
Conference: EMNLP'25
Github: https://github.com/xuyang-liu16/VidCom2
1. Introduction
视频大语言模型(VideoLLMs)在视频理解任务(如视频问答、视频推理、时序理解等)上表现出色,但其推理效率受到视觉 token 数量过多的严重制约。具体而言,当前主流 VideoLLM 通常将视频拆解为多帧图像,每一帧再由 ViT 等视觉编码器转化为大量 patch-level tokens,这些视觉 tokens 会与文本 tokens 一同送入 LLM 进行跨模态建模。
由于 Transformer 自注意力的复杂度为 $O(N^2)$,当视频帧数 $T$ 和每帧 token 数 $M$ 较大时,总 token 数 $N = T \times M$ 会迅速膨胀,导致推理延迟和显存消耗急剧上升。这一问题在长视频理解和高分辨率视频场景中尤为突出。
作者系统性地分析了现有 VideoLLM token compression 方法,发现其普遍存在两个关键问题:
-
忽视帧间差异性(Frame-level Distinctiveness) 多数方法对所有帧采用统一的压缩比例,默认每一帧“信息密度相同”,从而容易在关键帧上丢失重要视觉线索。
-
工程实现受限(Implementation Constraints) 一些方法依赖特定模型结构(如 ViT 的 [CLS] token)或显式 attention 权重,导致难以兼容现代视觉编码器(如 SigLIP)或高效注意力算子(如 FlashAttention)。
为此,作者总结出 三条 VideoLLM token compression 的设计原则,并提出一种**即插即用(plug-and-play)**的推理加速框架 Video Compression Commander(VidCom2)。
VidCom2 的核心思想是:量化每一帧在整个视频中的“独特性(uniqueness)”,并据此动态调整不同帧的压缩强度,从而在保证信息保真的前提下最大化冗余削减。
大量实验表明,VidCom2 在多种 VideoLLM 架构和 benchmark 上均取得了更优的性能-效率权衡。
在仅保留 25% 视觉 tokens 的情况下,VidCom2 在 LLaVA-OneVision 上仍能保持 99.6% 的原始性能,同时将 LLM 生成延迟降低 70.8%,显示出极高的性价比。
此外,VidCom2 提出的 Frame Compression Adjustment(帧级压缩调度) 机制具备良好的通用性,可作为一个外部模块,与现有 token compression 方法叠加使用,进一步提升整体性能。
2. Motivation

To mitigate this computational burden, researchers have turned to token compression methods (Chen et al., 2024a; Yang et al., 2025), considering the inherent visual redundancy and aiming to minimize redundant visual information.
为缓解 VideoLLM 的计算开销,研究者提出了多种 token compression 方法,基于一个核心观察:视频中存在大量时序与空间冗余,并非所有视觉 tokens 都同等重要。
These approaches can be categorized as pre-LLM (Zhang et al., 2024b) or intra-LLM (Chen et al., 2024a) methods, based on whether compression occurs before or within the LLM.

现有方法大致可分为两类:
- Pre-LLM compression:在视觉 encoder 输出后、送入 LLM 前进行 token 压缩;
- Intra-LLM compression:在 LLM 内部(如特定层)动态丢弃或合并 tokens。
Most of these methods are training-free, enabling plug-and-play inference acceleration for existing VideoLLMs.
多数方法无需额外训练,具备即插即用特性,理论上适合部署到已有 VideoLLM 系统中。
However, despite these efforts, existing token compression methods suffer from two critical issues:
(I) Design Myopia
In human video perception we naturally focus on distinctive frames (e.g., those with significant spatio-temporal changes) while ignoring repetitive and redundant visual information (Ma et al., 2025).
人类在观看视频时,天然会聚焦于发生显著变化的关键帧,而对高度重复的画面自动忽略。
By contrast, most existing token compression methods apply a uniform compression strategy across all frames, treating each one as equally informative.
然而,大多数方法对所有帧使用统一压缩比例,默认每一帧的信息价值相同。
Even recent VideoLLM-specific method DyCoke (Tao et al., 2025) exhibits this limitation by grouping every four consecutive frames into a fixed window and compressing them identically.
即便是针对 VideoLLM 设计的 DyCoke,也采用固定窗口(如每 4 帧)进行一致压缩,忽略了帧间差异。
Figure 1 further illustrates the critical nature of this issue: removing 24 redundant frames does not affect the accurate response of the LLaVA-OneVision, whereas dropping just 8 unique frames causes it to fail.
Figure 1 直观展示了这一问题:删除 24 个冗余帧对模型预测几乎无影响,而仅删除 8 个关键帧就会导致模型失败,尽管数量更少。
This contrast shows that uniform compression risks discarding critical information in unique frames.
这表明均匀压缩极易误伤关键信息帧。
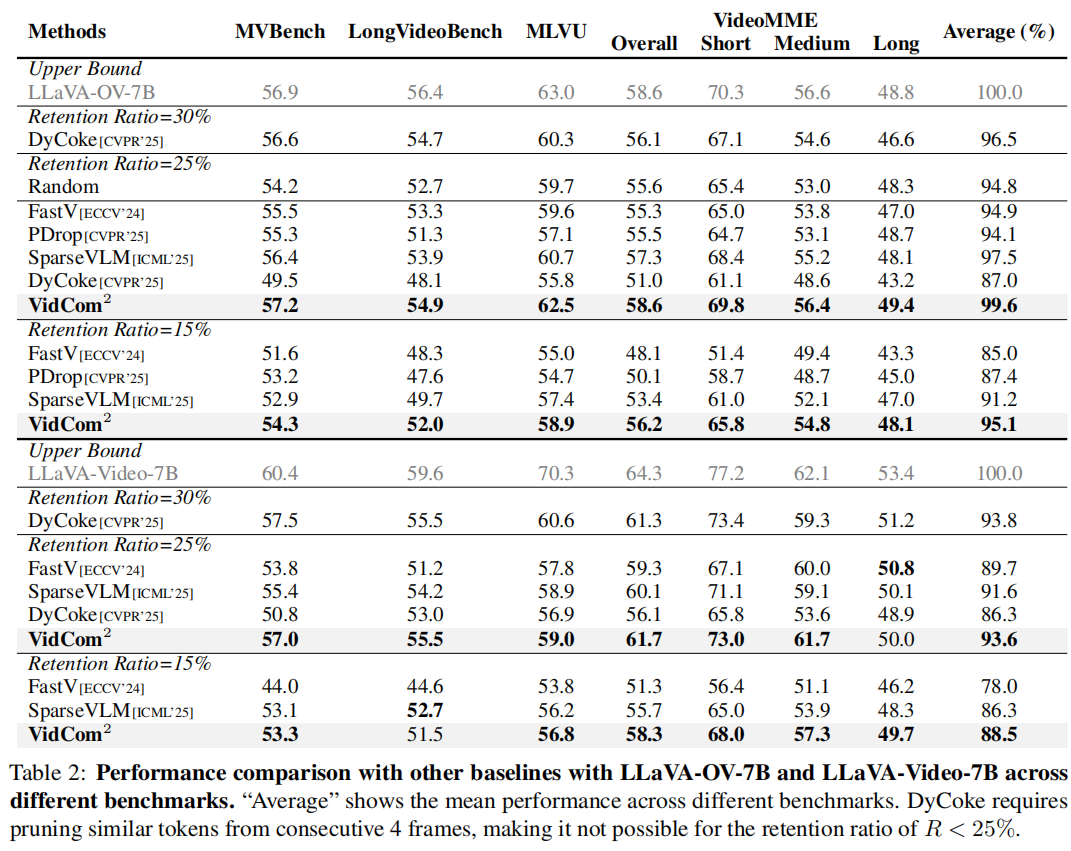
Notably, Table 2 indicates that some methods even underperform random token dropping.
Table 2 中甚至显示,部分方法的效果不如随机丢 token,说明其压缩策略存在明显缺陷。
(II) Implementation Constraints
Beyond design limitations, existing methods face practical constraints.
除设计层面问题外,现有方法在工程实现上也存在严重限制。
Some token compression works rely on [CLS] attention weights in ViT, yet modern VideoLLMs adopt SigLIP without [CLS] token.
一些方法依赖 ViT 的 [CLS] token attention,但现代 VideoLLM 通常采用 SigLIP 等无 [CLS] 架构,导致方法失效。
Meanwhile, certain methods require explicit attention weights in specific LLM layers, making them incompatible with efficient attention operators (Dao et al., 2022).
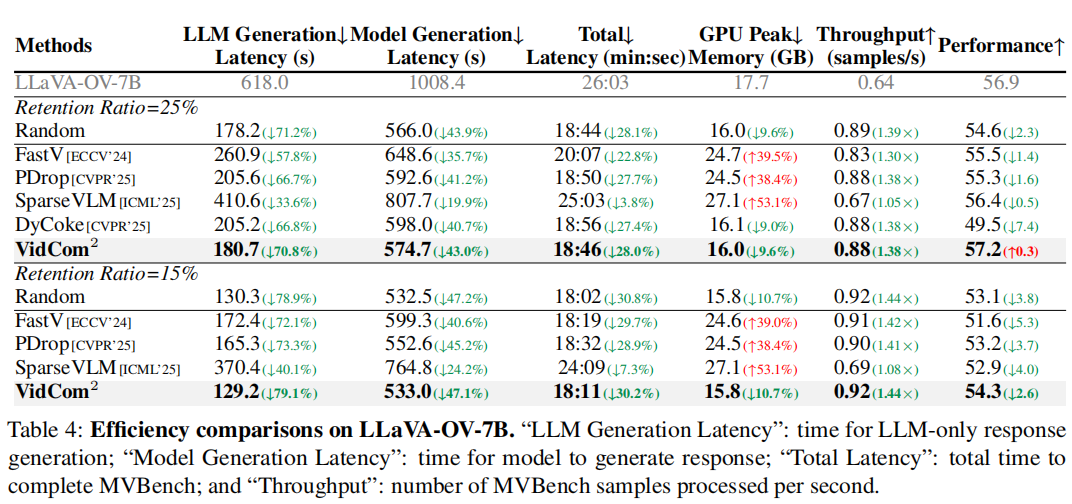
另一些方法需要访问显式 attention weights,无法与 FlashAttention 等高效算子兼容,反而增加显存峰值(Table 4)。
We identify three key principles:
- Model Adaptability
- Frame Uniqueness
- Operator Compatibility
VidCom2 的设计正是围绕这三条原则展开。
3. Method
Video Compression Commander
VidCom2 是一个训练无关、模型无关、算子友好的视频 token 压缩框架。
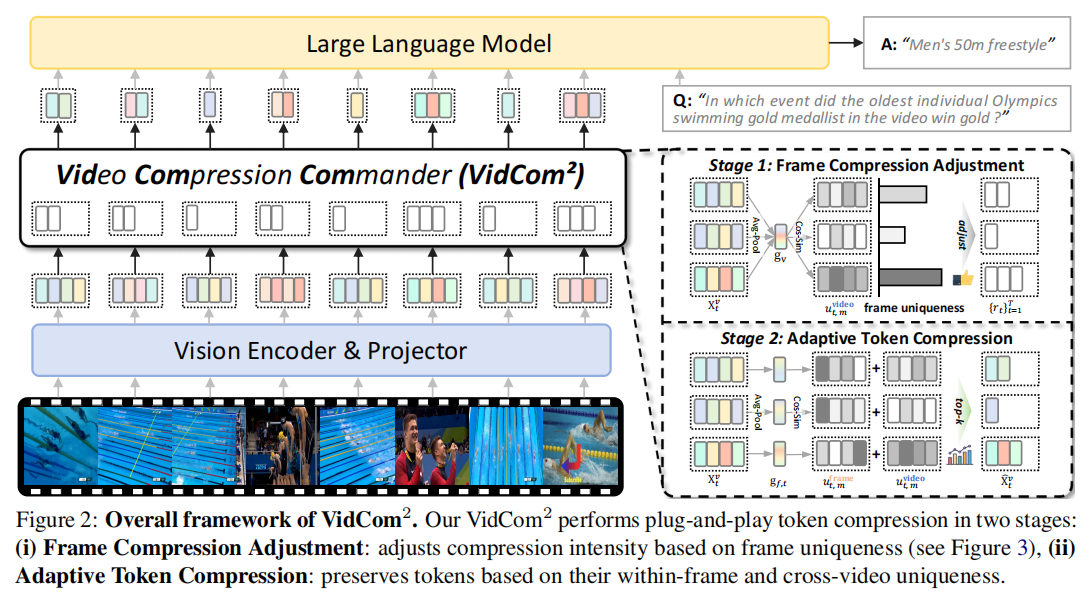
Figure 2 展示了 VidCom2 的整体流程,其核心由两个阶段构成:
- Stage 1: Frame Compression Adjustment(帧级压缩调度)
- Stage 2: Adaptive Token Compression(自适应 token 压缩)
该两阶段设计体现了 VidCom2 的核心思想: 先在“帧级”决定资源分配,再在“token 级”执行精细压缩。
3.3 Stage 1: Frame Compression Adjustment
设计目标
该阶段的目标是: 根据每一帧在整个视频中的独特性,动态调整其 token 保留比例。
数学建模
设视频共有 $T$ 帧,每帧包含 $M$ 个视觉 tokens:
$$ x^v_{t,m} \in \mathbb{R}^{D’} $$
全局视频表示
通过对所有帧、所有 token 求平均,得到视频级表示:
$$ g_v = \frac{1}{T \cdot M} \sum_{t=1}^{T} \sum_{m=1}^{M} x^v_{t,m} $$
该向量 $g_v$ 作为整个视频的粗粒度语义中心。
Token 级视频相似度
计算每个 token 与视频全局表示的余弦相似度:
$$ s^{video}{t,m} = \frac{x^v{t,m} \cdot g_v}{|x^v_{t,m}| |g_v|} $$
相似度越低,说明该 token 与“视频整体”差异越大,信息越独特。
定义 token 的视频级独特性:
$$ u^{video}{t,m} = - s^{video}{t,m} $$
帧级独特性评分
对每一帧的 token 独特性求平均:
$$ u_t = \frac{1}{M} \sum_{m=1}^{M} u^{video}_{t,m} $$
$u_t$ 越大,说明该帧包含的 token 越“非冗余”。
Figure 3 展示了 $u_t$ 在真实视频中的分布情况,可有效区分关键帧与冗余帧。
稳定化与归一化
为避免数值不稳定,作者进行 softmax 调度:
$$ \tilde{u}_t = \frac{u_t - \max(u_t)}{\tau}, \quad \tau = 0.01 $$
$$ \sigma_t = \frac{\exp(\tilde{u}t)}{\sum{l=1}^{T} \exp(\tilde{u}_l) + \epsilon} $$
帧级保留比例调整
给定全局平均保留率 $R$,每帧的实际保留率为:
$$ r_t = R \times \left(1 + \sigma_t - \frac{1}{T}\right) $$
该公式保证:
- 平均保留率仍为 $R$
- 独特帧 $r_t > R$
- 冗余帧 $r_t < R$
3.4 Stage 2: Adaptive Token Compression
设计目标
在已确定每帧 token 预算 $r_t \times M$ 后,选择最有信息量的 tokens。
Token 独特性建模
帧级表示
$$ g_{f,t} = \frac{1}{M} \sum_{m=1}^{M} x^v_{t,m} $$
帧内相似度
$$ s^{frame}{t,m} = \frac{x^v{t,m} \cdot g_{f,t}}{|x^v_{t,m}| |g_{f,t}|} $$
定义帧内独特性:
$$ u^{frame}{t,m} = - s^{frame}{t,m} $$
综合独特性评分
结合帧内与视频级信息:
$$ u_{t,m} = u^{frame}{t,m} + u^{video}{t,m} $$
该设计使 token 同时满足:
- 在当前帧中是“非中心”的
- 在整个视频中是“非冗余”的
Top-K 压缩
$$ \hat{X}^v_t = \text{TopK}(X^v_t, {u_{t,m}}, r_t \times M) $$
最终得到压缩后的视频 token 序列。

完整算法流程见 Appendix E。
4. Evaluation
4.1 Experimental Setting
实验在多种 VideoLLM 架构上进行,包括 LLaVA-OneVision 等主流模型,覆盖多种视频理解 benchmark(如视频问答、推理任务等)。
VidCom2 作为 inference-time 插件,无需微调模型参数。
4.2 Main Comparisons
主要对比方法包括:
- Random token dropping
- Uniform token compression
- DyCoke
- 其他 pre-LLM / intra-LLM 方法(Table 1)
结果显示:
- 在相同 token 保留率下,VidCom2 性能最高
- 在相同性能下,VidCom2 延迟最低
Table 2 表明,VidCom2 在 25% tokens 下仍保持 99.6% 精度。
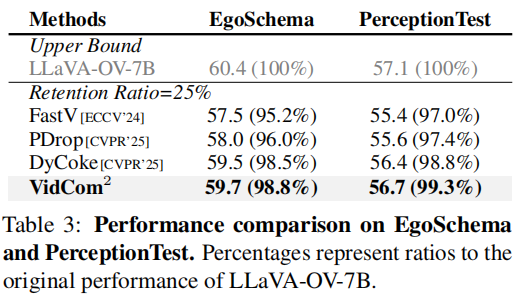
Table 4 显示,VidCom2 显著降低 LLM 生成延迟(70.8%),且显存占用低于部分压缩方法。
4.3 Ablation Study and Analysis
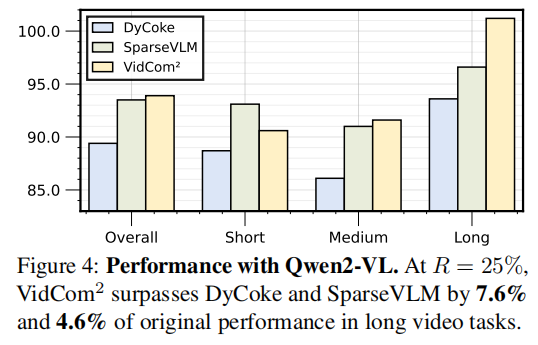
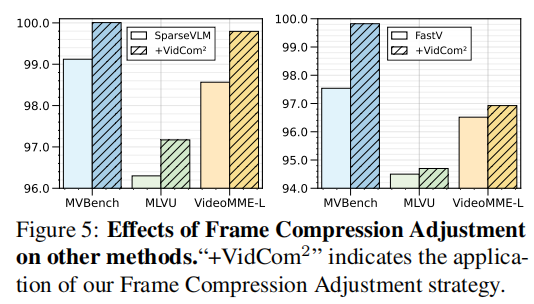
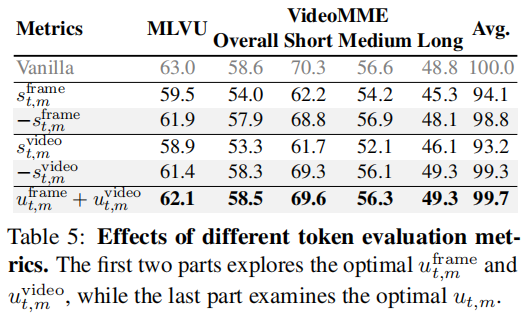
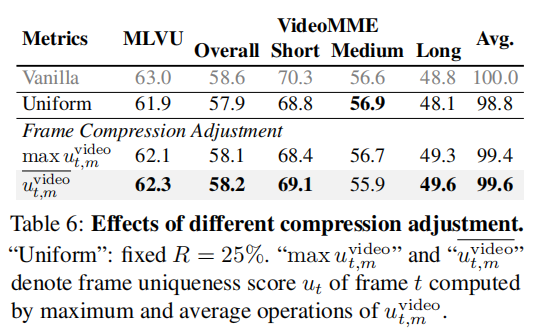
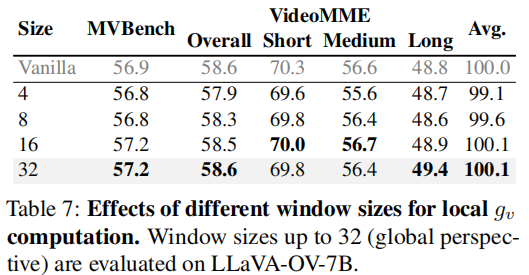
消融实验验证了:
- Frame Compression Adjustment 的必要性
- 双重独特性(frame + video)优于单一标准
- VidCom2 可与其他方法叠加,进一步提升性能
5. Conclusion
本文系统分析了 VideoLLM token compression 的设计与工程瓶颈,提出三条设计原则,并据此提出 VidCom2 框架。
VidCom2 通过帧级调度 + token 级选择,在不牺牲模型性能的前提下显著降低推理成本。
尽管当前未在 72B 级模型上评估,但作者合理推断该方法在大模型场景下收益更大。
未来方向包括:
- 更大规模模型验证
- 实时流式视频理解适配