
Conference: INFOCOM'26
1. Motivation (动机)
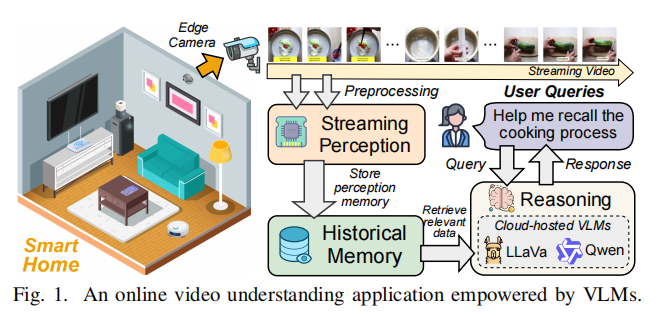
图 1 抽象了一个部署在智能家居场景中的基于VLM(视觉-语言模型)的在线视频理解应用。在这个应用中,家庭成员可以随时发起针对当前或历史录制视频片段的查询。该应用包含三个关键模块:
- 流媒体感知模块 (Streaming Perception Module): 配备板载计算能力的边缘摄像头持续捕获家庭场景的视频,并即时处理多模态数据。
- 历史记忆模块 (Historical Memory Module): 构建历史视频流并存储在记忆数据库中,以支持高效准确地检索与查询相关的信息。
- 推理模块 (Reasoning Module): 在接收到用户查询后,利用云托管的 VLM 进行推理并生成答案,由历史记忆提供上下文基础 (contextual grounding)。

AI 社区中新兴的研究工作(如 [13]–[15])探索了 VLM 在视频理解中的有效性,但大多数工作都侧重于算法性能 (algorithmic performance),而忽略了部署相关的约束 (deployment-related constraints),这限制了它们在边缘智能场景中的直接适用性。
- 纯云端部署 (Fully Cloud-based Deployment):
- 利用强大的服务器端计算来减少设备端处理。
- 缺点: 需要上传整个相关视频 (entire relevant video),导致显著的通信延迟 (communication latency)。图 2 显示,通信延迟可占总响应延迟的 80%,且随着视频时长的增加而大幅增长。
- 边缘-云端策略(边缘执行选择算法)(Edge-Cloud Strategy):
- 一些方法 [3], [13] 通过在推理前执行**帧选择 (frame selection)**来提高准确性。
- 在边缘设备上执行选择算法,只将选定的帧上传到云端,可以显著减少通信开销。
- 缺点: 边缘设备的计算能力有限,导致逐帧处理产生巨大的设备端处理成本 (substantial on-device processing costs),例如高达 924秒 的设备端延迟(图 2)。
- 现有方法的共同限制: 除了通信和计算开销,现有方法固有地受限于离线执行 (offline execution),不适用于涉及在线用户查询并需要**长期上下文记忆 (long-term contextual memory)**的在线流媒体应用。
2. Contribution (贡献)
为解决上述限制,作者提出了 Venus,一种新颖的设备端记忆和检索系统 (on-device memory-and-retrieval system),专为高效在线边缘视频理解而设计。
Venus 具备两个基本能力:
- 记忆 (Memory): 通过嵌入多模态输入并将向量表示插入到历史记忆中,实现实时视频感知 (real-time video perception),支持高效召回和低延迟查询推理。
- 检索 (Retrieval): 支持自然语言查询,实现精确且自适应的关键帧检索 (precise and adaptive retrieval),最大限度地减少传输到云托管 VLM 的数据,从而降低通信和计算开销,实现低延迟响应。
Venus 利用一种新颖的边缘-云解耦架构 (edge–cloud disaggregated architecture),在边缘执行多模态记忆构建和关键帧检索,在云端执行 VLM 推理。该架构包含两个主要阶段:
- 摄取阶段 (Ingestion Stage):
- 边缘摄像头连续记录流媒体视频。
- 应用**场景分割 (scene segmentation)和帧聚类 (frame clustering)来消除冗余,选择簇中心 (cluster centroids)**作为索引帧。
- 索引帧使用**多模态嵌入模型 (MEM)**嵌入为向量表示,并辅以轻量级辅助模型。
- 索引向量及其关联簇中的原始帧构成了支持准确高效召回和检索的分层记忆 (hierarchical memory)。
- 查询阶段 (Querying Stage):
- 接收到查询时激活,查询使用相同的 MEM 编码并计算与记忆中向量的相似性得分。
- 采用采样式策略 (sampling-based strategy)(而非贪婪的 Top-K 算法)来平衡关键帧选择的相关性 (relevance)和多样性 (diversity)。
- 引入阈值驱动的渐进式采样算法 (threshold-driven progressive sampling algorithm),自适应地调整选定帧的数量,实现系统成本和推理准确性之间的灵活权衡。
作者的广泛评估显示,与最先进的方法相比,Venus 在总响应延迟方面实现了 $15\times–131\times$ 的加速,同时保持了相当甚至更优的推理准确性。
主要贡献总结如下:
- 作者重新审视了 AI 社区现有算法的部署限制,并提出了一个边缘-云解耦架构,以服务于基于 VLM 的在线视频理解。
- 作者设计了一个场景分割和聚类模块以实现实时设备端感知。流媒体视频帧被嵌入并组织成分层记忆,以支持准确和高效的召回和检索。
- 作者提出了一个阈值驱动的渐进式采样算法用于关键帧选择,它增强了多样性,并自适应地平衡了系统成本和推理准确性。
- 作者将作者的设计整合并实现为一个系统 Venus,并在真实的边缘设备上进行了评估。作者的广泛评估显示,与基线方法相比,Venus 在总响应延迟方面实现了 $15\times–131\times$ 的加速。
3. BackGround (背景)
3.1 Limitations of Existing VLM-based Video Understanding (现有基于 VLM 视频理解的局限性)
现有基于 VLM 的视频理解方法普遍忽略了部署相关的约束,这阻碍了它们在边缘智能场景中的直接适用性。
- LLaVA-OneVision [14]: 逐帧处理视频,不进行任何 token 缩减,导致一小时 8 FPS 的视频产生约 600 万个 token,引入了显著的视频传输和推理开销。
- Video-RAG [15] 和 MDF [21]: 采用统一采样 (Uniform Sampling) 或 冗余帧移除 (Redundant Frame Removal) 等查询无关策略 (query-agnostic strategies) 来减少冗余。这种方法假设帧重要性均等,容易在复杂场景中表现不佳,采样过稀可能错过关键内容,过度采样则增加传输和推理成本。
- BOLT [13] 和 AKS [3] (查询相关方法): 利用视觉-语言相似性识别查询相关帧,使用对比编码器将帧与文本关联。虽然其自适应选择有助于平衡信息量和推理效率,但它们仍需将整个相关视频传输到云端进行处理,导致显著的通信延迟。将这些算法在边缘设备上逐帧执行以减少传输开销,由于边缘设备缺乏运行基于 Transformer 编码器的实时计算能力,对于在线场景是不切实际的。
图 2 比较了现有方法在不同部署策略下的延迟分解。
- Cloud-Only (纯云端): 强大的服务器计算减少了设备端开销,但需要上传整个视频流,导致通信延迟占总响应延迟的 80%。
- Edge-Cloud (边缘-云端,例如 BOLT/AKR): 显著减少了通信开销,但由于边缘设备的计算能力限制,逐帧处理导致高达 924 秒 的设备端延迟。
所有上述方法都限制于离线执行,不适合需要在线查询和长期上下文记忆的流媒体场景。
3.2 Our Design Goals (作者的设计目标)
作者的目标是提出一个高效的记忆和检索系统,以解决现有方法的限制:
- 支持实时视频处理,将多模态表示连续注入到历史记忆数据库中,实现高效召回和低延迟的基于查询的推理。
- 支持自然语言查询,并实现准确且自适应地检索记忆中的关键帧和多模态上下文,以最小化发送到云端 VLM 的数据量,从而降低通信和计算开销,实现低延迟响应。
4. EDGE-CLOUD DISAGGREGATED ARCHITECTURE FOR ONLINE VIDEO UNDERSTANDING (在线视频理解的边缘-云解耦架构)
4.1 An Edge-Cloud Disaggregated Architecture (边缘-云解耦架构)
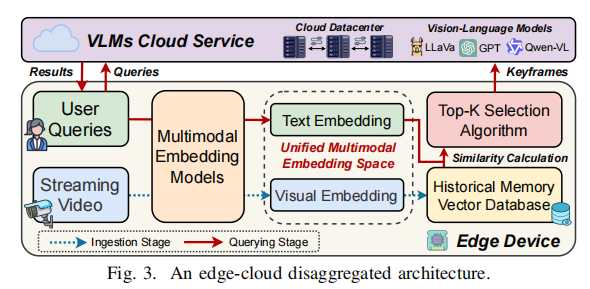
图 3 展示了作者提出的工作流程,包含两个主要阶段:摄取阶段 (Ingestion Stage) 和 查询阶段 (Querying Stage)。
- 摄取阶段 (Ingestion Stage - 边缘设备):
- 摄像头连续捕获视频流。
- 每个视频帧经 MEM (Multimodal Embedding Model) 处理,生成统一的图像-文本嵌入空间内的向量表示。
- 向量表示随后插入到**向量数据库 (Vector Database)**中,构建索引结构以加速相似性搜索。
- 查询阶段 (Querying Stage - 边缘到云端):
- 用户自然语言查询通过相同的 MEM 映射到统一多模态嵌入空间。
- 查询向量通过相似性计算与向量数据库中存储的索引向量进行比较。
- 检索 Top-K 最相关的视频帧。
- 检索到的帧随后传输给云托管的 VLM 服务(如 LLaVA、GPT、Qwen-VL)进行推理,生成最终推理结果。
4.2 Challenges in Naive Deployment (朴素部署中的挑战)
上述架构虽然概念简单,但在现实世界部署中面临几个关键挑战:
1. High latency hinders real-time embedding and ingestion (高延迟阻碍实时嵌入和摄取)

- 问题: 典型边缘摄像头以 25–60 FPS 捕获视频,对每帧应用 MEMs 的开销在资源受限的边缘设备上是巨大的。
- 结果: 输入 FPS 超过设备嵌入吞吐量时,帧会积压,查询到达时必须先嵌入所有积压帧,引入延迟。
- 可行性评估 (Figure 4): * 在原生帧率(如 25 FPS)下,嵌入延迟超过 212 分钟,在线查询不切实际。
- 实时嵌入的阈值 FPS 极低:Jetson TX2 为 0.3 FPS;Jetson Xavier NX 为 0.7 FPS;Jetson AGX Orin 为 1.8 FPS。
- 风险: 激进的统一降采样会导致严重信息损失,可能丢失关键帧,导致视频理解失败。
2. Excessively redundant frames overwhelm the memory database and degrade retrieval performance (过度冗余的帧淹没记忆数据库并降低检索性能)
- 问题: 嵌入和保留所有帧虽然能保留细节,但会因记忆数据库中包含大量时间相邻且视觉相似的帧,导致检索算法返回冗余、近似重复的内容。
- 结果 (Figure 5(a)): 准确性并非随帧数线性增加,实验显示在 Video-MME 短片段上,保留 64 帧 时常能达到最高准确性。
- 副作用: 冗余帧增加了数据库的索引复杂性和存储开销。
3. Lack of diversity and adaptivity in Top-K selection algorithm (Top-K 选择算法缺乏多样性和自适应性)
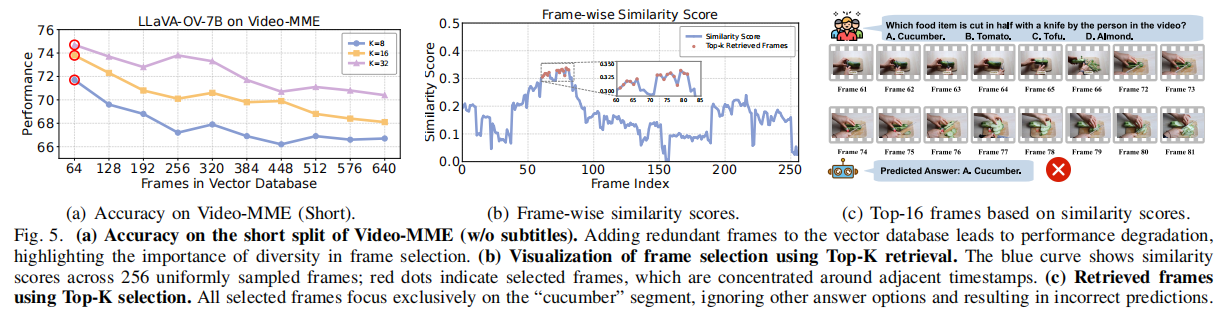
- 缺乏多样性: Top-K 采样通常选择时间上相邻的冗余帧,尤其当数据库密集填充时。检索结果可能缺乏上下文多样性,无法捕获准确视频问答所需的场景覆盖范围。例如,图 5(b) 显示 Top-K 集中在索引 75,而忽略了索引 190-210 的相关场景。
- 缺乏自适应性: Top-K 需要手动指定、静态的 $K$ 值,难以适应不同查询、网络条件和延迟要求下的自适应调整。
5. VENUS SYSTEM DESIGN (Venus 系统设计)
5.1 Venus System Overview (Venus 系统概览)
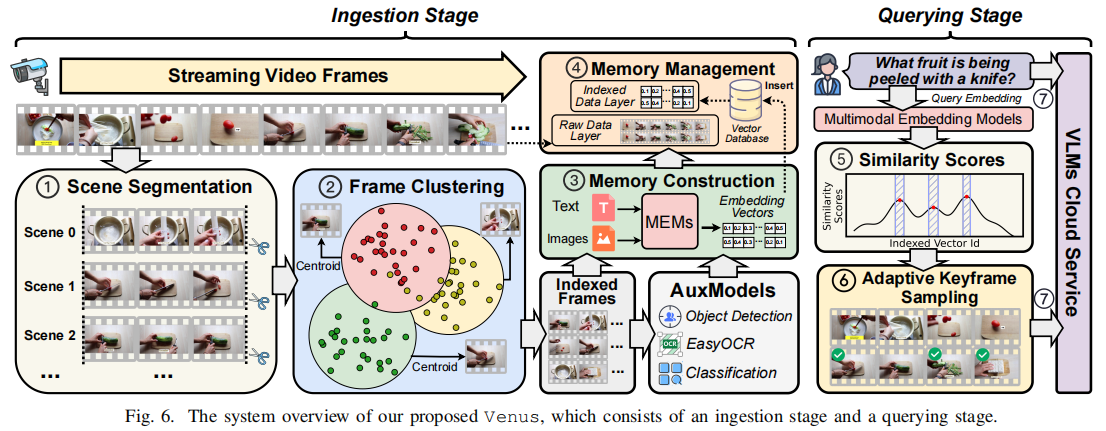
Venus 的核心在于其边缘-云解耦架构和两个主要阶段:
- 摄取阶段 (Ingestion Stage) - 边缘端:
- 实时感知和过滤 (Step 1): 场景分割和帧聚类,选择索引帧 $\mathcal{K}$。
- 多模态嵌入 (Step 2): 索引帧和辅助提示经 MEMs 嵌入为向量 $\mathcal{O}$。
- 记忆构建 (Step 3): 索引向量和原始帧形成分层记忆 (Hierarchical Memory)。
- 查询阶段 (Querying Stage) - 边缘到云端:
- 查询嵌入 (Step 4): 用户查询 $Q$ 经 MEM 编码并计算与索引向量的相似性分数。
- 自适应关键帧检索 (Step 5 - AKR): 采用自适应采样算法确保选择帧的相关性和多样性。
- VLM 推理 (Step 6): 查询和选定的关键帧发送到云端 VLM 进行推理。
5.2 Scene Segmentation and Clustering for Frame Filtering (用于帧过滤的场景分割和聚类)
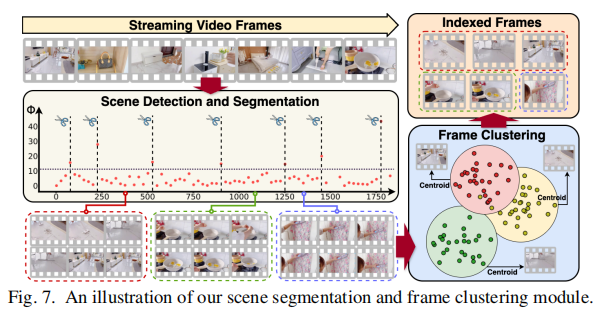
目的: 在保证信息完整性的前提下,减少流媒体视频的冗余,确保实时设备端感知 (real-time on-device perception)。
1) 场景分割 (Scene Segmentation)
- 方法: 采用基于时间差分 (temporal difference)的轻量级启发式算法 (lightweight heuristic algorithm)。
- 机制: 通过比较连续帧之间的差异来高效识别场景边界 (scene boundaries)。
- 优势: 计算开销极小,可以实时运行在资源受限的边缘设备上。
- 输出: 视频流 $\mathcal{F}$ 被分割成场景分区 (scene partitions) $\mathcal{M}={m_{1}, m_{2}, \dots}$。
2) 帧聚类 (Frame Clustering)
- 目的: 在每个场景分区内,以更细粒度分组视觉相似的帧,进一步减少冗余;并选择**簇中心 (cluster centroids)**作为稀疏索引的代表帧。
- 策略: 采用增量聚类策略 (incremental clustering strategy)。
- 机制: 对于场景分区 $m_{i}\in\mathcal{M}$:
- 第一个帧 $f_{1}$ 分配给初始簇 $c_{1}$。
- 新帧 $f_{i}$ 展平像素值向量后,计算与每个现有簇中心的 $L_{2}$ 距离。
- 如果最小 $L_{2}$ 距离小于预定义阈值 $\delta$,将 $f_{i}$ 添加到最近的簇并更新簇中心 (update the cluster centroid)。
- 否则,创建一个新的簇 $c_{j}$。
- 索引帧选择 $\mathcal{K}$: 每个簇的中心帧 (centroid frame) 被选为索引帧 (index frame) $\mathcal{K}={k_{1}, k_{2}, \dots}$。
5.3 Memory Construction and Management (记忆构建与管理)
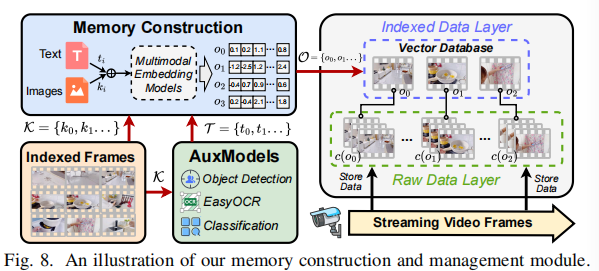
1) Multimodal Embedding (多模态嵌入)
- 辅助模型 (AuxModels): 一组轻量级模型(如 OCR [36] 和 YOLO [37])。它们根据应用需求配置,输出被格式化为文本模板以构建辅助提示 $\mathcal{T}$ (auxiliary prompts)。
- 嵌入过程: 索引帧 $k_{i}$ 和关联的辅助提示 $t_{i}$ 被送入 MEMs(Multimodal Embedding Models),生成统一图像-文本嵌入空间内的向量表示 $\mathcal{O}$: $$ \mathcal{O}={o_{i}=MEM(k_{i},t_{i})|k_{i}\in\mathcal{K},t_{i}\in\mathcal{T}} \tag{3} $$
2) Hierarchical Memory Management with Semantic Indexing (分层记忆管理与语义索引)
记忆管理架构分为两个层级:
- 原始数据层 (Raw Data Layer): 存储边缘摄像头捕获的原始、未处理格式的流媒体视频帧。作为历史数据的持久档案 (persistent archive),为准确的用户查询推理提供可靠源头。
- 索引数据层 (Index Data Layer): 构建了一个结构化和语义化的索引,存储索引向量 $\mathcal{O}$、它们关联的原始帧元数据(时间戳、位置)和辅助提示 $\mathcal{T}$。索引向量 $\mathcal{O}$ 存储在向量数据库中,实现查询驱动的检索。
5.4 Query-Relevant Keyframe Retrieval (查询相关关键帧检索)
-
步骤 1: 查询嵌入和相似性计算 (Query Embedding and Similarity Calculation):
- 用户查询 $Q$ 通过相同的 MEM 模型嵌入。
- 与稀疏索引帧计算**余弦相似性 (cosine similarity)**分数 $\mathcal{S}$: $$ \mathcal{S}={s_{i}=cos(MEM(Q),o_{i})|o_{i}\in\mathcal{O}} \tag{4} $$
-
步骤 2: 自适应关键帧检索 (Adaptive Keyframe Retrieval - AKR): 采用采样式策略而非贪婪 Top-K,以平衡相关性和多样性。
-
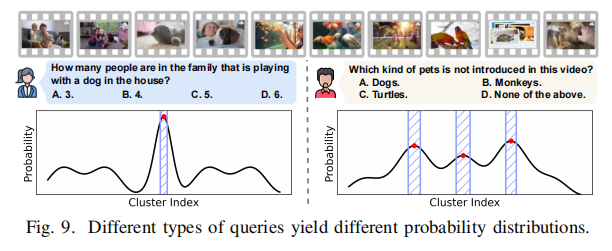
概率分布 $P$: 基于相似性分数 $\mathcal{S}$ 构建一个离散、查询引导的概率分布:
$$ P(i) = \frac{\exp(s_{i}/\tau)}{\sum_{j} \exp(s_{j}/\tau)} \tag{5} $$
其中,$\tau$ 是温度参数 (temperature parameter)。较小的 $\tau$ 强调相关性,分布更集中;较大的 $\tau$ 强调多样性,分布更平坦。
-
采样: 从分布 $P$ 中独立且有放回地 (independently and with replacement)采样 $N_{max}$ 个帧,增加了非 Top-K 高分帧的选中概率,增强了时间多样性**。
-
-
步骤 3: 阈值驱动的渐进式采样算法 (Threshold-driven Progressive Sampling Algorithm):
- 目标: 动态调整选定帧的数量 $N$,在系统成本和推理准确性之间实现灵活权衡。
- 初始阶段: 采样一个固定大小的初始批次 $\mathcal{K}{N{init}}$ 并发送 VLM 推理。
- 迭代阶段 (Progressive Selection):
-
推理质量评估: 推理质量评估器 (Reasoning Quality Evaluator)评估 VLM 的推理结果(如选择题的答案置信度,生成式 QA 的信息熵或语义清晰度)。
-
阈值判断: 如果评估得分低于预定义阈值 $\lambda$,则认为当前帧集不足。
-
渐进式采样: 从排除已选帧 $\mathcal{K}_{N}$ 的剩余分布 $P’$ 中再采样一个较小的增量批次 $\Delta \mathcal{K}$:
$$ \Delta \mathcal{K} \sim P’ $$
-
重复: VLM 使用新的帧集 $\mathcal{K}{N} \cup \Delta \mathcal{K}$ 再次推理,直到达到**最大预算 $N{max}$** 或评估得分达到 $\lambda$ 为止。
-
- 优势: 实现了自适应停止采样和推理,避免了不必要的通信和计算,同时保证了准确性。
6. Implementation and Evaluation (实现与评估)
6.0 Implementation (实现)
Venus 的原型系统和基线已在 PyTorch 之上使用 Python 实现,代码量约为 1000 行 ($\sim1000$ LoC)。
6.1 Experimental Setup (实验设置)
- 边缘测试平台: NVIDIA Jetson AGX Orin, Jetson Xavier NX, 和 Jetson TX2。
- 数据集: 用于 VQA (Video Question Answering) 的 Video-MME [38] (900 视频, 2,700 问题, 部分视频超一小时) 和 EgoSchema [39] (超 5,000 多项选择 QA 对, 基于 250 小时第一人称视频)。所有输入视频统一以 8 FPS 采样。
- 查询模拟: 假设查询在每个视频片段播放后立即到达,模拟在线视频理解场景。
- 模型:
- 云端 VLM: LLaVA-OV-7B [14] 和 Qwen2-VL-7B [40]。
- MEM: 使用 BGE-VL-large [25]。
- 辅助模型 (Auxiliary Models): 使用 EasyOCR [36] 和 YOLO-NAS [42]。
- 基线方法:
- 查询无关: Uniform Sampling, MDF [21], Video-RAG [15]。
- 查询相关: BOLT [13], AKS [3] (采用 Cloud-Only 和 Edge-Cloud 两种部署策略)。
- Vanilla 基线: 使用 Venus 的场景分割和聚类进行记忆构建,但在检索阶段使用贪婪 Top-K 选择算法(固定采样预算 $N=32$)。
6.2 Comparison with Query-Irrelevant Baselines (与查询无关基线的比较)
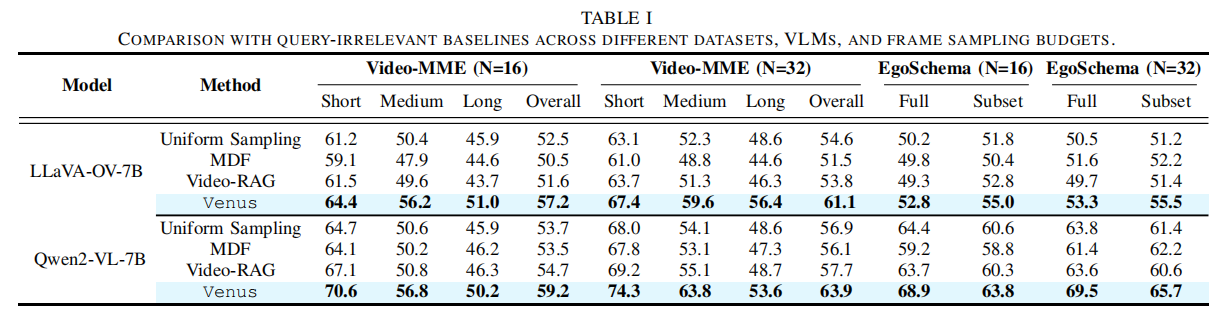
(以 LLaVA-OV-7B 模型, $N=32$ 帧的准确性为例)
| Model | Method | Video-MME (Short) | Video-MME (Medium) | Video-MME (Long) | Video-MME (Overall) |
|---|---|---|---|---|---|
| LLaVA-OV-7B | Uniform Sampling | 63.1 | 48.6 | 52.3 | 54.6 |
| LLaVA-OV-7B | MDF | 61.0 | 48.8 | 44.6 | 51.5 |
| LLaVA-OV-7B | Video-RAG | 63.7 | 51.3 | 46.3 | 53.8 |
| LLaVA-OV-7B | Venus | 67.4 | 59.6 | 56.4 | 60.3 |
- 结论: Venus 在所有 Video-MME 划分和总体准确性上均优于所有查询无关基线。
6.3 Comparison with Query-Relevant Baselines (与查询相关基线的比较)
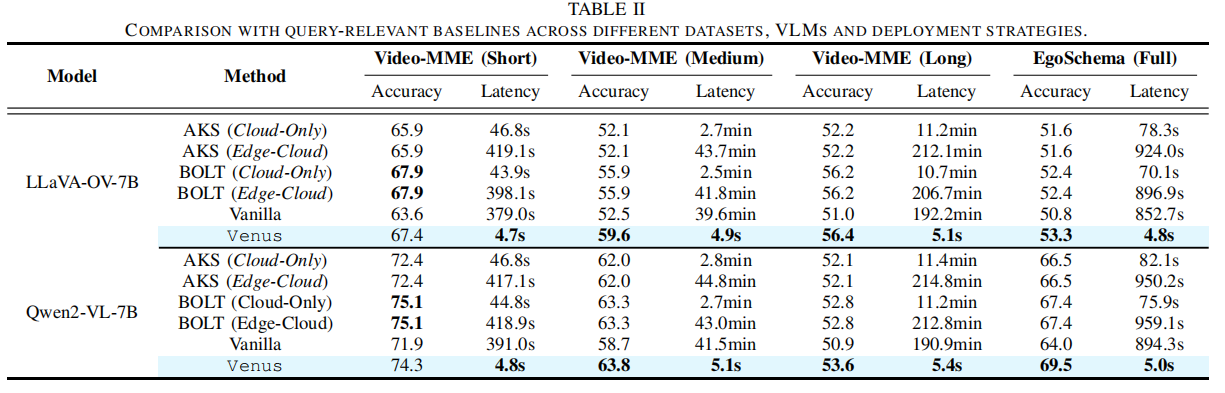
(以 LLaVA-OV-7B 模型为例,准确性/延迟对比)
| Model | Method | Video-MME (Short) Acc./Latency | Video-MME (Medium) Acc./Latency | Video-MME (Long) Acc./Latency | EgoSchema (Full) Acc./Latency |
|---|---|---|---|---|---|
| LLaVA-OV-7B | AKS (Cloud-Only) | 65.9 / 46.8s | 52.1 / 2.7min | 52.2 / 11.2min | 51.6 / 78.38s |
| LLaVA-OV-7B | BOLT (Cloud-Only) | 67.9 / 43.9s | 55.9 / 2.5min | 56.2 / 10.7min | 52.4 / 70.1s |
| LLaVA-OV-7B | AKS (Edge-Cloud) | 65.9 / 419.1s | 52.1 / 43.7min | 52.2 / 212.1min | 51.6 / 924.0s |
| LLaVA-OV-7B | BOLT (Edge-Cloud) | 67.9 / 398.1s | 55.9 / 41.8min | 56.2 / 206.7min | 52.4 / 896.9s |
| LLaVA-OV-7B | Vanilla | 63.6 / 379.0s | 52.5 / 39.6min | 51.0 / 192.2min | 50.8 / 852.7s |
| LLaVA-OV-7B | Venus | 67.4 / 4.7s | 59.6 / 4.9s | 56.4 / 5.1s | 53.3 / 4.8s |
- 准确性: Venus 在 Video-MME (Medium) 上实现最高准确性 (59.6),在其他数据集上与最优基线保持可比或略优。
- 延迟: Venus 在所有数据集上均取得压倒性的最低延迟。与最先进方法相比,实现了 $15\times–131\times$ 的总响应延迟加速。例如,在 Video-MME (Short) 上,Venus (4.7s) 远低于 BOLT (Cloud-Only) 的 43.9s 和 BOLT (Edge-Cloud) 的 398.1s。
6.4 Comparison of Top-K and Sampling-Based Retrieval (Top-K 与采样式检索的比较)

- 目的: 比较 Vanilla 贪婪 Top-K 选择和 Venus 采样式检索在多样性和覆盖范围上的差异(固定预算 $N=8$ 帧)。
- 案例研究 (Figure 10): 对于同一问题,Top-K 选择仅覆盖选项 C 相关内容,而采样式检索则包括与选项 B、C 和 D 相关的内容。
- 结论: 采样式检索提供了更广的覆盖范围和时间多样性,能帮助模型排除不正确选项。
6.5 Ablation Study on Adaptive Keyframe Retrieval (自适应关键帧检索的消融研究)
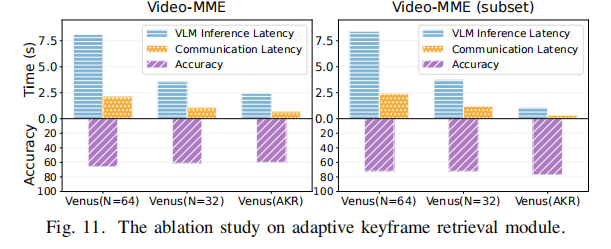
- 目的: 评估 AKR (Adaptive Keyframe Retrieval) 模块的影响。
- 发现: Venus with AKR ($N_{max}=32$) 在推理准确性方面与固定预算 $N=32$ 或 $N=64$ 的采样方法保持可比性。
- 优势: AKR 实现了最低的平均延迟和通信开销。这证明 AKR 能够根据评估得分自适应地停止采样和推理,避免了不必要的帧传输和 VLM 推理,同时保证了准确性。
6.6 End-to-end Query Latency Breakdown (端到端查询延迟分解)
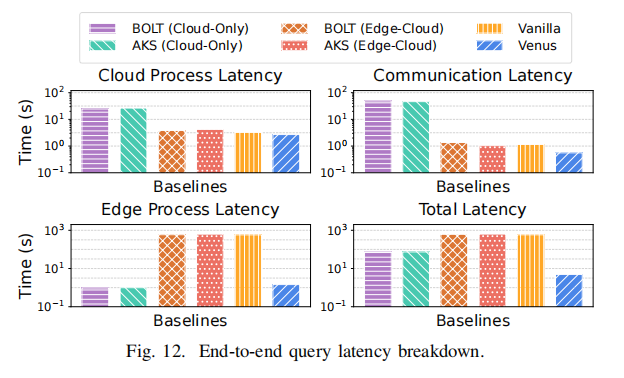
- 结果 (Figure 12): * Venus 在所有处理步骤中始终实现最低延迟。
- 总加速比: 相比基线,Venus 实现了 $15\times–131\times$ 的总响应延迟加速。
- 延迟优势原因:
- Ingestion Stage: Venus 的场景分割和聚类实现了实时设备端嵌入和记忆构建,确保在查询到达时只需嵌入查询文本,从而大幅减少了设备端延迟。
- Querying Stage: AKR 自适应选择关键帧进行上传,显著减少了通信和云端 VLM 推理延迟。
7. Conclusion (结论)
Venus 采用了一种边缘-云解耦架构 (edge–cloud disaggregated architecture),实现了实时设备端感知、分层历史记忆构建和高效关键帧检索。系统仅将最相关的上下文转发给云托管的 VLM 进行准确推理。作者的广泛评估表明,与最先进的方法相比,Venus 在总响应延迟方面实现了 $15\times–131\times$ 的加速。