
Conference: NeurIPS'25
Github: https://github.com/dvlab-research/VisionThink
1. Motivation
最近,视觉语言模型(VLMs) 通过将视觉标记(visual tokens)投影并适配到大语言模型(LLM)空间中,在通用视觉问答(General VQA)和各种现实场景中取得了显著成就。然而,随着 VLM 性能的不断提升,视觉标记的消耗呈指数级增长。例如,一张使用智能手机拍摄的 $2048 \times 1024$ 照片在 LLaVA 1.5 中需要 576 个视觉标记,而现在在 Qwen2.5-VL 中则需要 2,678 个。因此,避免过度使用视觉标记已成为当务之急。
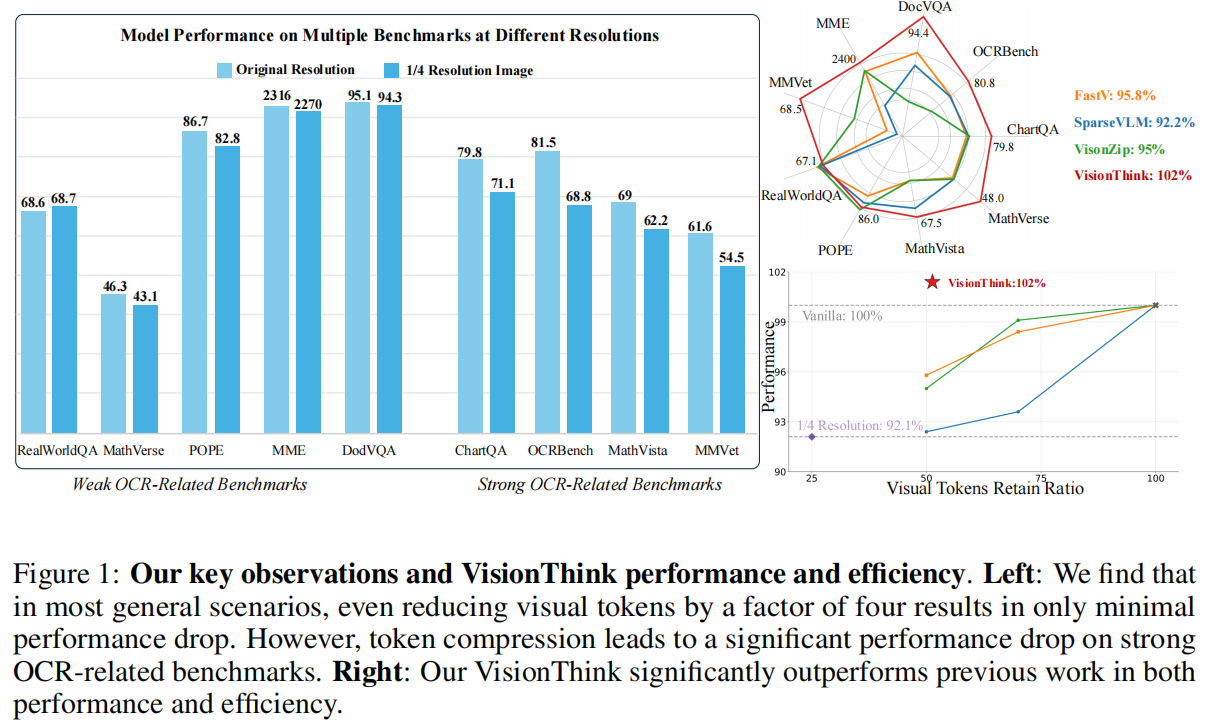
目前已经有大量关于视觉标记压缩的研究被提出。大多数方法使用预定义的阈值来修剪或合并固定数量的视觉标记。然而,不同问题和图像的冗余程度各不相同,这引发了一个自然的问题:作者真的应该在所有场景中应用统一的标记压缩比吗?为了回答这个问题,作者简单地通过降低图像分辨率来减少视觉标记的数量,并评估了 Qwen2.5-VL 在多个基准测试上的性能。如 Fig. 1 左侧所示,作者发现对于大多数现实场景(如 MME 和 RealWorldQA),即使将图像分辨率降低四倍(显著减少 75% 的视觉标记),对模型性能的影响也微乎其微。然而,如 Fig. 1 右侧所示,对于 ChartQA 和 OCRBench 等需要细节理解和 OCR 相关能力的基准测试,减少视觉标记会导致性能大幅下降。
基于这些观察,作者发现大多数现实世界的问题并不需要带有长视觉标记的高分辨率图像,而一小部分 OCR 相关任务对这类细节输入的要求非常高 。因此,如果作者能够动态区分哪些样本需要高分辨率处理,哪些不需要,那么效率优化将具有巨大的潜力 。
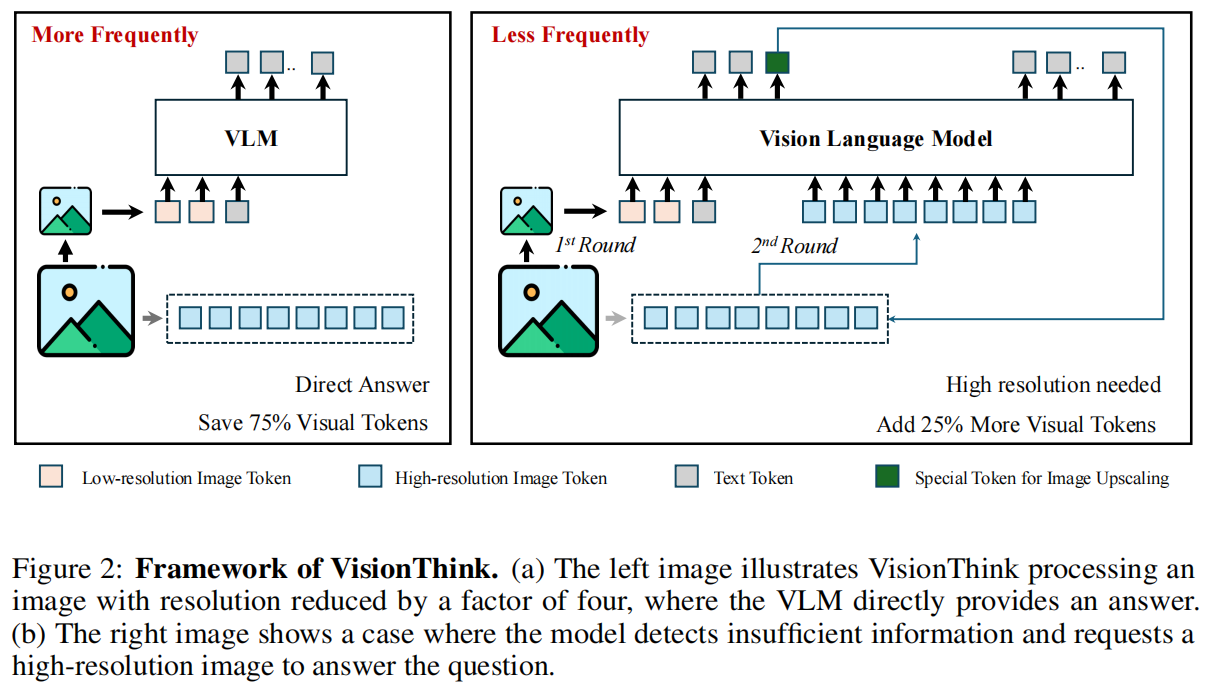
在本文中,作者提出了 VisionThink,这是一种利用模型推理能力的新型高效 VLM 范式 。与之前处理全图后丢弃冗余标记的方法不同,VisionThink 直接输入压缩后的视觉标记,并允许模型在需要时请求原始高分辨率图像 。这使得在大多数现实场景中能够进行更高效的推理,同时保留在 OCR 相关任务上的性能 。
2. Contribution
在本文中,作者提出了 VisionThink,这是一种新的高效 VLM 范式,它利用了模型的推理能力 。与之前处理完整图像然后丢弃冗余标记的方法不同,VisionThink 直接输入压缩后的视觉标记,并允许模型在需要时请求原始高分辨率图像 。这使得在大多数现实场景中能够实现更高效的推理,同时在 OCR 相关任务上保持性能 。
尽管 VisionThink 提供了一种聪明处理具有不同视觉冗余水平样本的前景方法,但它仍然面临两个关键挑战:
-
针对通用 VQA 的有效强化学习 (Effective Reinforcement Learning for General VQA):传统的基于规则的强化学习算法(通常用于优化推理过程)难以应对通用 VQA 的多样性和复杂性 。为了克服这个问题,作者提出了 LLM-as-Judge 方法,实现了语义匹配 。实验表明,在多个通用 VQA 基准测试中性能都有所提升,突显了将基于视觉的强化学习从视觉数学推理扩展到更广泛 VQA 任务的潜力 。
-
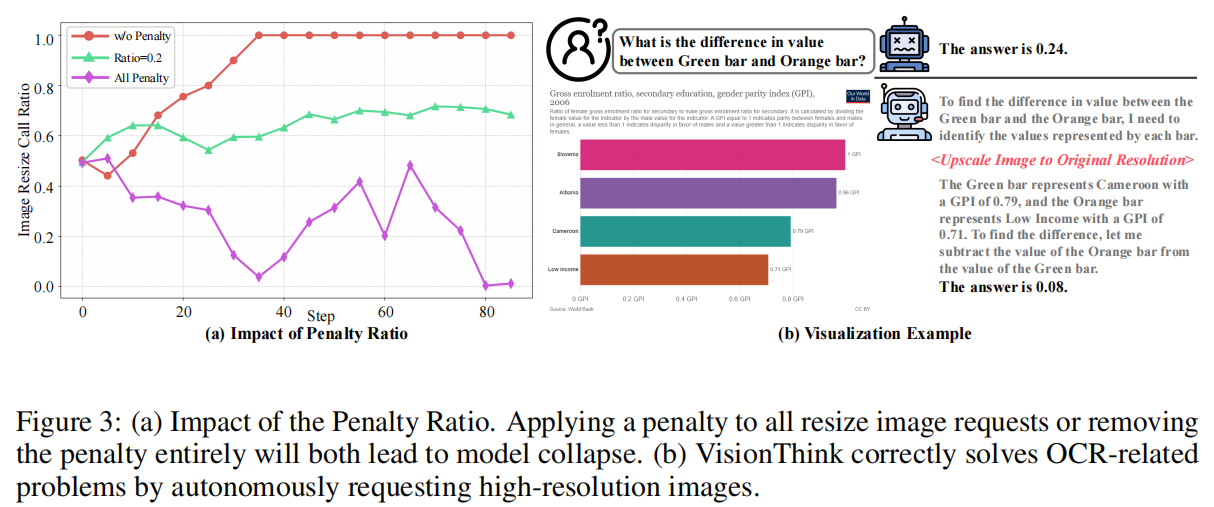
确定高分辨率何时值得 (Determine When High Resolution is Worth):为了在不损害性能的情况下提高效率,模型必须准确确定何时需要高分辨率输入 。作者通过精心设计平衡奖励函数 (balanced reward function) 来实现这一点,以防止模型陷入总是要求高分辨率图像或总是使用低分辨率图像的崩溃状态 。通过这种机制,VisionThink 在 OCR 基准测试上保持了强大的性能,同时在非 OCR 基准测试上实现了显著的加速,DocVQA 的加速高达 100% 。
总的来说,作者提出了一个简单且有效的流水线——VisionThink 。它通过根据每个样本的内容动态决定压缩,引入了一种视觉标记压缩的新方法,从而在样本级别实现效率增益 。因此,它与其它先进的空间级方法兼容 。
3. Preliminary
3.1 Large Language Models and Reinforcement Learning
最近在提升大语言模型(LLMs)推理能力方面的进展表明,强化学习(RL)是一种有效的训练方法 。在这项工作中,作者使用 GRPO (Group Relative Policy Optimization) 作为作者的训练方法 。GRPO 通过使用组分数来估计基准,从而消除了对独立 Critic 模型的需要,这降低了计算成本,提高了训练稳定性 。
训练过程中,GRPO 根据旧策略 对给定问题 采样一组输出 ,并通过最大化以下目标来优化策略模型 :
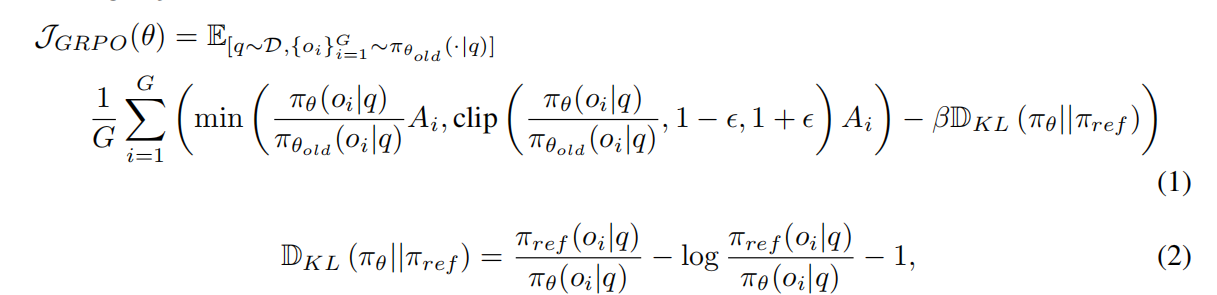

3.2 Computation Complexity

4. Methodology (详细设计)
4.1 Overview
作者的目标是开发一个智能且高效的 VLM,能够自主判断给定图像中的信息是否足以准确回答问题 。如 Fig. 2 所示,该流水线首先处理低分辨率图像以最小化计算成本 。当降采样图像中的信息不足以回答问题时,它会智能地请求原始高分辨率输入 。理想情况下,这一策略在大幅减少计算负载的同时保持了高性能 。
为了实现这一目标,作者必须解决两个关键挑战:
-
在通用 VQA 上实现有效的 RL:由于通用 VQA 的多样性和复杂性,传统的基于规则的 RL 算法并不直接适用 。为此,作者提出了 LLM-as-Judge 策略,利用大语言模型指导和评估 RL 训练过程 。
-
使模型能够决定何时需要高分辨率:模型必须学会评估降采样图像是否包含足够信息,或者是否需要原始高分辨率图像,以便平衡效率和性能 。
4.2 LLM-as-Judge for General VQA
挑战:在通用 VQA 中应用强化学习的核心挑战之一在于评估模型响应,特别是当答案是开放式或依赖上下文时 。大多数现有的多模态 RL 努力仍局限于结构化任务(如视觉数学),其 Ground-truth 答案可以通过规则或精确匹配轻松验证 。
纯文本准确性判断 (Pure Text Accuracy Judgement):
-
作者采用外部强 LLM(如 GPT-4o)作为评判者 。
-
评判完全在文本层面进行,通过对比模型预测和 Ground-truth 来判断正确性 。这种设计避免了来自视觉内容的偏见以及 VLM 性能本身的局限 。
-
为了减少评判者的误判,奖励是离散的(0 或 1),而非连续得分 。具体 Prompt 模板见附录 Table 3 。
-
有效性:该策略非常灵活,可以利用绝大部分 SFT 数据。作者收集了 130K 样本直接进行 GRPO 训练,无需冷启动 。
4.3 Multi-Turn Training Algorithm (多轮训练算法)

模型如何发出信号?: 作者修改了 Prompt,引导模型在需要高分辨率时输出特定的特殊标记(如 Agent Prompt) 。选择合适的 Prompt 至关重要,否则 GRPO 会因零样本下无法输出特殊标记而导致梯度缺失 。研究发现 Qwen-2.5VL 推荐的 Agent Prompt 最适合 VisionThink 。
4.4 Reward Design (奖励设计详情)

4.5 Data Preparation (数据准备)
为了训练模型学会在不同分辨率间决策,作者构建了一个平衡数据集 :
-
采样:对基础模型进行 8 次采样(rollouts),Temperature 设为 1.0。
-
类别划分:
- Solvable Low-Res (低分可解):在低分和高分下均 8 次全对的样本。
- High-Res Required (需高分):高分下的正确率比低分下显著高出(如高出 6 次及以上)的样本。
-
规模:最终挑选各 10K 样本,共 20K 训练数据。
5. Experiments (详细实验评估)
5.1 Evaluation Setup
-
模型:基于 Qwen2.5-VL-7B-Instruct 。
-
训练细节:使用 veRL 框架,全局 Batch Size 512,采样 16 个响应进行 GRPO 训练。
-
对比模型:包括 GPT-4o, Claude-3.5 Sonnet, Gemini-1.5-Pro 等闭源模型,以及 InternVL2-8B, LLaVA-OneVision 等开源模型。
5.2 Reinforcement Learning Enables VLM to Be More Effective
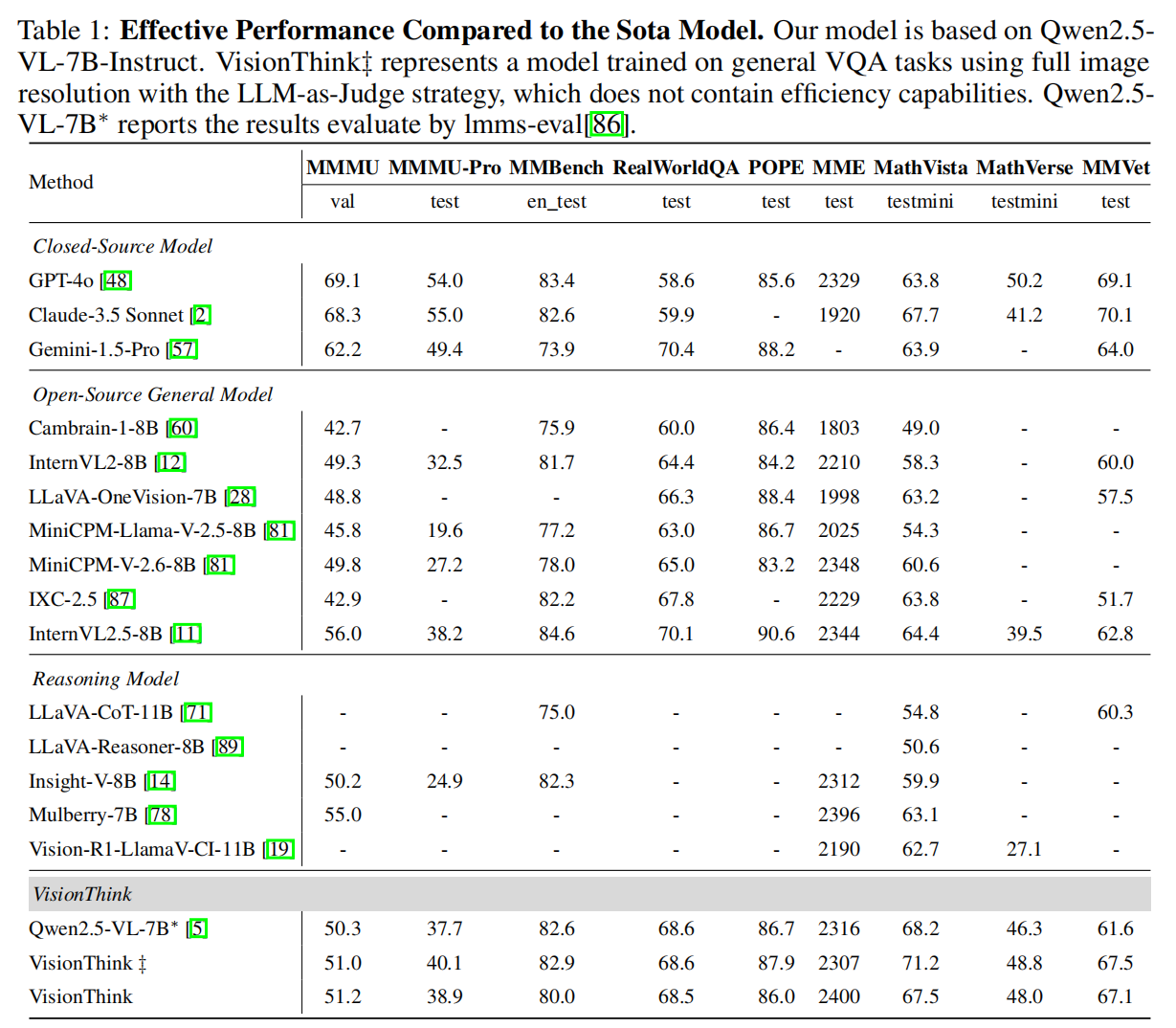
如 Table 1 所示,VisionThink 在多个基准测试上取得了显著提升:
- MathVerse 提升了 3.7%,MMVet 提升了 8.9%。
- 在 MME 测试中,VisionThink 达到了 2400 分,超越了 GPT-4o (2329)。
- 实验证明,即使不考虑效率,通过 LLM-as-Judge 引导的 RL 也能显著增强模型的推理和理解能力。
5.3 Reinforcement Learning Enables VLM to Be More Efficient
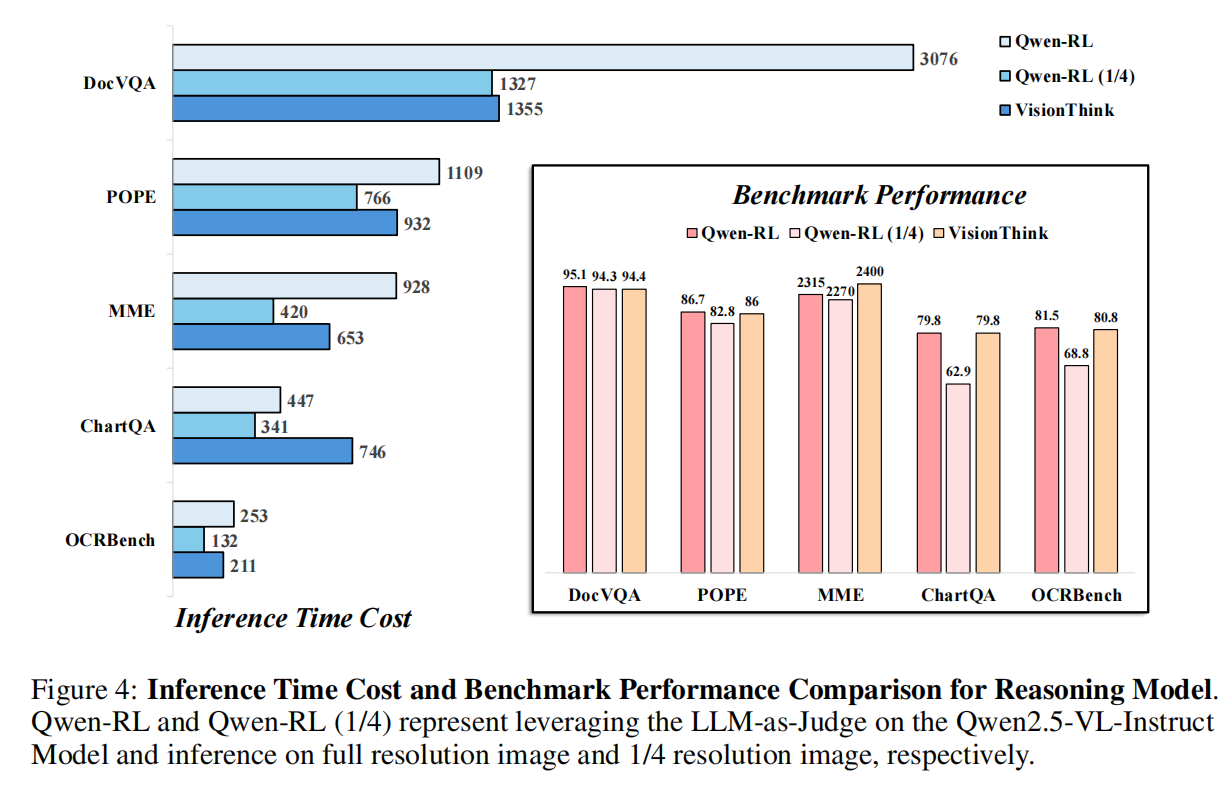
VisionThink 实现了极高的推理效率(见 Fig. 1 右侧和 Table 7):
-
DocVQA:相比全分辨率模型,实现了 100% 的提速 。
-
MME & POPE:在这些通用任务上,推理时间减少了约 1/3,因为模型自主选择了低分路径。
-
性能/效率平衡:在 ChartQA 上,VisionThink 以更少的视觉标记实现了 102% 的相对性能(相比全分辨率基础模型) 。
5.4 Reinforcement Learning Enables VLM to Be Smarter

模型表现出了明显的“因地制宜”能力:
-
对于 OCRBench 等强 OCR 任务,模型请求高分辨率的比例显著更高 。
-
对于简单物体识别或常识问答,模型几乎总是直接回答,节省了 75% 的图像标记 。
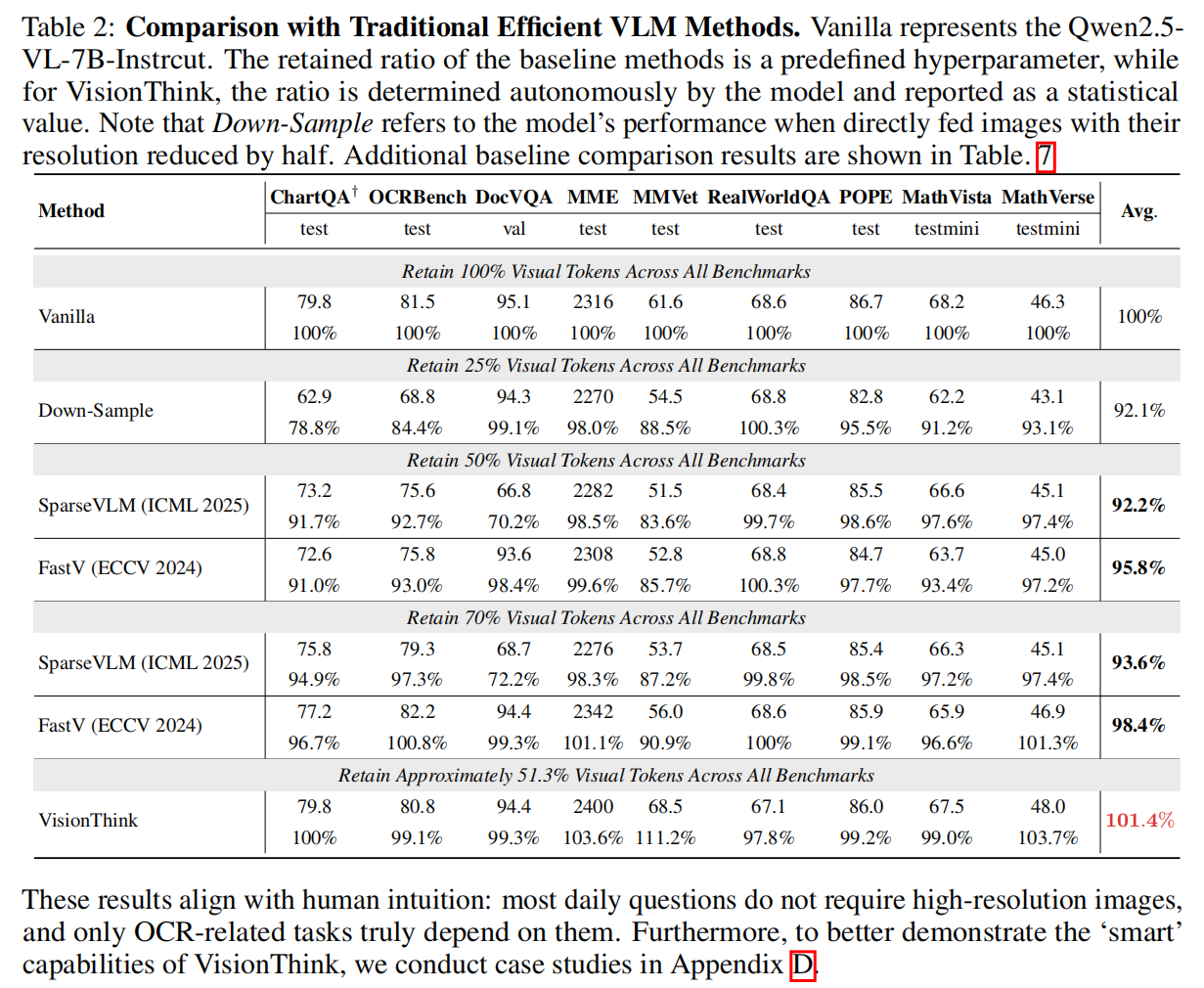
5.5 Relationship of the EfficientVLM methods and VisionThink
-
Key Differences (核心区别):传统方法(如 FastV, SparseVLM)使用固定阈值剪枝,容易在 OCR 任务上造成毁灭性打击 。VisionThink 是根据内容自主决定是否需要更多信息 。
-
Integration Potential (集成潜力):VisionThink 是一种处理图像的新范式,可以与现有的标记压缩技术(如 VisionZip)结合 。通过 RL,模型可以更聪明地使用这些工具,从而在不降性能的前提下进一步推高效率上限。
6. Concluding Remarks
6.1 Summary
在本文中,作者介绍了 VisionThink,这是一种增强通用 VQA 效率和性能的新范式。通过最初处理降采样图像,并利用强化学习在需要时选择性地升级到更高分辨率,VisionThink 在优化计算资源的同时保留了准确性。利用 LLM-as-Judge 策略和量身定制的奖励函数,作者的方法在各种 VQA 基准测试中优于之前的最先进模型,特别是在 OCR 等需要细粒度细节的任务中。作者相信 VisionThink 展示了强化学习在视觉语言模型中的潜力,并鼓励开发更有效、更高效的 AI 系统。
6.2 Limitations and Future work
在这项工作中,作者关注 2 倍分辨率升级和最多两轮对话的设置,并取得了可喜的结果。然而,它尚未扩展到灵活分辨率升级的设置。此外,结合裁剪(cropping)等更多视觉工具将进一步带来效率和性能方面的收益。此外,多轮(例如超过 5 轮)图像工具调用在解决复杂视觉问题方面可以获得更多收益。
此外,作者的论文利用图像缩放来减少视觉标记的数量。这种简单的方法通过强化学习在性能和效率之间取得了良好的平衡。作者希望这项工作能启发高效推理视觉语言模型领域的进一步研究,特别是让模型变得更聪明、更像人。作者将继续探索构建更通用、更强大且更高效的视觉语言模型的道路。