
Conference: ICLR'26 submitted
1. Motivation
在设备端运行大语言模型(On-device LLMs)通过将数据保留在本地,显著增强了安全性,降低了数据泄露风险,同时支持实时智能和用户隐私保护。然而,其实际部署仍受到紧凑系统严苛的功耗与计算预算限制。随着对高级模型需求的增长——尤其是在离线或弱连接场景下——亟需在资源效率与隐私之间取得平衡的解决方案。当前这些模型已被广泛部署于智能手机、桌面设备与机器人,以支持自然语言交互、实时任务执行以及更强的用户隐私保障。
然而,现有方法几乎完全聚焦于软件或算法层面的优化——主要是低比特量化(low-bit quantization)——却缺乏对碎片化多样的移动 GPU 与新兴 NPU 的支持,也无法很好地跨不同硬件平台适配。大多数先前工作仅尝试解决该问题的一两个方面,尚无端到端的完整解决方案。尤其重要的是,它们常常忽略了软硬件联合设计(joint design of software and hardware)。其结果是,设备无法充分利用可用资源,且功耗问题很少被系统性地考虑。
大型多模态模型(LMMs)具有天然的模块化结构,通常由视觉编码器、嵌入层、投影器(projector)和语言解码器等组件组成,每个组件具有独特的计算特性。同时,不同硬件加速器也具备各自的优势:例如,NPU 在低比特张量运算(如 INT4/INT8),而 GPU 则擅长大规模并行浮点计算。然而,目前 LMMs 通常被当作单体(monolithic)工作负载部署在单一加速器上,无视这些架构差异。这种错配导致硬件利用率低下、端到端延迟增加、推理效率低下。若无法将不同组件动态卸载到最适合的计算单元,大量宝贵的硬件资源将长期闲置。实验(见第 4 节)表明,NPU 在编码器推理任务上始终优于其他单元,这凸显了动态、模块级卸载的重要性。
此外,尽管许多框架现已支持在边缘设备上部署 LLM,但它们大多源自服务器或传统 PC 架构,其中 CPU 与 GPU 拥有独立的内存空间。相比之下,现代边缘设备(包括手机)普遍采用统一内存架构(Unified Memory Architecture, UMA),CPU、GPU(或 NPU)共享同一物理 DRAM。这一根本差异使得许多传统设计在边缘设备上效率低下。在 UMA 下,NPU 与 GPU 缺乏 DMA 隔离,必须协调对共享内存的访问,这就要求全新的系统级优化和精心的重新设计以确保高效运行。
现有方法主要聚焦于软件层面技术(如低比特量化和模型缩放)以减少内存占用,却常常忽视了硬件层面的关键优化,包括:对移动 GPU/NPU 低比特操作的驱动支持、高效电源管理、以及跨加速器利用率的提升。此外,将整个模型简单地部署在单一加速器上通常会导致高延迟,使得这些框架无法充分利用边缘和小型设备上有限的计算资源。
2. Related Work
推理系统:在系统级优化方面,近期工作已开始利用现代 SoC 中的异构加速器。例如,llm.npu (Xu et al., 2025) 在提示词、张量和块级别重构 NPU 上的执行流程,将异常值和浮点(FP)操作卸载到 CPU/GPU,并通过子图重排来提高利用率——解决了移动 NPU 仅支持静态输入形状的限制。PowerInfer-2 (Xue et al., 2024) 提出了一种 NPU-CPU 协同框架,根据神经元激活密度卸载 LLM 推理,使手机能运行超出其内存容量的模型。
开源框架:MLC LLM (team, 2023a;b) 使用 TVM (Chen et al., 2018) 在移动和边缘设备上原生部署 LLM。然而,TVM 沉重的资源需求使其在小型平台上的常规设备端推理中不切实际,且在功耗和内存效率方面表现不佳。llama.cpp (Gerganov, 2023a) 是 Georgi Gerganov 使用 C++ 开发的轻量级、可移植的 LLM 推理框架。它支持多种后端,包括 Vulkan、OpenCL 和 CUDA,但在许多移动和边缘 GPU 上效率不佳。作者的实验表明,在特定平台上,它通常默认回退到 CPU 卸载,甚至在 GPU 上运行更慢,限制了性能提升(见表 1)。许多现有推理框架(如 LlamaEdge (LlamaEdge, 2024) 和 Ollama Gross (2023))都以 llama.cpp 作为后端。
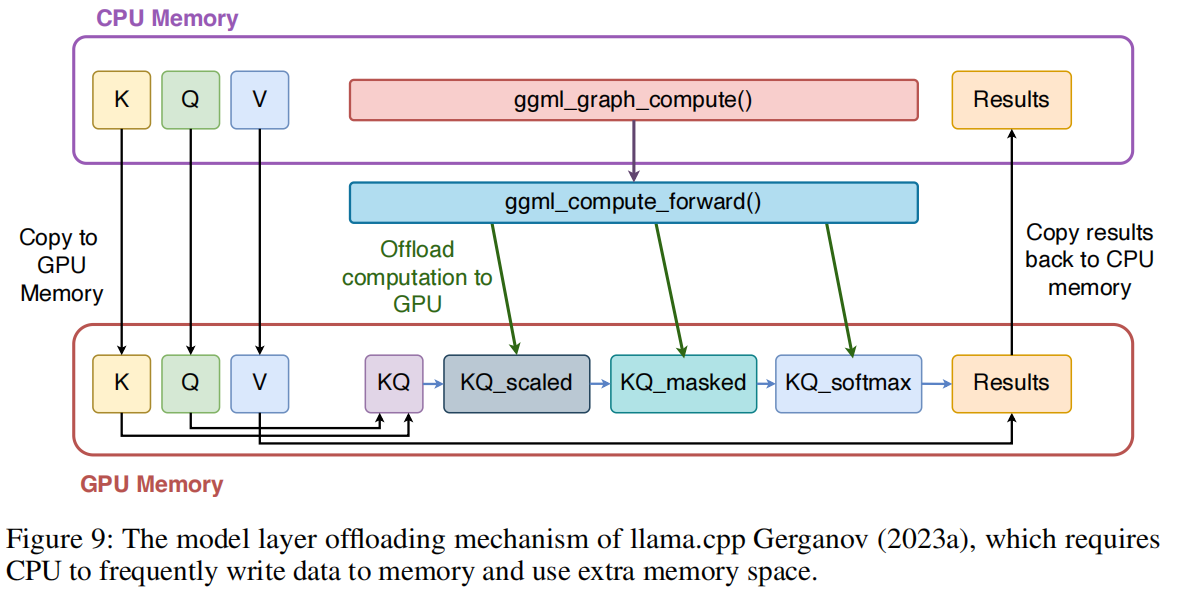
llama.cpp 的低效性:尽管 llama.cpp 引入了层卸载机制,但其工作负载分布在小型设备上(尤其是在现代统一内存平台上)效率低下。虽然它允许在 CPU 和 GPU 之间分配计算,但 GPU 执行仍依赖 CPU 通过缓冲区控制数据传输,从而在推理过程中增加了内存开销。附录中的图 9 展示了这种卸载工作流。当 GPU 可用时,张量可被赋予 GGML_BACKEND_GPU 标志,使 ggml_compute_forward() 能将计算卸载到 GPU。此过程涉及将关键张量从 CPU 内存传输到 GPU,而 CPU 必须持续向缓冲区写入数据并维护独立的内存分配,导致额外开销。这类框架虽能实现边缘设备上的 LLM 部署,但其设计沿用了服务器端 CPU/GPU 内存分离的架构,与现代边缘设备的统一内存架构(CPUs, GPUs, and NPUs share the same DRAM)不兼容。
3. Contribution
为克服上述挑战,本文提出 NANOMIND——首个完全在设备端运行的推理框架,它将大型多模态模型(LMMs)拆分为可独立执行的模块化“砖块”(vision, language, audio, etc.),并动态地将每个模块分配到其最优计算单元(GPU、NPU 或 CPU)。该框架基于紧密集成的软硬件协同设计(hardware–software co-design),作者通过开发一个小型电池供电设备(如图 10 所示)来验证 NANOMIND。借助该定制硬件,作者的系统性能超越了在现有商用现成平台上运行的主流框架。
作者还设计了一种事件驱动的按需级联推理管道(event-driven On-Demand Cascade Inference Pipeline)。该管道仅保留并传递到下一阶段所需的最小输出(如文本字符串或嵌入向量),从而形成一种轻量级的“多米诺骨牌式”执行链。
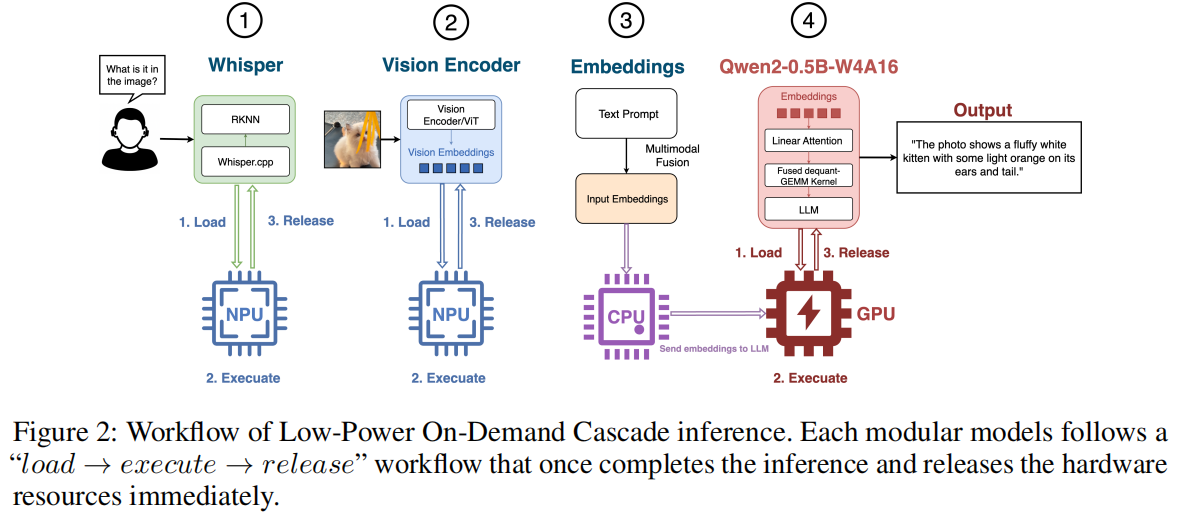
如图 3 和图 2 所示,作者的框架能在资源受限的硬件上高效执行视觉和语音推理。为实现这一目标,作者设计了定制硬件,实施了系统级优化,并为低端 SoC 的内置 GPU 和 NPU 开发了驱动程序和计算内核。作者的主要贡献总结如下:
-
面向模块化 VLM 的跨加速器调度(Cross-accelerator scheduling for modular VLMs):作者将模型分解为视觉、融合和解码模块,并在统一内存架构(UMA)下将每个模块调度到最适合的加速器上,从而提高硬件利用率并降低端到端延迟。
-
定制化的软硬件协同设计(Custom Hardware–Software Co-Design):在硬件方面,作者采用商用 RK3566 SoC(集成 GPU 和 NPU),通过四个并行 LPDDR4x 模块最大化内存带宽,并增加了专用电源管理单元(PMU)用于实时能耗监控。在软件方面,作者实现了针对硬件定制的 2-bit、4-bit 和 8-bit GEMM 内核,以及一个卸载调度器和驱动程序,以加速 GPU 和 NPU 上的量化张量运算。
-
动态工作负载卸载(Dynamic workload Offloading):一个轻量级的环形缓冲区(ring buffer)和缓冲区管理器实现了共享内存中的零拷贝(zero-copy)令牌交换。作者的层感知卸载器(layer-aware offloader)会根据电池电量、内存使用情况和延迟需求做出逐层决策,并绕过 CPU 进行缓冲区写入。
-
电池感知的执行模式(Battery-aware execution modes):轻量级策略能根据功耗约束自适应地调整模块部署位置和内存时钟,以延长运行时间,同时保持响应能力。
通过这些措施,一个微型设备能够在严格的硬件资源限制下,高效运行 LLMs 和 LMMs(如 LLaVA (Liu et al., 2023b;a)、Qwen-VL 系列 (Bai et al., 2023; Wang et al., 2024b)),并根据功耗和内存使用情况,直接将工作负载卸载到设备上的 GPU 或 NPU,从而绕过 CPU 的处理时间。这种方法显著提升了推理性能并大幅降低了功耗。作者的工作为在资源受限环境中部署 LLM 奠定了基础,推动了响应迅速、能效高且智能系统的开发,并为在小型设备上实现 LMM 的普及化开辟了道路,改变了作者在日常场景中与 AI 的交互方式。
3. Method
3.1 MODEL
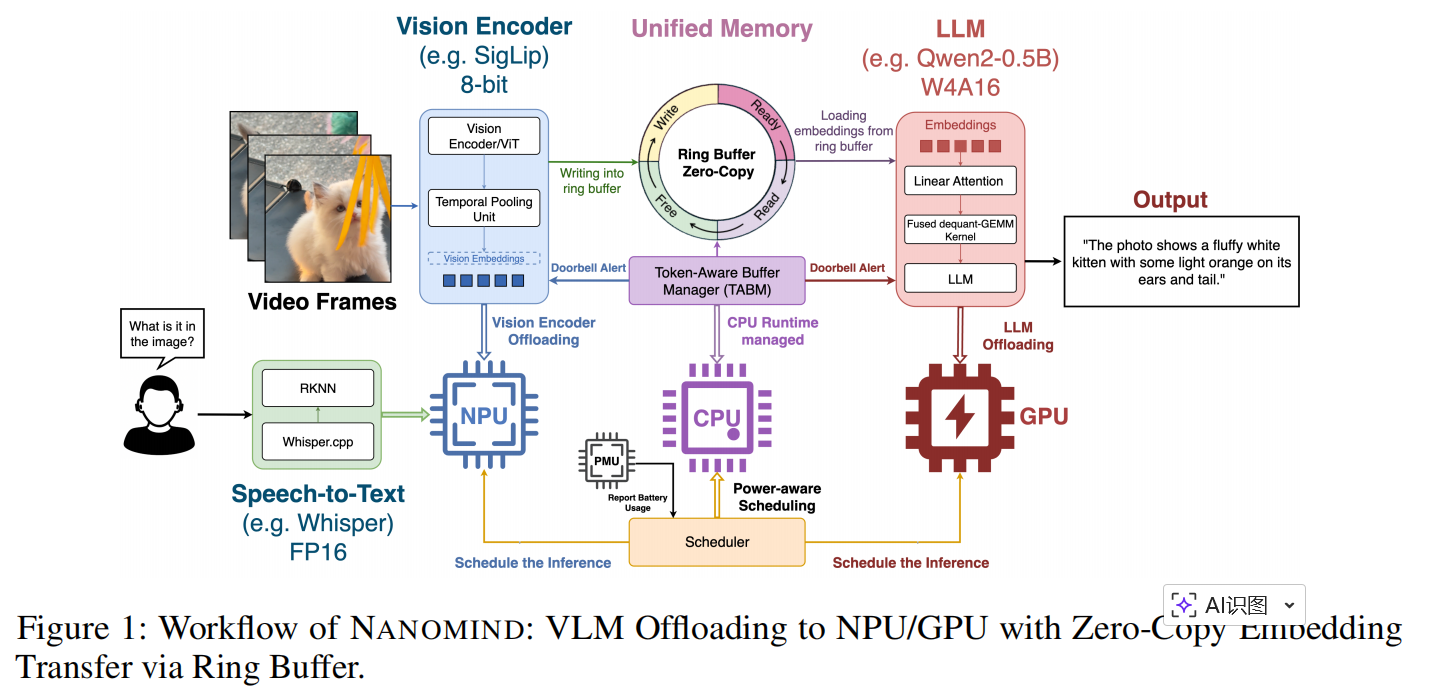
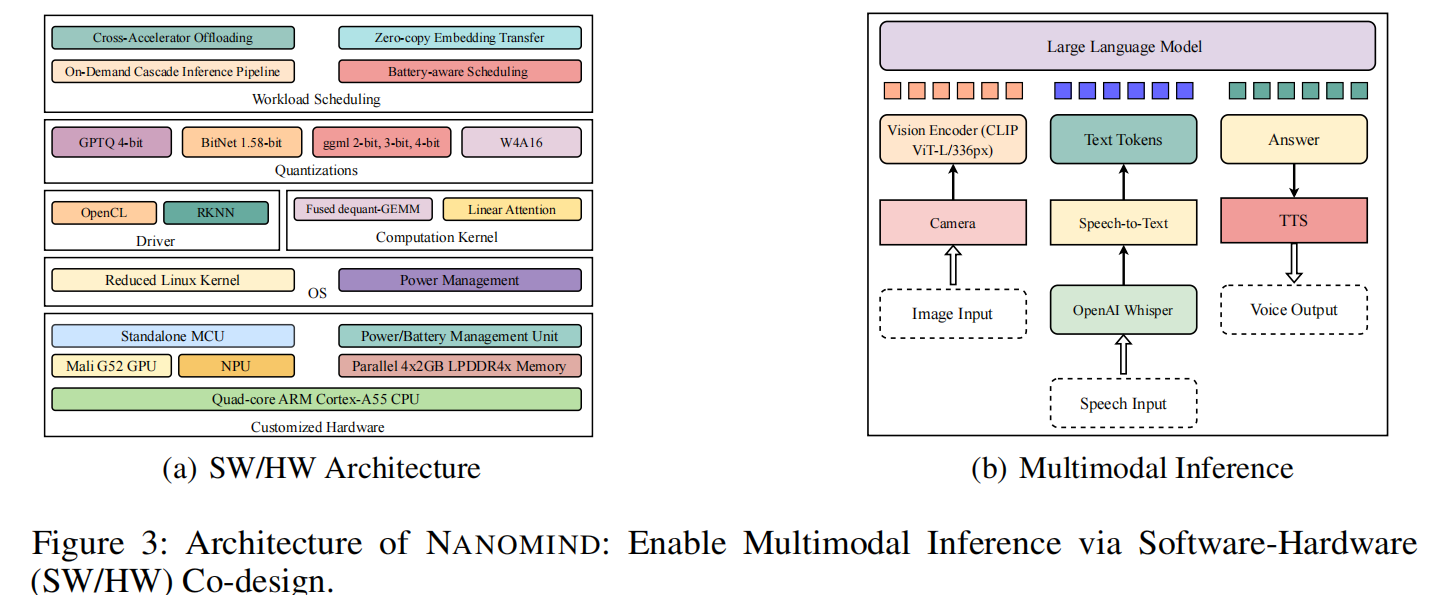
作者从模型分解(model decomposition)开始。由于 LMMs 具有天然的模块化特性,作者将各组件配置为可在不同加速器上独立运行(如图 1 和图 3 所示)。作者对多个模型进行了分解和转换,以实现高效的设备端推理:
- 语音转文本(Speech-to-text):由独立的
Whisper-base模型(Radford et al., 2023)处理,该模型通过Whisper.cpp(Gerganov, 2023b)实现。 - 文本转语音(Text-to-speech):由
Piper(Rhasspy, 2025)提供,这是一个运行在 CPU 上的轻量级 C++ 程序,独立于 VLM。 - 视觉模块:作者从 VLMs(如
LLaVA-OneVision-Qwen2-0.5B(Liu et al., 2024a) 和Qwen2-VL(Bai et al., 2023; Wang et al., 2024b))中提取视觉编码器。这些模型均采用SigLip(Zhai et al., 2023)作为其视觉编码器。 - 模型转换:
SigLip编码器可使用 Rockchip 官方工具包(Linux, 2025)转换为RKNN格式,从而在 NPU 上高效部署。根据LLaVA-OneVision架构,作者从 Hugging Face(Li et al., 2024; HF, 2025)获取了 safetensors 格式的原始权重,并提取了视觉编码器及其投影器、多模态嵌入层和Qwen-2.0-0.5B基础模型。
3.2 SOFTWARE–HARDWARE COORDINATION
在此,作者详细描述使 LMM 模块化组件得以适配的系统级优化,重点介绍在 NPU 和 GPU 加速器上的推理后端、混合量化、用于零拷贝数据传输的令牌感知缓冲区管理,以及能效策略。尽管该部署策略是为作者的定制 SoC 设计的,但该框架具有灵活性,可应用于其他移动 SoC,并采用不同的卸载策略。
NPU
大多数移动 NPU 仅支持静态计算图,这意味着任何输入形状的改变都需要重新编译固件——这对于资源受限的设备是不切实际的。为解决此限制(如 llm.npu (Xu et al., 2025) 所强调的),作者将视觉编码器卸载到 NPU,并对所有图像进行预处理(压缩和调整为固定分辨率),以确保推理过程中输入形状的一致性。Rockchip 的 NPU 驱动(RKNN)(Linux, 2025)为运行 CLIP(Radford et al., 2021)、SigLip(Zhai et al., 2023)和 Whisper.cpp 等模型提供了原生支持,其速度优于开源实现。
作者将 SigLip 部署在 SoC 的 NPU 而非 GPU 上,主要出于性能考虑:官方 RKNN 驱动提供了更高效的执行环境,使得视觉编码器在 NPU 上的速度大幅提升。相比之下,将 LLM 映射到 NPU 并不实际,因其静态形状限制——提示词长度是动态变化的,任何输入形状的改变都需要重新编译模型。虽然可以通过将输入填充到固定的最长上下文长度来规避此问题,但这会导致严重的效率低下,浪费大量计算周期和内存带宽。除了官方 SDK,社区资源(如技术博客和论坛)在 RKNN 转换和算子映射优化方面也起到了关键作用,帮助作者最大化 NPU 效率。
GPU
作者的推理框架基于 llama.cpp,保留了 ggml(GGUF)模型格式,同时通过定制后端对其进行扩展,以支持异构边缘加速器。使用 GGUF 作为统一格式,使 NANOMIND 能够利用广泛的开源量化模型。
为了进一步提高在资源受限设备上的效率,作者集成了基于 OpenCL 的 GPU 内核,并对其进行了增强,支持线性注意力(linear attention)和融合反量化-GEMM(fused dequant-GEMM)操作,适用于 W4A16 量化(4-bit 权重,FP16 激活)。
- 线性注意力:为高效处理序列,作者将标准的二次方注意力(quadratic attention)替换为线性注意力。这种内核化、流式变体维护了过去键和值的运行摘要,随着新令牌的到来进行更新,并通过单次矩阵-向量乘法计算输出,从而避免了代价高昂的 $T \times T$ 评分矩阵($T$ 为序列长度)。
- 融合反量化-GEMM 内核:作者实现了一个融合的
dequant-GEMMOpenCL 内核,该内核在 GEMM 循环内在寄存器中直接解包并重缩放 int4 权重,随后立即进行 FP16 FMA(乘加)运算。这种融合消除了中间缓冲区和内存传递,将每个字节都转化为有用的 MAC(乘加运算),这对缺乏 INT8 张量核心的移动 GPU 至关重要。 - 内核优化细节:该内核使用分块向量加载(tiled vector loads),将缩放表(scale tables)存储在常量内存或 LDS(Local Data Share)中,并配备一个可融合偏置和激活函数的尾声(epilogue),同时使用 FP16/FP32 累加器以保证数值稳定性。这些优化共同减少了内存流量和延迟,同时保持了模型精度。
Model compression
模型压缩对于设备端 LLM 推理至关重要,因其受到硬件约束。NANOMIND 支持 GPU 和 NPU 的多种比特量化方案,包括 4-bit(GPTQ 4-bit (Frantar et al., 2022))、1-bit(BitNet (Ma et al., 2024; Wang et al., 2024a))以及 ggml(GGUF)的 2-bit/3-bit/4-bit (Gerganov, 2023a)。
通过将 LMMs 分解为模块化组件,作者可以应用混合量化(hybrid quantization)——对视觉编码器(ViT)和基础模型(LLM)使用不同的量化策略。在作者的设置中:
- SigLip 视觉编码器被部署在 NPU 上,采用 RKNN 格式,精度为 FP16 或 8-bit。
- GGUF 量化后的 LLMs在 GPU 上运行,采用 4-bit(W4A16)或更低比特(2/3-bit)量化。
这种策略背后的原因是:视觉编码器的高精度能显著提升图像理解能力,而4-bit 的 LLM 对于可穿戴设备和边缘设备已足够,因为这些场景下的复杂推理任务相对较少。近期研究(Li et al., 2025)也证实,4-bit 量化在内存效率和精度之间提供了最佳平衡。
由于移动 GPU 通常缺乏快速的 INT8 张量核心,作者采用仅权重量化(weight-only quantization,即 INT8/INT4 权重 + FP16 激活),并配合融合的 dequant-GEMM OpenCL 内核——在寄存器中解包和重缩放,然后相乘。应避免单独的反量化步骤,以减少内存流量并保持计算流水线的饱和。
Token-Aware Buffer Management
为实现跨加速器的高效令牌流(token flow),NANOMIND 引入了 **Token-Aware Buffer Manager **(TABM)。这是一个轻量级的 CPU 运行时模块,也是动态工作负载卸载的核心(见图 3)。
TABM 在统一 DRAM 中管理一个共享环形缓冲池(shared ring buffer pool),并直接在 NPU(生产者)和 GPU(消费者)之间流式传输令牌,实现了真正的零拷贝传输(true zero-copy transfer)。该设计消除了冗余的内存移动,减少了 CPU 开销,降低了延迟,并维持了高吞吐量的令牌管道。
TABM 通过一个简单的状态机跟踪缓冲区状态(FREE, ALLOCATED_FOR_WRITE, READY_TO_READ, ALLOCATED_FOR_READ),并使用轻量级同步机制。这不仅平滑了生产者与消费者之间的速率不匹配问题,还为更高级别的控制提供了调度信号。
Power-efficiency Strategy
NANOMIND 采用一种由板载电源管理单元(PMU)实时数据驱动的动态三态电源管理策略。通过监控设备的电池电量(B),该策略智能地在性能与续航之间进行权衡:
- (i) 无约束性能状态(Unconstrained Performance State, B > Thigh):系统以全容量运行,积极地将工作负载并行卸载到加速器。
- (ii) 比例节流状态(Proportional Throttling State, Tlow < B ≤ Thigh):系统进入优雅降级状态,使用缩放因子 $\alpha = (B - T_{low}) / (T_{high} - T_{low})$ 对摄像头帧率和内存读写速率进行线性插值。
- (iii) 关键节能状态(Critical Conservation State, B ≤ Tlow):为确保关键功能,系统激活 On-Demand Cascade Inference 模式,暂停并行执行,转而采用功耗优化的串行工作流。
Low-Power On-Demand Cascade Inference
在电池电量极低的情况下,系统会切换到一种名为 “On-Demand Cascade Inference” 的事件触发模式,旨在最小化峰值内存使用和功耗。在此“一次性推理”模式下,系统保持在超低功耗待机状态,仅有一个 CPU 核心等待摄像头或麦克风事件。
例如,摄像头仅捕获单帧(禁用时间池化),所有加速器每次触发只运行一次。当被唤醒词等事件触发时,系统运行一个顺序推理管道。每个模块(Whisper, ViT, 或 LLM)遵循 “load → execute → release” 生命周期:加载后执行任务,然后立即释放,仅将最小输出(如文本或嵌入)传递给下一阶段。这形成了一个轻量级的多米诺骨牌式级联,显著减少了内存和功耗,避免了高内存占用和 CPU 空等。
Embeddings Zero-Copy Transfer in Unified Memory
为支持高效的令牌流和跨加速器的零拷贝传输,NANOMIND 再次强调了 **Token-Aware Buffer Manager **(TABM) 的核心作用。TABM 在统一 DRAM 中管理一个共享环形缓冲池,协调 NPU(生产者)和 GPU(消费者)之间的令牌传输,无需冗余内存移动或阻塞。
NPU 编码器将嵌入(embeddings)直接写入缓冲区槽位,GPU 可立即将其绑定为 LLM 输入,从而避免了拷贝。此设计降低了 CPU 负载,减少了延迟,平滑了生产者-消费者速率差异,并维持了高吞吐量的令牌管道。
3.3 HARDWARE DESIGN
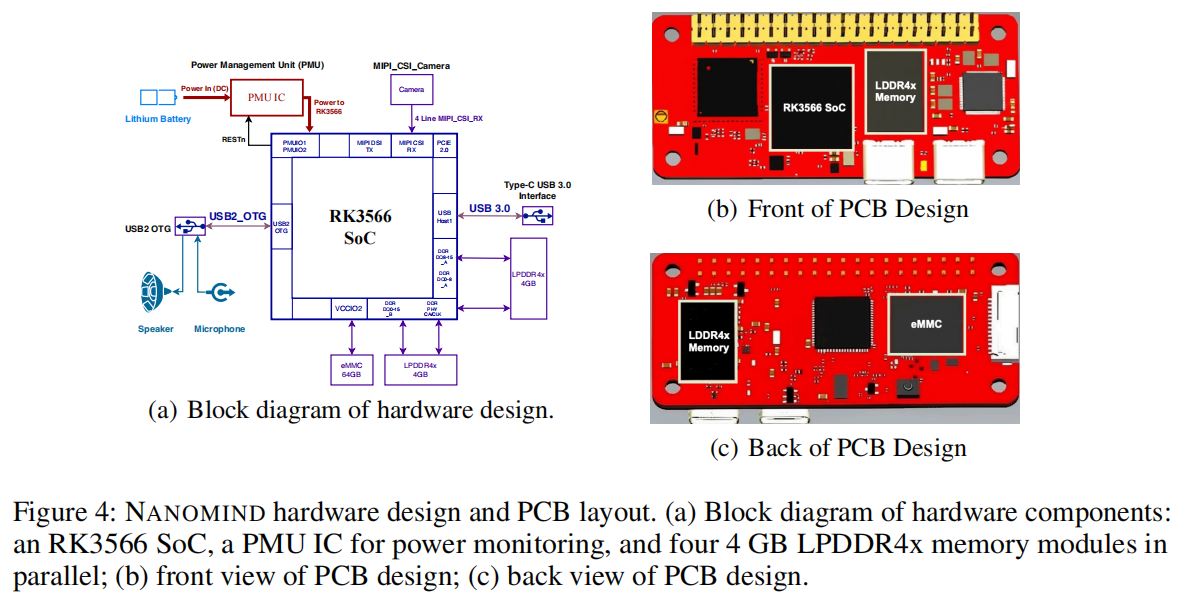

为实现模块化模型组件的卸载,并在系统层面更好地协调各加速器,作者设计了专用硬件。PCB 设计借鉴并修改了多个开源参考设计,以确保与主流 I/O 接口的兼容性。如图 4 所示,该设计针对高效的设备端 LLM 推理进行了优化。构建的硬件演示见图 10。
- RK3566 SoC:作者采用 Rockchip 的 RK3566,这是一款高性价比、低功耗的 SoC。它包含四核 Arm Cortex-A55(最高 1.6GHz)、集成 NPU、Mali G52-2EE GPU 和外部 DDR 支持。其单价低于 12 美元,为构建能进行本地 LLM 推理的紧凑型设备提供了所有核心功能。
- 并行 LPDDR4x 内存:为解决小型设备的内存带宽瓶颈(对内存受限的 LLM 工作负载尤为重要),作者集成了四个并行的 LPDDR4x 内存通道,显著提升了有效内存吞吐量。CPU 负责跨加速器的统一内存管理,对资源回收拥有完全控制权,特别是管理 GPU 和 NPU 工作负载的内存清理和缓冲区复用,确保共享内存空间的高效利用。
- 接口(Interfaces):为最小化功耗并简化系统,作者移除了 HDMI、Wi-Fi/Bluetooth 等非必要组件。作者使用 USB-OTG 支持一个音频集线器,用于扬声器和麦克风输入,实现语音交互。MIPI CSI 接口支持从低功耗摄像头捕获图像。可用接口见附录中的图 10。
- 电源管理单元(PMU):与传统移动和边缘平台不同,作者的系统包含一个专用的 PMU,用于实时能耗监控和控制,支持作者的能效策略。
4. Evaluation
4.1 RESOURCE USAGE
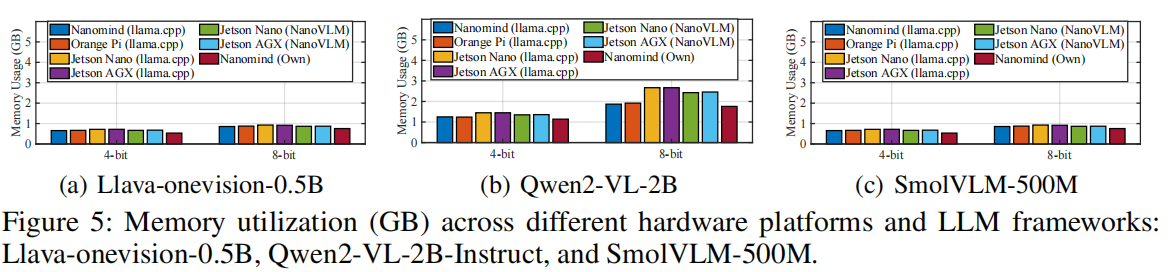
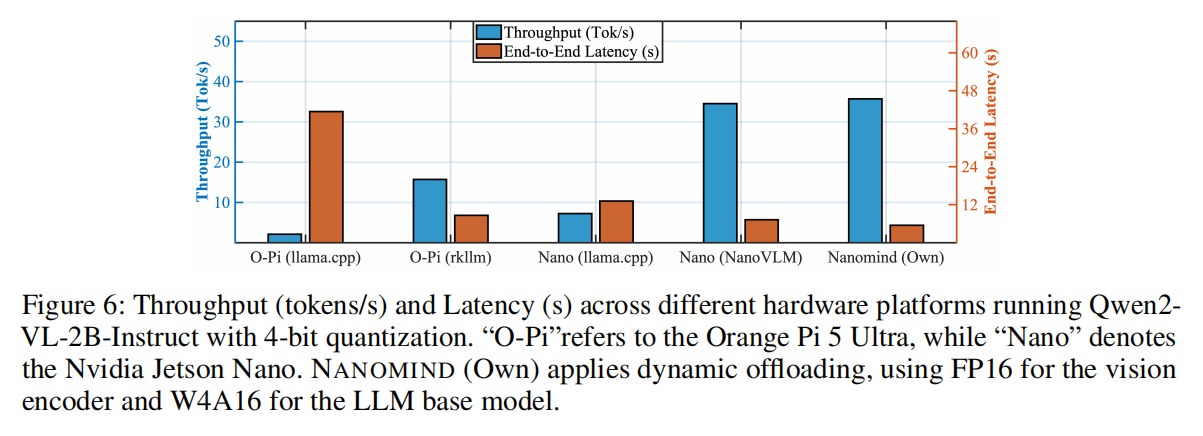
本节从三个维度对 NANOMIND 进行实验评估:(1) 不同平台的资源使用情况分析,(2) 不同卸载策略下的模型精度,(3) 不同运行条件下的能效测量。
作者在包括 InfoVQA、DoCVQA、MMBench 和 MME 在内的数据集上评估了 VLM 推理的资源效率,重点关注响应延迟、硬件利用率(CPU、GPU、内存)和能效。
- 内存使用(图 5):在 LLaVA-OneVision-0.5B、Qwen2-VL-2B 和 SmolVLM-500M 三个模型上,
llama.cpp在所有平台(NANOMIND、Orange Pi 5 Ultra、Jetson Nano/AGX)上始终消耗更多内存。NANOMIND 的内存使用更低,这归功于 TABM 的环形缓冲区对共享内存的优化。 - 吞吐量与延迟(图 6):在运行 4-bit 量化的 Qwen2-VL-2B-Instruct 时,尽管 NANOMIND 的硬件(RK3566)性能低于 Orange Pi 5 Ultra (RK3588) 和 Jetson Nano,但其吞吐量(约 35.7 tokens/s)与使用 CUDA 的 Jetson Nano 上运行
NanoVLM框架相当,并且相比使用官方rkllm的 Orange Pi 5 Ultra,端到端延迟降低了 36.2%。值得注意的是,在 NANOMIND 硬件上运行llama.cpp因超出运行时间限制而未获得结果。
4.2 DIFFERENT COMBINATIONS OF HYBRID QUANTIZATION
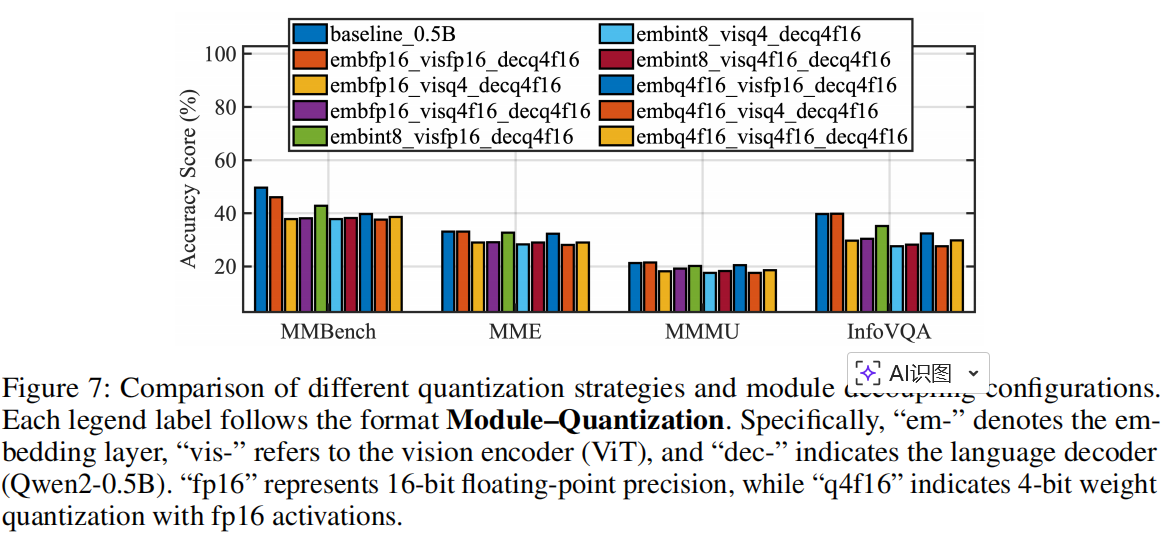
图 7 展示了不同量化策略和模块解耦配置的对比。图例标签格式为 模块–量化,其中:
em-表示嵌入层,vis-表示视觉编码器(ViT),dec-表示语言解码器(Qwen2-0.5B)。fp16代表 16 位浮点精度,q4f16表示 4-bit 权重量化 + fp16 激活。
作者在 MMBench、MMLU、MME 和 InfoVQA 等多个基准上评估了这些配置。结果明确显示:当 VLM 被分解并在不同加速器上独立执行时,视觉相关任务的精度主要由 ViT 的精度决定。这凸显了在硬件资源受限的情况下,为视觉编码器分配更高比特宽度或计算资源对于优化多模态性能的重要性。
4.3 POWER CONSUMPTION AND HOURS TO USE
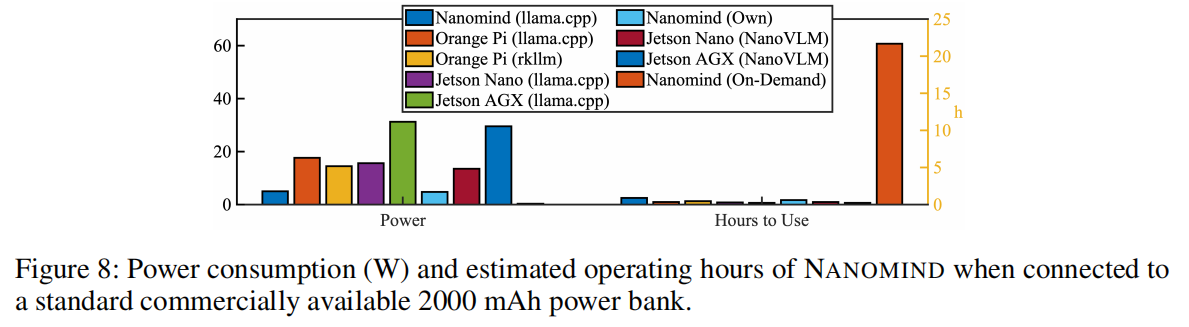
图 8 报告了 NANOMIND 在标准 2000 mAh 商用电池包供电下的功耗和预估运行时间。得益于软硬件协同设计,NANOMIND 通过减少资源使用而降低了功耗。
- 在低功耗模式下,按需一次性级联推理的平均功耗仅为 0.375 W,可提供长达 20.8 小时的事件触发式推理,超越了现有的边缘设备。
- 在全性能模式下,系统也能支持 LlaVA-OneVision 与摄像头连续工作近半天(约12小时)。
5. Conclusion
在本文中,作者提出了 NANOMIND——一个用于高效设备端大型多模态模型推理的软硬件协同设计框架。通过将模型分解为模块化组件,并在异构加速器之间动态卸载任务,作者的评估表明,该框架在边缘设备上的性能匹配甚至超越了现有框架,并且在低功耗模式下可实现超过 20 小时的电池供电多模态推理。这项工作为在日常设备上实现私密、响应迅速且高能效的多模态 AI 提供了一条切实可行的路径。