的GRPO算法。单个GRPO训练步骤包含三个主要阶段(如图4所示):
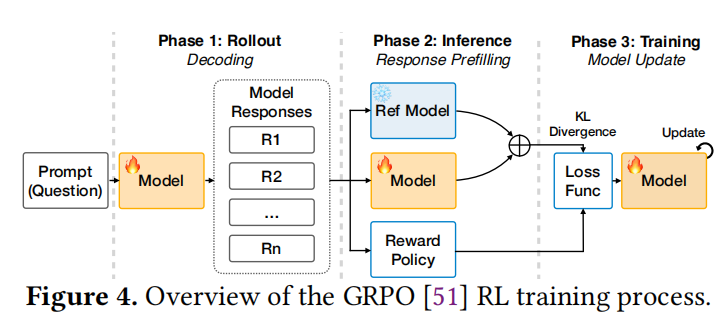
- Rollout阶段 (Rollout Stage): 目标模型针对每个提示(Prompt)生成多个候选响应。这是性能瓶颈所在,尤其是长尾分布导致资源浪费。
- 推理阶段 (Inference Stage):
- 生成的响应由目标模型和参考模型(Reference Model)处理,计算logits以得出KL散度惩罚,限制模型更新幅度。
- 同时,基于规则的策略(如答案正确性)计算奖励(Reward),而非依赖单独的价值模型(Critic),这减少了内存开销。
- 训练阶段 (Training Stage): 使用奖励和KL散度构建损失函数,并更新目标模型权重。
3.2 Speculative Decoding for Efficient Reasoning RL
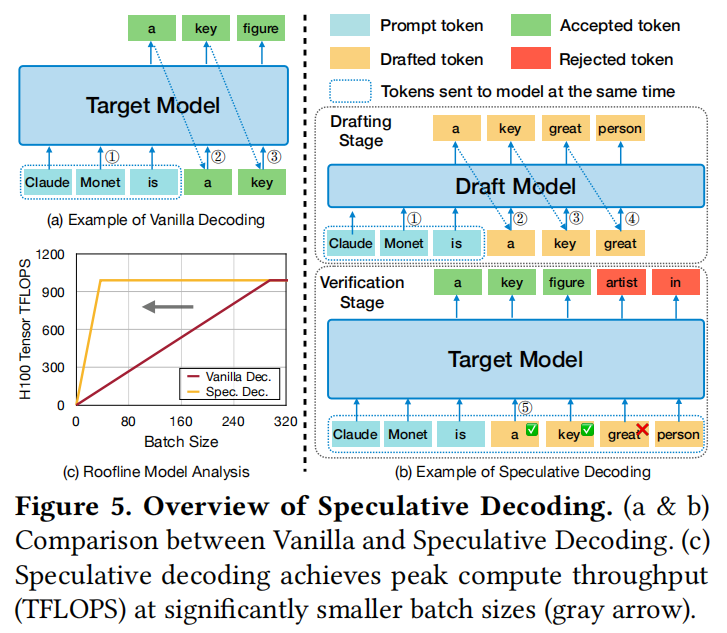
SD机制 (Mechanism):
如图5(b)所示,轻量级草稿模型快速生成候选token序列,然后由巨大的目标模型在一次前向传播中并行验证。系统接受匹配的token,直到第一个不匹配的token为止,并保留目标模型在该位置生成的正确token。
Roofline模型分析:
如图5(c)所示,SD通过将自回归生成从**内存受限(Memory-Bound)转变为计算受限(Compute-Bound)**来提高吞吐量。这对于RL Rollout的长尾阶段(有效Batch Size很小)尤为有效,能够更充分地利用GPU资源。
4. TLT Design
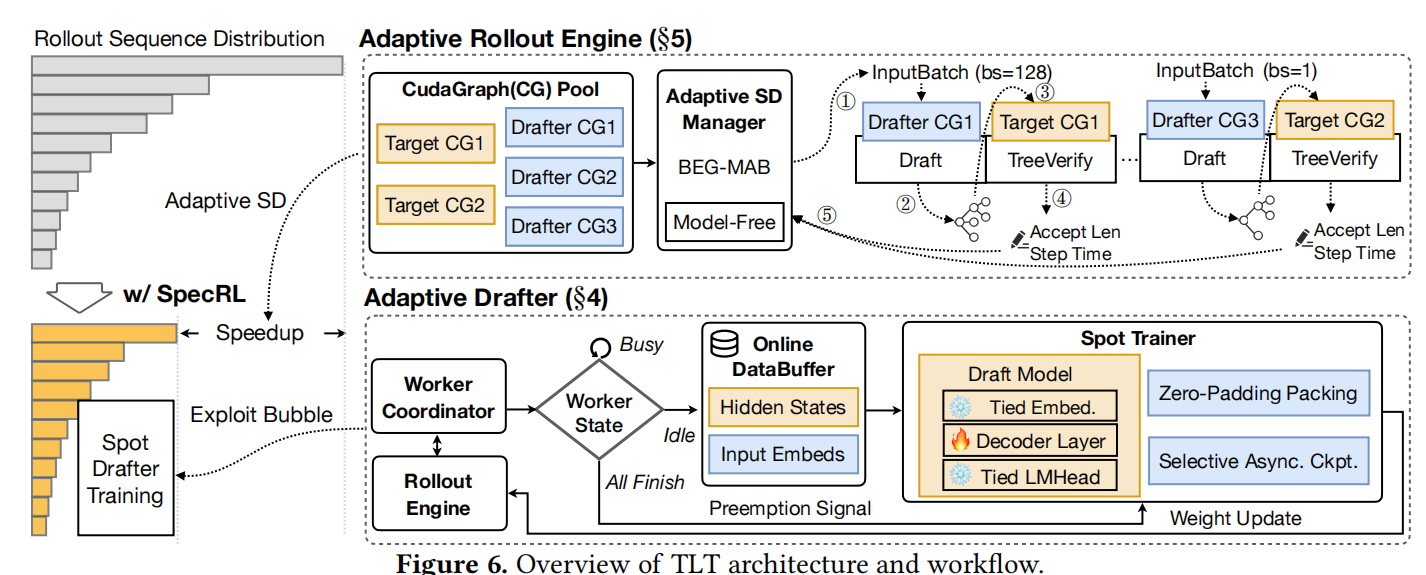 (Figure 6展示了TLT的整体架构和工作流)
(Figure 6展示了TLT的整体架构和工作流)
4.1 Overview
TLT的设计遵循四个原则:(a) 无损保证(数学上等价),(b) 无干扰(草稿训练不影响主RL任务),(c) 自动且简单,(d) 通用可扩展。
系统由两个紧密集成的组件组成:Adaptive Drafter(自适应草稿器) 和 Adaptive Rollout Engine(自适应Rollout引擎)。
4.2 Adaptive Drafter (自适应草稿器)
该组件负责在不干扰主要RL工作负载的情况下持续更新草稿模型,解决目标模型演进(C1)和训练成本(C2)问题。
4.2.1 Draft Model Architecture (草稿模型架构)
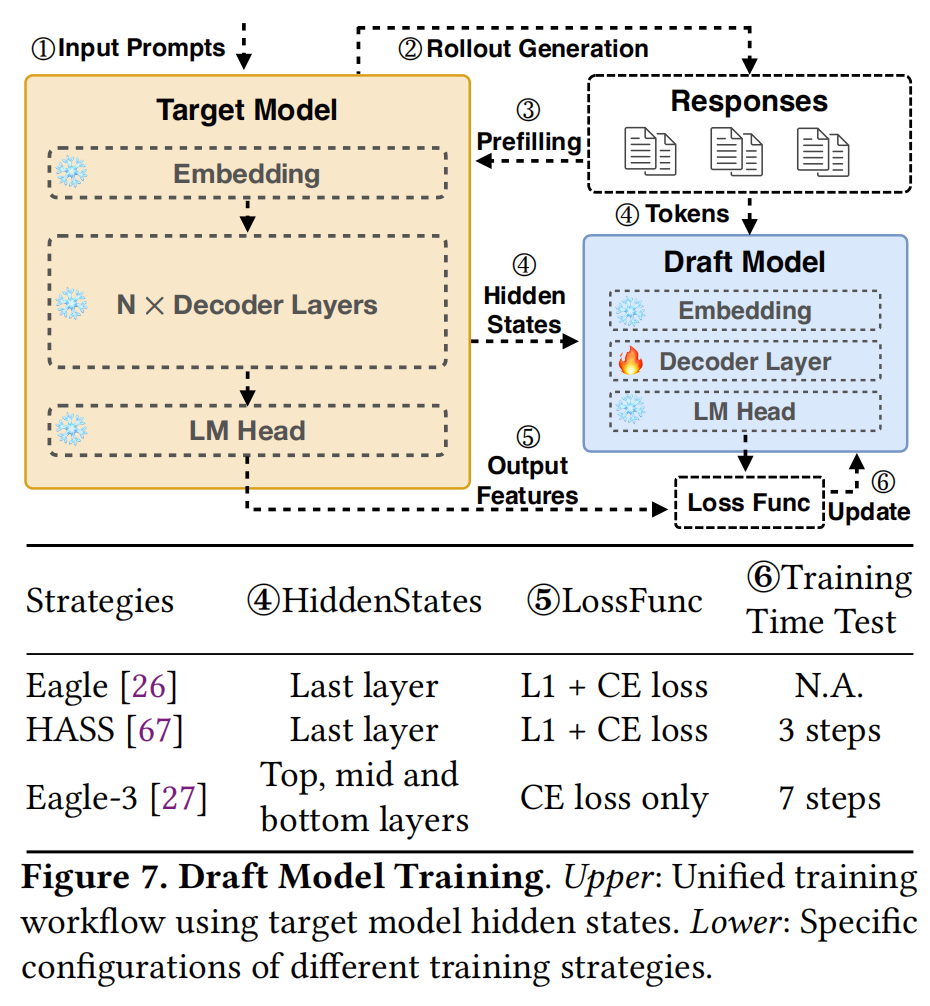
- 轻量化设计: TLT采用了类似EAGLE的单层解码器设计,而不是使用单独的小型LLM(如Qwen-0.5B)。
- 复用权重: 草稿器复用目标模型的原始Embedding层和LM Head层(在训练期间冻结)。
- 仅训练一层: 仅添加并训练一个Transformer解码器层。参数量极小(约为目标模型的1/Layer_Num),推理和训练开销极低。
- 性能优势: 实验表明,TLT的单层草稿器比Qwen2.5-0.5B快2.4倍。
- 统一训练框架: 支持多种训练策略(如EAGLE, HASS, EAGLE-3),默认使用EAGLE策略,因为它在低训练成本下提供了高接受长度。
4.2.2 Spot Trainer (机会性训练器)

Spot Trainer旨在利用长尾Rollout期间释放的GPU资源,以非阻塞方式对抗模型漂移。
-
Worker Coordinator (工作者协调器):
- 基于ZeroMQ实现的集中式协调器,监控所有Rollout Worker的状态。
- 状态管理: Worker在三种状态间循环:
BUSY(正在Rollout)、IDLE(推理完成,内存释放)、TRAINING(正在更新草稿器)。 - 资源调度: 当空闲Worker数量超过阈值时,协调器将其提升为训练模式。当Rollout整体完成需要进入下一步时,协调器立即发送抢占信号,优雅地停止草稿器训练,确保不干扰主RL流程。
-
Spot Training with DataBuffer (带数据缓冲的机会性训练):
- 问题: 仅仅依赖当前步骤早完成的响应(短响应)进行训练会导致分布不匹配,因为草稿器看不到长序列。
- 解决方案 (DataBuffer): 引入DataBuffer将训练与Rollout完成解耦。Buffer缓存推理阶段产生的隐藏状态(Hidden States)。
- One-Step Offset (一步偏移): 支持跨步持久化Buffer。训练数据混合了当前步骤的部分数据和上一步骤的完整长尾数据。这确保了草稿器能接触到长序列样本,尽管样本略有陈旧,但实验证明依然有效。
4.2.3 Efficiency Optimizations (效率优化)
- Selective Asynchronous Checkpointing (选择性异步检查点):
- 为了支持抢占式设计,必须频繁保存检查点。TLT采用了异步检查点技术,将保存过程卸载到后台线程。
- 优化: 仅保存可训练参数(过滤掉冻结的Embedding和LM Head),将检查点延迟降低了 9.2倍,最大限度减少了因抢占导致的工作丢失。
- Sequence Packing (序列打包):
- 训练数据长度差异巨大。TLT使用序列打包技术,将多个变长序列拼接成单一打包序列,利用Attention Mask保持独立性。
- 这消除了Padding带来的计算浪费,将训练吞吐量提高了 2.2倍。
4.3 Adaptive Rollout Engine (自适应Rollout引擎)
该组件解决RL中批大小动态波动(C3)的问题,通过动态调整SD策略来最大化吞吐量。
4.3.1 Adaptive SD Manager (自适应SD管理器)
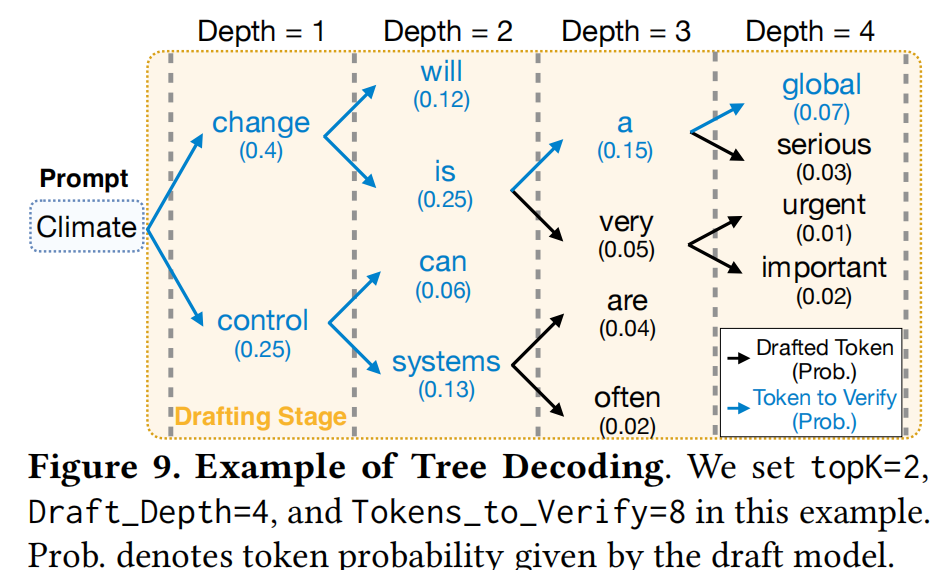
- Tree-based Drafting (基于树的草稿生成):
- 与线性生成不同,TLT构建候选Token树以并行探索多个路径。
- 参数包括:
topK(每个节点的分支数)、Draft_Depth(树深)、Tokens_to_Verify(验证Token数)。 - 这种方法显著增加了每次验证接受的Token数量。
- Adaptivity is Necessary (自适应的必要性):
- RL Rollout的批大小从很大(如128)迅速减小到很小(如1)。静态策略不仅效率低,且在大批次下可能导致显存溢出(OOM)。
- SD管理器根据当前剩余请求数动态调整参数,并采用弹性机制:仅在剩余请求低于阈值(默认32)时激活SD,以平衡计算开销。
4.3.2 Memory-Efficient CUDAGraph Capture (内存高效的CUDAGraph捕获)

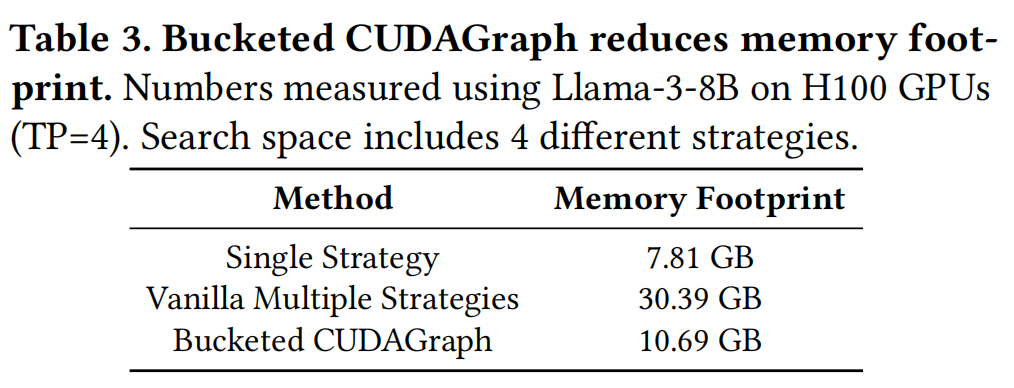
- 问题: CUDAGraph需要为每个批大小和策略组合捕获静态图。多策略会导致内存爆炸(例如从7.81GB增加到30.39GB),挤占KV Cache空间。
- Bucketed CUDAGraph Capture (分桶捕获优化):
- 分桶批大小 (Bucketed batch sizes): 将批大小分组到桶中(例如B1~B4),而非为每个具体大小捕获。
- 解耦捕获 (Disaggregated capture): 分别捕获目标模型和草稿模型的图。因为某些参数(如topK)只影响草稿器,避免了乘法级的内存增长。
- 合并捕获 (Merged captures): 合并共享参数配置的图。
- 结果: 将内存占用降低到 10.69 GB(降低2.8倍),仅比单一静态策略略高,使自适应切换成为可能。
4.3.3 Auto-Tune Algorithm (自动调优算法)

- Bucketed $\epsilon$-Greedy MAB (BEG-MAB):
- TLT设计了一种在线决策算法来自动选择最佳策略元组 $(Draft_Depth, topK, Verify_Tokens)$。
- 奖励定义: $r_s = \frac{\text{accepted_token_num}}{\text{step_latency}}$,即单位时间的生成效率。
- 算法逻辑:
- 将策略按验证Token数分组并映射到批大小桶。
- 探索 ($\epsilon$): 以概率 $\epsilon$ 随机选择策略。
- 利用 ($1-\epsilon$): 选择滑动窗口内中位数奖励最高的策略。
- 这种方法避免了手动调参,并能适应RL训练中的非平稳动态。
4.3.4 Model-free Drafter (无模型草稿器)
- 作为补充,TLT包含一个基于检索的非参数化草稿器。它利用同一Prompt生成的不同Rollout之间的相似性,构建n-gram检索库。
- 作为**Fallback(后备)**机制:在训练初期草稿模型尚未就绪时,或者预测学习型草稿器效率低时,动态激活该无模型草稿器,确保全程加速。
5. Evaluation
5.1 Experimental Setup
- 实现: 基于VeRL框架,使用Ray进行分布式执行,SGLang作为Rollout后端,PyTorch DCP进行异步检查点。
- 硬件: 8台 NVIDIA DGX H100 (共64 GPU) 和 DGX A100集群。
- 模型: Qwen2.5-7B, DeepSeek-R1-Distill-Qwen-7B, Qwen2.5-32B, Llama-3.3-70B。
- 数据集: Eurus-2-RL (数学和代码任务)。
- 基线: Open-R1, VeRL (SOTA开源框架), TLT-Base (仅无模型草稿器)。
5.2 End-to-End Evaluation (端到端评估)
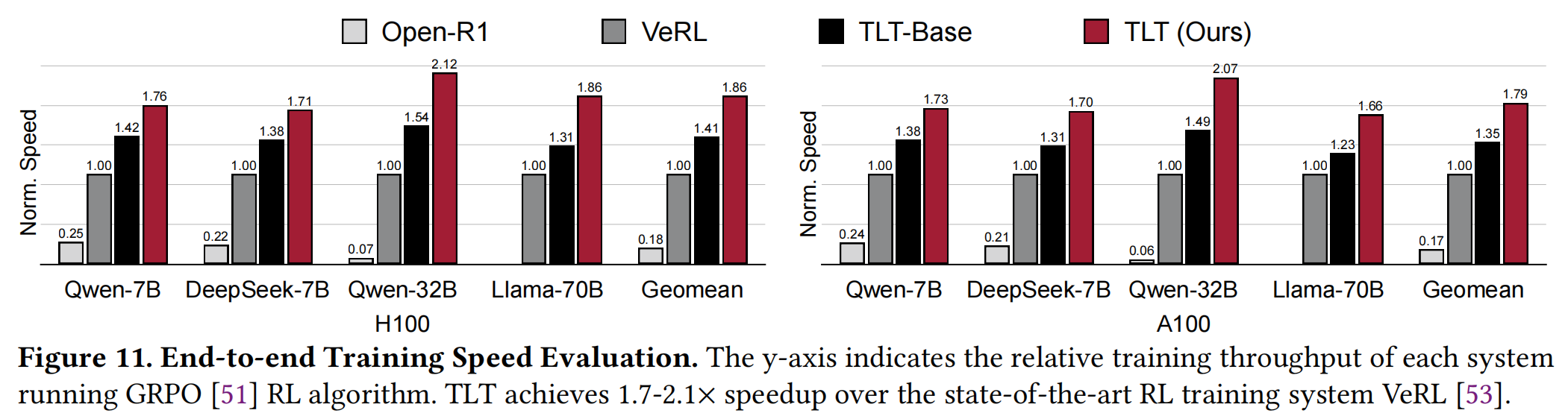 (Figure 11展示了端到端训练速度对比)
(Figure 11展示了端到端训练速度对比)
- 加速效果: 如图11所示,TLT在不同模型规模和硬件平台上均显著优于VeRL。在H100上,TLT实现了 1.7x - 2.1x 的端到端训练吞吐量加速。Open-R1由于GPU利用率低表现最差。
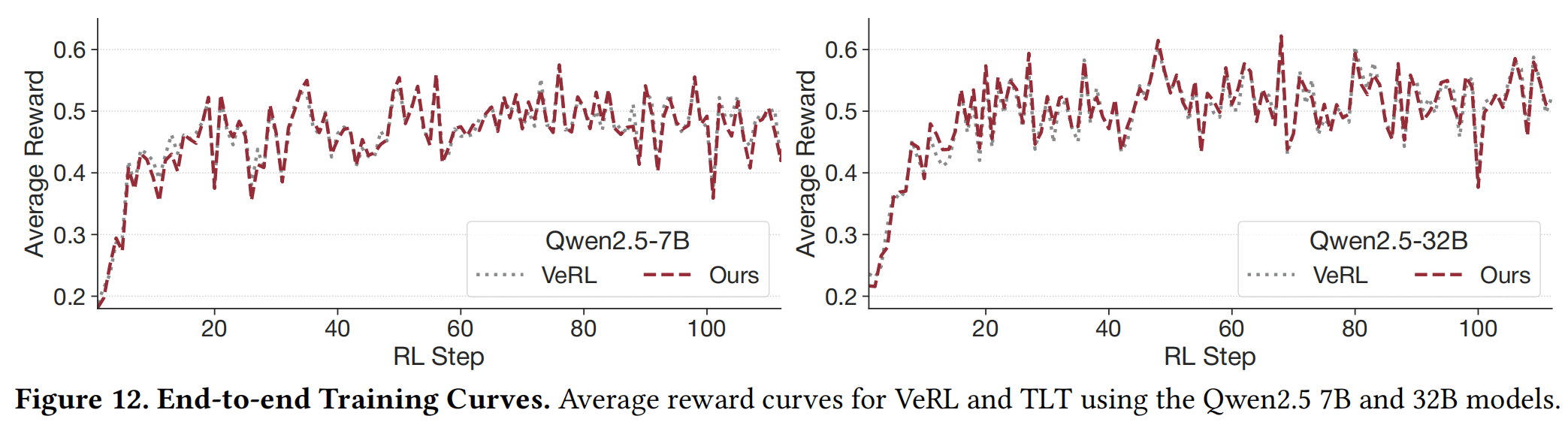
- 无损性验证: 图12展示了Qwen2.5-7B和32B的平均奖励曲线。TLT与VeRL的曲线几乎完全重合,证明了TLT的加速是无损的,未改变RL算法的学习动态。
5.3 Detailed Component Analysis (详细组件分析)
5.3.1 Evaluation of Adaptive SD (自适应SD评估)
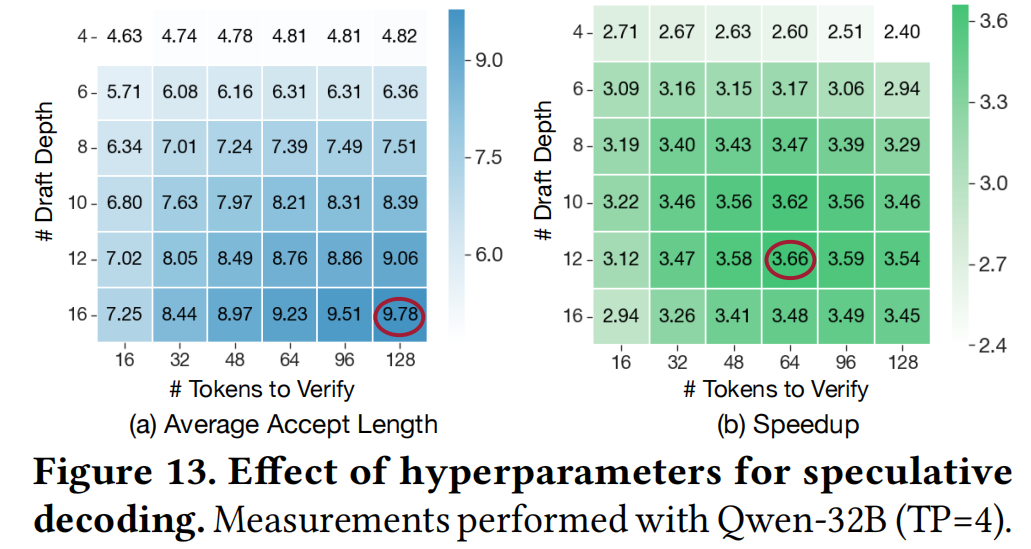
- 策略影响: 图13显示,单纯增加
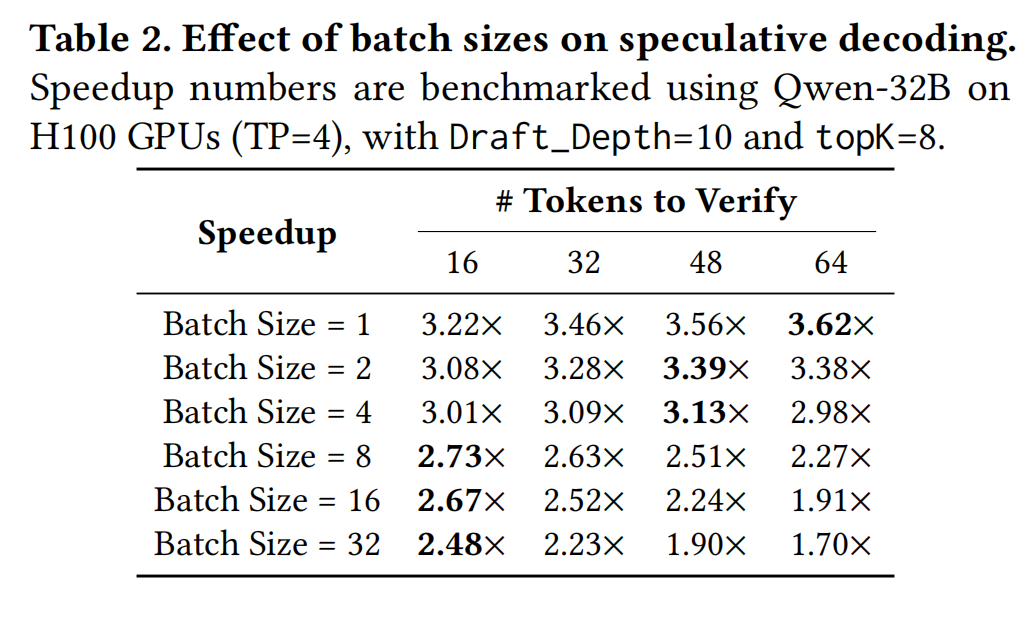
Draft_Depth并不总能带来加速(边际效益递减)。必须根据实际性能(加速比)而非中间指标(接受长度)来调优参数。 - 批大小敏感性: Table 2表明,最佳SD配置随批大小变化。例如,大批次时减少
Tokens_to_Verify效果更好。BEG-MAB选择器能有效识别这些配置。 - Case Study: 图14的分析显示,TLT仅在请求数降至阈值(32)以下时启用SD,并动态调整配置,相比无SD基线实现了 2.44x 的Rollout加速。
- 内存优化: Table 3显示,分桶CUDAGraph将内存占用从30.39GB降至 10.69GB,使得在有限显存下支持多种策略成为可能。
5.3.2 Evaluation of Spot Trainer (Spot Trainer评估)
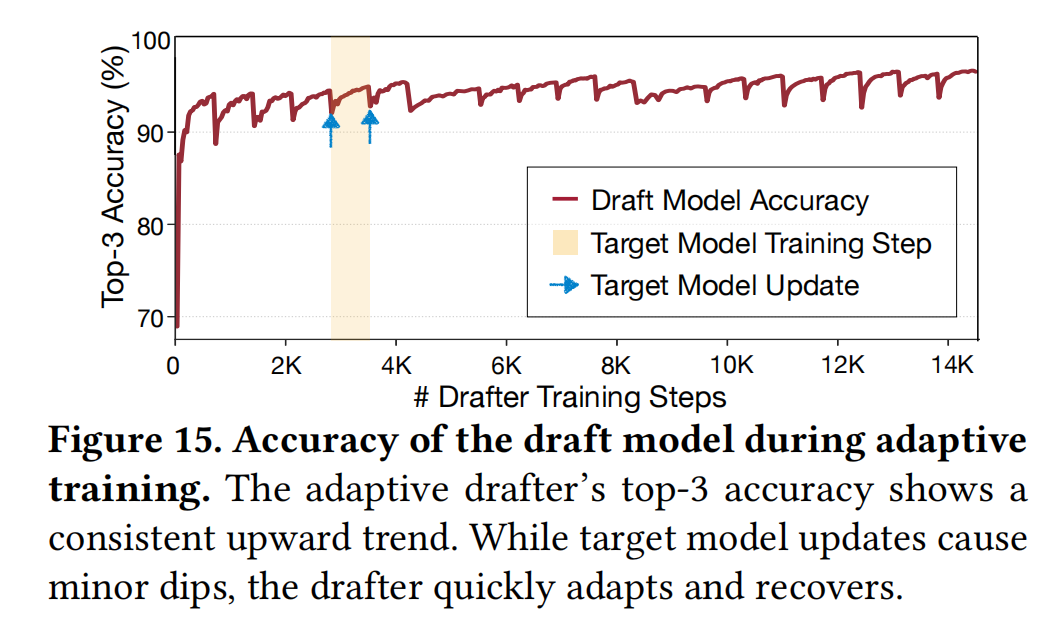
- 训练曲线: 图15展示了草稿器的Top-3准确率。在目标模型更新后(RL Step结束),草稿器准确率会暂时下降(分布偏移),但能在随后的几次Spot训练迭代中迅速恢复。
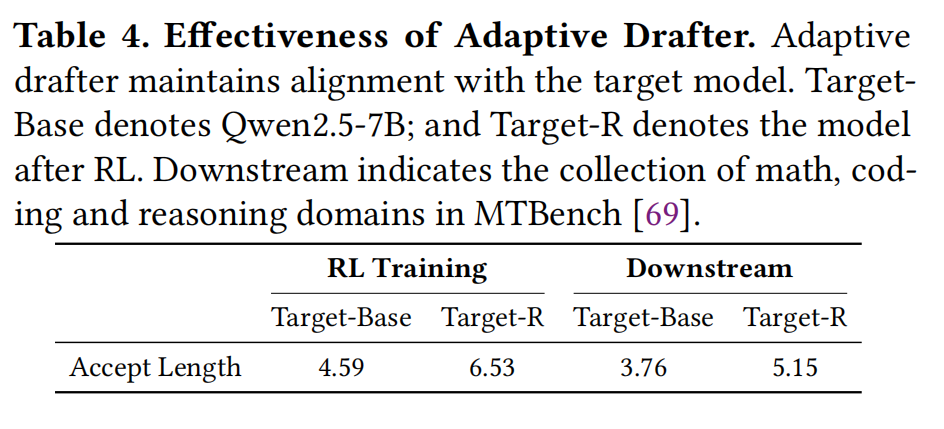
- 有效性: Table 4对比显示,自适应草稿器在RL训练后维持了更高的平均接受长度(Target-R: 6.53),而静态草稿器(Target-Base)仅为 4.59,证明了持续适应的重要性。
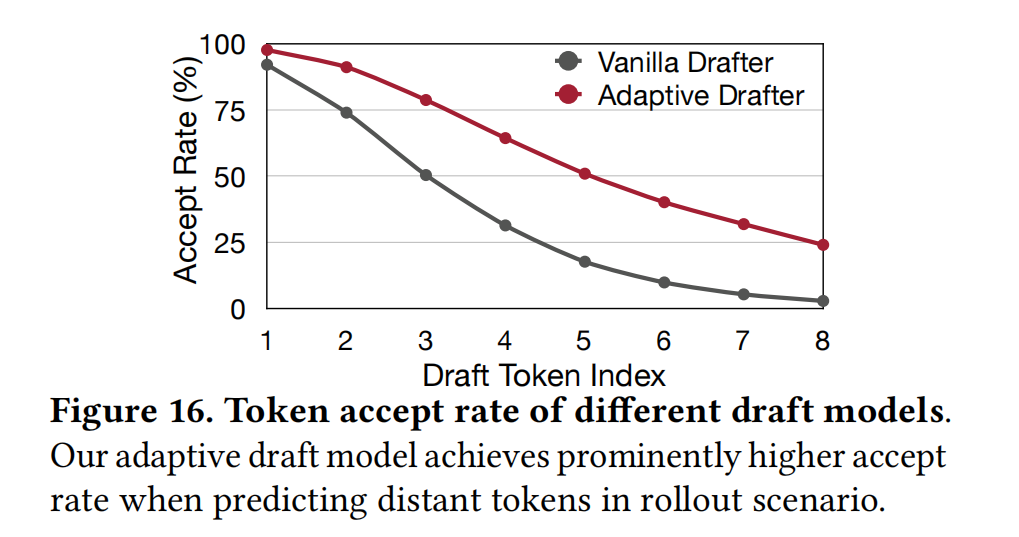
- 接受率: 图16显示,自适应草稿器在预测远端Token(distant tokens)时保持了更高的接受概率,而静态模型因误差累积表现不佳。
- 系统开销:
- 检查点: 选择性异步检查点将延迟降低了 9.2倍。
- 打包: 序列打包通过消除Padding计算,将训练吞吐量提升了 2.2倍。
- 总体开销: 阶段转换、SD切换和协调开销总计极低(<1%步长时间),远小于性能增益。
6. Discussion
更多应用场景 (More Application Scenarios):
虽然本文主要研究利用SD缓解RL训练中的长尾Rollout问题,但这开启了更广泛的应用前景:
- (1) 统一长响应 (Uniformly long responses): 当所有请求都很长(无长尾)时,KV Cache压力巨大导致批大小受限。此时工作负载天然处于SD的“甜蜜点”,适合利用SD加速。
- (2) 工具调用RL的多轮Rollout (Multi-turn rollouts with tool-calling RL): 在涉及工具调用的多轮RL中,部分请求在执行工具(不占用GPU计算),这减少了活跃解码请求数,再次创造了适合SD的小批次环境。
- (3) 在线服务与边缘部署 (Online serving and edge deployment): 固定目标模型后,通过TLT训练的草稿模型可直接部署。自适应SD在处理变动负载时依然高效。
我们可以打破RL同步吗?(Can We Break RL Synchronization?):
TLT旨在不修改On-Policy要求的前提下提升效率。
- 异步更新风险: 尝试在长解码阶段使用部分Rollout异步更新模型可能会引入Off-Policy漂移,偏置梯度估计,损害收敛性和模型质量。
- 未来方向: 虽然需要额外的算法修改来安全地适应异步模式,但在保留正确性的前提下允许有限的异步性是一个有趣的方向。即使在异步设置下,长尾问题依然存在,TLT的SD方法可以与之结合进一步加速。
TLT能否应用于其他RL算法?(Can TLT be applied to other RL algorithms?):
GRPO是推理RL的代表性算法。其他替代算法如 RLOO, DAPO, REINFORCE, 和 REINFORCE++ 共享相似的训练工作流,主要区别在于奖励公式和KL正则化。TLT的自适应草稿器和Spot Training设计与这些算法完全兼容,表明TLT可以加速广泛的RL方法。
7. Conclusion
总之,TLT 通过引入自适应草稿器 (Adaptive Drafter) 缓解了推理RL训练中关键的长尾瓶颈。其自适应性体现在两个方面:
- 训练期间: 通过Spot Trainer适应目标模型的更新。
- 推理期间: 通过Adaptive Rollout Engine适应变化的批大小。
结果表明,TLT在保持模型质量的同时实现了巨大的吞吐量提升。