
Conference: CVPR'26
Github: https://github.com/xuyang-liu16/V2Drop
Abstract
Large vision-language models(LVLMs)在多模态理解任务上表现强大,但随着高分辨率图像与长视频理解需求不断增加,视觉 token 数量急剧上升,从而显著降低推理效率。Token compression 提供了一条直接路径:在不改变模型结构的前提下减少待处理 token 数,从而提升计算效率。作者通过系统分析指出,现有 inner-LLM token compression 方法主要存在两个关键问题:positional bias 和 incompatibility with efficient operators,这两点严重阻碍了它们在 LVLM 加速中的实际部署。本文提出了首个从动态 token variation 视角出发的方法,发现 LLM 内部的视觉 token variation 具有 task-agnostic 特性。基于这一观察,作者提出 Variation-aware Vision Token Dropping(V2Drop),在 LVLM 推理过程中逐步移除 variation 最小的视觉 token,从而提升计算效率。大量实验表明,V2Drop 在图像理解任务和视频理解任务上分别保留了原始性能的 94.0% 和 98.6%,同时将 LLM generation latency 分别降低了 31.5% 和 74.2%。
1. Introduction
Large vision-language models(LVLMs)在视觉理解与推理任务上表现突出,能够覆盖多种 vision-language 任务;但高分辨率图像理解和长视频理解会引入大量视觉 token,导致推理开销快速增长并限制实际部署。作者指出,随着输入分辨率和视频长度的提升,视觉 token 的数量增加会带来明显的计算复杂度压力,尤其是在 LLM 侧的 prefilling 和 generation 阶段。
为缓解这一问题,已有大量 token compression 方法被提出,用于去除冗余视觉 token 并尽可能保留性能。其中,Inner-LLM compression 因其 architecture-agnostic 和 plug-and-play 的性质受到特别关注:这类方法不需要修改主干结构,而是在 LLM forward 过程中进行 token 剪枝或合并。典型方法往往依赖 LLM attention weights 来选择“重要 token”,但作者强调,这类策略存在根本缺陷。
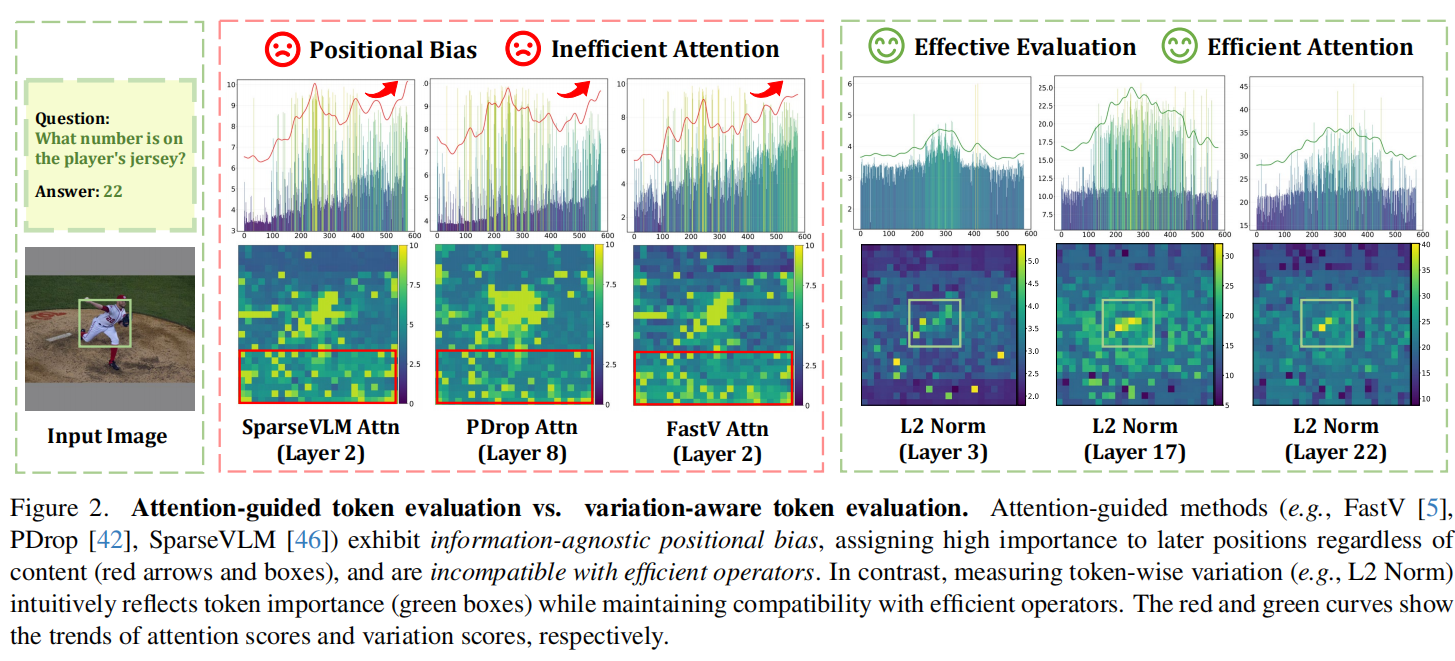
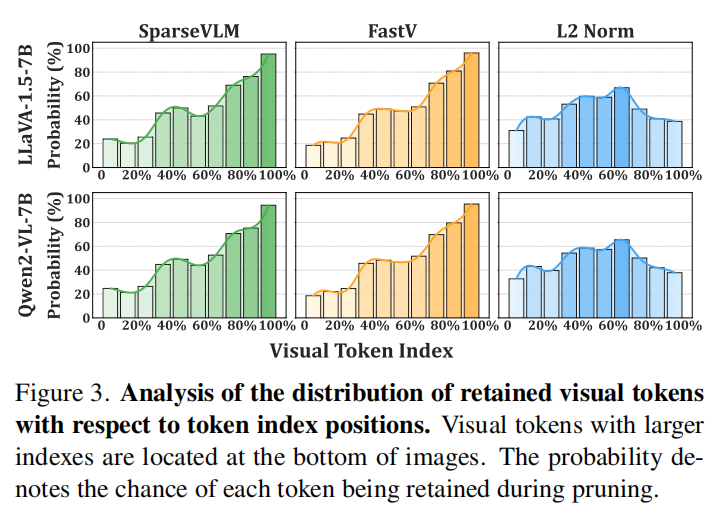
作者进一步分析了 attention-guided 方法(如 FastV、SparseVLM)与 variation-aware evaluation 的 token 保留分布:前者会显著偏向保留视觉序列末端 token,而不管内容是否真的重要;后者则能产生更自然、更均匀的空间分布。Figure 2 和 Figure 3 共同说明了这一点:attention-guided 方法表现出information-agnostic positional bias,即高重要性偏置与内容无关,更多与 token 位置相关;而 variation-aware 方法则更符合视觉语义的实际分布。这个偏差会导致早期重要 token 被误删,进而加剧 multimodal hallucination。与此同时,attention weight 的显式计算还会与 FlashAttention 等 efficient operators 冲突,造成额外显存开销,甚至峰值显存高于不压缩模型。
基于上述问题,作者提出了一个核心问题:是否可以不依赖间接 attention signal,而是直接利用 token 在模型内部的行为变化来判断其重要性? 为此,本文从 token variation 的角度重新审视“什么才是真正重要的视觉 token”。作者的核心洞察是:真正参与 LLM 计算的 token,会在层与层之间表现出更显著的表征变化;而作用较小的 token 则在多个层之间保持相对静态。 因此,作者定义这类变化缓慢的 token 为 lazy tokens,并提出 V2Drop:通过识别并逐步丢弃 lazy tokens,实现高效的 LVLM 推理加速,同时避免 positional bias,并保持与 efficient operators 的兼容性。
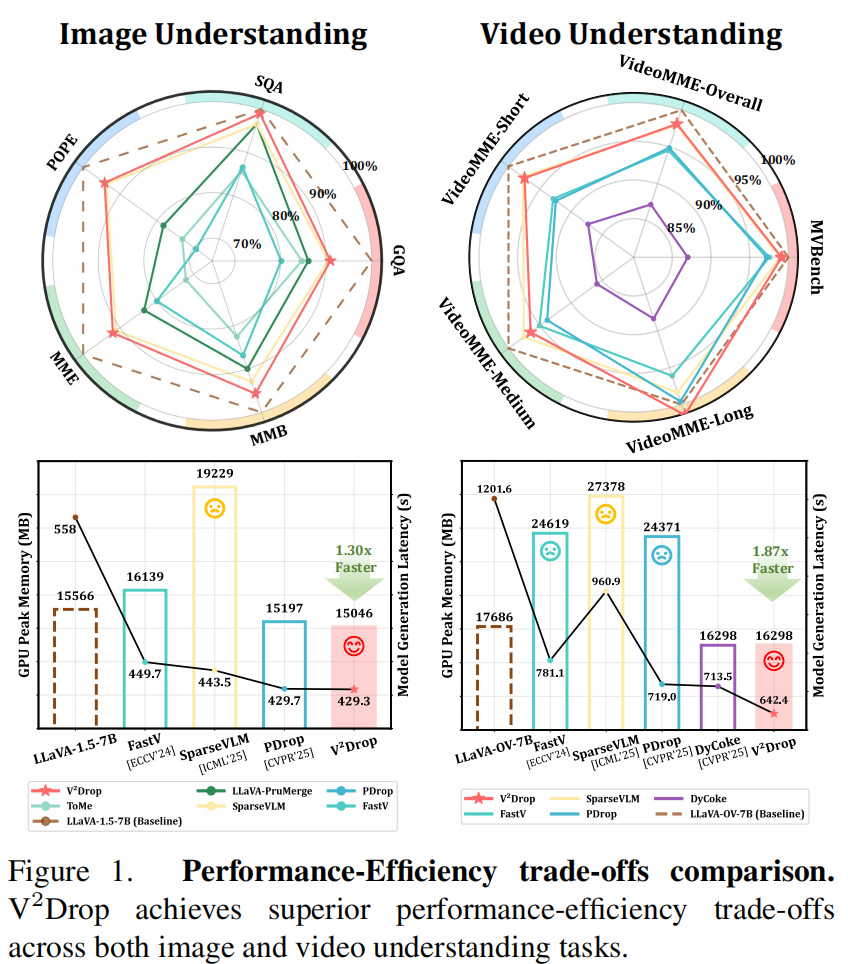
最终,V2Drop 在图像理解和视频理解上都取得了良好的 performance-efficiency trade-off:图像理解任务上达到 1.30× 加速,视频理解任务上达到 1.87× 加速。作者总结了三点贡献:第一,系统性分析 token variation pattern,证明 variation magnitude 与任务相关性和 token 重要性相关;第二,提出 variation-aware token dropping,在不依赖 attention weights 的情况下实现 progressive dropping;第三,通过大量实验验证其在不同 LVLM 和 VideoLLM 上均能兼顾准确率与效率。
2. Related Work
Large Vision-Language Models
LVLM 通常采用 ViT-Projector-LLM 范式:视觉编码器首先将图像或视频编码为视觉 embeddings,再通过 projector(通常是两层 MLP)映射为 vision tokens,最后交由 LLM 进行文本生成。近年来,LVLM 为适应更高分辨率输入和更长视频序列,开始引入动态裁剪、native resolution 和长上下文建模等策略,例如 InternVL-3、LLaVA-OneVision、Qwen2-VL、Seed1.5-VL、VideoLLaMA3 等。但这些改进也使 visual token 数量进一步增长,导致二次复杂度问题更加严重,影响 scalability 和 practical deployment。
Token Compression for LVLMs
Token compression 的目标是直接缩短 token 序列,从而提升模型效率。相关工作从 training-aware paradigm 逐步发展到 training-free 方法,后者更适合 plug-and-play 式的推理加速。作者将方法分为两类:
- Pre-LLM compression:在进入 LLM 之前对视觉 token 进行压缩;
- Inner-LLM compression:在 LLM forward 过程中完成压缩。
然而,大多数 Inner-LLM 方法依赖 attention weights,因而存在两个问题:一是无法与 FlashAttention 等 efficient attention operator 兼容,导致显存峰值上升;二是容易产生 positional bias,偏向保留序列末端 token,而忽略真正关键的视觉区域。作者因此转向低 variation token 的渐进式丢弃,以实现无需 attention weights 的训练自由加速。
3. Methodology
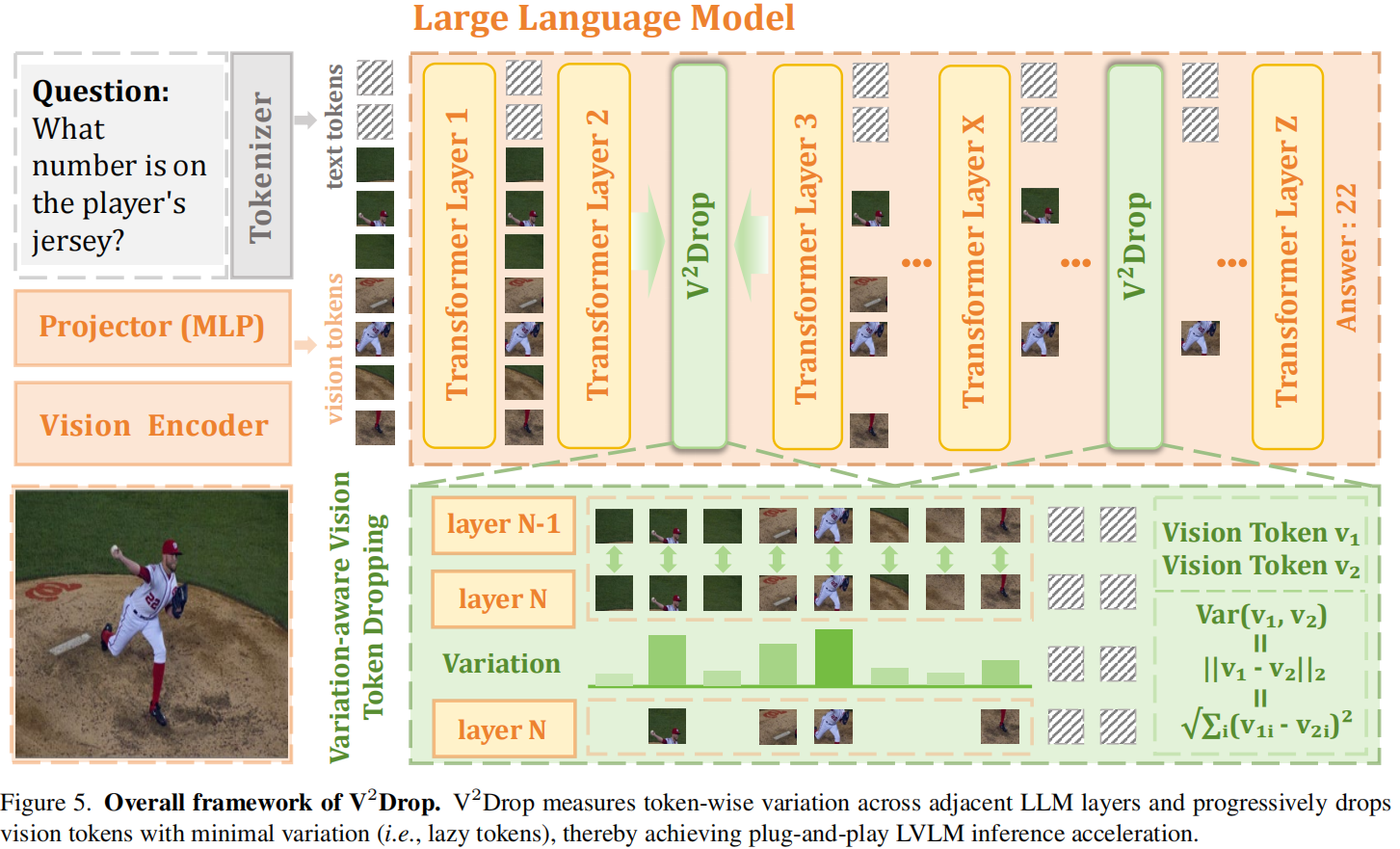
3.1. Preliminary: LVLMs
LVLM 主要遵循 “ViT-Projector-LLM” 架构。给定图像 $I \in \mathbb{R}^{H \times W \times 3}$ 或视频 $V = {v_i}{i=1}^{T} \in \mathbb{R}^{T \times H \times W \times 3}$,其处理流程可概括为三步: (i) Visual encoder(ViT) 将输入映射为视觉 embeddings $E \in \mathbb{R}^{N \times D}$(图像)或 $E = {e_i}{i=1}^{T} \in \mathbb{R}^{T \times N \times D}$(视频); (ii) Projector(通常为 2-layer MLP) 将 embeddings 映射为 vision tokens $F_v \in \mathbb{R}^{M \times D’}$(图像)或 $F_v = {f_v^i}_{i=1}^{T} \in \mathbb{R}^{T \times M \times D’}$(视频),其中 $M \le N$; (iii) LLM decoder 在 prefilling 阶段同时处理视觉 token 和文本 token $F_t$,并在 decoding 阶段自回归地产生答案。生成过程可写为:
$$ p(Y \mid F_v, F_t)=\prod_{j=1}^{L} p\left(y_j \mid F_v, F_t, Y_{1:j-1}\right), $$
其中 $Y={y_j}_{j=1}^{L}$ 表示最终生成 token 序列。这里作者强调,不同 LVLM 的 token 数变化存在差异:例如 LLaVA-1.5 在 projector 后 token 数通常保持不变($M=N$),而部分 VideoLLM 会为了效率在 projector 阶段提前压缩 token($M<N$)。这也解释了为什么 token compression 在不同模型上的作用位置和收益会不同。
3.2. Token Variation in LVLMs
为克服 attention-guided 的局限,作者从“外部信号”转向“内部属性”,重新思考 token importance 的本质:一个视觉 token 之所以重要,是因为它在 LLM 处理过程中持续参与并引发表征变化。 与之相对,变化较小的 token 更像是“lazy token”,对最终输出贡献有限。
Token Variation Metrics
作者定义了相邻 LLM transformer layers 之间的 token variation,并使用三种指标衡量:L1 Distance、L2 Distance 和 Cosine Similarity。对于第 $l$ 层的第 $i$ 个视觉 token $f_i^{(l)}$,variation 记为:
$$
\text{Var}(f_i^{(l-1)}, f_i^{(l)})=
\begin{cases}
|f_i^{(l)}-f_i^{(l-1)}|_1, & \text{L1 Distance}
|f_i^{(l)}-f_i^{(l-1)}|_2, & \text{L2 Distance}
1-\dfrac{f_i^{(l)} \cdot f_i^{(l-1)}}{|f_i^{(l)}|_2 |f_i^{(l-1)}|_2}, & \text{Cosine Similarity}
\end{cases}
$$
其中,数值越大表示 token 在相邻层之间表征变化越显著。三种指标分别反映不同类型的变化:L1 更关注稀疏变化,L2 反映整体幅度变化,Cosine Similarity 则关注方向变化。作者默认在实验中采用 L2 distance,并在消融实验中验证其他指标也同样有效。
Variation-Relevance Relationship
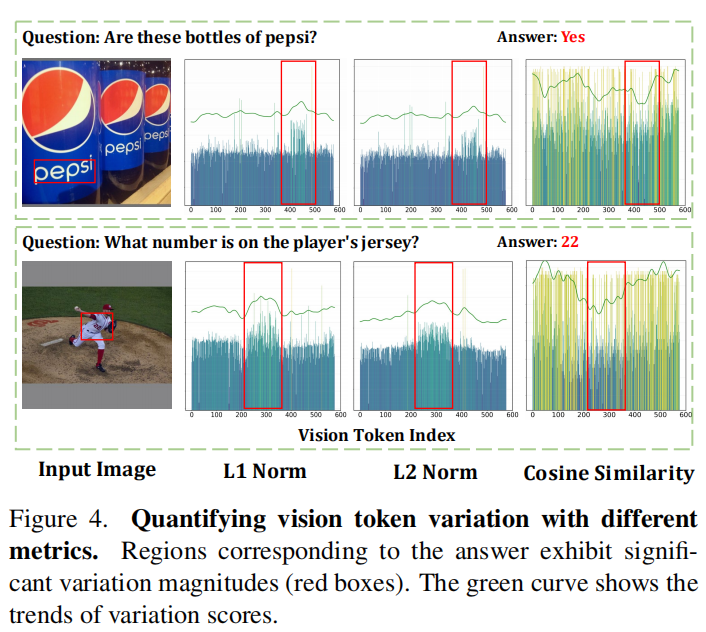
Figure 4 给出定性证据:在 LLaVA-1.5-7B 第三层 transformer 中,具有显著 variation 的 token(高 L1/L2、低 cosine similarity)与答案相关区域高度一致,例如 “Are these bottles of pepsi?” 中与 pepsi 瓶子相关的 token,以及 “What number is on the player’s jersey?” 中与球衣数字相关的 token(如答案 22 对应区域)。相反,variation 较小的 token 多落在任务无关区域。
更重要的是,Figure 4 展示了两个不同空间位置的例子:一个答案区域位于图像中部,另一个位于底部,对应的 token index 也处于不同区间。但三种 variation 指标都能准确识别这些语义关键区域,说明 variation 机制具有spatial-agnostic 能力,不依赖 token 在序列中的绝对位置。这个性质恰好克服了 attention-guided 方法的 positional bias。作者由此提出:高 variation token 正在 actively participating in reasoning process,因此应被保留;低 variation token 代表稳定、贡献有限的 lazy tokens,可安全丢弃。
3.3. Variation-aware Vision Token Dropping
基于上述观察,作者提出 V2Drop:在 LLM 推理过程中,按 layer 逐步识别并丢弃 low-variation 的 vision tokens,同时保留语义上更关键的 token。
V2Drop 的核心设置是:给定 LLM 中的 vision tokens 序列 $F_v \in \mathbb{R}^{M \times D’}$,采用一个 multi-stage progressive dropping 策略,在预先选定的三处 LLM 层上进行 pruning。作者将这三层设计为覆盖 shallow / middle / deep 三个阶段,以在压缩率与性能保持之间取得平衡。Figure 5 展示了整体框架:V2Drop 在相邻层间比较 token variation,并在若干关键层进行逐步丢弃。
在第 $k$ 个 pruning layer $l_k \in L$,V2Drop 依次执行三个步骤:
(i) Variation Computation
对于层 $l_k$ 上的每个 token $f_i^{(l_k)}$,计算它相对于前一层 $l_k-1$ 的变化幅度:
$$ S^{(l_k)}=\left{\text{Var}\left(f_i^{(l_k-1)}, f_i^{(l_k)}\right)\right}{i=1}^{M{l_k}}, $$
其中 $M_{l_k}$ 表示该层当前剩余的视觉 token 数。默认使用 L2 distance,因为实验表明它在性能与效率之间取得较好平衡。作者强调,该步骤只需要简单的向量差分与范数计算,不需要重新计算 attention weights,因此在实现上非常轻量。
(ii) Token Ranking and Selection
接着,将所有视觉 token 按 variation score 从大到小排序,保留 top-$K_{l_k}$ 个 variation 最大的 token:
$$ \hat{F}v^{l_k} = \text{TopK}(F_v^{l_k}, S^{(l_k)}, K{l_k}). $$
这一机制的关键在于:variation 大的 token 更可能承载与当前推理问题相关的关键信息,因此应被保留;variation 小的 token 更可能是冗余或无关信息,因此可被丢弃。 由于排名依据来自 token 自身的动态变化,而非 attention scores,因此不会出现“总偏向序列末尾 token”的问题。
(iii) Token Reorganization
保留下来的 token 会被重组为后续层的输入,且满足 $K_{l_k} < M_{l_k}$,从而完成 progressive visual token dropping。作者使用一个预定义的压缩日程:
$$ M \rightarrow K_a \rightarrow K_b \rightarrow K_c, $$
其中 $K_a, K_b, K_c$ 分别是三个阶段的压缩目标,可用于调节 performance-efficiency trade-off。也就是说,V2Drop 并非一次性把 token 大幅砍掉,而是在模型的浅层、中层、深层逐步压缩,以尽量减少早期误删导致的信息损失。作者在消融实验中证明,progressive dropping 明显优于 one-time dropping,同时不同 pruning layer 的选择也较为鲁棒。
从方法设计上看,V2Drop 的关键优势是两点:第一,它不再使用 attention weights,所以天然避免 attention-guided 的 positional bias;第二,它与 FlashAttention 等 efficient operators 完全兼容,因为不需要为 token selection 额外保留昂贵的 attention map。
3.4. Theoretical Analysis
作者通过一阶分析建立了 token variation 与模型输出变化之间的理论联系,从而证明 variation magnitude 可以作为 token importance 的有效 proxy。
3.4.1. Problem Formulation
设第 $t$ 层的 token 表示为:
$$ X^{(t)}={x_1^{(t)}, \ldots, x_n^{(t)}}\subset \mathbb{R}^{d}. $$
定义 token $j$ 的层间 variation 为:
$$ \Delta x_j^{(t)} = x_j^{(t+1)} - x_j^{(t)}. $$
令 $f:\mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{k}$ 表示从第 $t+1$ 层表示到最终输出的映射,则 token $j$ 关于输出的 Jacobian 为:
$$ J_j = \frac{\partial f}{\partial x_j^{(t+1)}} \in \mathbb{R}^{k \times d}. $$
这个建模方式的直观含义是:我们想知道某个 token 在层间发生变化后,会对最终输出带来多大影响。
3.4.2. Variation-Impact Theorem
Theorem 1. 在 $f$ 满足温和光滑性条件下,token $j$ 引起的输出变化满足:
$$ |\Delta f_j| \approx |J_j|_{\text{op}} \cdot |\Delta x_j^{(t)}|. $$
这里 $|\cdot|_{\text{op}}$ 是 operator norm,$\Delta f_j$ 表示仅 token $j$ 从第 $t$ 层变化到第 $t+1$ 层时引起的输出变化。
证明思路是对 $f$ 在 $x_j^{(t)}$ 附近作一阶 Taylor 展开:
$$ f(\ldots, x_j^{(t+1)}, \ldots) = f_j^{(t)} + J_j \Delta x_j^{(t)} + O(|\Delta x_j^{(t)}|^2) = f_j^{(t)} + J_j \Delta x_j^{(t)} + R_j, $$
其中 $R_j$ 是高阶余项。再利用三角不等式与 operator norm 的定义:
$$ |\Delta f_j| \le |J_j \Delta x_j^{(t)}| + |R_j| \le |J_j|_{\text{op}} \cdot |\Delta x_j^{(t)}| + |R_j|. $$
当 $|\Delta x_j^{(t)}|$ 足够小时,二阶项可忽略,于是得到近似关系:
$$ |\Delta f_j| \approx |J_j|_{\text{op}} \cdot |\Delta x_j^{(t)}|. $$
这说明:token 在层间变化越大,其对输出的影响通常越大。
3.4.3. Implications
基于上述定理,作者得到一个 corollary:若 token 的 Jacobian operator norm 具有下界 $|J_j|_{\text{op}} \ge \mu > 0$,则更大的 variation 意味着更大的 output influence,因此 variation 可以作为计算高效的 token importance proxy。形式上有:
$$ |\Delta f_j| \gtrsim \mu \cdot |\Delta x_j^{(t)}|. $$
这意味着,只要 token 的梯度影响不退化,选择 variation 小的 token 进行 dropping,就近似等价于选择对输出扰动最小的一组 token 删除。作者进一步在附录中说明,这一假设在 Transformer 结构中是合理的:残差连接、layer normalization 以及 softmax attention 都有助于维持稳定的梯度传播。
4. Experiments
作者在多个 LVLM 和 VideoLLM 上进行了全面实验,涵盖 10 个多模态理解 benchmark,并在附录中给出了实现细节。实验结论总体上支持两个核心主张:第一,variation-aware token dropping 在性能上优于 attention-guided baselines;第二,它在效率上与 efficient operators 高度兼容,尤其适合视频场景和高分辨率输入。
Computational Overhead
作者首先评估了 V2Drop 的计算开销。由于只在三层进行 pruning,因此计算成本极低。对 $M$ 个、维度为 $D’$ 的 token 计算 L2 distance 的代价约为 $3MD’$ FLOPs;以 LLaVA-1.5 中 $M=576, D’=4096$ 为例,单层约为 7M FLOPs,仅占单个 attention layer(约 32B FLOPs)的 0.022%。三层总开销约 21M FLOPs,仅占完整 forward pass 的 0.002%。Table 5 也验证了这一点:V2Drop 和 random dropping 的 throughput 几乎一致,说明 variation 计算几乎不构成额外瓶颈。
4.1. Main Comparisons
Image Understanding
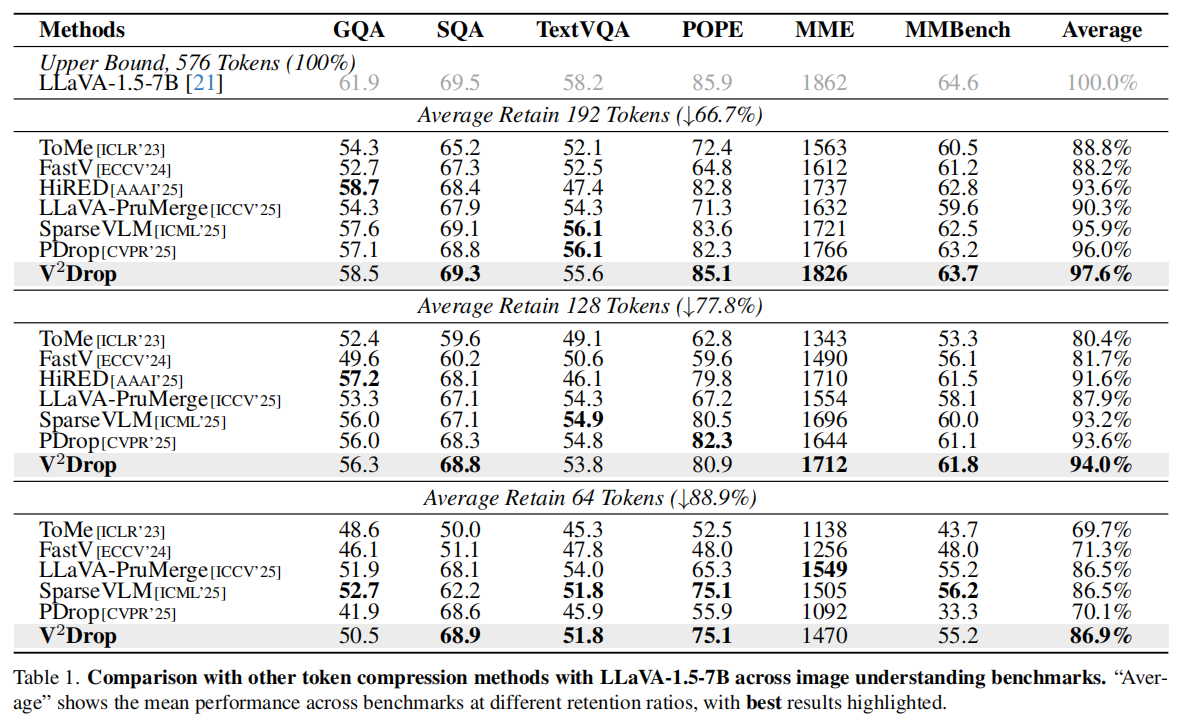
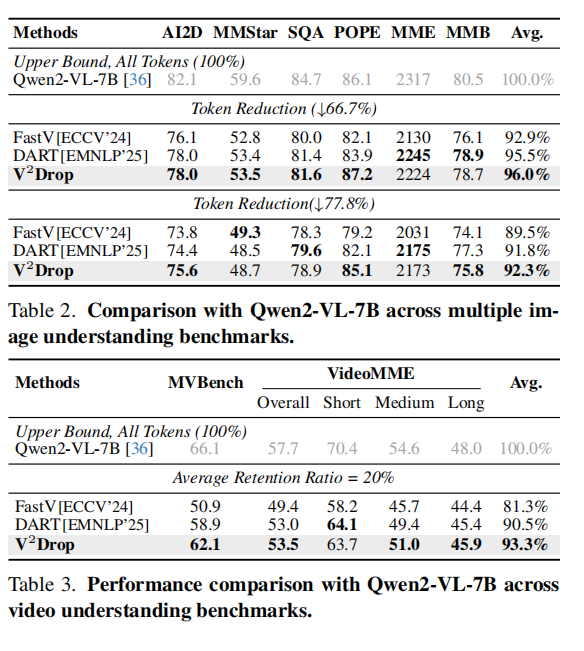
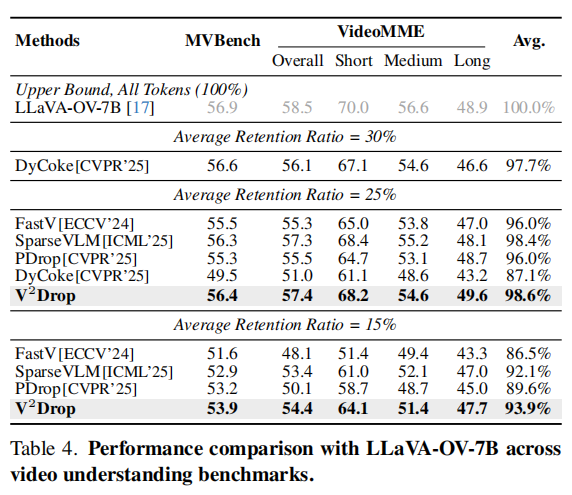

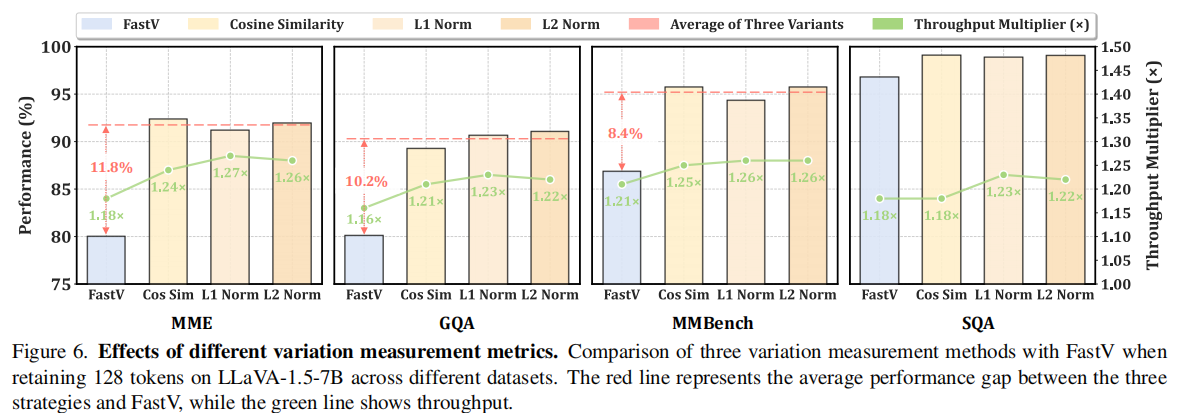

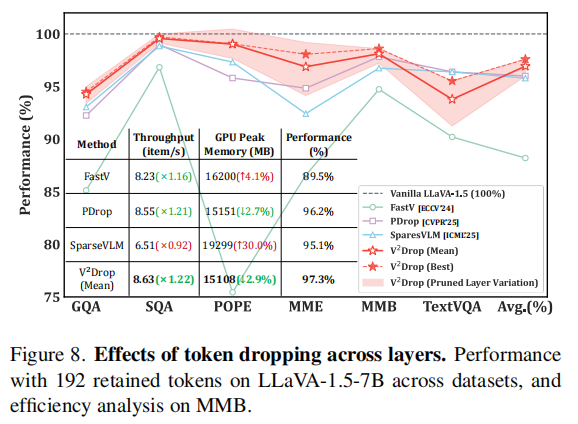
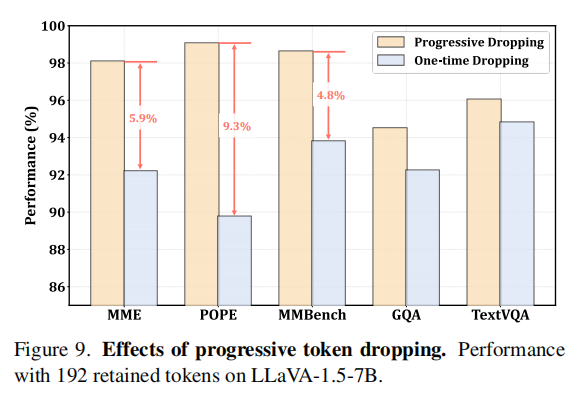
Table 1 比较了 V2Drop 与多种 token compression 方法在 LLaVA-1.5-7B 上的图像理解性能,分别在保留 192、128、64 个 token 的情况下进行对比。作者重点强调了三个结论:
- State-of-the-art performance:在保留 192 tokens(即减少 66.7%)时,V2Drop 的平均性能达到 97.6%,比第二名 PDrop 高 1.6%;即使压缩更激进,V2Drop 依旧保持稳定。
- Efficient operator compatibility:V2Drop 不需要显式 attention score 计算,因此可以无缝接入 FlashAttention,且在峰值显存和总时延上接近 random dropping。
- Scalability:在 Qwen2-VL-7B 上,V2Drop 在高分辨率和 variable-resolution 输入下也保持领先,说明方法对先进模型具有良好迁移性。
Table 1. Comparison with other token compression methods on LLaVA-1.5-7B.
| Methods | GQA | SQA | TextVQA | POPE | MME | MMBench | Average |
|---|---|---|---|---|---|---|---|
| Upper Bound, 576 Tokens (100%) | |||||||
| LLaVA-1.5-7B | 61.9 | 69.5 | 58.2 | 85.9 | 1862 | 64.6 | 100.0% |
| Average Retain 192 Tokens (↓66.7%) | |||||||
| ToMe | 54.3 | 65.2 | 52.1 | 72.4 | 1563 | 60.5 | 88.8% |
| FastV | 52.7 | 67.3 | 52.5 | 64.8 | 1612 | 61.2 | 88.2% |
| HiRED | 58.7 | 68.4 | 47.4 | 82.8 | 1737 | 62.8 | 93.6% |
| LLaVA-PruMerge | 54.3 | 67.9 | 54.3 | 71.3 | 1632 | 59.6 | 90.3% |
| SparseVLM | 57.6 | 69.1 | 56.1 | 83.6 | 1721 | 62.5 | 95.9% |
| PDrop | 57.1 | 68.8 | 56.1 | 82.3 | 1766 | 63.2 | 96.0% |
| V2Drop | 58.5 | 69.3 | 55.6 | 85.1 | 1826 | 63.7 | 97.6% |
| Average Retain 128 Tokens (↓77.8%) | |||||||
| ToMe | 52.4 | 59.6 | 49.1 | 62.8 | 1343 | 53.3 | 80.4% |
| FastV | 49.6 | 60.2 | 50.6 | 59.6 | 1490 | 56.1 | 81.7% |
| HiRED | 57.2 | 68.1 | 46.1 | 79.8 | 1710 | 61.5 | 91.6% |
| LLaVA-PruMerge | 53.3 | 67.1 | 54.3 | 67.2 | 1554 | 58.1 | 87.9% |
| SparseVLM | 56.0 | 67.1 | 54.9 | 80.5 | 1696 | 60.0 | 93.2% |
| PDrop | 56.0 | 68.3 | 54.8 | 82.3 | 1644 | 61.1 | 93.6% |
| V2Drop | 56.3 | 68.8 | 53.8 | 80.9 | 1712 | 61.8 | 94.0% |
| Average Retain 64 Tokens (↓88.9%) | |||||||
| ToMe | 48.6 | 50.0 | 45.3 | 52.5 | 1138 | 43.7 | 69.7% |
| FastV | 46.1 | 51.1 | 47.8 | 48.0 | 1256 | 48.0 | 71.3% |
| LLaVA-PruMerge | 51.9 | 68.1 | 54.0 | 65.3 | 1549 | 55.2 | 86.5% |
| SparseVLM | 52.7 | 62.2 | 51.8 | 75.1 | 1505 | 56.2 | 86.5% |
| PDrop | 41.9 | 68.6 | 45.9 | 55.9 | 1092 | 33.3 | 70.1% |
| V2Drop | 50.5 | 68.9 | 51.8 | 75.1 | 1470 | 55.2 | 86.9% |
表格说明:在 192 tokens 时,V2Drop 在 GQA、POPE、MME、MMBench 上都很强;在 128 tokens 时总体依旧稳;在极限 64 tokens 时,平均表现明显优于传统压缩方法,说明 variation-based selection 在更强压缩下仍能保留关键语义。
Qwen2-VL-7B Image Understanding
Table 2 将方法推广到 Qwen2-VL-7B,实验覆盖 AI2D、MMStar、SQA、POPE、MME、MMBench。V2Drop 在 66.7% token reduction 和 77.8% token reduction 下都优于 FastV 与 DART,说明该方法对更强大的 native-resolution LVLM 仍然有效。尤其值得注意的是,V2Drop 在 POPE 上的表现非常稳定,说明它不仅能保留语义信息,也能减少 object hallucination 风险。
Table 2. Comparison with Qwen2-VL-7B across multiple image understanding benchmarks.
| Methods | AI2D | MMStar | SQA | POPE | MME | MMB | Avg. |
|---|---|---|---|---|---|---|---|
| Upper Bound, All Tokens (100%) | |||||||
| Qwen2-VL-7B | 82.1 | 59.6 | 84.7 | 86.1 | 2317 | 80.5 | 100.0% |
| Token Reduction (↓66.7%) | |||||||
| FastV | 76.1 | 52.8 | 80.0 | 82.1 | 2130 | 76.1 | 92.9% |
| DART | 78.0 | 53.4 | 81.4 | 83.9 | 2245 | 78.9 | 95.5% |
| V2Drop | 78.0 | 53.5 | 81.6 | 87.2 | 2224 | 78.7 | 96.0% |
| Token Reduction (↓77.8%) | |||||||
| FastV | 73.8 | 49.3 | 78.3 | 79.2 | 2031 | 74.1 | 89.5% |
| DART | 74.4 | 48.5 | 79.6 | 82.1 | 2175 | 77.3 | 91.8% |
| V2Drop | 75.6 | 48.7 | 78.9 | 85.1 | 2173 | 75.8 | 92.3% |
Video Understanding
作者将 V2Drop 扩展到视频理解任务,并使用 LLaVA-OV-7B 与 Qwen2-VL-7B 进行评估。Table 3 和 Table 4 给出整体性能,Table 5 给出效率指标。结论非常明确:V2Drop 在视频场景下比图像场景更有优势,因为视频 token 更长、更冗余,而 variation-based dropping 更适合在长序列中识别那些真正影响推理的 token。
在 Qwen2-VL-7B 上,V2Drop 在 20% average retention ratio 下取得 93.3% 的平均性能,显著优于 FastV 的 81.3% 和 DART 的 90.5%。在 LLaVA-OV-7B 上,V2Drop 在 25% retention 下达到 98.6%,在 15% retention 下也仍达到 93.9%,并且明显优于 FastV、SparseVLM、PDrop 和 DyCoke。尤其在 VideoMME (Long) 上,V2Drop 的优势更明显,因为它缓解了 VideoLLM 对后期帧 token 的偏置,避免把注意力过度集中在后续 token。
Table 3. Performance comparison with Qwen2-VL-7B across video understanding benchmarks.
| Methods | MVBench Overall | VideoMME Short | VideoMME Medium | VideoMME Long | Avg. |
|---|---|---|---|---|---|
| Upper Bound, All Tokens (100%) | |||||
| Qwen2-VL-7B | 66.1 | 57.7 | 70.4 | 54.6 | 100.0% |
| Average Retention Ratio = 20% | |||||
| FastV | 50.9 | 49.4 | 58.2 | 45.7 | 81.3% |
| DART | 58.9 | 53.0 | 64.1 | 49.4 | 90.5% |
| V2Drop | 62.1 | 53.5 | 63.7 | 51.0 | 93.3% |
Table 4. Performance comparison with LLaVA-OV-7B across video understanding benchmarks.
| Methods | MVBench Overall | VideoMME Short | VideoMME Medium | VideoMME Long | Avg. |
|---|---|---|---|---|---|
| Upper Bound, All Tokens (100%) | |||||
| LLaVA-OV-7B | 56.9 | 58.5 | 70.0 | 56.6 | 100.0% |
| Average Retention Ratio = 30% | |||||
| DyCoke | 56.6 | 56.1 | 67.1 | 54.6 | 97.7% |
| Average Retention Ratio = 25% | |||||
| FastV | 55.5 | 55.3 | 65.0 | 53.8 | 96.0% |
| SparseVLM | 56.3 | 57.3 | 68.4 | 55.2 | 98.4% |
| PDrop | 55.3 | 55.5 | 64.7 | 53.1 | 96.0% |
| DyCoke | 49.5 | 51.0 | 61.1 | 48.6 | 87.1% |
| V2Drop | 56.4 | 57.4 | 68.2 | 54.6 | 98.6% |
| Average Retention Ratio = 15% | |||||
| FastV | 51.6 | 48.1 | 51.4 | 49.4 | 86.5% |
| SparseVLM | 52.9 | 53.4 | 61.0 | 52.1 | 92.1% |
| PDrop | 53.2 | 50.1 | 58.7 | 48.7 | 89.6% |
| V2Drop | 53.9 | 54.4 | 64.1 | 51.4 | 93.9% |
Efficiency Comparison
Table 5 从效率角度展示了 V2Drop 的收益,包括 LLM generation latency、model generation latency、total latency、GPU peak memory 和 throughput。这里最值得强调的是:V2Drop 在降低时延的同时,并没有引入明显额外显存开销,说明 variation 计算是“低成本、高收益”的。
- 在 LLaVA-1.5-7B 上,V2Drop 将 LLM generation latency 从 400s 降到 273.9s,减少 31.5%;总时延从 10:14 降到 8:06;throughput 从 7.13 提升到 9.01 item/s。
- 在 LLaVA-OV-7B 上,V2Drop 将 LLM generation latency 从 752.2s 降到 193.8s,减少 74.2%;throughput 提升到 0.72 item/s。
- 与 SparseVLM 相比,V2Drop 避免了显著的 peak memory 增长;作者特别指出 SparseVLM 在 MVBench 上会因 merging 策略和显式 attention computation 导致峰值显存上升 54.8%。
Table 5. Efficiency comparison on image/video understanding.
| Methods | LLM Generation↓ | Model Generation↓ | Total Latency↓ | GPU Peak Memory↓ | Throughput↑ | Performance↑ |
|---|---|---|---|---|---|---|
| Upper Bound, 576 Tokens (100%) | ||||||
| LLaVA-1.5-7B | 400 | 558 | 10:14 | 15566 | 7.13 | 64.6 |
| Random | 270.4 (↓32.4%) | 425.9 (↓23.7%) | 8:02 (↓21.5%) | 15045 (↓3.3%) | 9.08 (↑1.27×) | 59.1 (91.5%) |
| FastV | 294.0 (↓26.5%) | 449.7 (↓19.4%) | 8:26 (↓17.6%) | 16139 (↑3.7%) | 8.65 (↑1.21×) | 56.1 (86.8%) |
| SparseVLM | 288.2 (↓28.0%) | 443.5 (↓20.5%) | 8:20 (↓18.6%) | 19229 (↑23.5%) | 8.75 (↑1.23×) | 60.0 (92.9%) |
| PDrop | 279.6 (↓30.1%) | 429.7 (↓23.0%) | 8:09 (↓20.3%) | 15197 (↓2.3%) | 8.95 (↑1.25×) | 61.1 (94.6%) |
| V2Drop | 273.9 (↓31.5%) | 429.3 (↓23.1%) | 8:06 (↓20.8%) | 15046 (↓3.3%) | 9.01 (↑1.26×) | 61.8 (95.7%) |
| Upper Bound, All Tokens (100%) | ||||||
| LLaVA-OV-7B | 752.2 | 1201.6 | 32:02 | 17686 | 0.52 | 56.9 |
| Random | 190.9 (↓74.6%) | 639.0 (↓46.8%) | 23:09 (↓27.7%) | 16298 (↓7.8%) | 0.72 (↑1.38×) | 54.6 (96.0%) |
| FastV | 315.9 (↓58.0%) | 781.1 (↓35.0%) | 25:05 (↓21.7%) | 24619 (↑39.2%) | 0.67 (↑1.29×) | 55.5 (97.5%) |
| SparseVLM | 493.8 (↓34.4%) | 960.9 (↓20.0%) | 30:12 (↓5.7%) | 27378 (↑54.8%) | 0.55 (↑1.06×) | 56.4 (99.1%) |
| PDrop | 256.3 (↓65.9%) | 719.0 (↓40.2%) | 23:18 (↓27.3%) | 24371 (↑37.8%) | 0.71 (↑1.36×) | 55.3 (97.2%) |
| DyCoke | 249.2 (↓66.7%) | 713.5 (↓40.6%) | 23:25 (↓26.9%) | 16298 (↓7.8%) | 0.71 (↑1.36×) | 49.5 (87.0%) |
| V2Drop | 193.8 (↓74.2%) | 642.4 (↓46.5%) | 23:13 (↓27.5%) | 16298 (↓7.8%) | 0.72 (↑1.38×) | 56.4 (99.1%) |
4.2. Ablation Study
Effects of Variation Metric
Figure 6 比较了三种 variation metric:Cosine Similarity、L1 Norm、L2 Norm,并与 FastV 对照。结论是三种 variation-based pruning 都能在平均性能上超过 FastV,说明这种“看 token 变化而不是看 attention 分数”的思路本身就更稳健。进一步看 throughput,L2 Norm 在性能与效率之间最均衡,因此被设为默认配置。
Table 7. Supplementary results on variation metric selection. Throughput with 128 retained tokens on LLaVA-1.5-7B.
| Methods | MME | GQA | MMBench | SQA |
|---|---|---|---|---|
| LLaVA-1.5-7B | 8.02 | 7.5 | 7.13 | 6.9 |
| FastV | 9.46 (1.18×) | 8.68 (1.16×) | 8.65 (1.21×) | 8.14 (1.18×) |
| Cosine Similarity | 9.95 (1.24×) | 9.13 (1.21×) | 8.90 (1.25×) | 8.14 (1.18×) |
| L1 Norm | 10.16 (1.27×) | 9.23 (1.23×) | 9.01 (1.26×) | 8.49 (1.23×) |
| L2 Norm | 10.11 (1.26×) | 9.18 (1.22×) | 9.01 (1.26×) | 8.42 (1.22×) |
Table 9. Supplementary results on variation metric selection.
| Methods | MME | POPE | MMBench | GQA | TextVQA |
|---|---|---|---|---|---|
| LLaVA-1.5-7B | 1862 | 85.9 | 64.6 | 61.9 | 58.2 |
| FastV | 1490 | 49.6 | 56.1 | 67.3 | 67.3 |
| Cosine Similarity | 1718 | 55.2 | 61.8 | 69.2 | — |
| L1 Norm | 1698 | 56.1 | 60.9 | 68.7 | — |
| L2 Norm | 1712 | 56.3 | 61.8 | 68.8 | — |
这里的核心信息是:三种 variation metric 的差别并不大,说明 V2Drop 的主要收益来自“variation 视角”本身,而不是某个特殊指标;其中 L1/L2 的 throughput 较好,L2 是默认选择。
Effects of Token Dropping across Different Layers
Figure 8 研究了在不同 LLM transformer layers 上执行 token dropping 的效果。作者采用了多个 pruning layer 组合进行测试,发现 V2Drop 在不同层组合下都较为鲁棒,且在 192 retained tokens 的设置下平均性能能达到 vanilla 的 97.3%。相比之下,FastV 和 SparseVLM 对层选择更敏感,而且 SparseVLM 的 peak memory 明显更高。
Table 6. Supplementary results on pruned layers selection. Performance with 192 retained tokens on LLaVA-1.5-7B.
| Benchmark | Vanilla | Pruned Layers (4,14,30) | (3,14,29) | (3,15,27) | (3,16,24) | (3,17,22) | (2,16,21) | FastV | SparseVLM | PDrop |
|---|---|---|---|---|---|---|---|---|---|---|
| GQA | 61.9 | 57.8 | 58.6 | 58.5 | 58.8 | 58.5 | 57.9 | 52.7 | 57.1 | 57.6 |
| SQA | 69.5 | 68.9 | 69.1 | 69.3 | 69.1 | 69.3 | 69.5 | 67.3 | 68.8 | 68.7 |
| POPE | 85.9 | 86.3 | 85.0 | 85.1 | 85.0 | 85.1 | 83.9 | 64.8 | 82.3 | 83.6 |
| MME | 1862 | 1753 | 1826 | 1847 | 1813 | 1826 | 1759 | 1612 | 1766 | 1721 |
| MMB | 64.6 | 63.2 | 63.4 | 63.7 | 63.5 | 63.7 | 62.8 | 61.2 | 63.2 | 62.5 |
| TextVQA | 58.2 | 53.1 | 54.0 | 54.8 | 55.2 | 55.6 | 54.8 | 52.5 | 56.1 | 56.1 |
| Avg. (%) | 100.0% | 96.0% | 97.0% | 97.5% | 97.3% | 97.6% | 96.2% | 88.2% | 96.0% | 95.8% |
这里可以看出,V2Drop 在不同 pruning layer 组合上波动很小,最优配置(3,17,22)达到 97.6%,说明“在哪几层剪”不会严重影响整体效果。
Effects of Progressive Token Dropping
Figure 9 对比了 progressive dropping 与 one-time dropping。结果显示 progressive dropping 明显更优,尤其在 MME 和 POPE 上分别提升 5.9% 和 9.3%。其原因在于:逐步丢弃能让模型在多个层次上重新筛选 token,避免一次性删除过多关键信息,从而更稳妥地保留视觉语义。
Table 8. Supplementary results on effects of progressive token dropping. Performance with 192 retained tokens on LLaVA-1.5-7B.
| Methods | MME | POPE | MMBench | GQA | TextVQA |
|---|---|---|---|---|---|
| LLaVA-1.5-7B | 1862 | 85.9 | 64.6 | 61.9 | 58.2 |
| One-time dropping | 1717 | 77.1 | 60.6 | 57.1 | 55.2 |
| Progressive dropping | 1826 | 85.1 | 63.7 | 58.5 | 55.9 |
4.3. Visualizations
Figure 7 展示了 TextVQA 上的 token compression 可视化结果。作者从左到右展示不同层剪枝后的图像压缩效果:FastV 使用 one-time dropping,会在后续层保留一些冗余 token;SparseVLM 虽然采用 progressive dropping,但仍然存在 positional bias,倾向于保留后序 token,因而会丢失一些前部重要信息;而 V2Drop 则依据 variation 逐步保留关键区域,能更稳定地锁定语义核心。
Figure 10 提供了更多真实场景下的可视化案例,覆盖诸如品牌识别、文本阅读、动作理解等多种 TextVQA 场景。灰色 mask 表示被丢弃的 token。作者特别指出,在关键区域位于左下、右上、左上等不同位置的情况下,V2Drop 仍能准确保留对应区域,说明 token importance 与 semantic relevance 的对应关系能够通过 variation metric 被稳定识别。
5. Conclusion
LVLM 在推理阶段会消耗大量计算资源,核心原因是视觉 token 过多。现有 token compression 方法往往依赖 attention weights,或者引入 positional bias,从而限制了实际效果与对 efficient operators 的兼容性。本文提出 V2Drop,从 token variation 的角度重构 token importance 的定义,证明视觉 token variation 具有 task-agnostic 特性,因此可以在不依赖 attention weights 的情况下进行压缩,也不容易受到位置偏置影响。V2Drop 通过 progressively removing minimal-variation tokens 实现 LVLM inference acceleration,并在多种 benchmark 上证明了它能有效平衡性能与效率。
Supplementary Material
作者在附录中提供了更详细的实验设置、额外实验结果、算法细节、对 content-agnostic positional bias 的进一步讨论,以及更完整的理论分析。
A. Detailed Experimental Settings
Benchmark Details
作者在多个多模态理解 benchmark 上评估 V2Drop,具体如下:
- GQA:包含 scene graphs、questions 和 images,用于测试视觉场景理解与组合推理能力。
- MMBench:采用三层层次结构与 20 个能力维度,综合评估 perception 和 reasoning。
- MME:包含 14 个子任务,通过人工构造 instruction-answer pairs 评估 perceptual 与 cognitive 能力,并尽量减少数据泄露问题。
- POPE:以 object presence 二分类问题评估 hallucination,使用 accuracy、recall、precision 和 F1。
- ScienceQA:覆盖自然、语言和社会科学,强调多步推理与多模态理解。
- TextVQA:测试模型识别图像中文字并进行推理的能力。
- AI2D:科学图表与问答数据集,重点考察视觉空间推理。
- MMStar:高分辨率图像集,强调空间、时间与 commonsense reasoning。
- MVBench:20 项视频理解任务,要求深度 temporal understanding。
- VideoMME:900 个视频、2700 个多选题,持续时间从 11 秒到 1 小时,并划分为 short / medium / long 子集。
Baseline Models
- LLaVA-1.5:通过视觉指令微调和两阶段训练提升多模态理解能力,在视觉推理、OCR 和 multimodal dialogue 上表现强劲。
- Qwen2-VL:强调任意分辨率输入与 scaling laws,在文档解析、OCR、视觉推理和视频理解上具有很强表现。
- LLaVA-OneVision:统一单图、多图与视频任务,把视频视为长视觉 token 序列,以支持 image-video task transfer。
Comparison Methods
- ToMe:在 ViT 层通过轻量 matching 合并相似 token。
- LLaVA-PruMerge:结合 pruning 和 merging,基于 CLS-patch attention 和聚类来压缩 token。
- FastV:利用 attention maps 在早期层执行 token pruning。
- DART:基于 duplication-aware 机制,按冗余程度而非传统 importance score 选择 token。
- HiRED:基于 CLS token attention 给不同图像区域分配预算。
- PDrop:采用 pyramid-like progressive token dropping。
- SparseVLM:通过 cross-modal attention 与 adaptive sparsity ratio 进行 token sparsification,并引入 token recycling。
- DyCoke:面向视频的大模型方法,先按时间维度 prune 相似 token,再利用 attention weights 压缩 KV cache,但其依赖显式 attention 权重,因此不兼容更高效的 attention operator。
Implementation Details
实验在 NVIDIA A100-PCIe-80GB 上完成,使用 Python 3.10、PyTorch 2.1.2、CUDA 12.1。所有 baseline 设定都遵循原论文配置。
Experimental Parameter Details for V2Drop
在 LLaVA-1.5-7B 上,作者采用三阶段 pruning,位于 layer 3、17、22。具体压缩比例为:
- 维持 192 tokens 时,在三处层分别剪去 50% / 70% / 100% 的视觉 token;
- 维持 128 tokens 时,剪去 72% / 75% / 100%;
- 维持 64 tokens 时,剪去 95% / 95% / 100%。
这说明作者并不是均匀剪枝,而是按层深和剩余 token 数制定不同压缩强度,以兼顾浅层信息保留与深层冗余去除。
B. Additional Experimental Results
Supplementary Results on Variation Metric Selection
Table 7 和 Table 9 进一步给出了三种 variation metric 在多个数据集上的 throughput 与 performance。结果表明,variation-based pruning 相比 FastV 这类 attention-score-based pruning,不但性能更好,而且吞吐也更高,进一步说明 V2Drop 的稳健性。作者还指出,L2 Norm 是默认选择,因为它兼顾了效果和实现简洁性。
Supplementary Results on Pruned Layers Selection
Table 6 的结果说明,不同 pruning layer 组合都会带来相近的效果,尤其在 192 retained tokens 下,V2Drop 的平均表现维持在 96%~97.6% 之间,证明它对 layer scheduling 不敏感。换句话说,V2Drop 的效果不是建立在某个“神奇层号”上,而是来自 variation 作为 token importance 信号的有效性。
Supplementary Results on Effects of Progressive Token Dropping
Table 8 清晰表明 progressive dropping 优于 one-time dropping,说明“先粗后细”的逐步筛选比一次性硬删更稳健。这也是 V2Drop 设计 multi-stage progressive dropping 的直接经验依据。
More Visualizations of Token Compression
Figure 10 提供了更多样化场景:例如摄像机品牌、酒类品牌、事件识别、食物识别、书籍是否为 reference book、书名、国家队、角色生存、午餐盒偏好、专辑名等。作者用这些案例说明,V2Drop 在不同空间位置、不同语义类型的关键区域上都能较好地定位重要 token,并且与 semantic relevance 保持一致。
C. Algorithm Details of V2Drop
作者在附录中给出了算法 1 的完整流程。V2Drop 的输入包括:视觉 tokens $F_v \in \mathbb{R}^{M \times D’}$、dropping layers $L={l_1,l_2,\ldots,l_K}$ 以及各层对应的 compression targets ${K_{l_1},K_{l_2},\ldots,K_{l_K}}$;输出是压缩后的视觉 tokens。算法的基本流程如下:
-
初始化当前 token 数量 $M_{\text{curr}} \leftarrow M$。
-
遍历 LLM 的每一层 $l$。
-
若当前层属于预设 pruning layers,则:
- 计算每个 token 的 variation score: $$ s_i^{(l)} \leftarrow |f_i^{(l)} - f_i^{(l-1)}|_2 $$
- 汇总得到 $S^{(l)}={s_1^{(l)},s_2^{(l)},\ldots,s_{M_{\text{curr}}}^{(l)}}$;
- 按 score 降序排序,取前 $K_l$ 个 token;
- 将保留 token 作为新的 $F_{\text{curr}}^v$,并把 $M_{\text{curr}}$ 更新为 $K_l$。
-
若当前层不属于 pruning layers,则直接把 $F_{\text{curr}}^v$ 输入当前 Transformer layer。
-
最终返回压缩后的 $F_{\text{curr}}^v$。
更直白地说:V2Drop 就是在几个关键层里“看谁变化大就留下谁,变化小就删掉谁”,然后继续把这些保留下来的 token 送到后续层处理。
D. More Discussions about Content-agnostic Positional Bias
作者进一步分析了 attention-guided 方法为何会产生 content-agnostic positional bias。Figure 2 和 Figure 3 的结果说明:即使某些重要区域确实获得较高 attention score,这些方法仍然会过度偏向序列末端 token,导致前面真正有用的信息被误删,最终造成 multimodal hallucination。作者在 TextVQA、POPE 和 MME 上按 token index 分段统计保留概率,发现 FastV、SparseVLM 等方法呈现明显的 end-of-sequence bias。
与之相反,variation-aware evaluation 更接近自然的空间分布:它不是问“这个 token 在序列里靠前还是靠后”,而是问“这个 token 在 LLM 内部变化得是否足够明显”。因此它更容易保留真正与语义相关的区域,并且不会因为绝对位置而系统性偏置。作者由此强调,V2Drop 的优势不仅在于压缩本身,更在于它改变了“重要性”的评估范式。
E. Suppleymentary Theoretical Analysis
E.1. Smoothness Assumption
作者假设模型 $f$ 在表示空间中具有足够的局部光滑性,使得 Taylor 展开中的二阶余项满足:
$$ |R_j| = O(|\Delta x_j^{(t)}|^2). $$
这一假设在 Transformer-based LVLM 中是合理的,原因包括:
- residual connections 限制层间变化,使 $|\Delta x_j^{(t)}|$ 相对稳定;
- layer normalization 限制 token 表示范围,从而约束高阶导数;
- GELU、SiLU 等平滑激活函数保证二阶连续性。
因此,在足够小的局部扰动下,二阶项可忽略,从而得到:
$$ |\Delta f_j| \approx |J_j|_{\text{op}} \cdot |\Delta x_j^{(t)}|. $$
这一步是理论主线的关键,因为它把“token 表示变化量”直接连接到了“输出变化量”。
E.2. Justification of Bounded Jacobian Assumption
作者在 corollary 中进一步假设 Jacobian operator norm 有下界 $|J_j|_{\text{op}} \ge \mu > 0$。其合理性主要来自三点:
- Information flow in Transformers:注意力机制使每个 token 通过多头 attention 与 FFN 参与输出形成,softmax 归一化保证 token 的贡献一般不会完全消失;
- Residual connections preserve gradients:残差结构 $x^{(t+1)} = x^{(t)} + \text{Block}(x^{(t)})$ 使梯度可沿 identity path 传播,不易消失;
- Layer normalization stabilizes gradients:layer norm 把梯度规模控制在有限范围内。
如果某些 token 的 $|J_j|_{\text{op}} \approx 0$,说明这些 token 对输出本就几乎没有影响,那么无论其 variation 多大,删除它们也不会带来显著性能损失;因此这并不会破坏 V2Drop 的基本逻辑。
E.3. Connection to V2Drop Algorithm
作者给出了一个更强的优化视角:在有 $n$ 个 token 的情况下,希望选择要删除的 token 集合 $S_{\text{drop}}$,使得删除后总输出扰动最小:
$$ S^**{\text{drop}} = \arg\min*{S \subseteq [n], |S|=\alpha n} \sum_{j \in S} |\Delta f_j|. $$
结合 Theorem 1 和 Jacobian 下界假设,有:
$$ \sum_{j \in S}|\Delta f_j| \approx \sum_{j \in S}|J_j|{\text{op}} \cdot |\Delta x_j^{(t)}| \in \left[\mu \sum{j \in S}|\Delta x_j^{(t)}|,; M \sum_{j \in S}|\Delta x_j^{(t)}|\right]. $$
因此,最小化输出扰动可以近似转化为最小化 variation 之和:
$$ S^**{\text{drop}} \approx \arg\min*{S \subseteq [n], |S|=\alpha n} \sum_{j \in S}|\Delta x_j^{(t)}|. $$
这正好解释了 V2Drop 的策略为何合理:丢弃 variation 最小的 token,近似等价于丢弃对输出影响最小的 token。 而且这种选择只需要简单的 L2 norm 计算,计算成本极低。
E.4. Connection to information flow
在 Transformer 的 residual 结构中:
$$ x_j^{(t+1)} = x_j^{(t)} + \text{Attn}(x_j^{(t)}) + \text{FFN}(x_j^{(t)}), $$
因此:
$$ \Delta x_j^{(t)} = \text{Attn}(x_j^{(t)}) + \text{FFN}(x_j^{(t)}). $$
这意味着 variation 实际上对应每层对 token 的“有效更新量”。变化大的 token,说明它正在被网络积极 refinement,携带并传播任务相关信息;变化小的 token 则更像是被网络“忽略”的部分,因此可以安全丢弃。这个解释把 variation 与 Transformer 中的信息流动机制直接对应起来,也进一步说明了为什么 V2Drop 会比 attention-guided pruning 更符合模型内部计算过程。