
1. Motivation
-
前缀缓存(Prefix Cache)的局限性:目前的 KV Cache 重用机制(如前缀缓存)要求新请求的初始片段(即前缀)与已有缓存序列精确匹配。这种严格的匹配标准虽然保证了输出准确性,但在多模态场景下引入了严重的效率瓶颈:即便图像完全相同,只要系统提示词或用户问题不同,也无法触发缓存命中。
-
位置无关重用的必要性:如果允许在不同位置重用预缓存的 KV Cache,将显著提升多模态推理的灵活性。然而,位置变化会破坏因果注意力中的位置一致性,因此为了保持输出准确性,必须对部分 token 进行重新计算(recompute)。
-
现有启发式方法的缺陷:
-
CacheBlend [14]:通过比较前三层的 KV Cache 距离来识别“最不可靠”的 token 并重计算。但该方法仅依赖浅层局部信息,无法刻画 token 在整个 Transformer 堆栈中的全局重要性。
-
EPIC [6] 与 MPIC [16]:以 chunk 为单位,重计算每个数据块的初始 token。其中 MPIC 假设存在“注意力汇聚(attention sink)”效应,但该假设在视觉 token 上并不成立,因为视觉 token 不像系统提示词那样在注意力中占据主导地位。
-
KVShare [13]:基于注意力分布偏差选择性重计算关键 token,但仍然缺乏对重用误差如何在解码阶段传播的系统性分析。
-
-
缺乏系统性研究:上述方法普遍缺少以下两点:
- 不同 Transformer 层对最终输出贡献差异的系统研究;
- 重用误差在自回归解码过程中跨 token、跨层传播机制的深入分析。
2. Contribution
-
识别累积重用误差效应:系统性分析了多模态大语言模型(VLM)中 KV Cache 重用所引入的误差,提出并验证了 累积重用误差效应(Cumulative Reuse Error Effect),即早期 token 的重用误差会在后续生成过程中不断传播和放大。
-
层级重要性差异分析:通过实验发现,不同 Transformer 层对最终模型输出的影响高度不均衡,并首次从实证角度揭示了 VLM 中的层级重要性多样性。
-
提出 VLCache 框架:设计了一个端到端的视觉 token KV Cache 重用流水线,兼顾算法有效性与系统可落地性。
-
双重重用机制:
- 重用视觉编码器输出(Encoder Cache);
- 重用语言模型中的 KV Cache。
-
动态重计算策略:在固定重计算预算约束下,提出一种逐层自适应的重计算比例分配算法,以最小化输出误差。
-
显著性能提升:实验表明,仅需重新计算 2–5% 的视觉 token,即可实现近乎无损的准确率,同时将首字延迟(TTFT)提升 1.2×–16×。
-
系统集成验证:在 SGLang 框架中实现原型系统,显著降低真实部署环境中的推理延迟。
3. Observation
3.1 Cumulative Reuse Error Effect(累积重用误差效应)
在自注意力机制中,每个 token 的输出依赖于其上下文表示。在因果语言模型(Causal LLM)中,第 $i$ 个 token 会关注所有位置 $j \le i$ 的 token。当 KV Cache 在不匹配的上下文下被重用时,会引入 重用误差(Reuse Error)。
作者将位置 $i$ 的 token 总误差分解为两部分:
- 自身重用误差(Self Reuse Error):
$$ \epsilon_i^{\text{self}} = h_i^{\text{reuse}} - h_i^{\text{full}}, $$
其中 $h_i^{\text{reuse}}$ 表示使用重用 KV Cache 得到的隐状态,$h_i^{\text{full}}$ 表示完全重计算得到的隐状态。
- 传播误差(Propagated Error):来自所有先前 token 的误差累积:
$$ \epsilon_i^{\text{prop}} = \sum_{j < i} \alpha_{i,j} , \epsilon_j, $$
其中 $\alpha_{i,j}$ 表示位置 $j$ 的误差通过自注意力机制向位置 $i$ 传播的权重。
因此,第 $i$ 个 token 的总重用误差为:
$$ \epsilon_i = \epsilon_i^{\text{self}} + \epsilon_i^{\text{prop}}. $$
该公式揭示了一个关键现象:即使后续 token 本身被精确计算,只要早期 token 存在重用误差,该误差仍会持续影响下游表示。
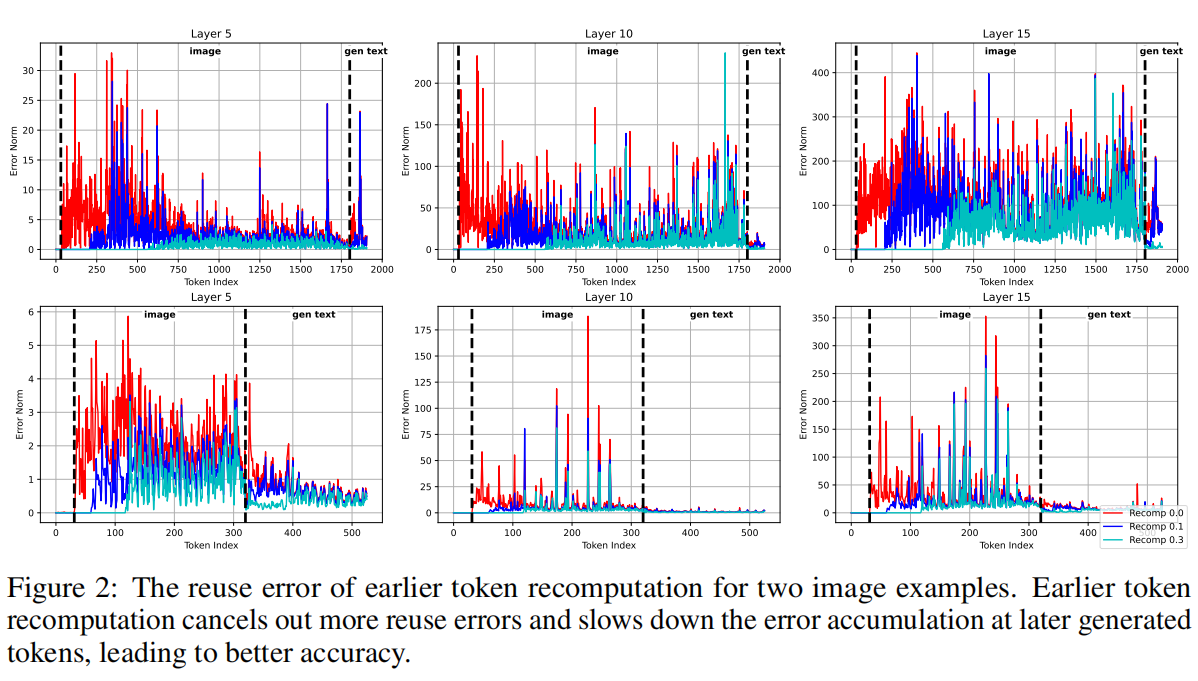 (对应论文 Figure 2:早期 token 的重计算可显著抑制下游误差累积)
(对应论文 Figure 2:早期 token 的重计算可显著抑制下游误差累积)
实验验证:通过测量不同重计算比例下的误差范数,作者发现:
- 早期 token 的重用会引入持久且累积的误差;
- 仅对前 $10%$ 或 $30%$ 的 token 进行重计算,即可消除大部分上游误差,从而显著改善整体输出质量。
3.2 Layer-wise Importance Difference(层级重要性差异)
作者在 Qwen2.5-VL-7B 上实证研究了不同 Transformer 层对最终输出的敏感性,验证“所有层同等重要”的假设是否成立。
实验流程(三阶段):
-
构造缓存:固定输入图像,将原始问题替换为无关提示词(如 “Please describe this image”),执行前向传播并缓存图像对应的 KV Cache。
-
获取基准输出:使用原始问题进行标准推理,记录输出的 logits 与生成文本。
-
注入误差并测量敏感度:
- 在推理过程中使用不匹配的图像 KV Cache;
- 仅在指定的第 $l$ 层对前 $r$ 比例的 token 进行重计算;
- 计算当前输出 logits 与基准 logits 之间的 MSE 损失。
$$ \mathcal{L}_l(r) = | \mathbf{z}^{\text{reuse}}_l(r) - \mathbf{z}^{\text{full}} |_2^2. $$
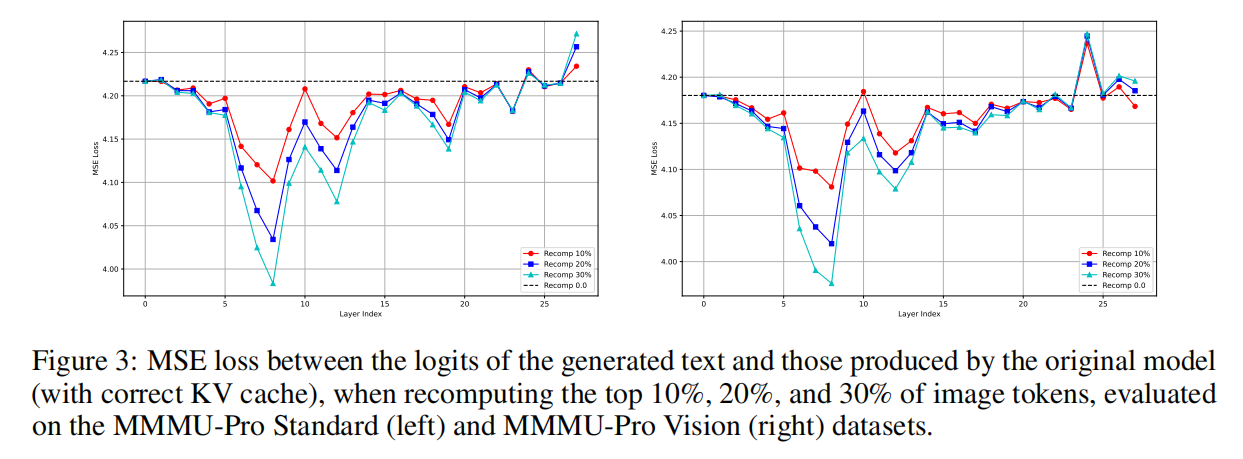 (对应论文 Figure 3:MMMU-Pro 上的层级敏感度曲线)
(对应论文 Figure 3:MMMU-Pro 上的层级敏感度曲线)
结论:
- 不同层对重计算比例 $r$ 的敏感性差异极大;
- 某些中间或高层是“关键层”,需要较高的重计算比例;
- 也存在对重用几乎不敏感的层,甚至可以完全跳过重计算而不影响输出质量。
4. Design (Algorithm & System Implementation)
4.1 VLCache: Reuse and Dynamic Recomputation
VLCache 以插件形式集成到标准的 VLM 推理流水线中。
基础算法(Basic Algorithm)
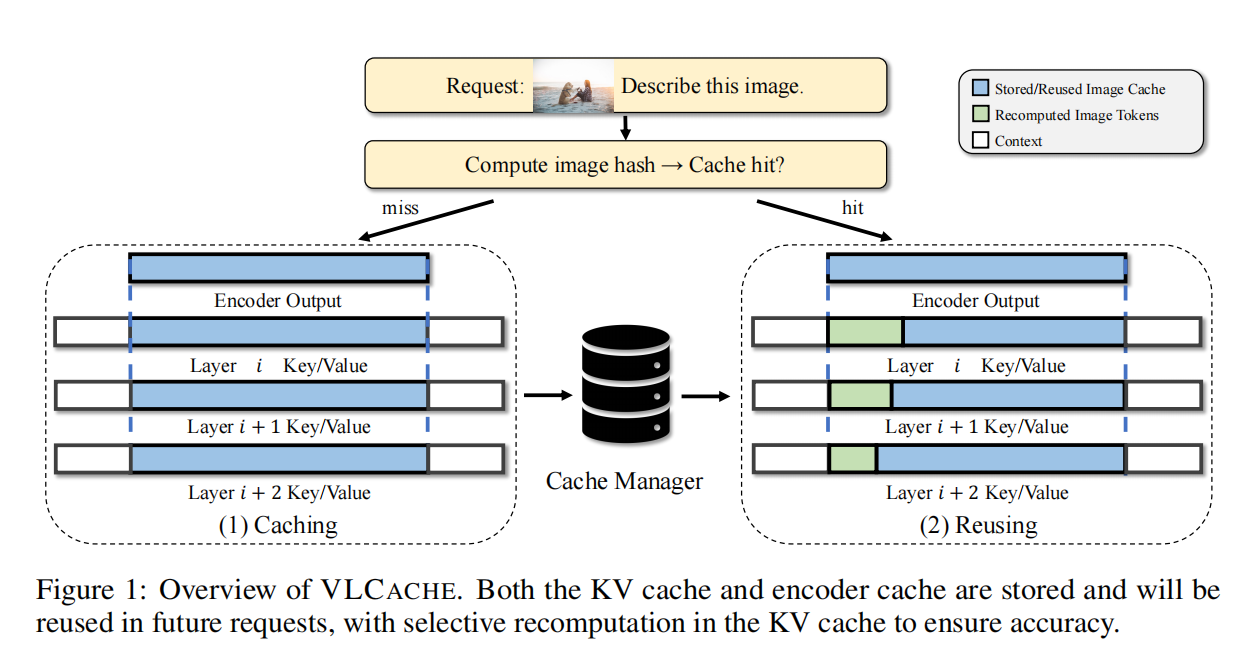 (对应论文 Figure 1:整体缓存与重用流程)
(对应论文 Figure 1:整体缓存与重用流程)
-
哈希与检索:
- 对输入图像计算内容哈希值;
- Cache Miss:执行完整 prefilling,并将视觉编码器输出(Encoder Cache)与 LLM 的 KV Cache 存入后端存储(如 Tair KVCache Store);
- Cache Hit:直接从后端检索缓存。
-
部分重计算:
- 对缓存的视觉 token,仅重计算最前面的 $r$ 比例;
- 其余 $(1-r)$ 的 token 直接重用缓存结果。
-
计算跳过:
- 对重用 token,其 Attention 与 MLP 计算被完全跳过;
- 这是 VLCache 实现显著加速的核心机制。
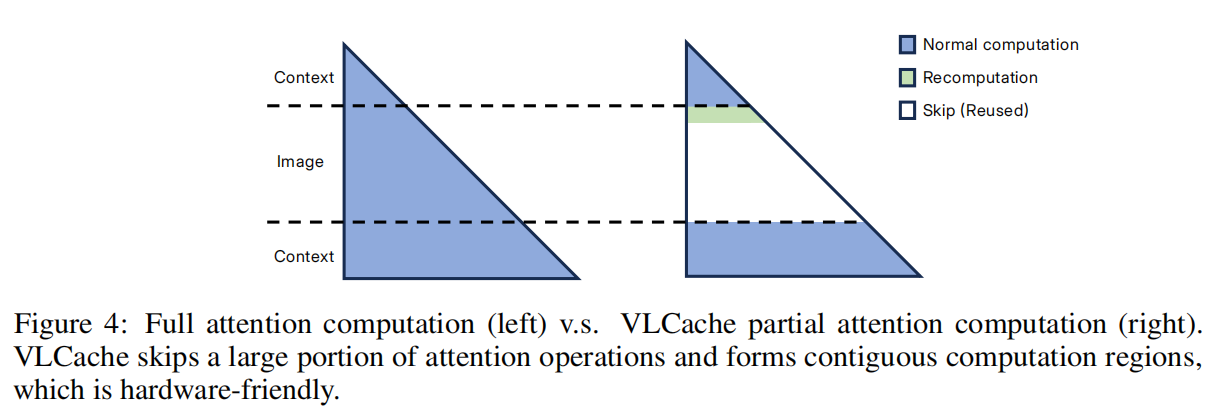 (对应论文 Figure 4:形成连续、硬件友好的计算区域)
(对应论文 Figure 4:形成连续、硬件友好的计算区域)
动态重计算策略(Dynamic Recomputation)
为在固定预算下获得最优精度,作者提出逐层动态分配重计算比例的策略。
- 层敏感度定义:
在代理数据集 $\mathcal{D}$ 上,第 $l$ 层在重计算比例 $r$ 下的敏感度定义为:
$$ S_l(r) = \mathbb{E}_{(x,y) \sim \mathcal{D}} \left[ | \mathbf{z}_l^{\text{reuse}}(r) - \mathbf{z}^{\text{full}} |_2^2 \right]. $$
- 优化目标建模:
在总重计算预算 $B$ 下,优化问题表示为:
$$ \min_{{r_l}} \sum_{l=1}^L S_l(r_l) $$
约束条件:
$$ \sum_{l=1}^L r_l \le B, $$
$$ r_1 \ge r_2 \ge \cdots \ge r_L, $$
$$ r_l \in {0, \Delta, 2\Delta, \dots, 1}. $$
其中单调不增约束保证深层可以直接复用浅层已经计算好的隐状态,避免重复计算。
- 贪心近似算法:
由于该问题是离散整数规划,作者在假设层间近似独立的前提下,采用贪心策略搜索近似最优解,大幅降低搜索成本。
4.2 SGLang Integration of VLCache
在 SGLang 框架中的实现包含两项关键系统优化:
-
跳过 ViT 计算:
- 对输入图像像素计算全局内容哈希;
- 若缓存命中,直接从 Tair KVCache Store 读取视觉 embedding,完全绕过视觉 Transformer(ViT)。
-
跳过 Attention 与 MLP 计算:
- 为每张图像分配独立哈希,实现细粒度缓存管理;
- 采用 Block Sparse Attention 支持非连续 token 的选择性重计算;
- 在每一层构造二值 Computation Mask,标识需重计算的 token;
- 仅对被选中的 token 执行 RoPE、Attention 与 MLP,其余部分直接复用;
- KV Cache 在应用 RoPE 之前存储,从而支持位置无关重用。
5. Experiments and Discussion
5.1 Acceleration of VLCache(加速性能)
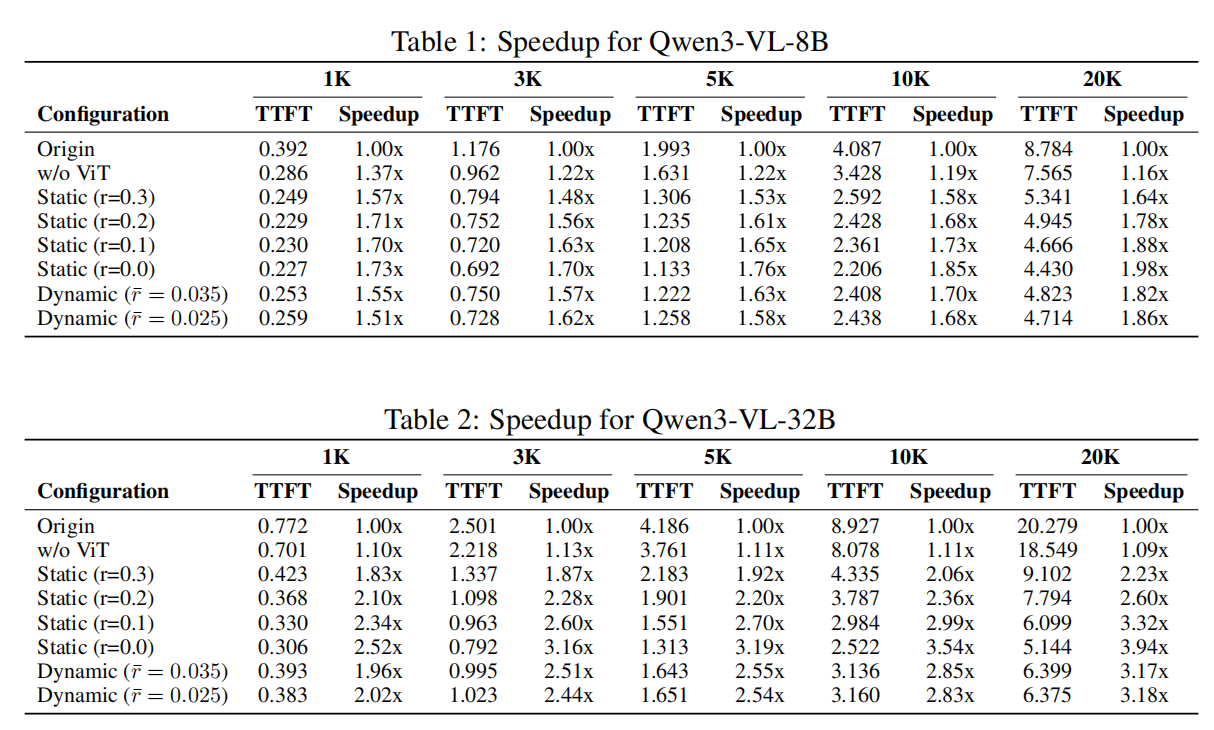 VLCache 显著降低了 Time-To-First-Token(TTFT)。在 Qwen2.5-VL(表中标记为 Qwen3-VL)上的实验表明:
VLCache 显著降低了 Time-To-First-Token(TTFT)。在 Qwen2.5-VL(表中标记为 Qwen3-VL)上的实验表明:
-
Qwen2.5-VL-8B:
- 在 20K 视觉 token 下,原始 TTFT 为 8.784s;
- 动态配置后降至 4.714s,加速比 1.86×;
- 即使不考虑 ViT 跳过,仅 KV Cache 重用也贡献主要加速。
-
Qwen2.5-VL-32B:
- 在 20K token 下,加速比最高可达 3.94×(静态),动态配置下仍超过 2.5×。
-
整体趋势:视觉 token 越长,加速效果越显著,TTFT 提升范围为 1.2×–16×。
5.2 Accuracy Preservation of VLCache(准确度保持)
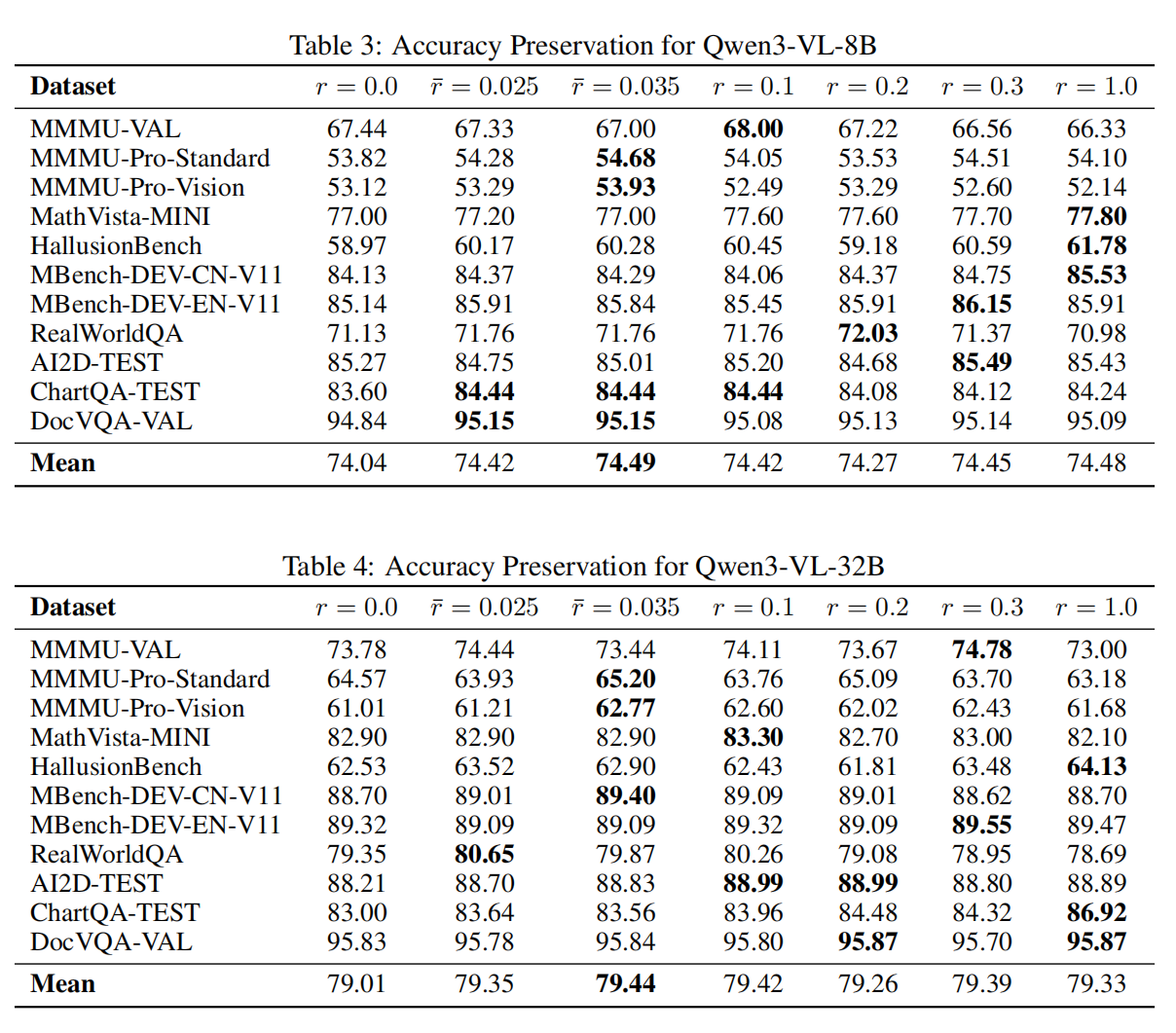
-
近乎无损精度:仅重计算 2–5% 的视觉 token,在 MMMU-Pro、MME 等基准上与全量重计算几乎一致。
-
动态优于静态:在相同预算下,逐层动态分配重计算比例显著优于统一比例策略。
5.3 Comparisons with Other SOTA Methods
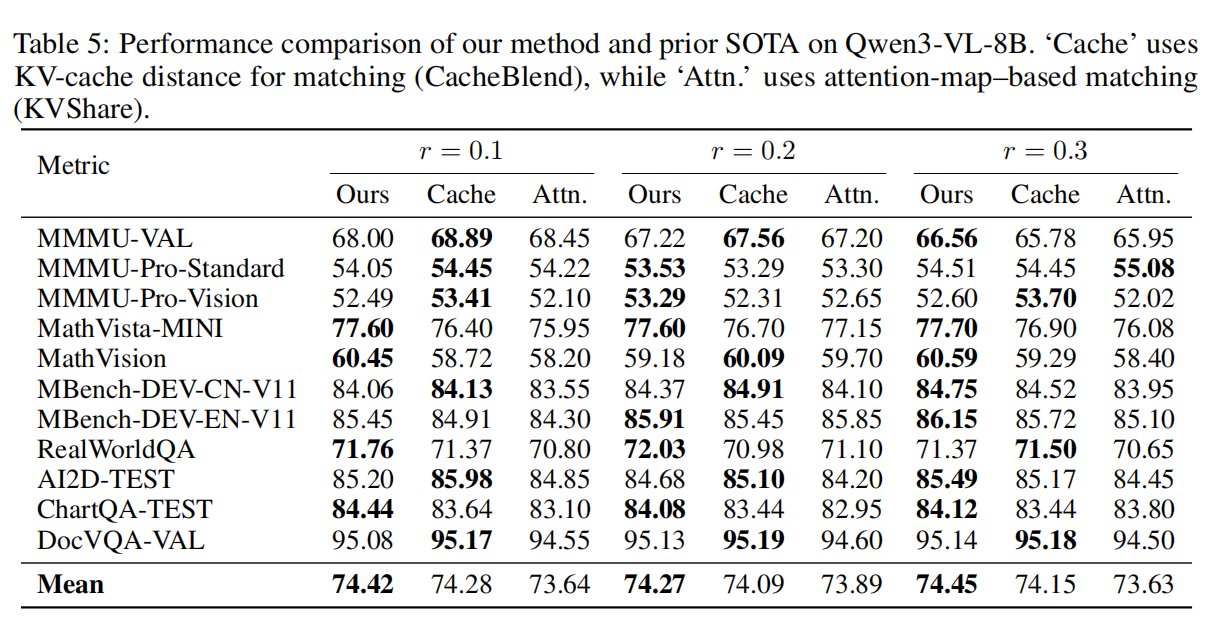
-
全面优于启发式方法:在加速比与准确率上均优于 CacheBlend、MPIC 与 KVShare;
-
理论驱动优势:基于累积误差效应与层级重要性分析,VLCache 避免了 MPIC 在视觉 token 场景下失效的问题。
6. Conclusion
VLCache 提供了一个将理论洞察与系统实现深度结合的完整方案,在几乎不损失推理精度的前提下,大幅加速了 VLM 的预填充阶段。该方法尤其适用于多请求共享同一图像的高并发推理场景。未来的研究方向包括将缓存重用从“完全相同图像”扩展到“相似视觉输入”,以进一步提升其实用价值。